文章目录
- 基础知识补充
- 一、聚类算法
-
- 1、K均值聚类
-
- (1)K均值聚类算法描述
- (2)K均值聚类运行示意
- (3)K均值聚类的基本假设与优化目标
-
- 1、K均值聚类简介
- 2、如何表示簇?
- 3、如何划分节点?
- 4、目标函数
- 5、如何优化?
-
- (1)最小化损失函数
- [(2)鸡生蛋、蛋生鸡问题(Chicken and egg problem)](#(2)鸡生蛋、蛋生鸡问题(Chicken and egg problem))
- (3)迭代求解(坐标轴下降法)
- [(4)初始化K个类中心: μ k \mu_k μk](#(4)初始化K个类中心: μ k \mu_k μk)
- (4)K-means算法的收敛性
- (5)K的选择
-
- 1、训练集上K越大,目标函数值越小
- 2、K的选择------肘部法
- 3、K的选择------假设检验法
- [4、补充:p值(p value)](#4、补充:p值(p value))
- 5、K的选择------假设检验法示例
- (6)如何初始化K-means?
- (7)k-means++
- (8)预处理和后处理
- (9)K-means的局限性
- (10)克服K-means的局限性
- (11)K-medoids
- (12)K-means聚类的优点
- (13)K-means的局限性
- 2、高斯混合模型和EM算法
-
- (1)多元高斯分布
- (2)高斯混合模型
- (3)引入隐含变量
- (4)混合高斯模型的学习过程困难
- [(5)求解方法:EM (Expectation-Maximization) 算法](#(5)求解方法:EM (Expectation-Maximization) 算法)
- (6)通用的EM算法
- [(7)EM for GMM](#(7)EM for GMM)
- (8)通用EM算法
- [(9)证据下界(Evidence Lower Bound, ELBO)](#(9)证据下界(Evidence Lower Bound, ELBO))
- [(10)Why E步?](#(10)Why E步?)
- [(11)Why M步?](#(11)Why M步?)
- (12)EM算法的收敛性
- (13)高斯混合模型与K-means的关系
- [(14)K-means vs 高斯混合模型(GMM)](#(14)K-means vs 高斯混合模型(GMM))
- 3、层次聚类
- 4、基于密度的聚类
-
- (1)DBSCAN
- (2)预备知识
- [(3)DBSCAN 算法](#(3)DBSCAN 算法)
- [(4)DBSCAN 聚类结果](#(4)DBSCAN 聚类结果)
- [(5)DBSCAN: 如何确定 ϵ \epsilon ϵ 和 M i n P t s MinPts MinPts](#(5)DBSCAN: 如何确定 ϵ \epsilon ϵ 和 M i n P t s MinPts MinPts)
- (6)对DBSCAN的分析
- [(7)DBSCAN 什么时候表现不好](#(7)DBSCAN 什么时候表现不好)
- 5、基于图的聚类
-
- (1)基于图的方聚类
- (2)边的创建
- (3)边的权重
- (4)图论基础
- [(5)Laplace矩阵 L L L: L = D − W L = D - W L=D−W](#(5)Laplace矩阵 L L L: L = D − W L = D - W L=D−W)
- (6)Laplace矩阵的性质2
- (7)Laplace矩阵的性质4
- (8)Laplace矩阵的性质5
- (9)图的拉普拉斯矩阵及其应用
- (10)切图(cut)
- (11)最小切图
基础知识补充
一、聚类算法
1、K均值聚类
(1)K均值聚类算法描述
问题描述
给定 N N N个样本点 X = { x i } i = 1 N X = \{x_i\}_{i=1}^N X={xi}i=1N进行聚类。
输入
数据集 D = { x 1 , x 2 , . . . , x N } D = \{x_1, x_2, ..., x_N\} D={x1,x2,...,xN},簇数目为 K K K。
算法步骤
- 随机选择 K K K个种子数据点作为 K K K个簇的中心。
- 重复以下步骤直到簇中心不再更新:
- 对于每个数据点 x i ∈ D x_i \in D xi∈D,计算其与每个簇中心的距离 dist ( x i , μ k ′ ) \text{dist}(x_i, \mu_{k'}) dist(xi,μk′)。
- 将 x i x_i xi指派到距离最近的簇中心: z i = argmin k ′ dist ( x i , μ k ′ ) z_i = \text{argmin}{k'} \text{dist}(x_i, \mu{k'}) zi=argmink′dist(xi,μk′)。
- 使用当前的簇内点,重新计算 K K K个簇中心位置。
时间复杂度
- 第3步的时间复杂度为 O ( N K D ) O(NKD) O(NKD),其中 D D D是数据点的维度。
- 第7步的时间复杂度为 O ( N ) O(N) O(N)。
(2)K均值聚类运行示意
以下是K均值聚类算法的运行过程示意图,展示了算法在不同迭代次数下的变化情况:
在每次迭代中,算法首先随机选择 K K K个数据点作为初始簇中心(Iteration 1)。然后,算法将每个数据点指派到最近的簇中心(Iteration 2-3)。接着,算法根据当前的簇内点重新计算簇中心的位置(Iteration 4-5)。这个过程会不断重复,直到簇中心的位置不再发生变化(Iteration 6)。
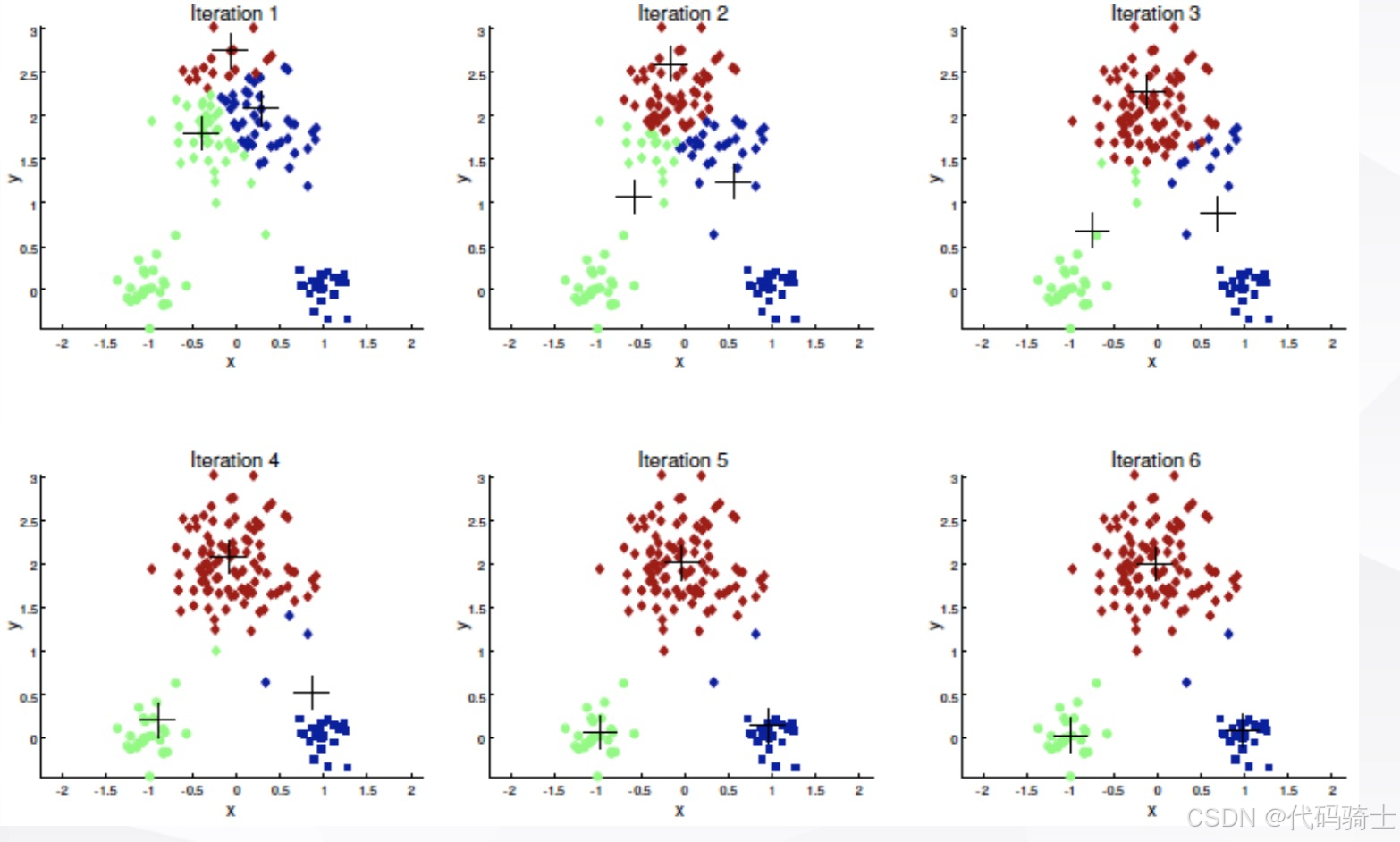
(3)K均值聚类的基本假设与优化目标
1、K均值聚类简介
K均值聚类是一种基于划分的聚类方法,也是一种基于中心的聚类方法。
2、如何表示簇?
每个簇都用其质心(centroid)或原型(prototype) μ k \mu_k μk表示。
3、如何划分节点?
- 采用欧氏距离作为距离度量。
- 每个节点都划分到距离其最近的那个质心的簇中。
- r i , k ∈ { 0 , 1 } r_{i,k} \in \{0,1\} ri,k∈{0,1} 为从属度,指示样本 x i x_i xi是否属于簇 k k k,且 ∑ k = 1 K r i , k = 1 \sum_{k=1}^{K} r_{i,k} = 1 ∑k=1Kri,k=1(每个样本点属于且仅属于一个类)。
4、目标函数
目标函数为 J = ∑ i = 1 N ∑ k = 1 K r i , k ∥ x i − μ k ∥ 2 J = \sum_{i=1}^{N} \sum_{k=1}^{K} r_{i,k} \|x_i - \mu_k\|^2 J=∑i=1N∑k=1Kri,k∥xi−μk∥2,即平方误差和(SSE)。
5、如何优化?
(1)最小化损失函数
如何最小化损失函数 J = ∑ i = 1 N ∑ k = 1 K r i , k ∥ x i − μ k ∥ 2 J = \sum_{i=1}^{N} \sum_{k=1}^{K} r_{i,k} \|x_i - \mu_k\|^2 J=∑i=1N∑k=1Kri,k∥xi−μk∥2?
(2)鸡生蛋、蛋生鸡问题(Chicken and egg problem)
- 如果中心点 μ k \mu_k μk已知,可以计算样本的类别归属 r i , k r_{i,k} ri,k;
- 如果样本的类别归属 r i , k r_{i,k} ri,k已知,可以计算中心点 μ k \mu_k μk。
(3)迭代求解(坐标轴下降法)
- 固定 μ k \mu_k μk,优化 r i , k r_{i,k} ri,k;
- 固定 r i , k r_{i,k} ri,k,优化 μ k \mu_k μk。
(4)初始化K个类中心: μ k \mu_k μk
迭代求解
- 固定 μ k \mu_k μk,最小化 J ( r i , k ) J(r_{i,k}) J(ri,k):分配每个样本点到其最近的中心点所在的簇
z i = argmin k dist ( x i , μ k ′ ) { r i , k = 1 , k = z i r i , k = 0 , k ≠ z i z_i = \text{argmin}k \text{dist}(x_i, \mu{k'}) \\ \begin{cases} r_{i,k} = 1, & k = z_i \\ r_{i,k} = 0, & k \neq z_i \end{cases} zi=argminkdist(xi,μk′){ri,k=1,ri,k=0,k=zik=zi - 固定 r i , k r_{i,k} ri,k,最小化 J ( μ k ) J(\mu_k) J(μk): μ k \mu_k μk为簇中所有样本的中心/均值:
μ k = ∑ i r i , k x i ∑ i r i , k \mu_k = \frac{\sum_i r_{i,k} x_i}{\sum_i r_{i,k}} μk=∑iri,k∑iri,kxi
(4)K-means算法的收敛性
1、K-means是在目标函数上进行坐标轴下降优化
- 目标函数 J J J单调下降,所以目标函数值会收敛,因此聚类结果也会收敛。
- K-means有可能在不同聚类结果间震荡,但在实际中较少发生。
- J J J是非凸的,所以目标函数 J J J上应用坐标下降法不能保证收敛到全局的最小值。一个常见的方法是运行K-means多次,选择最好的结果。
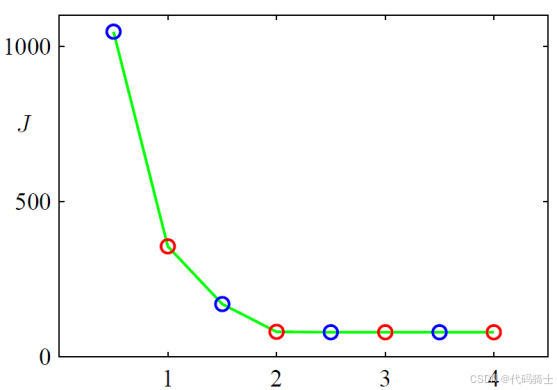
(纵轴:目标函数;横轴:迭代次数)
在Scikit-Learn中,KMeans的构造函数中参数n_init可设置重复次数,默认值为10,即以10种不同的质心初始化,执行10次聚类,然后返回10次聚类的最好结果(损失函数最小)。
python
class sklearn.cluster.KMeans(n_clusters=8, *, init='k-means++', n_init=10,
max_iter=300, tol=0.0001, verbose=0, random_state=None, copy_x=True,
algorithm='lloyd')(5)K的选择
1、训练集上K越大,目标函数值越小
方法
- 非监督学习/聚类通常是监督学习任务的一部分,用监督学习任务验证集上的评价指标选择K。
- 聚类评价指标
- 肘部法
- 假设检验法
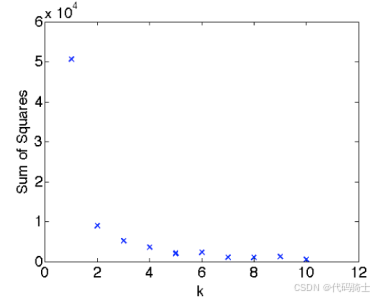
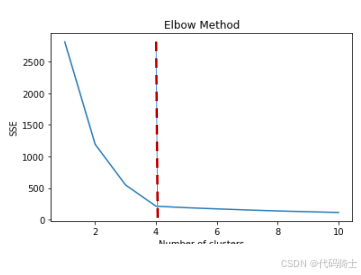
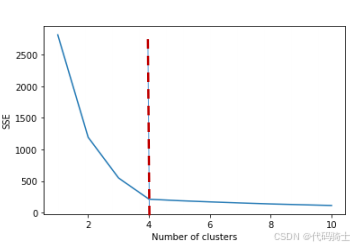
2、K的选择------肘部法
寻找估计目标函数风险急剧下降的地方:
- 令 J K J_K JK表示聚成K个簇的经验风险(目标函数值)。
- 寻找第一个K,使得 J K − J K + 1 J_K - J_{K+1} JK−JK+1的改进很小,这个位置称为肘部。
- 给定一个较小的数值 α > 0 \alpha > 0 α>0,定义
K α = min { k : J k − J k + 1 σ 2 ≤ α } K_\alpha = \min \left\{ k : \frac{J_k - J_{k+1}}{\sigma^2} \leq \alpha \right\} Kα=min{k:σ2Jk−Jk+1≤α}
其中 σ 2 = E ∥ X − μ ∥ 2 \sigma^2 = \mathbb{E}\\\|X - \\mu\\\|\^2 σ2=E∥X−μ∥2, μ = E X \mu = \mathbb{E}X μ=EX。 - 实际应用中, σ 2 \sigma^2 σ2用估计 σ ^ 2 = 1 / N ∑ i = 1 N ∥ x i − x ˉ ∥ 2 \hat{\sigma}^2 = 1/N \sum_{i=1}^N \|x_i - \bar{x}\|^2 σ^2=1/N∑i=1N∥xi−xˉ∥2, x ˉ = 1 / N ∑ i = 1 N x i \bar{x} = 1/N \sum_{i=1}^N x_i xˉ=1/N∑i=1Nxi。
- 不过真正应用中,肘部的位置可能并不明显。
3、K的选择------假设检验法
一种更正式的方式是采用假设检验
- 对每个K,我们进行假设检验:
- 原假设 H 0 H_0 H0:簇的数目为K
- 备择假设 H 1 H_1 H1:簇的数目不为K
- 从 K = 1 K = 1 K=1开始,如果拒绝 H 0 H_0 H0,则继续对 K = 2 K = 2 K=2进行假设检验,直到接受原假设。即K为第一个不被拒绝的假设。
- 假设检验:检验每个簇的分布是否为一个多元正态分布。
- 如果不是,将簇分裂成2个簇。
4、补充:p值(p value)
p值:在原假设成立条件下,事件发生的概率
- 如果事件发生的概率太低(小于愿承受犯第一类错误的概率),则选择拒绝原假设,即认为备择假设是对的。
- p值很小,说明在原假设情况下,事情发生的概率很小;如果出现了,根据小概率原理,我们就有理由拒绝原假设,p值越小,我们拒绝原假设的理由越充分。
5、K的选择------假设检验法示例
示例:K的选择------假设检验法
上图展示了两种不同的数据分布情况及其对应的p值分布图。对于上图中的数据分布,假设检验法选择的簇数为1,因为p value大于0.05的 K = 1 K = 1 K=1;对于下图中的数据分布,假设检验法选择的簇数为3,因为p value大于0.05的 K = 3 K = 3 K=3。

(6)如何初始化K-means?
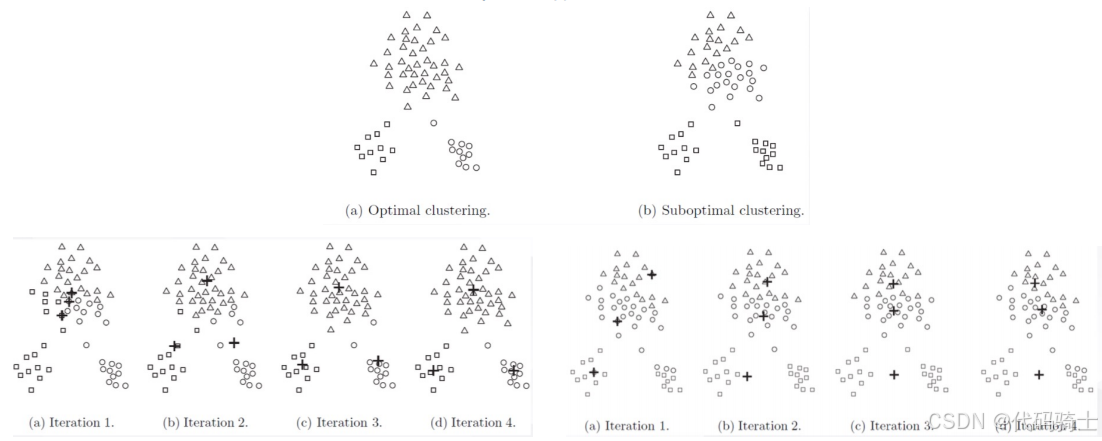
1、不同初始点的选择
下图展示了不同初始点选择对K-means聚类结果的影响。左图展示了聚类结果较好的情况,而右图展示了聚类结果较差的情况。
2、一些启发式做法
即便存在K个真实的簇,正好选到K个簇的中心的机会也很小。以下是一些启发式做法:
- 随机确定第一个类的中心,其他类中心的位置尽量远离已有类中心。
- 在Scikit-Learn中,K-means实现中参数
init可设置初始值的设置方式,默认值为'k-means++',将初始化质心彼此远离,得到比随机初始化更好的结果。
python
class sklearn.cluster.KMeans(n_clusters=8, *, init='k-means++', n_init=10,
max_iter=300, tol=0.0001, verbose=0, random_state=None, copy_x=True,
algorithm='lloyd')(7)k-means++
1、算法步骤
给定数据集 D = { x 1 , x 2 , . . . , x N } D = \{x_1, x_2, ..., x_N\} D={x1,x2,...,xN},簇数目为K,算法步骤如下:
- 从 D = { x 1 , x 2 , . . . , x N } D = \{x_1, x_2, ..., x_N\} D={x1,x2,...,xN}随机选择1个样本点,作为 μ 1 \mu_1 μ1, u = { μ 1 } u = \{\mu_1\} u={μ1};
- 对于 k = 2 , 3 , . . . , K k = 2, 3, ..., K k=2,3,...,K
- 对于每个 x i ∈ D x_i \in D xi∈D,计算 x i x_i xi与已有簇中心的最短距离: D ( x i ) = min μ ∈ u dist ( x i , μ ) D(x_i) = \min_{\mu \in u} \text{dist}(x_i, \mu) D(xi)=minμ∈udist(xi,μ);
- 以概率 p i = ( D ( x i ) ) 2 ∑ j = 1 N ( p ( x j ) ) 2 p_i = \frac{(D(x_i))^2}{\sum_{j=1}^N (p(x_j))^2} pi=∑j=1N(p(xj))2(D(xi))2抽取样本点 x i x_i xi;
- 将这个随机抽样得到的样本点作为第k个初试的簇中心 μ k : u = u ∪ { μ k } \mu_k : u = u \cup \{\mu_k\} μk:u=u∪{μk};
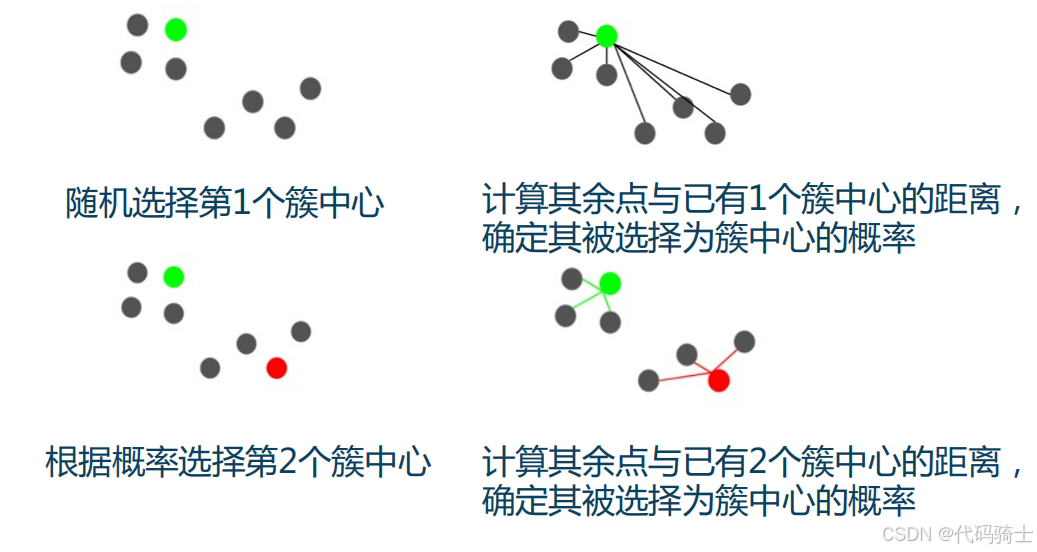
上图展示了"k-means++"法选择簇中心的过程。首先随机选择第一个簇中心,然后计算其余点与已有1个簇中心的距离,确定其被选择为簇中心的概率。接着根据概率选择第二个簇中心,并计算其余点与已有2个簇中心的距离,确定其被选择为簇中心的概率。
(8)预处理和后处理
1、预处理
在进行K-means聚类之前,通常需要进行一些预处理步骤,以提高聚类的效果和准确性:
- 特征缩放(例如,缩放到0均值单位标准差)
- 删除离群点
2、后处理
聚类完成后,可以进行一些后处理步骤来优化聚类结果:
- 删除小的簇:可能代表离群点
- 分裂松散的簇:簇内节点间距离之和很高
- 合并距离较近的簇
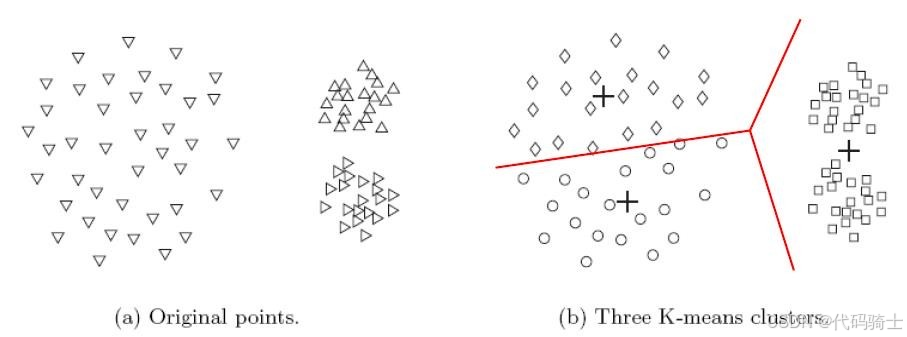
(9)K-means的局限性
1、K-means存在的问题
K-means算法在处理具有不同尺寸、密度和非球形的簇时可能会遇到问题,导致得不到理想的聚类结果。
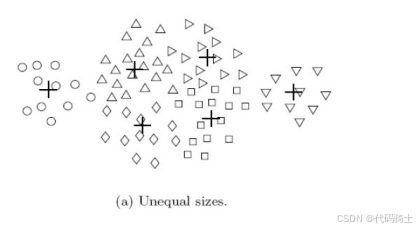
2、K-means的局限性:不同的尺寸
下图展示了K-means在处理不同尺寸簇时的局限性。尽管原始数据中存在三个明显的簇,但由于尺寸差异,K-means算法只能识别出两个簇。

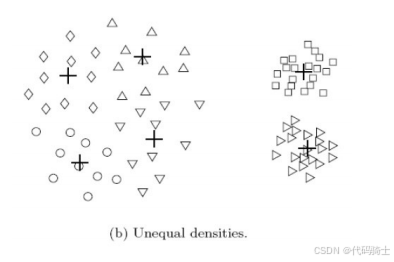
3、K-means的局限性:不同的密度
下图展示了K-means在处理不同密度簇时的局限性。尽管原始数据中存在三个明显的簇,但由于密度差异,K-means算法只能识别出两个簇。
4、K-means的局限性:非凸的形状
下图展示了K-means在处理非凸形状簇时的局限性。尽管原始数据中存在两个明显的簇,但由于形状复杂,K-means算法只能识别出一个簇。
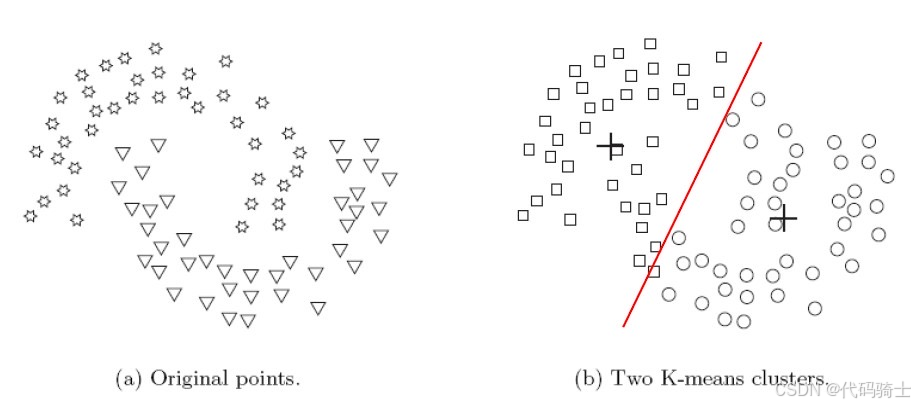
(10)克服K-means的局限性
1、使用更大量的簇
为了克服K-means在处理不同尺寸、密度和非球形簇时的局限性,可以使用更大量的簇,用几个小的簇表示一个真实的簇。
2、使用基于密度的方法
另一种方法是使用基于密度的聚类方法,如DBSCAN,这些方法可以更好地处理不同密度和非球形的簇。
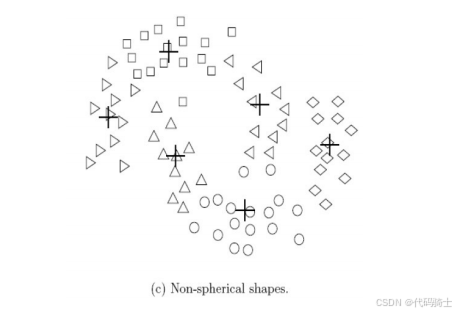
3、离群点带来的问题
K-means容易受到离群点的影响,因为离群点可能会被错误地分配到簇中,从而影响整个簇的中心。
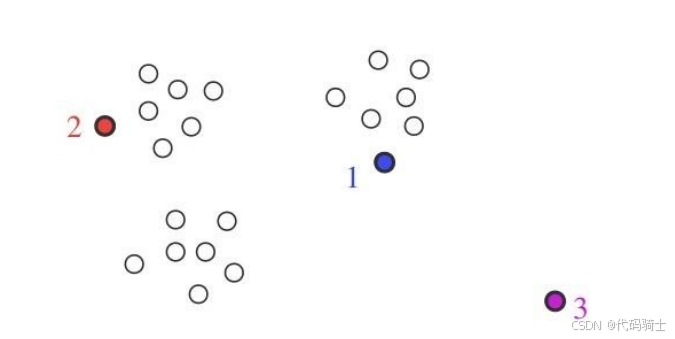
(11)K-medoids
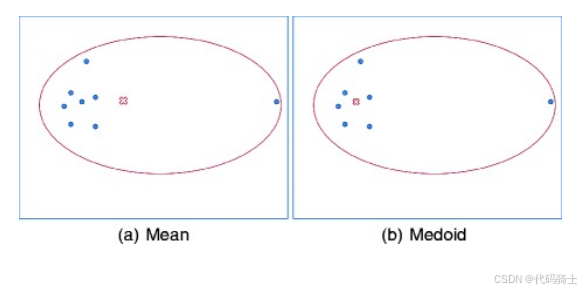
1、中值作为中心
均值作为中心易受影响,换用簇的中值点(median)作为中心可以提高聚类的鲁棒性。
- 均值可能是一个不存在的样本点,不足以代表该簇中的样本,而中值是一个样本集合中真实存在的一个样本点。
- 相对均值而言,中值对噪声(孤立点、离群点)不那么敏感。
- 但中值计算需要对簇内所有样本进行排序,计算费用高。
2、非向量空间的聚类
对于K-means聚类算法,数据必须在某个向量空间,这样欧氏距离是一个很自然的相似性度量。
- 也可以采用类似核函数 k ( x i , x k ) k(x_i, x_k) k(xi,xk)度量样本之间的相似性,然后基于这种相似性进行聚类。
(12)K-means聚类的优点
尽管K-means有其局限性,但它也有一些显著的优点:
- 一种经典的聚类算法,简单、快速。
- 能处理大规模数据,可扩展型好。
- 当簇接近高斯分布时,效果较好。
(13)K-means的局限性
K-means算法在某些情况下可能无法得到理想的聚类结果:
- 硬划分数据点到簇,当数据上出现一些小的扰动,可能导致一个点划分到另外的簇。
- 假定簇为球形且每个簇的概率相等。
- 解决方案:高斯混合模型。
2、高斯混合模型和EM算法
(1)多元高斯分布
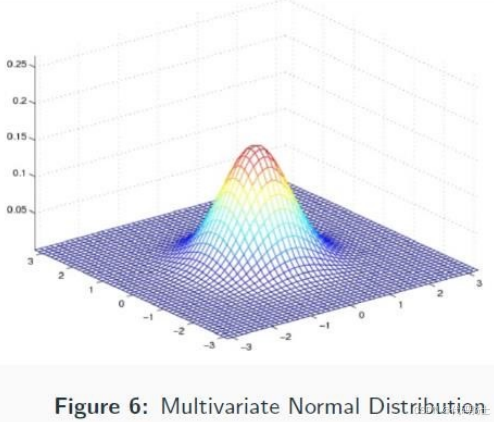
图中展示了多元高斯分布的概率密度函数。多元高斯分布的概率密度函数公式如下:
x ∼ N ( μ , Σ ) x \sim N(\mu, \Sigma) x∼N(μ,Σ)
p ( x ) = 1 ( 2 π ) D 2 ∣ Σ ∣ 1 2 e − 1 2 ( x − μ ) T Σ − 1 ( x − μ ) p(x) = \frac{1}{(2\pi)^{\frac{D}{2}}|\Sigma|^{\frac{1}{2}}} e^{-\frac{1}{2}(x-\mu)^{\mathrm{T}}\Sigma^{-1}(x-\mu)} p(x)=(2π)2D∣Σ∣211e−21(x−μ)TΣ−1(x−μ)
(2)高斯混合模型
高斯混合模型是一种概率模型,它假设数据由 K K K个高斯分布组成。每个高斯分布以概率 π k \pi_k πk被随机选择,从其分布中采样出一个样本点,从而得到观测数据。概率密度函数如下:
p ( x ) = ∑ k = 1 K π k N ( x ∣ μ k , Σ k ) where ∑ k = 1 K π k = 1 , 0 ≤ π k ≤ 1 p(x) = \sum_{k=1}^{K} \pi_k N(x|\mu_k, \Sigma_k) \quad \text{where} \quad \sum_{k=1}^{K} \pi_k = 1, \quad 0 \leq \pi_k \leq 1 p(x)=k=1∑KπkN(x∣μk,Σk)wherek=1∑Kπk=1,0≤πk≤1
模型参数为:
θ = ( π 1 , . . . , π K , μ 1 , . . . , μ K , Σ 1 , . . . , Σ K ) T \theta = (\pi_1, ..., \pi_K, \mu_1, ..., \mu_K, \Sigma_1, ..., \Sigma_K)^{\mathrm{T}} θ=(π1,...,πK,μ1,...,μK,Σ1,...,ΣK)T
(3)引入隐含变量
为了每个样本点 x x x关联一个 K K K维的隐含变量 z = ( z 1 , z 2 , . . . , z K ) z = (z_1, z_2, ..., z_K) z=(z1,z2,...,zK),指示样本 x x x所属的簇(独热编码,所属簇的指示向量),其对应的随机向量用大写字母 Z Z Z表示:
P ( Z k = 1 ) = π k P(Z_k = 1) = \pi_k P(Zk=1)=πk
如果已知 z z z的取值,如 x x x属于第 k k k簇,则:
p ( x ∣ Z k = 1 ) = N ( x ∣ μ k , Σ k ) p(x|Z_k = 1) = N(x|\mu_k, \Sigma_k) p(x∣Zk=1)=N(x∣μk,Σk)
因此,概率密度函数可以表示为:
p ( x ) = ∑ z p ( x , z ) = ∑ z p ( x ∣ z ) p ( z ) = ∑ k = 1 K p ( x ∣ Z k = 1 ) P ( Z k = 1 ) p(x) = \sum_z p(x, z) = \sum_z p(x|z)p(z) = \sum_{k=1}^{K} p(x|Z_k = 1)P(Z_k = 1) p(x)=z∑p(x,z)=z∑p(x∣z)p(z)=k=1∑Kp(x∣Zk=1)P(Zk=1)
= ∑ k = 1 K π k N ( x ∣ μ k , Σ k ) = \sum_{k=1}^{K} \pi_k N(x|\mu_k, \Sigma_k) =k=1∑KπkN(x∣μk,Σk)
(4)混合高斯模型的学习过程困难
参数估计:极大似然估计,最大化对数似然(log likelihood):
X = ( x 1 , x 2 , . . . , x N ) 为所有训练样本集合 X = (x_1, x_2, ..., x_N) \quad \text{为所有训练样本集合} X=(x1,x2,...,xN)为所有训练样本集合
l ( θ ∣ X ) = ln ( p ( X ∣ θ ) ) = ∑ i = 1 N ln ( p ( x i ∣ θ ) ) l(\theta|X) = \ln(p(X|\theta)) = \sum_{i=1}^{N} \ln(p(x_i|\theta)) l(θ∣X)=ln(p(X∣θ))=i=1∑Nln(p(xi∣θ))
= ∑ i = 1 N ln ( ∑ k = 1 K π k N ( x i ∣ μ k , Σ k ) ) = \sum_{i=1}^{N} \ln \left( \sum_{k=1}^{K} \pi_k N(x_i|\mu_k, \Sigma_k) \right) =i=1∑Nln(k=1∑KπkN(xi∣μk,Σk))
上述函数优化很困难:
- ln \ln ln里有求和,导致求导困难,所有参数耦合在一起
(5)求解方法:EM (Expectation-Maximization) 算法
EM算法是一种迭代算法,用于在存在隐变量的情况下寻找概率模型参数的最大似然估计。EM算法分为两个步骤:E步(期望步)和M步(最大化步)。
1、E步:计算隐变量的期望
基于当前参数值 θ old \theta^{\text{old}} θold,推断隐含变量 z i z_i zi的信息(后验概率/期望):
r i , k = E ( Z i , k ) = P ( Z i , k = 1 ∣ x i , θ old ) = P ( Z i , k = 1 ) p ( x i ∣ Z i , k = 1 ) ∑ k ′ = 1 K P ( Z i , k ′ = 1 ) p ( x i ∣ Z i , k ′ = 1 ) r_{i,k} = \mathbb{E}(Z_{i,k}) = P(Z_{i,k} = 1|x_i, \theta^{\text{old}}) = \frac{P(Z_{i,k} = 1)p(x_i|Z_{i,k} = 1)}{\sum_{k'=1}^{K} P(Z_{i,k'} = 1)p(x_i|Z_{i,k'} = 1)} ri,k=E(Zi,k)=P(Zi,k=1∣xi,θold)=∑k′=1KP(Zi,k′=1)p(xi∣Zi,k′=1)P(Zi,k=1)p(xi∣Zi,k=1)
= π k old N ( x i ∣ μ k old , Σ k old ) ∑ k ′ = 1 K π k ′ old N ( x i ∣ μ k ′ old , Σ k ′ old ) = \frac{\pi_k^{\text{old}} \mathcal{N}(x_i|\mu_k^{\text{old}}, \Sigma_k^{\text{old}})}{\sum_{k'=1}^{K} \pi_{k'}^{\text{old}} \mathcal{N}(x_i|\mu_{k'}^{\text{old}}, \Sigma_{k'}^{\text{old}})} =∑k′=1Kπk′oldN(xi∣μk′old,Σk′old)πkoldN(xi∣μkold,Σkold)
r i , k r_{i,k} ri,k可以看作是对 x i x_i xi从属于第 k k k个簇的一种估计或者"解释"。
2、M步:重新估计参数
基于当前的期望 r i , k r_{i,k} ri,k,重新估计参数的值 π k \pi_k πk、 μ k \mu_k μk、 Σ k \Sigma_k Σk:
π k new = ∑ i r i , k N , μ k new = ∑ i r i , k x i ∑ i r i , k , Σ k new = ∑ i r i , k ( x i − μ k ) ( x i − μ k ) T ∑ i r i , k \pi_k^{\text{new}} = \frac{\sum_i r_{i,k}}{N}, \quad \mu_k^{\text{new}} = \frac{\sum_i r_{i,k} x_i}{\sum_i r_{i,k}}, \quad \Sigma_k^{\text{new}} = \frac{\sum_i r_{i,k} (x_i - \mu_k)(x_i - \mu_k)^{\mathrm{T}}}{\sum_i r_{i,k}} πknew=N∑iri,k,μknew=∑iri,k∑iri,kxi,Σknew=∑iri,k∑iri,k(xi−μk)(xi−μk)T
(6)通用的EM算法
EM算法的通用步骤如下:
- 写出完整数据的对数似然函数: ln ( p ( X , Z ∣ θ ) ) \ln(p(X, Z|\theta)) ln(p(X,Z∣θ))
- 初始化参数 θ old \theta^{\text{old}} θold
- E步:计算隐含变量的后验: p ( Z ∣ X , θ old ) p(Z|X, \theta^{\text{old}}) p(Z∣X,θold)
- M步:计算 θ new \theta^{\text{new}} θnew: θ new = arg max θ Q ( θ , θ old ) \theta^{\text{new}} = \arg\max_{\theta} Q(\theta, \theta^{\text{old}}) θnew=argmaxθQ(θ,θold)
- 其中 Q ( θ , θ old ) = ∑ Z p ( Z ∣ X , θ old ) ln ( p ( X , Z ∣ θ ) ) Q(\theta, \theta^{\text{old}}) = \sum_Z p(Z|X, \theta^{\text{old}}) \ln(p(X, Z|\theta)) Q(θ,θold)=∑Zp(Z∣X,θold)ln(p(X,Z∣θ))
- 检查似然函数或者参数的值是否收敛,如果没有达到收敛条件,则令 θ old ← θ new \theta^{\text{old}} \leftarrow \theta^{\text{new}} θold←θnew,转E步。
(7)EM for GMM
对于高斯混合模型(GMM),完整数据的对数似然函数为:
ln ( p ( X , Z ∣ θ ) ) = ∑ i = 1 N ∑ k = 1 K z i , k ( ln ( π k ) + ln ( N ( x i ∣ μ k , Σ k ) ) ) \ln(p(X, Z|\theta)) = \sum_{i=1}^{N} \sum_{k=1}^{K} z_{i,k} (\ln(\pi_k) + \ln(\mathcal{N}(x_i|\mu_k, \Sigma_k))) ln(p(X,Z∣θ))=i=1∑Nk=1∑Kzi,k(ln(πk)+ln(N(xi∣μk,Σk)))
- 与不完整数据的对数似然函数对比: ln ( p ( X ∣ θ ) ) = ∑ i = 1 N ln ( ∑ k = 1 K π k N ( x i ∣ μ k , Σ k ) ) \ln(p(X|\theta)) = \sum_{i=1}^{N} \ln \left( \sum_{k=1}^{K} \pi_k \mathcal{N}(x_i|\mu_k, \Sigma_k) \right) ln(p(X∣θ))=∑i=1Nln(∑k=1KπkN(xi∣μk,Σk))
- 参数 π k \pi_k πk和 ( μ k , Σ k ) (\mu_k, \Sigma_k) (μk,Σk)解耦合,存在平凡的封闭解
M步目标函数:
Q ( θ , θ old ) = E Z ∣ X ln ( p ( X , Z ∣ θ ) ) Q(\theta, \theta^{\text{old}}) = \mathbb{E}_{Z|X}\\ln(p(X, Z\|\\theta)) Q(θ,θold)=EZ∣Xln(p(X,Z∣θ))
= ∑ i = 1 N ∑ k = 1 K E Z ∣ X ( z i , k ) ( ln ( π k ) + ln ( N ( x i ∣ μ k , Σ k ) ) ) = \sum_{i=1}^{N} \sum_{k=1}^{K} \mathbb{E}{Z|X}(z{i,k})(\ln(\pi_k) + \ln(\mathcal{N}(x_i|\mu_k, \Sigma_k))) =i=1∑Nk=1∑KEZ∣X(zi,k)(ln(πk)+ln(N(xi∣μk,Σk)))
= ∑ i = 1 N ∑ k = 1 K r i , k ( ln ( π k ) + ln ( N ( x i ∣ μ k , Σ k ) ) ) = \sum_{i=1}^{N} \sum_{k=1}^{K} r_{i,k} (\ln(\pi_k) + \ln(\mathcal{N}(x_i|\mu_k, \Sigma_k))) =i=1∑Nk=1∑Kri,k(ln(πk)+ln(N(xi∣μk,Σk)))
(8)通用EM算法
EM算法是一种寻找含有隐含变量的概率模型的最大似然解的通用技术。我们通过这种启发式的方式推导出EM算法,但实际上是在最大化似然函数。
θ new = arg max θ Q ( θ , θ old ) ⇒ θ = arg max θ p ( X , θ ) \theta^{\text{new}} = \arg\max_{\theta} Q(\theta, \theta^{\text{old}}) \quad \Rightarrow \quad \theta = \arg\max_{\theta} p(X, \theta) θnew=argθmaxQ(θ,θold)⇒θ=argθmaxp(X,θ)
1、目标:最大化
E步:根据参数的当前值 θ \theta θ和观测 X X X,计算隐含变量 Z Z Z的隐含分布 q q q:
q ( z ) = p ( z ∣ X , θ ) q(z) = p(z|X, \theta) q(z)=p(z∣X,θ)
M步:最大化 ln ( p ( X , Z ∣ θ ) ) \ln(p(X, Z|\theta)) ln(p(X,Z∣θ))的期望,其中期望在E步得到的分布 q q q下进行:
θ = arg max θ E q ln ( p ( X , Z ∣ θ ) ) \theta = \arg\max_{\theta} \mathbb{E}_q\\ln(p(X, Z\|\\theta)) θ=argθmaxEqln(p(X,Z∣θ))
(9)证据下界(Evidence Lower Bound, ELBO)
ln ( p ( X ∣ θ ) ) \ln(p(X|\theta)) ln(p(X∣θ))的表达式为:
ln ( p ( X ∣ θ ) ) = ln ( ∫ p ( X , Z = z ∣ θ ) d z ) \ln(p(X|\theta)) = \ln \left( \int p(X, Z = z|\theta) dz \right) ln(p(X∣θ))=ln(∫p(X,Z=z∣θ)dz)
= ln ( ∫ q ( z ) p ( X , Z = z ∣ θ ) q ( z ) d z ) = \ln \left( \int q(z) \frac{p(X, Z = z|\theta)}{q(z)} dz \right) =ln(∫q(z)q(z)p(X,Z=z∣θ)dz)
≥ ∫ q ( z ) ln ( p ( X , Z = z ∣ θ ) q ( z ) ) d z (Jensen不等式) \geq \int q(z) \ln \left( \frac{p(X, Z = z|\theta)}{q(z)} \right) dz \quad \text{(Jensen不等式)} ≥∫q(z)ln(q(z)p(X,Z=z∣θ))dz(Jensen不等式)
ELBO = ∫ q ( z ) ln ( p ( X , Z = z ∣ θ ) q ( z ) ) d z \text{ELBO} = \int q(z) \ln \left( \frac{p(X, Z = z|\theta)}{q(z)} \right) dz ELBO=∫q(z)ln(q(z)p(X,Z=z∣θ))dz
Jensen不等式:当函数 g ( ln ) g(\ln) g(ln)是凸函数时, g ( E y ) ≥ E g ( y ) g(\mathbb{E}y) \geq \mathbb{E}g(y) g(Ey)≥Eg(y)。 ln \ln ln函数是凸函数。
(10)Why E步?
ELBO的表达式为:
ELBO = ∫ q ( z ) ln ( p ( X , Z = z ∣ θ ) q ( z ) ) d z \text{ELBO} = \int q(z) \ln \left( \frac{p(X, Z = z|\theta)}{q(z)} \right) dz ELBO=∫q(z)ln(q(z)p(X,Z=z∣θ))dz
= ∫ q ( z ) ln ( p ( Z = z ∣ X , θ ) p ( X ∣ θ ) q ( z ) ) d z = \int q(z) \ln \left( \frac{p(Z = z|X, \theta)p(X|\theta)}{q(z)} \right) dz =∫q(z)ln(q(z)p(Z=z∣X,θ)p(X∣θ))dz
= ∫ q ( z ) ln ( p ( Z = z ∣ X , θ ) q ( z ) ) d z + ∫ q ( z ) ln ( p ( X ∣ θ ) ) d z = \int q(z) \ln \left( \frac{p(Z = z|X, \theta)}{q(z)} \right) dz + \int q(z) \ln(p(X|\theta)) dz =∫q(z)ln(q(z)p(Z=z∣X,θ))dz+∫q(z)ln(p(X∣θ))dz
= − D K L ( q ( z ) ∣ ∣ p ( Z = z ∣ X , θ ) ) + ln ( p ( X ∣ θ ) ) = -D_{KL}(q(z)||p(Z = z|X, \theta)) + \ln(p(X|\theta)) =−DKL(q(z)∣∣p(Z=z∣X,θ))+ln(p(X∣θ))
K L ( q ∣ ∣ p ) = − ∫ q ( z ) ln ( p ( Z = z ∣ X , θ ) q ( z ) ) d z ≥ 0 KL(q||p) = - \int q(z) \ln \left( \frac{p(Z = z|X, \theta)}{q(z)} \right) dz \geq 0 KL(q∣∣p)=−∫q(z)ln(q(z)p(Z=z∣X,θ))dz≥0
当E步中,取 q ( z ) = p ( Z = z ∣ X , θ ) q(z) = p(Z = z|X, \theta) q(z)=p(Z=z∣X,θ)时, K L ( q ∣ ∣ p ) = 0 KL(q||p) = 0 KL(q∣∣p)=0,ELBO = ln ( p ( X ∣ θ ) ) \ln(p(X|\theta)) ln(p(X∣θ))
(11)Why M步?
当 θ = θ old \theta = \theta^{\text{old}} θ=θold, q ( z ) = p ( Z = z ∣ X , θ old ) q(z) = p(Z = z|X, \theta^{\text{old}}) q(z)=p(Z=z∣X,θold)时:
ELBO = ∫ q ( z ) ln ( p ( X , Z = z ∣ θ ) q ( z ) ) d z \text{ELBO} = \int q(z) \ln \left( \frac{p(X, Z = z|\theta)}{q(z)} \right) dz ELBO=∫q(z)ln(q(z)p(X,Z=z∣θ))dz
= ∫ q ( z ) ln ( p ( X , Z = z ∣ θ ) ) d z − ∫ q ( z ) ln ( q ( z ) ) d z = \int q(z) \ln(p(X, Z = z|\theta)) dz - \int q(z) \ln(q(z)) dz =∫q(z)ln(p(X,Z=z∣θ))dz−∫q(z)ln(q(z))dz
最大化ELBO,等价于最大化:
Q ( θ , θ old ) = ∫ q ( z ) ln ( p ( X , Z = z ∣ θ ) ) d z Q(\theta, \theta^{\text{old}}) = \int q(z) \ln(p(X, Z = z|\theta)) dz Q(θ,θold)=∫q(z)ln(p(X,Z=z∣θ))dz
(12)EM算法的收敛性
ln ( p ( X ∣ θ new ) ) \ln(p(X|\theta^{\text{new}})) ln(p(X∣θnew))的表达式为:
ln ( p ( X ∣ θ new ) ) \ln(p(X|\theta^{\text{new}})) ln(p(X∣θnew))
= ln ( ∫ p ( X , Z = z ∣ θ new ) d z ) = \ln \left( \int p(X, Z = z|\theta^{\text{new}}) dz \right) =ln(∫p(X,Z=z∣θnew)dz)
= ln ( ∫ p ( X , Z = z ∣ θ new ) p ( Z = z ∣ X , θ old ) p ( Z = z ∣ X , θ old ) d z ) = \ln \left( \int \frac{p(X, Z = z|\theta^{\text{new}})p(Z = z|X, \theta^{\text{old}})}{p(Z = z|X, \theta^{\text{old}})} dz \right) =ln(∫p(Z=z∣X,θold)p(X,Z=z∣θnew)p(Z=z∣X,θold)dz)
≥ ∫ p ( Z = z ∣ X , θ old ) ln ( p ( X , Z = z ∣ θ new ) p ( Z = z ∣ X , θ old ) ) d z (Jensen不等式) \geq \int p(Z = z|X, \theta^{\text{old}}) \ln \left( \frac{p(X, Z = z|\theta^{\text{new}})}{p(Z = z|X, \theta^{\text{old}})} \right) dz \quad \text{(Jensen不等式)} ≥∫p(Z=z∣X,θold)ln(p(Z=z∣X,θold)p(X,Z=z∣θnew))dz(Jensen不等式)
= ∫ p ( Z = z ∣ X , θ old ) ln ( p ( X , Z = z ∣ θ new ) ) d z − ∫ p ( Z = z ∣ X , θ old ) ln ( p ( Z = z ∣ X , θ old ) ) d z = \int p(Z = z|X, \theta^{\text{old}}) \ln(p(X, Z = z|\theta^{\text{new}})) dz - \int p(Z = z|X, \theta^{\text{old}}) \ln(p(Z = z|X, \theta^{\text{old}})) dz =∫p(Z=z∣X,θold)ln(p(X,Z=z∣θnew))dz−∫p(Z=z∣X,θold)ln(p(Z=z∣X,θold))dz
≥ ∫ p ( Z = z ∣ X , θ old ) ln ( p ( X , Z = z ∣ θ old ) ) d z − ∫ p ( Z = z ∣ X , θ old ) ln ( p ( Z = z ∣ X , θ old ) ) d z \geq \int p(Z = z|X, \theta^{\text{old}}) \ln(p(X, Z = z|\theta^{\text{old}})) dz - \int p(Z = z|X, \theta^{\text{old}}) \ln(p(Z = z|X, \theta^{\text{old}})) dz ≥∫p(Z=z∣X,θold)ln(p(X,Z=z∣θold))dz−∫p(Z=z∣X,θold)ln(p(Z=z∣X,θold))dz
= ln ( p ( X ∣ θ old ) ) = \ln(p(X|\theta^{\text{old}})) =ln(p(X∣θold))
例:
下图展示了EM算法在不同迭代次数下对数据进行聚类的效果。
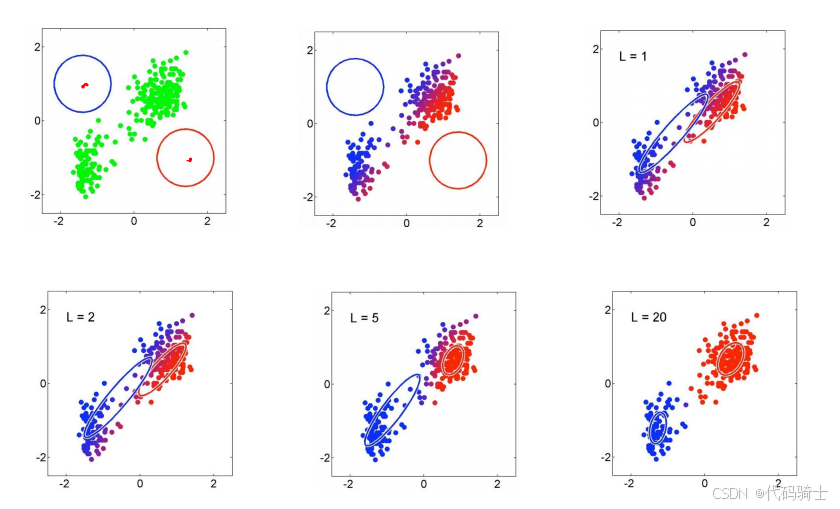
(13)高斯混合模型与K-means的关系
高斯混合模型的E步是一个软划分版本的K-means,其中 r i j k ∈ 0 , 1 r_{ijk} \in 0,1 rijk∈0,1。高斯混合模型的M步除了估计均值外,还估计协方差矩阵。
当所有 π k \pi_k πk相等, ∑ k = δ 2 I \sum_k = \delta^2 I ∑k=δ2I,当 δ 2 → 0 \delta^2 \rightarrow 0 δ2→0, r i k → { 0 , 1 } r_{ik} \rightarrow \{0, 1\} rik→{0,1},则两个方法是一致的。
(14)K-means vs 高斯混合模型(GMM)
K-Means
- 损失函数:最小化平方距离的和
- 样本点硬划分到某个簇
- 假定样本属于每个簇的概率相等,且为球形簇
GMM
- 最小化负对数似然
- 点到簇的从属关系为软分配
- 可以被用于椭圆形簇,且各个簇概率不同
3、层次聚类
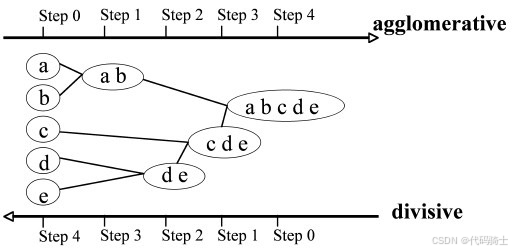
(1)层次聚类
产生树形嵌套的簇,可以被可视化为树状图(dendrogram)。树形的示意图,记录了簇合并或分割的序列。

(2)层次聚类的优点
- 不需要提前假定簇的数目
- 通过选择树状图的某一层可以获得任意簇数量的聚类结构
- 聚类结果可能对应着有意义的分类体系
- 例如在生物科学中(e.g., 门纲目科, 人类种系...)
(3)层次聚类方法
自底向上(凝聚式):递归地合并相似度最高/距离最近的两个簇
自顶向下(分裂式):递归地分裂最不一致的簇(例如:具有最大直径的簇)
用户可以在层次化的聚类中选择一个分割,得到一个最自然的聚类结果(例如:各个簇的簇间相似性高于一定阈值)
(4)凝聚式聚类算法
相较于分裂式,凝聚式是更加流行的层次聚类技术
基本算法非常直观:
- Compute the proximity matrix
- Let each data point be a cluster
- Repeat
4. Merge the two closest clusters
5. Update the proximity matrix
6. Until only a single cluster remains
关键是如何计算簇之间的相似度(proximity)→ 不同的定义簇间距离的方法,将得到不同的聚类算法
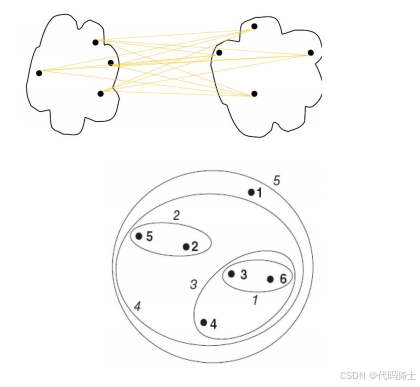
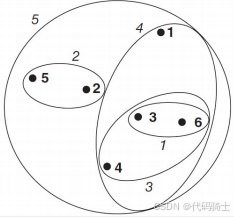
(5)层次聚类的起始状态
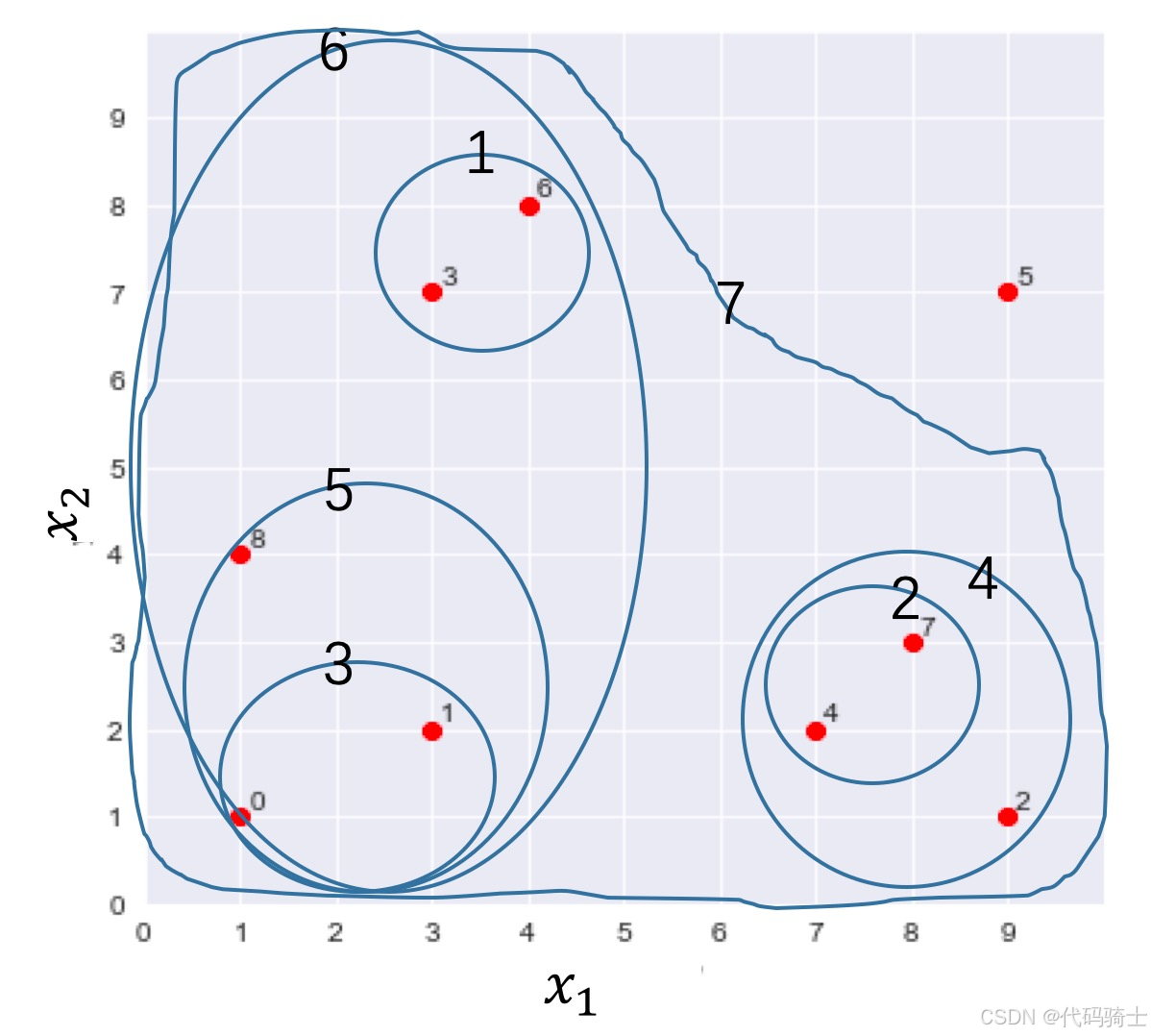
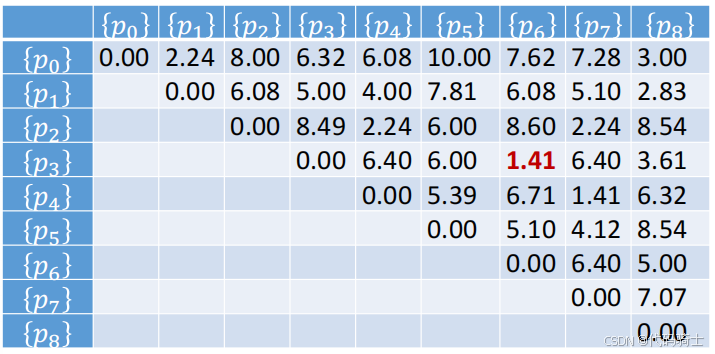
开始时每个点是一个簇,计算一个相似度矩阵。距离最短的两个簇为 { p 3 } \{p_3\} {p3}和 { p 6 } \{p_6\} {p6},因此合并二者为一个新的簇 { p 3 , p 6 } \{p_3, p_6\} {p3,p6},并删除原有的两个簇 { p 3 } \{p_3\} {p3}和 { p 6 } \{p_6\} {p6}。
(6)层次聚类的中间过程
经过一些合并步骤后,我们可以获得一些簇,更新簇间距离。
合并步骤1
合并 { p 3 } \{p_3\} {p3}和 { p 6 } \{p_6\} {p6}为一个新的簇 { p 3 , p 6 } \{p_3, p_6\} {p3,p6},并删除原有的两个簇 { p 3 } \{p_3\} {p3}和 { p 6 } \{p_6\} {p6}。此时表中距离最短的两个簇为 { p 4 } \{p_4\} {p4}和 { p 7 } \{p_7\} {p7}。
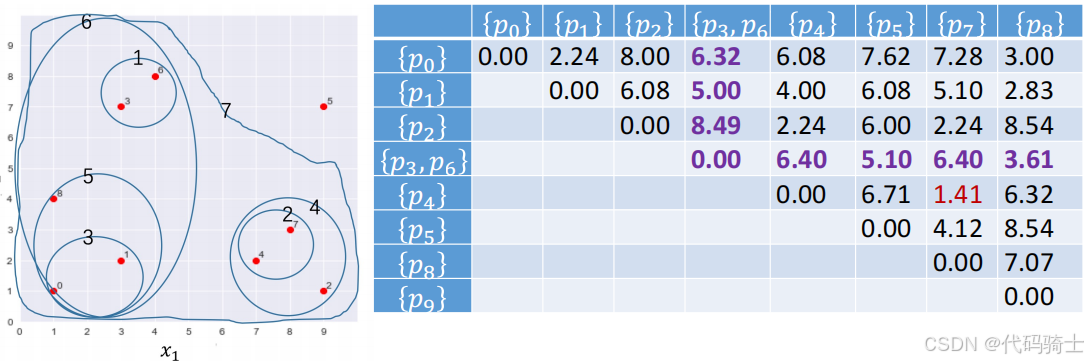
合并步骤2
合并 { p 4 } \{p_4\} {p4}和 { p 7 } \{p_7\} {p7}为一个新的簇 { p 4 , p 7 } \{p_4, p_7\} {p4,p7},并删除原有的两个簇 { p 4 } \{p_4\} {p4}和 { p 7 } \{p_7\} {p7}。此时表中距离最短的两个簇为 { p 0 } \{p_0\} {p0}和 { p 1 } \{p_1\} {p1}。
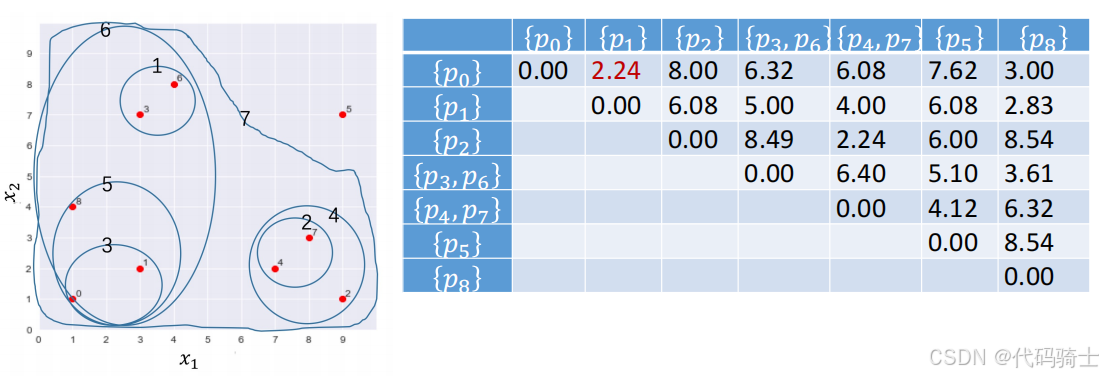
合并步骤3
合并 { p 0 } \{p_0\} {p0}和 { p 1 } \{p_1\} {p1}为一个新的簇 { p 0 , p 1 } \{p_0, p_1\} {p0,p1},并删除原有的两个簇 { p 0 } \{p_0\} {p0}和 { p 1 } \{p_1\} {p1}。此时表中距离最短的两个簇为 { p 2 } \{p_2\} {p2}和 { p 4 , p 7 } \{p_4, p_7\} {p4,p7}。
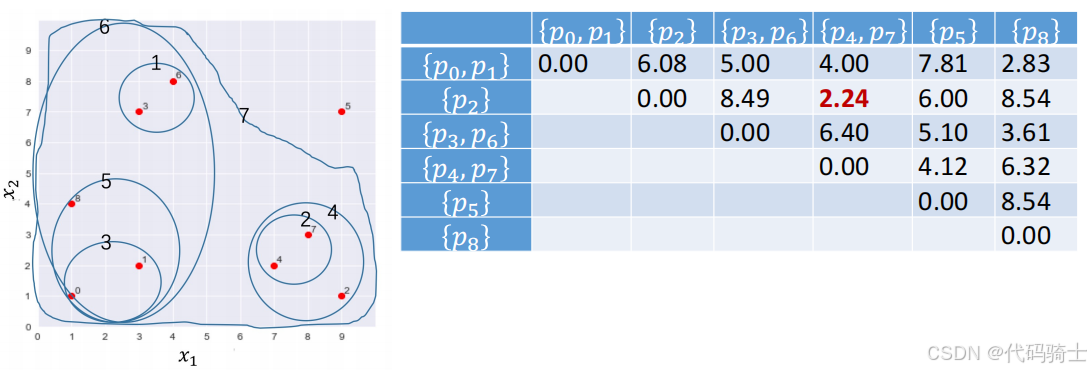
合并步骤4
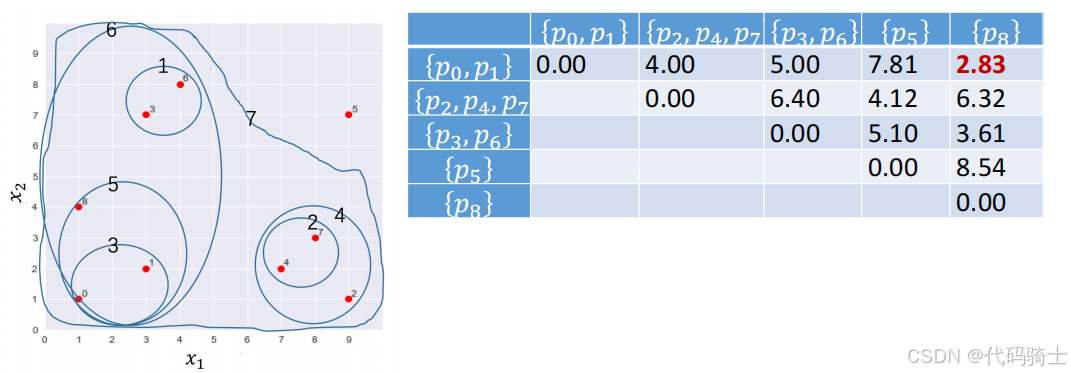
合并 { p 2 } \{p_2\} {p2}和 { p 4 , p 7 } \{p_4, p_7\} {p4,p7}为一个新的簇 { p 2 , p 4 , p 7 } \{p_2, p_4, p_7\} {p2,p4,p7},并删除原有的两个簇 { p 2 } \{p_2\} {p2}和 { p 4 , p 7 } \{p_4, p_7\} {p4,p7}。此时表中距离最短的两个簇为 { p 0 , p 1 } \{p_0, p_1\} {p0,p1}和 { p 8 } \{p_8\} {p8}。
(7)如何定义簇间相似性
在层次聚类中,定义簇间相似性是关键步骤之一。以下是几种常用的方法来衡量簇间的相似性:
- 最小距离 (MIN)
- 最大距离 (MAX)
- 平均距离 (Group Average)
- 中心点距离 (Distance Between Centroids)
- 其他由某种目标函数推导出来的方法
- Ward's 方法使用平方误差
这些方法可以帮助我们决定哪些簇应该首先被合并。每种方法都有其优势和潜在的问题。
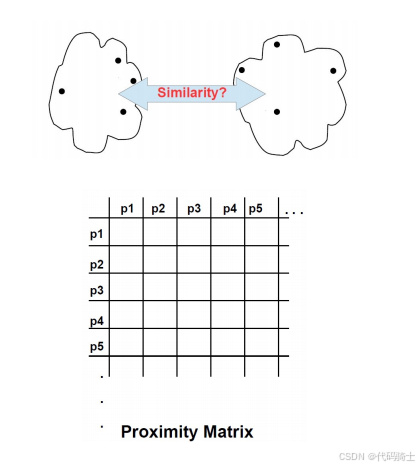
1、单链法 (Single Link)
- 最小距离 (MIN) (Single link)
- 最大距离 (MAX)
- 平均距离 (Group Average)
- 中心点距离 (Distance Between Centroids)
- 其他由某种目标函数推导出来的方法
- Ward's 方法使用平方误差
优势:可以形成非球形、非凸的簇。
问题 :链式效应,可能导致不合理的簇合并。

2、全链法 (Complete Link)
- 最小距离 (MIN)
- 最大距离 (MAX) (complete link)
- 平均距离 (Group Average)
- 中心点距离 (Distance Between Centroids)
- 其他由某种目标函数推导出来的方法
- Ward's 方法使用平方误差
优势:对噪声更加鲁棒(不成链)。
问题:趋向于拆开大的簇,偏好球形簇。

3、平均链法 (Average Linkage)
- 最小距离 (MIN)
- 最大距离 (MAX)
- 平均距离 (Group Average) (average-linkage)
- 中心点距离 (Distance Between Centroids)
- 其他由某种目标函数推导出来的方法
- Ward's 方法使用平方误差
MIN 和 MAX 的折中方案。
4、其他方法
- 最小距离 (MIN)
- 最大距离 (MAX)
- 平均距离 (Group Average)
- 中心点距离 (Distance Between Centroids)
- 其他由某种目标函数推导出来的方法
- Ward's 方法使用平方误差
问题 :反向效应(后边合并的簇间距离可能比之前合并的簇间距离更近)。

两个簇的相似性基于两个簇融合后平方误差的增加:
- 更少受噪声和离群点影响
- 倾向于球形簇
- K-means的层次化版本
- 可以用于初始化K-means
(8)层次聚类示例
以下是层次聚类在不同相似性度量下的效果对比:
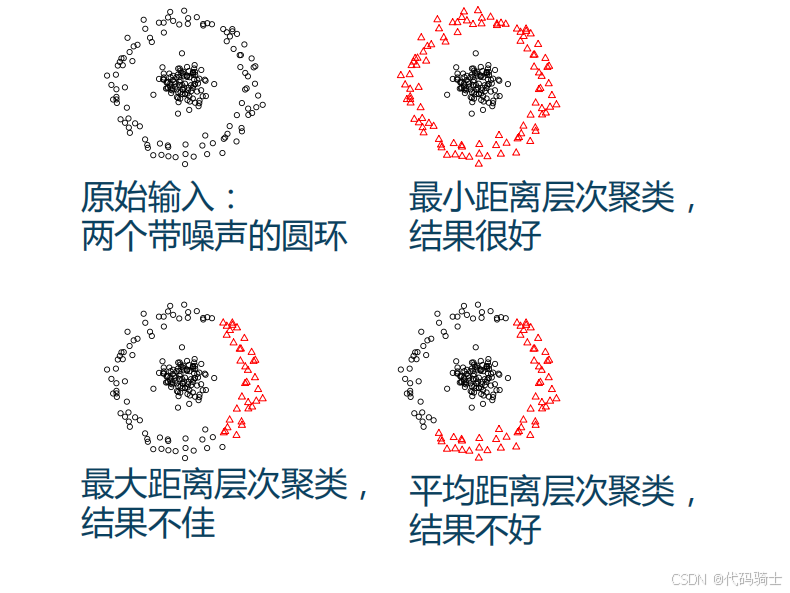
原始输入:两个带噪声的圆环
- 最小距离层次聚类,结果很好
- 最大距离层次聚类,结果不佳
- 平均距离层次聚类,结果不好
(9)层次聚类的簇数目确定
簇的数目可以通过树状图中垂直线的数量来确定,水平线切割垂直线。最佳簇的数目为4:树状图中的红色水平线覆盖了最大垂直距离AB。
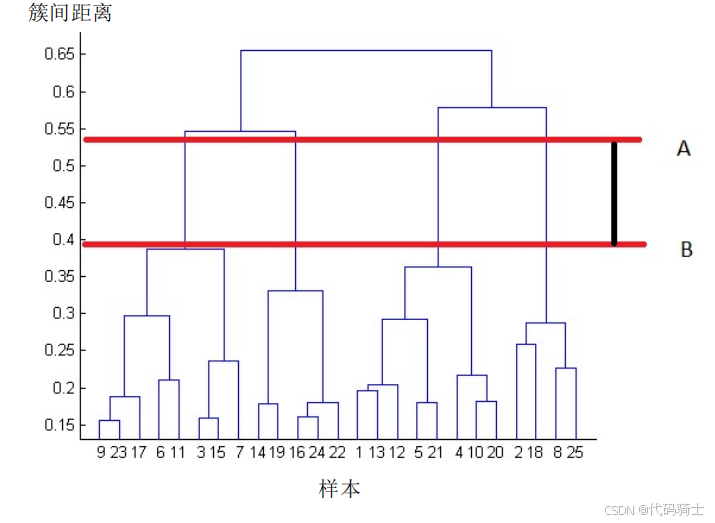
(10)层次聚类的限制
层次聚类算法有一些限制和挑战:
- 贪心:一旦簇被合并或者拆分,过程不可逆
- 没有优化一个全局的目标函数
- 不同方法存在以下一个或多个问题:
- 对噪声和离群点敏感(后来出现一些去除噪声的工作,与基于密度和图的聚类方法类似)
- 比较难处理不同尺寸的簇和凸的簇
- 成链,误把大簇分裂
Birch(平衡迭代削减聚类)算法:层次聚类算法的优化,能处理大数据集
4、基于密度的聚类
基于密度的聚类方法将邻近的高密度区域连接成簇。
优点:
- 能够识别各种大小、各种形状的簇
- 具有一定的抗噪音特性
(1)DBSCAN
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法,特别适用于含有噪声的数据集。
密度(Density)定义为:给定半径 ϵ \epsilon ϵ (epsilon)内点的个数。
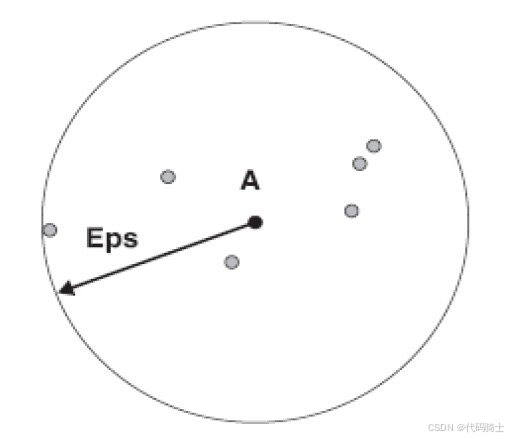
引用:Ester et al. A density-based algorithm for discovering clusters in large spatial databases with noise. Proceedings of the Second International Conference on Knowledge Discovery and Data Mining (KDD). 1996.
(2)预备知识
- 核心点 (Core point) :指定半径 ϵ \epsilon ϵ 内多于指定数量 M i n P t s MinPts MinPts 个点。
- 边界点 (Border point) :半径 ϵ \epsilon ϵ 内有少于 M i n P t s MinPts MinPts 个点,但在某个核心点的邻域内。
- 噪声点 (Outliers):核心点和边界点之外的点。
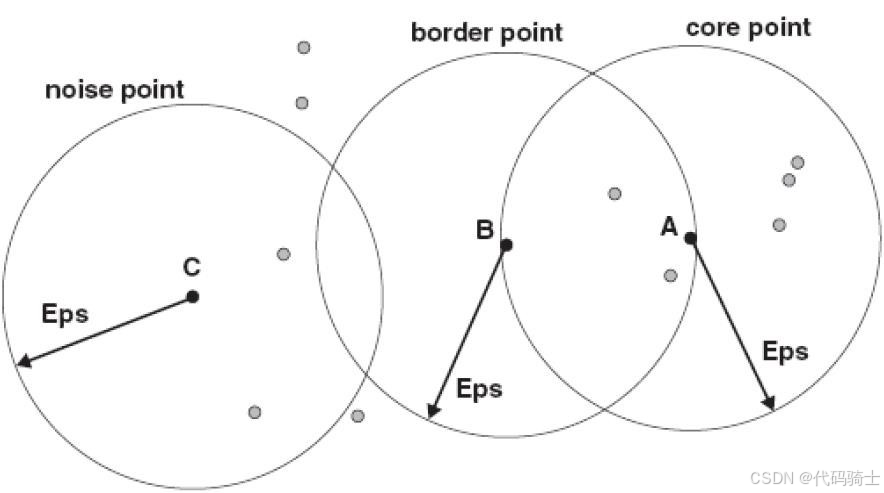
点 q q q 由点 p p p 密度可达:连接两个点的路径上所有的点都是核心点。
- 如果 p p p 是核心点,那么由它密度可达的点形成一个簇。
点 q q q 和点 p p p 是密度相连的,如果存在点 o o o 从其密度可达点 q q q 和点 p p p。
聚类的簇满足以下两个性质:
- 连接性:簇内的任意两点是密度相连的;
- 最大性 :如果一个点从一个簇中的任意一点密度可达,则该点属于该簇。
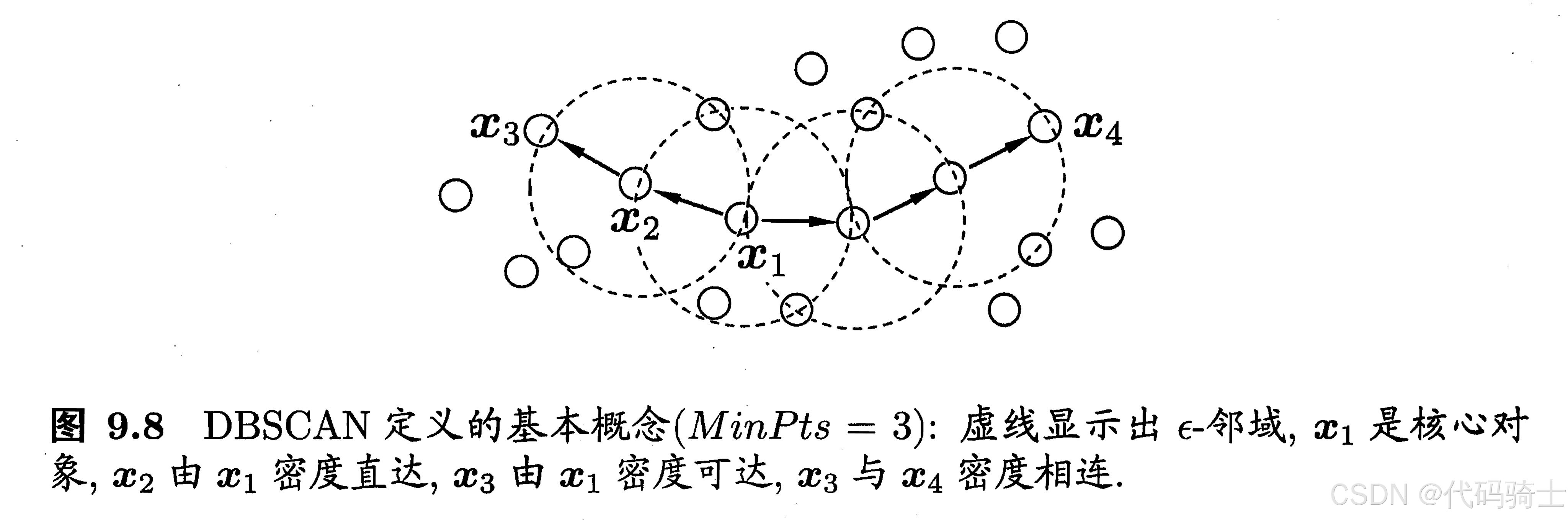
(3)DBSCAN 算法
DBSCAN 聚类
-
初始化核心点集合: Ω = ∅ \Omega = \varnothing Ω=∅;
-
确定核心点
- for i = 1 , 2 , ... , N i = 1, 2, \ldots, N i=1,2,...,N
- 确定样本点 x i x_i xi 的领域内的样本 N ϵ ( x i ) N_\epsilon(x_i) Nϵ(xi)
- if ∣ N ϵ ( x i ) ∣ ≥ M i n P t s |N_\epsilon(x_i)| \geq MinPts ∣Nϵ(xi)∣≥MinPts,
- 则将样本 x i x_i xi 将加入核心点集合: Ω = Ω ∪ { x i } \Omega = \Omega \cup \{x_i\} Ω=Ω∪{xi}
- end for
- for i = 1 , 2 , ... , N i = 1, 2, \ldots, N i=1,2,...,N
-
初始化簇的数目 K = 0 K = 0 K=0,未访问过的点集合 Γ = D \Gamma = \mathcal{D} Γ=D;
-
对所有核心点
- while Ω ≠ ∅ \Omega \neq \varnothing Ω=∅ do
- 记录当前未访问过的点的集合 Γ o l d = Γ \Gamma_{old} = \Gamma Γold=Γ ;
- 随机选择一个核心点 o ∈ Ω o \in \Omega o∈Ω,初始化队列 Q = ⟨ o ⟩ Q = \langle o \rangle Q=⟨o⟩;
- Γ = Γ ∖ { o } \Gamma = \Gamma \setminus \{o\} Γ=Γ∖{o}
- while Q ≠ ∅ Q \neq \varnothing Q=∅ do
- 取出队列 Q Q Q 中的首个样本点 q q q;
- if ∣ N ϵ ( q ) ∣ ≥ M i n P t s |N_\epsilon(q)| \geq MinPts ∣Nϵ(q)∣≥MinPts,
- Δ = N ϵ ( q ) ∩ Γ \Delta = N_\epsilon(q) \cap \Gamma Δ=Nϵ(q)∩Γ 为邻域中未访问过的点;
- 将 Δ \Delta Δ 中的点加入队列 Q Q Q;
- Γ = Γ ∖ Δ \Gamma = \Gamma \setminus \Delta Γ=Γ∖Δ;
- end if
- end while
- K = K + 1 , C K = Γ o l d ∖ Γ K = K + 1, C_K = \Gamma_{old} \setminus \Gamma K=K+1,CK=Γold∖Γ。
- end while
- while Ω ≠ ∅ \Omega \neq \varnothing Ω=∅ do
DBSCAN:核心点、边界点和噪声点
下图展示了DBSCAN算法如何将点分类为核心点、边界点和噪声点。

参数设置: E p s = 10 , M i n P t s = 4 Eps = 10, MinPts = 4 Eps=10,MinPts=4
(4)DBSCAN 聚类结果
下图展示了DBSCAN算法的聚类结果。

DBSCAN聚类动态过程:可视化链接
(5)DBSCAN: 如何确定 ϵ \epsilon ϵ 和 M i n P t s MinPts MinPts
直观想法:同一个簇内的点,它们第 k k k 个最近邻大约相同的距离。
噪声点到其第 k k k 最近邻距离较远。
方法 :画出每个点到其第 k k k 最近邻的距离。
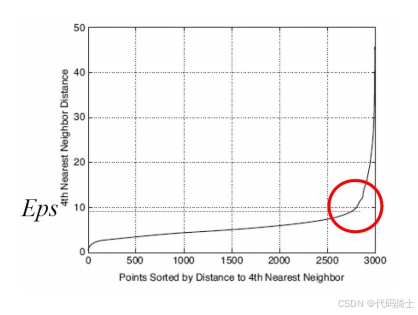
图中展示了如何通过分析每个点到其第4个最近邻的距离来确定 ϵ \epsilon ϵ 的值。图中红色圆圈标记的点对应的距离值可以作为 ϵ \epsilon ϵ 的选择。
M i n P t s = 4 MinPts = 4 MinPts=4
(6)对DBSCAN的分析
1、优势
- 不需要明确簇的数量
- 能够识别任意形状的簇
- 对离群点(outliers)较为鲁棒
2、劣势
-
参数选择比较困难( M i n P t s MinPts MinPts, ϵ \epsilon ϵ)
-
不适合密度差异较大的数据集
-
需要计算每个样本的邻居点,操作耗时( O ( N 2 ) O(N^2) O(N2));即使采用k-d tree索引等技术加速计算,算法的时间复杂也为 O ( N l o g ( N ) ) O(Nlog(N)) O(Nlog(N))。
-
OPTICS (Ordering Points To Identify the Clustering Structure) 聚类算法:DBSCAN 算法的扩展,能解决 DBSCAN 对超参数敏感的问题。
(7)DBSCAN 什么时候表现不好
DBSCAN 在以下情况下表现不佳:
- 密度变化
- 高维数据
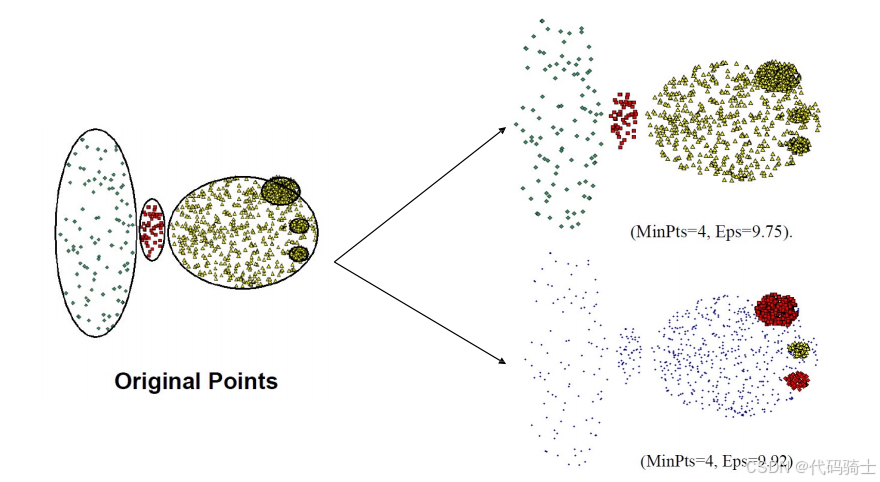
上图展示了DBSCAN算法在不同参数设置下对同一数据集的聚类效果。可以看出,参数选择对聚类结果有显著影响。
5、基于图的聚类
(1)基于图的方聚类
所有数据点构成相似图:带权无向图 G ( V , E ) G(\mathcal{V}, \mathcal{E}) G(V,E)
- 结点集合 V = { v 1 , v 2 , ... , v N } \mathcal{V} = \{v_1, v_2, \ldots, v_N\} V={v1,v2,...,vN}, N N N 表示节点数目, v i v_i vi 表示数据点 x i x_i xi
- 结点之间可以用边连接:边的集合 E = { e i , j , i , j = 1 , ... , N } \mathcal{E} = \{e_{i,j}, i, j = 1, \ldots, N\} E={ei,j,i,j=1,...,N}
- e i , j e_{i,j} ei,j 表示结点 v i v_i vi 和 v j v_j vj 之间边,其权重 w i , j w_{i,j} wi,j:结点 v i v_i vi 和 v j v_j vj 的相似性
- 相似的两个结点之间的边权重值较高
- 不相似的两个结点之间的边权重值较低
- e i , j e_{i,j} ei,j 表示结点 v i v_i vi 和 v j v_j vj 之间边,其权重 w i , j w_{i,j} wi,j:结点 v i v_i vi 和 v j v_j vj 的相似性
聚类:对所有数据点组成的相似图进行切图
- 不同的子图间边权重和尽可能的低
- 子图内的边权重和尽可能的高
(2)边的创建
全连接图对大多数场合来说不现实(图太大),所以一般建立局部连接图:如果 x i x_i xi 和 x j x_j xj 距离较近,则结点 v i v_i vi 和 v j v_j vj 连一条边。
边创建的两个准则:
-
ϵ \epsilon ϵ 邻域 ( ϵ − n e i g h b o r h o o d \epsilon-neighborhood ϵ−neighborhood):
- 如果 ∥ x i − x j ∥ < ϵ \|x_i - x_j\| < \epsilon ∥xi−xj∥<ϵ ( ϵ ∈ R + \epsilon \in \mathbb{R}^+ ϵ∈R+),结点 v i v_i vi 和 v j v_j vj 之间连一条边;
-
K K K 近邻:
- 如果 x i x_i xi 是 x j x_j xj 的 K K K 个最近邻之一且/或 x j x_j xj 是 x i x_i xi 的 K K K 个最近邻之一,则结点 v i v_i vi 和 v j v_j vj 之间连一条边。
(3)边的权重
定义矩阵 W W W 为邻接矩阵(Affinity matrix),元素 w i , j w_{i,j} wi,j 表示结点 v i v_i vi 和 v j v_j vj 的相似度,即为边 e i , j e_{i,j} ei,j 的权重
通常两个结点之间的相似度可取: s i , j = exp ( − ∥ x i − x j ∥ 2 σ 2 ) s_{i,j} = \exp\left(-\frac{\|x_i-x_j\|^2}{\sigma^2}\right) si,j=exp(−σ2∥xi−xj∥2),其中 σ 2 ∈ R + \sigma^2 \in \mathbb{R}^+ σ2∈R+
两个常见的边权重计算方式:
-
二值:
- w i , j = { 1 如果结点 v i 和 v j 相连 0 otherwise w_{i,j} = \begin{cases} 1 & \text{如果结点 } v_i \text{ 和 } v_j \text{ 相连} \\ 0 & \text{otherwise} \end{cases} wi,j={10如果结点 vi 和 vj 相连otherwise
-
连续值:
- w i , j = { s i , j 如果结点 v i 和 v j 相连 0 otherwise w_{i,j} = \begin{cases} s_{i,j} & \text{如果结点 } v_i \text{ 和 } v_j \text{ 相连} \\ 0 & \text{otherwise} \end{cases} wi,j={si,j0如果结点 vi 和 vj 相连otherwise
(4)图论基础
邻接矩阵 W W W :所有点之间的权重值 w i , j w_{i,j} wi,j,构成图的邻接矩阵 W W W,这是一个 N × N N \times N N×N 的对称矩阵。
度矩阵 D D D :每个节点的度构成 N × N N \times N N×N 的度矩阵 D D D。
- 结点 v i v_i vi 的度 d i d_i di 定义为和它相连的所有边的权重之和,即 d i = ∑ j = 1 N w i , j d_i = \sum_{j=1}^{N} w_{i,j} di=∑j=1Nwi,j
- D D D 是对角矩阵,第 i i i 行的主对角线元素值,为结点 v i v_i vi 的度数。
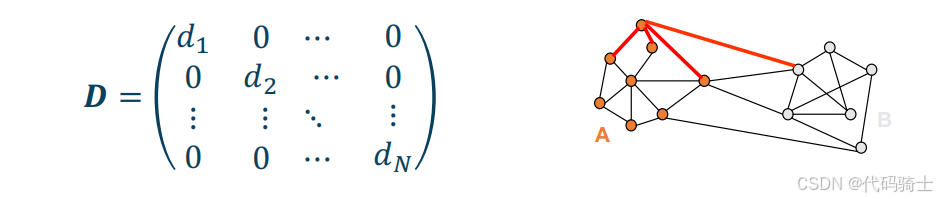
(5)Laplace矩阵 L L L: L = D − W L = D - W L=D−W
1. 拉普拉斯矩阵 L L L 是对称矩阵,所有特征值都是实数。
2. 对于任意的向量 f f f:
f T L f = 1 2 ∑ i , j = 1 N w i , j ( f i − f j ) 2 f^T L f = \frac{1}{2} \sum_{i,j=1}^{N} w_{i,j}(f_i - f_j)^2 fTLf=21i,j=1∑Nwi,j(fi−fj)2
3. 拉普拉斯矩阵 L L L 是半正定的,且对应的 N N N 个实数特征值都大于等于 0 0 0,即 0 = λ 1 ≤ λ 2 ≤ ⋯ ≤ λ N 0 = \lambda_1 \leq \lambda_2 \leq \cdots \leq \lambda_N 0=λ1≤λ2≤⋯≤λN ( L v = λ v Lv = \lambda v Lv=λv)
4. L L L 的最小特征值是 0 0 0,且特征值 0 0 0 所对应的特征向量为全 1 1 1 向量;
5. L L L 的特征值中 " 0 0 0" 出现的次数是图连通区域的个数。
(6)Laplace矩阵的性质2
证明 : f T L f = f T D f − f T W f f^T L f = f^T D f - f^T W f fTLf=fTDf−fTWf
= ∑ i = 1 N f i d i 2 − ∑ i , j = 0 N w i , j f i f j = \sum_{i=1}^{N} f_i d_i^2 - \sum_{i,j=0}^{N} w_{i,j} f_i f_j =i=1∑Nfidi2−i,j=0∑Nwi,jfifj
= 1 2 ( ∑ i = 1 N d i f i 2 − 2 ∑ i , j = 1 N w i , j f i f j + ∑ j = 1 N d j f j 2 ) = \frac{1}{2} \left( \sum_{i=1}^{N} d_i f_i^2 - 2 \sum_{i,j=1}^{N} w_{i,j} f_i f_j + \sum_{j=1}^{N} d_j f_j^2 \right) =21(i=1∑Ndifi2−2i,j=1∑Nwi,jfifj+j=1∑Ndjfj2)
= 1 2 ∑ i , j = 1 N w i , j ( f i − f j ) 2 ≥ 0 = \frac{1}{2} \sum_{i,j=1}^{N} w_{i,j} (f_i - f_j)^2 \geq 0 =21i,j=1∑Nwi,j(fi−fj)2≥0
L L L 类似导数算子,刻画图信号局部平滑度
(7)Laplace矩阵的性质4
拉普拉斯矩阵的最小特征值是 0 0 0,且对应的特征向量为全 1 1 1 向量。
证明 :根据定义: d i = ∑ j = 1 N w i , j d_i = \sum_{j=1}^{N} w_{i,j} di=∑j=1Nwi,j
L = D − W L = D - W L=D−W
令 v = 1 v = 1 v=1 (元素值全为 1 1 1),
L v = D v − W v = ( d 1 , 1 d 2 , 2 ⋮ d N , N ) − ( d 1 , 1 d 2 , 2 ⋮ d N , N ) = ( 0 0 ⋮ 0 ) = 0 × v Lv = Dv - Wv = \begin{pmatrix} d_{1,1} \\ d_{2,2} \\ \vdots \\ d_{N,N} \end{pmatrix} - \begin{pmatrix} d_{1,1} \\ d_{2,2} \\ \vdots \\ d_{N,N} \end{pmatrix} = \begin{pmatrix} 0 \\ 0 \\ \vdots \\ 0 \end{pmatrix} = 0 \times v Lv=Dv−Wv= d1,1d2,2⋮dN,N − d1,1d2,2⋮dN,N = 00⋮0 =0×v
根据特征值和特征向量的定义( L v = λ v Lv = \lambda v Lv=λv), L L L 有一个特征值为 0 0 0,且其对应的特征向量为 1 1 1(元素值全为 1 1 1)。
(8)Laplace矩阵的性质5
特征值中 0 0 0 出现的次数就是图连通区域的个数。
证明 :首先考虑 k = 1 k = 1 k=1:即图是全连通的。
假设 f f f 是特征值 0 0 0 的对应特征向量( L f = 0 × f = 0 Lf = 0 \times f = 0 Lf=0×f=0),那么
0 = f T L f = 1 2 ∑ i , j = 1 N w i , j ( f i − f j ) 2 . 0 = f^T L f = \frac{1}{2} \sum_{i,j=1}^{N} w_{i,j} (f_i - f_j)^2. 0=fTLf=21i,j=1∑Nwi,j(fi−fj)2.
w i , j ≥ 0 ∑ i , j = 1 N w i , j ( f i − f j ) 2 = 0 } ⇒ ∀ i , j = 1 , 2 , ... , N , f i = f j \left. \begin{array}{c} w_{i,j} \geq 0 \\ \sum_{i,j=1}^{N} w_{i,j} (f_i - f_j)^2 = 0 \end{array} \right\} \Rightarrow \forall i, j = 1, 2, \ldots, N, f_i = f_j wi,j≥0∑i,j=1Nwi,j(fi−fj)2=0}⇒∀i,j=1,2,...,N,fi=fj
即 f f f 在连通部件上是常数向量 1 1 1,这显然是连通分量的指示向量。
L L L 的特征值中 " 0 0 0" 出现的次数是图连通区域的个数。
证明 :假设图有 k k k 个连通部件。将结点按其所属的连通部件排序,此时邻接权重矩阵 W W W 具有块对角形式,矩阵 L L L 也是块对角形式:
L = ( L 1 ⋯ ⋯ L k ) L = \begin{pmatrix} L_1 & & \cdots & \cdots & L_k \end{pmatrix} L=(L1⋯⋯Lk)
每个块 L i L_i Li 都是第 i i i 个连通子图的拉普拉斯矩阵:每个 L i L_i Li 都有 1 1 1 个特征值 0 0 0,对应的特征向量是第 i i i 个连通分量上的常数向量 v i = ( 0 , 0 , ... , 0 , 1 , 1 , ... , 1 , 0 , 0 , ... , 0 ) T v_i = (0, 0, \ldots, 0, 1, 1, \ldots, 1, 0, 0, \ldots, 0)^T vi=(0,0,...,0,1,1,...,1,0,0,...,0)T:其中 1 1 1 的对应第 i i i 连通子件 L i L_i Li L v i = 0 , i = 1 , 2 , ... , k Lv_i = 0, i = 1, 2, \ldots, k Lvi=0,i=1,2,...,k: v i v_i vi 是 0 0 0 特征值对应的特征向量
L L L 的谱由 L i L_i Li 的谱的联合给出:矩阵 L L L 的特征值 0 0 0 的数目与连通分量的数目相同,相应的特征向量为连通分量的指示向量。
(9)图的拉普拉斯矩阵及其应用
例子:
图的表示:
- 图由节点 X 1 , X 2 , ... , X 5 X_1, X_2, \ldots, X_5 X1,X2,...,X5 组成,节点之间通过边连接。

邻接矩阵、度矩阵和拉普拉斯矩阵:
-
邻接矩阵 W W W :
W = ( 0 1 0 0 0 1 0 0 0 0 0 0 0 1 0 0 0 1 0 1 0 0 0 1 0 ) W = \begin{pmatrix} 0 & 1 & 0 & 0 & 0 \\ 1 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 1 & 0 \\ 0 & 0 & 1 & 0 & 1 \\ 0 & 0 & 0 & 1 & 0 \\ \end{pmatrix} W= 0100010000000100010100010 -
度矩阵 D D D :
D = ( 1 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0 2 0 0 0 0 0 1 ) D = \begin{pmatrix} 1 & 0 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 & 0 \\ 0 & 0 & 1 & 0 & 0 \\ 0 & 0 & 0 & 2 & 0 \\ 0 & 0 & 0 & 0 & 1 \\ \end{pmatrix} D= 1000001000001000002000001 -
拉普拉斯矩阵 L L L :
L = D − W = ( 1 − 1 0 0 0 − 1 1 0 0 0 0 0 1 − 1 0 0 0 − 1 2 − 1 0 0 0 − 1 1 ) L = D - W = \begin{pmatrix} 1 & -1 & 0 & 0 & 0 \\ -1 & 1 & 0 & 0 & 0 \\ 0 & 0 & 1 & -1 & 0 \\ 0 & 0 & -1 & 2 & -1 \\ 0 & 0 & 0 & -1 & 1 \\ \end{pmatrix} L=D−W= 1−1000−11000001−1000−12−1000−11
拉普拉斯矩阵 L L L 的特征值和特征向量:
- 特征值 : λ = 0 , 0 , 1 , 2 , 3 \lambda = 0, 0, 1, 2, 3 λ=0,0,1,2,3
- 特征向量 :
v 1 = ( 1 1 0 0 0 ) , v 2 = ( 0 0 1 1 1 ) , v 3 = ( 0 0 − 0.71 0 0.71 ) , v 4 = ( − 0.71 0.71 0 0 0 ) , v 5 = ( 0 0 − 0.41 0.82 − 0.41 ) v_1 = \begin{pmatrix} 1 \\ 1 \\ 0 \\ 0 \\ 0 \\ \end{pmatrix}, \quad v_2 = \begin{pmatrix} 0 \\ 0 \\ 1 \\ 1 \\ 1 \\ \end{pmatrix}, \quad v_3 = \begin{pmatrix} 0 \\ 0 \\ -0.71 \\ 0 \\ 0.71 \\ \end{pmatrix}, \quad v_4 = \begin{pmatrix} -0.71 \\ 0.71 \\ 0 \\ 0 \\ 0 \\ \end{pmatrix}, \quad v_5 = \begin{pmatrix} 0 \\ 0 \\ -0.41 \\ 0.82 \\ -0.41 \\ \end{pmatrix} v1= 11000 ,v2= 00111 ,v3= 00−0.7100.71 ,v4= −0.710.71000 ,v5= 00−0.410.82−0.41
图的拉普拉斯矩阵 L L L 的特征向量
图的表示:
- 图由一系列节点组成,节点之间通过边连接。

图的拉普拉斯矩阵 L L L 的特征向量:
- 前两个特征向量对应图的两个连通分量。
- 其他特征向量可视为连通部件内部的基。
特征向量的性质:
- 特征向量可以形成一组基:前面的成分变化比较平滑,后面的成分变化剧烈。
- 公式表示:
f T L f = ∑ i , j = 1 N w i , j ( f i − f j ) 2 f^T L f = \sum_{i,j=1}^{N} w_{i,j} (f_i - f_j)^2 fTLf=i,j=1∑Nwi,j(fi−fj)2
表示 f f f 相对图的平滑程度。
规范化的拉普拉斯矩阵:
对称 Laplace 矩阵和随机游走 Laplace 矩阵:
- 对称 Laplace 矩阵 :
L s y m = D − 1 / 2 L D − 1 / 2 L_{sym} = D^{-1/2} L D^{-1/2} Lsym=D−1/2LD−1/2 - 随机游走 Laplace 矩阵 :
L r m = D − 1 L L_{rm} = D^{-1} L Lrm=D−1L
性质
- 对于任意的向量 f f f,有:
f T L s y m f = 1 2 ∑ i , j = 1 N w i , j ( f i d i − f j d j ) 2 f^T L_{sym} f = \frac{1}{2} \sum_{i,j=1}^{N} w_{i,j} \left( \frac{f_i}{\sqrt{d_i}} - \frac{f_j}{\sqrt{d_j}} \right)^2 fTLsymf=21i,j=1∑Nwi,j(di fi−dj fj)2 - 如果 L r m L_{rm} Lrm 的特征值为 λ \lambda λ,对应的特征向量为 v v v,则 λ \lambda λ 是 L s y m L_{sym} Lsym 的特征值, D − 1 / 2 v D^{-1/2} v D−1/2v 是对应的特征向量。
- λ \lambda λ 是 L r m L_{rm} Lrm 的特征值,对应的特征向量为 v v v,当且仅当 λ \lambda λ 是广义特征值问题 L v = λ D v L v = \lambda D v Lv=λDv 的解。
(10)切图(cut)
无向图 G G G 的切图
- 将图 G ( V , E ) G(V, E) G(V,E) 切成互不连接的 K K K 个子图,每个子图点的集合为 A 1 , A 2 , ... , A K A_1, A_2, \ldots, A_K A1,A2,...,AK,满足 A i ∩ A j = ∅ A_i \cap A_j = \emptyset Ai∩Aj=∅,且 A 1 ∪ A 2 ∪ ⋯ ∪ A K = V A_1 \cup A_2 \cup \cdots \cup A_K = V A1∪A2∪⋯∪AK=V。
切图权重
- 对任意两个子图点的集合 A , B ⊆ V , A ∩ B = ∅ A, B \subseteq V, A \cap B = \emptyset A,B⊆V,A∩B=∅,定义 A , B A, B A,B 之间的切图权重为:
W ( A , B ) = ∑ i ∈ A , j ∈ B w i , j W(A, B) = \sum_{i \in A, j \in B} w_{i,j} W(A,B)=i∈A,j∈B∑wi,j
切图(cut)
- 对 K K K 个子图点的集合 A 1 ∪ A 2 ∪ ⋯ ∪ A K A_1 \cup A_2 \cup \cdots \cup A_K A1∪A2∪⋯∪AK,定义切图为:
c u t ( A 1 , A 2 , ... , A K ) = 1 2 ∑ k = 1 K W ( A k , A k ‾ ) cut(A_1, A_2, \ldots, A_K) = \frac{1}{2} \sum_{k=1}^{K} W(A_k, \overline{A_k}) cut(A1,A2,...,AK)=21k=1∑KW(Ak,Ak)
其中 A k ‾ \overline{A_k} Ak 为 A k A_k Ak 的补集。
(11)最小切图
最佳分割
- 图的切图最小(minimum cut):
c u t ( A 1 , A 2 , ... , A K ) = 1 2 ∑ k = 1 K W ( A k , A k ‾ ) cut(A_1, A_2, \ldots, A_K) = \frac{1}{2} \sum_{k=1}^{K} W(A_k, \overline{A_k}) cut(A1,A2,...,AK)=21k=1∑KW(Ak,Ak)
缺点
- 切图权重与边的数目成正比。
- 倾向于剪切成小的、孤立的成分(去掉最小的边即将图分成两部分)。
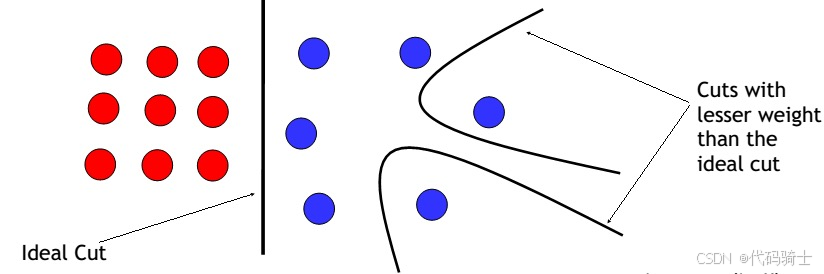
规范化切图(Normalized Cuts, NCuts)
基本思想
- 对每个分割区域的大小进行归一化。
- 解决最小切的偏向问题。
定义子集 A A A 的体积
- 定义子集 A A A 的体积为图中与 A A A 相连的边的权重:
v o l ( A ) = ∑ i ∈ A d i vol(A) = \sum_{i \in A} d_i vol(A)=i∈A∑di
规范化切图
- 规范化切图:
N c u t ( A 1 , A 2 , ... , A K ) = 1 2 ∑ k = 1 K W ( A k , A k ‾ ) v o l ( A k ) Ncut(A_1, A_2, \ldots, A_K) = \frac{1}{2} \sum_{k=1}^{K} \frac{W(A_k, \overline{A_k})}{vol(A_k)} Ncut(A1,A2,...,AK)=21k=1∑Kvol(Ak)W(Ak,Ak)