

前引:在进入本篇文章之前,我们经常在使用某个应用时,会出现【商品名称、最受欢迎、购买量】等等这些榜单,这里面就运用了我们的排序算法,作为刚学习数据结构的初学者,小编为各位完善了以下几种排序算法,包含了思路拆解,如何一步步实现,包含了优缺点分析、复杂度来历,种类很全,下面我们开始穿梭算法排序的迷雾,寻求真相!
堆排序
说到堆排序,我们又需要重温树的神奇了,大家先别畏惧,区区堆排序小编将带着大家解构它,让它毫无保留的展现给大家!在学习之前,我们需要知道两种思想结构:物理结构、逻辑结构
堆实现的逻辑结构就是一颗完全二叉树:
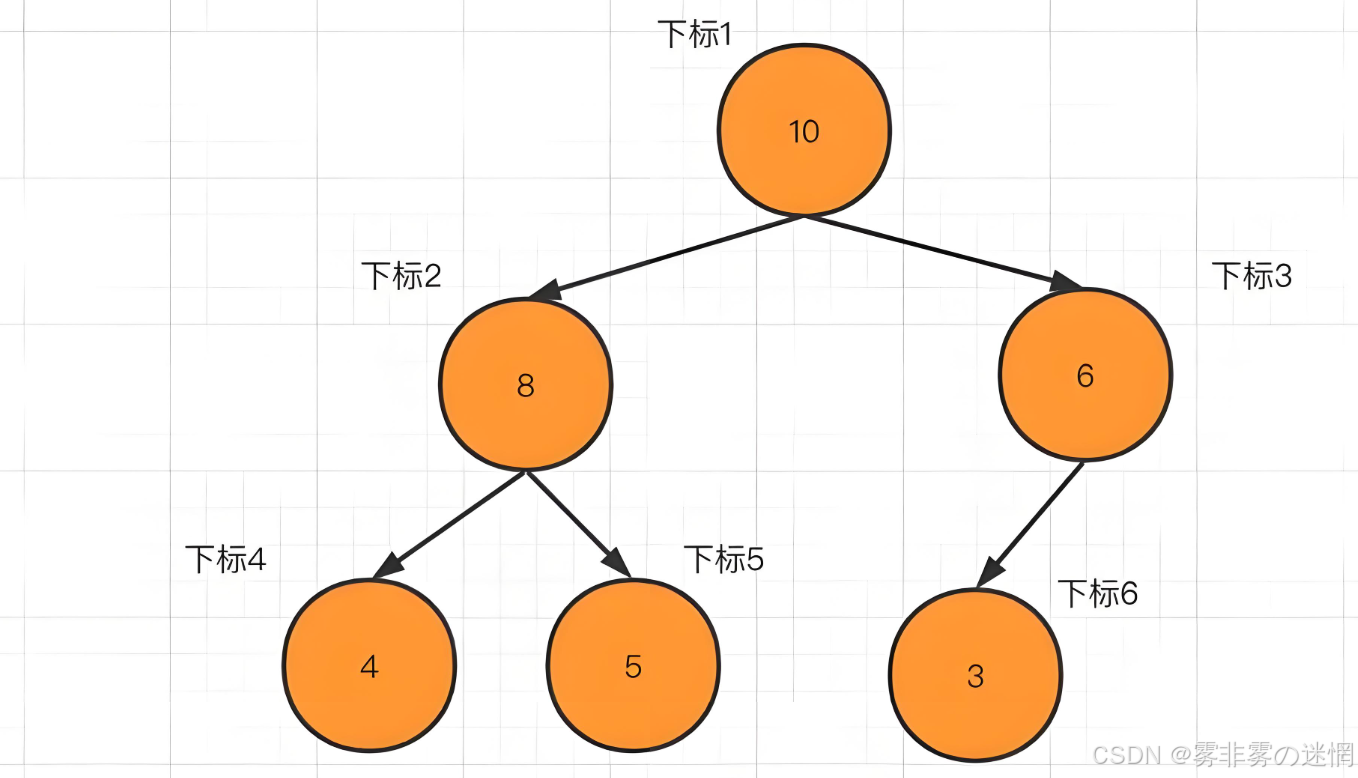
但是咱们是用数组实现的,只是借助逻辑结构去完成物理结构,大家对比两幅图,就明白了!

算法思路:
在看算法思路之前,我们需要知道什么是大顶堆,什么是小顶堆
大顶堆:每个节点的值都大于或等于其子节点的值,堆顶为最大值
小顶堆:每个节点的值都小于或等于其子节点的值,堆顶为最小值
咱们的堆本质是一颗用数组实现的完全二叉树,下面我以数组下标从1开始存储为例,如需更多的参考以及深入学习堆,可以参考小编主页的【堆】哦!下面是各节点下标换算的关系:
左子节点:2 * i 右子节点:2 * i + 1 父节点:i(若已知子节点 k ,则父节点为 k / 2)
堆的算法思路就是:利用堆的性质,来实现对数据的排序
(白话文理解:利用堆结构关系,对数据按照最大堆/最小堆提取堆顶元素来实现排序,因为堆顶是这组数组的最值,咱每次提取出来,不就是达到了排序效果吗!)
实现步骤:
咱们堆排序以实现堆为主,因此需要先手搓一个堆,堆的实现包含以下步骤:(实现有详细说明)
初始化 存储 上浮调整 移除堆尾元素 下沉调整
复杂度分析:
堆分为建堆、排序堆两个阶段,因此需要分别说明,参考如下理解
建堆阶段:从最后一个非叶子节点开始调整,时间复杂度为O(n)
排序堆阶段:每次调整堆的时间复杂度为O(logn),共需要调整n-1次,因此总时间复杂度为O(nlogn)
综合起来就是O(nlogn)
空间复杂度为O(1)。因为堆排序是原地排序算法,仅仅需要常数级的额外空间
代码实现:
建堆:
咱们按照堆排序的步骤,第一步需要先建立堆,咱们先建立一个结构体,参考如下代码:
cpp
#define MAX 10
typedef struct Pile
{
//存储的数组空间
int* space;
//当前堆存储数量
int size;
//当前最大存储量
int max;
}Pile;下面我们对堆进行初始化操作,开辟空间、设置初始变量,参考以下代码:
cpp
//初始化堆
void Preliminary(Pile* pilestruct)
{
assert(pilestruct);
pilestruct->size = 0;
pilestruct->max = MAX;
//开辟空间
pilestruct->space = (int*)malloc(sizeof(int) * MAX);
if (pilestruct->space == NULL)
{
perror("malloc");
return;
}
}接下来咱们进行数据存储进堆,来实现存储的代码:
cpp
//存储
void Storage(Pile* pilestruct,int data)
{
assert(pilestruct);
//先判断是否存满,是则扩容
if ((pilestruct->size+1) == pilestruct->max)
{
int* pc = (int*)realloc(pilestruct->space, sizeof(int) * (pilestruct->max) + MAX);
if (pc == NULL)
{
perror("realloc");
return;
}
pilestruct->space = pc;
//更新max
pilestruct->max += MAX;
}
//存储数据
pilestruct->size++;
pilestruct->space[pilestruct->size] = data;
//上浮调整
Adjust(pilestruct->space, pilestruct->size);
}存储之后需要数据满足最大堆的性质,所以咱们还需要一个调整函数,其思想如下:
将此数据与其父节点进行比较,如果这个数据较大,交换父节点与其位置,反之不交换,代码如下
cpp
//上浮调整
void Adjust(int * space, int child)
{
//父节点下标
int parent = child / 2;
while (child > 1)
{
if (space[child] > space[parent])
{
Exchange(&space[child], &space[parent]);
//更新child,parent
child = parent;
parent = (child ) / 2;
}
else
break;
}
}现在咱们的建堆就写完了,我存储了几个数字,大家可以看看效果:

排序堆:
将堆顶元素(最大值)与堆的最后一个元素交换,然后size--,这样我们就去除了堆顶元素(最大值),注意:这里的去除只是将堆元素个数减一,并不是删除。然后我们就一直重复这样的操作,直到将所有元素调整完,我们堆的元素原来是9 8 6 1 0 2,调整之后是:0 1 2 5 6 8 9
核心思想(重点):利用多次下沉调整每次将最大值放到末尾,这样就达到了有序数据
cpp
void Pilesort(Pile* pilestruct)
{
assert(pilestruct);
//parent下标
int parent = 1;
//child下标
int child = 2*parent;
//最后一个节点和根节点换位
Exchange(&pilestruct->space[pilestruct->size], &pilestruct->space[1]);
//移除根节点
pilestruct->size--;
//下沉调整
while (child <= pilestruct->size)// 注意点1
{
//找到左右孩子节点的最大值
// 注意点2
if (child < pilestruct->size && pilestruct->space[child] < pilestruct->space[child+1])
{
child++;
}
//看是否交换其与父节点
// 注意点3
if (child<=pilestruct->size && pilestruct->space[child] > pilestruct->space[parent])
{
Exchange(&pilestruct->space[child], &pilestruct->space[parent]);
//更新父、孩子节点下标
parent = child;
child = 2 * parent;
}
else
break;
}
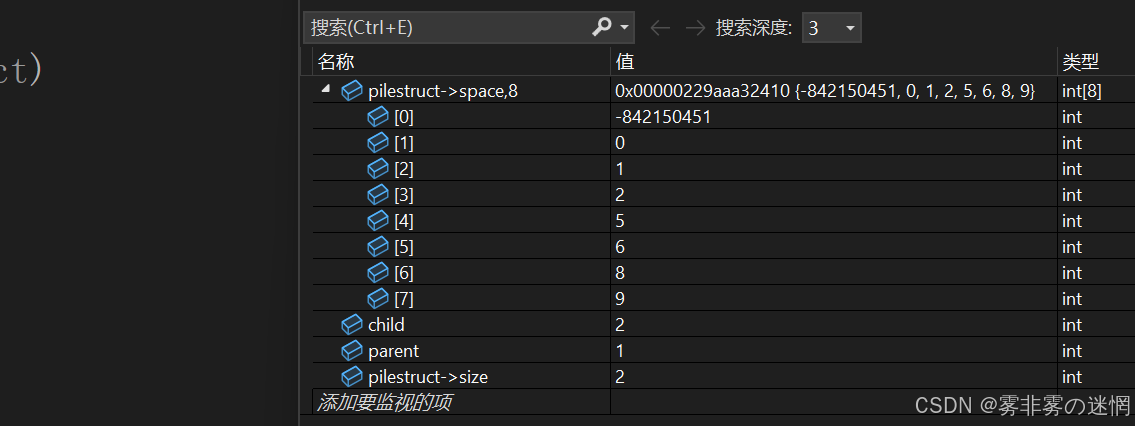
}在上面的代码中,有3个需要注意的地方**(上图标出来了)**,为哈3个判断条件需要注意?
注意点1:当堆最后只有2个元素的时候,还要发生一次交换(0与1),因此可以取等号
注意点2:这个 if 条件需要注意,当最后两个元素0与1时,1在根节点,0在子节点,虽然满足中国 判断条件,但是所以这两个数字不能发生交换,所以不能取等号
注意点3:还是跟上个判断条件一样,0在根节点,1在子节点,满足判断条件,需要交换
**总结:**堆的实现需要两次调整。一次是存储数据时需要满足最大堆的性质,需要做上浮调整。而 每次交换根节点元素 和 尾节点元素之后,还是需要保持大顶堆的性质,因此需要下沉调整
下面我们已经将这组数据利用下沉调整完全实现了有序,只需要再依次拿出来就行了
优缺点分析:
堆排序属于原地排序,对大规模数据排序效率较高,并且不会因为数据量增大导致性能急剧下降,但是堆排序同时也是非稳定排序,相同元素的相对顺序可能会改变,最大的问题就需要手动写一个堆,需要对指针、数组之间的逻辑、物理关系的相互转化
冒泡排序
"冒泡"排序的实现思路很简单,咱们先看一个图:

当各种小泡泡从鱼嘴里面吐出来到达最上面的水层,泡泡是最大的,因此咱们冒泡排序的实现也是,每次排序将最大值向后面靠,话不多说,进入正题!
算法思路:
通过重复遍历列表,比较相邻元素并看是否进行交换,将最大的元素逐渐"冒泡"到列表末尾
实现步骤:
记住咱们的排序先从单趟写,由里向外。
单趟的实现:通过 for 循环将第一次遍历的最大值通过比较移到末尾即可
单趟实现完后,咱们已经排序完了一个元素,那么只需要将剩余的 n-1 个元素排序完成就行了

复杂度分析:
最好最坏都是遍历(可以参看"代码实现"),所以时间复杂度都是O(n^2)
空间复杂度:冒泡属于原地排序,所以为O(1)
代码实现:
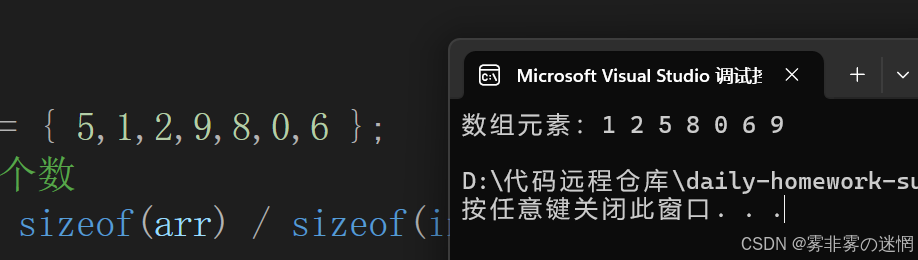
按照实现步骤,咱们先实现单趟:(对比左右两幅图,我们已经将 9 排序到了最后)
cpp
//单趟
for (int i = 0; i < size - 1; i++)
{
//如果前一个元素比后一个元素大
if (arr[i] > arr[i + 1])
{
Exchange(&arr[i], &arr[i + 1]);
}
}
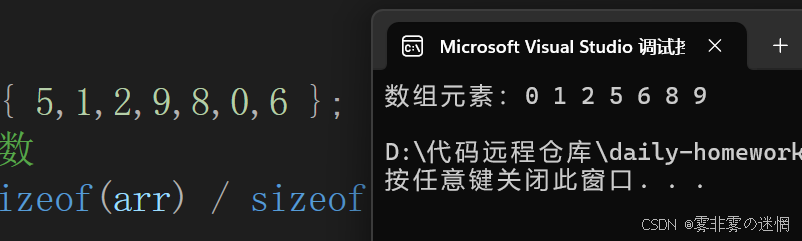
我们已经排序完了一个元素,下面我们再套个循环,排序剩余的 n-1 个元素:
cpp
for (int j = 1; j < size - 1; j++)
{
//单趟
for (int i = 0; i < size - 1; i++)
{
//如果前一个元素比后一个元素大
if (arr[i] > arr[i + 1])
{
Exchange(&arr[i], &arr[i + 1]);
}
}
}
代码优化:
我们在优化之前不管后面的元素是否已经有序,都需要遍历,导致重复了无用的次数,优化如下
如果我们开始假设整组元素都是有序的,也就是 false = -1 ,如果发生了交换,那么 false = 1 ,那么就表明需要进行下一次的循环判断,否则直接退出循环,因为遍历一遍结束之后,false如果还为-1,就表明数组已经是有序的了,代码如下:
cpp
for (int j = 1; j < size - 1; j++)
{
//假设整组数据有序
int false = -1;
//单趟
for (int i = 0; i < size - 1; i++)
{
//如果前一个元素比后一个元素大
if (arr[i] > arr[i + 1])
{
Exchange(&arr[i], &arr[i + 1]);
//假设不符合
false = 1;
}
}
if (false == -1)
{
break;
}
}优缺点分析:
冒泡排序是稳定的排序算法,相等的元素在排序之后依然保持原来的相对顺序,但是时间复杂度原先很高,达到了O(n^2),但是我们通过优化,提高了一定的算法效率,在处理数据时可以排除有序数据,表现更好
Hoare排序
Hoare排序是快速排序的一种经典实现,由Tony Hoare于1960年提出,核心思想是基于分治策略,通过Hoare分区方法将数组分为两部分,递归的再对子数组排序,看不懂没有关系,咱们学习Hoare排序肯定要知道它咋来的,以上是术语,下面我们进行学习!(特别提醒!很不好理解!)
算法思路:
Hoare排序的关键在于Hoare分区方法,其特点是通过双指针从数组两端向中间扫描,减少冗余交换,尤其擅长处理重复的元素,整体分治思路如下:
划分:选择一个基准值(pivot),将数组分为两部分,左半部分元素 <= pivot ,右半部分元素 >= pivot
递归:对左右两部分分别递归调用Hoare排序

复杂度分析:
每次递归将数组分为两部分,递归深度为 log n ,每层处理时间为 O(n),因此平均时间复杂度为(n logn)
当每次分区完全逆序,递归深度为 n ,最坏情况达到了 O(n^2)
实现步骤:
首先咱们来讲解单趟的实现(重点):
(1)假设我们开始有一个数组,将它的最左边的值 6 作为基准值pivot

(2)现在我们再设置这个数组的最左边的值 和 最右边的值分别为left 和 right
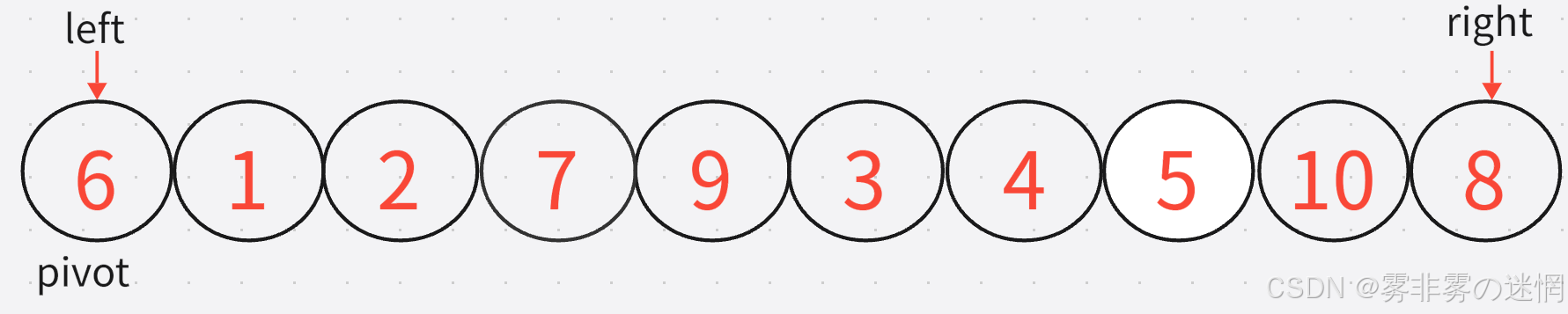
(3)下面我们通过循环找:左边大于等于基准值的元素(找大),右边小于等于基准值的元素(找小),因为我们需要让大于基准值的元素摞到右边,小于基准值的移到左边
注意事项:我们的初衷是大的在右边,小的在左边,因此需要从右边开始移动,只有这样,才能保证小于基准值的移到左边来。反之,如果基准值在右边,就从左边开始移动 。 如下:

(4)将找到的满足条件的元素进行交换 ,如下图:

(5)继续循环找到满足条件的两个元素,直到两者相遇, 然后交换相遇的元素与基准值元素

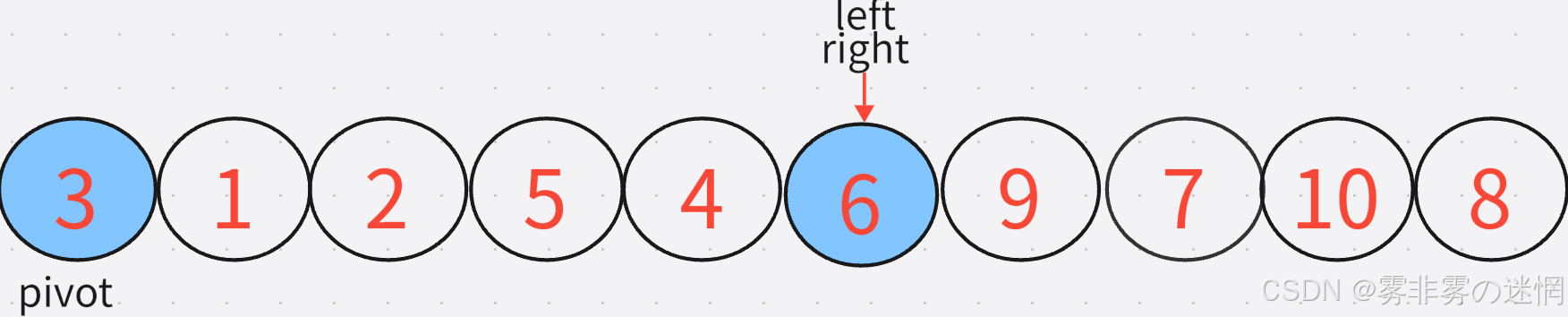
(6)现在我们把数组分为了两组,以 6 为分界线,左边的数字小于等于6,右边的数字大于等于6
然后我们采用递归,两端采用分组进行Hoare排序,随着递归函数的调用,这两个组又会分为几个小组,因此我们必须要弄清楚单趟的思路。注意left、right、pivot需要更新,
通俗理解:理解成数,树根就是一整个数组,它会分为很多个子数组(这就是对这里分组的理解)

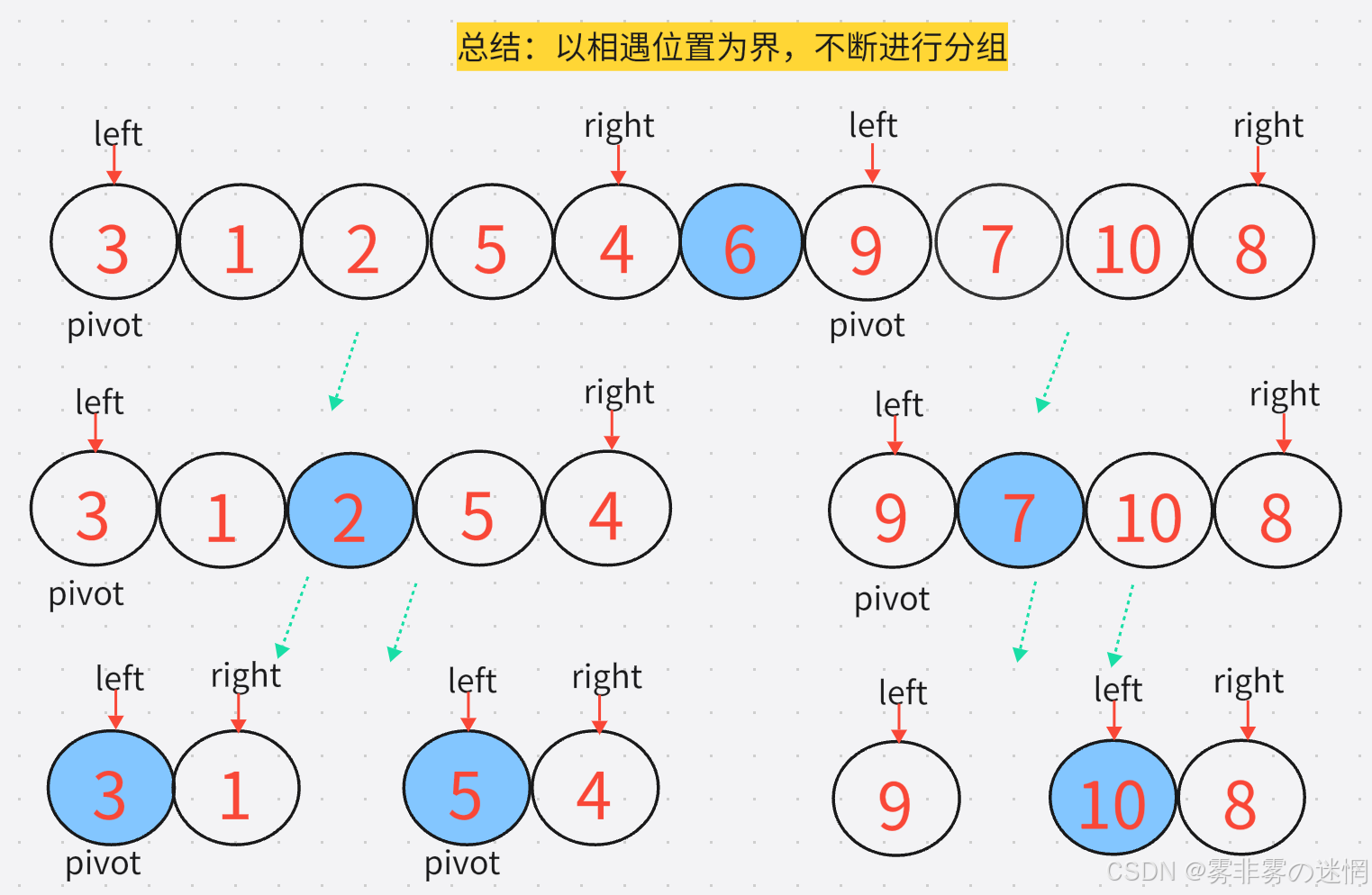
代码实现:
按照上面的思路,我们先实现单趟,也就是先排序一个元素:(我再强调一下注意点)
(1)pivot 作为下标开始是left 的位置,这里不要写死为0 ,因为我们递归是需要灵活变化的, pivot 的开始位置应该是left的位置
(2)基准值在左边,就从右边开始找;基准值在右边,就从左边开始找
(3)大循环条件就是它们相遇停止;下面的两个子循环:首先判断大小我就不解释了,之所以加 上 left < right ,是因为避免left 与 right一直走,出界(建议画图最好理解)
(4)记得更新相遇位置为新的 pivot
cpp
int pivot = left;
//单趟
while (left < right)
{
//左边找大于等于基准值的元素(找大)
while (left<right && arr[right]>=arr[pivot])
{
right--;
}
//右边找小于等于基准值的元素(找小)
while (left<right && arr[left]<=arr[pivot])
{
left++;
}
//找到之后进行交换
Exchange(&arr[left], &arr[right]);
}
//交换基准值和相遇的元素
Exchange(&arr[left], &arr[pivot]);
pivot = left;上面我们已经实现了单趟, 下面我们来实现递归,这里有2个注意要点:
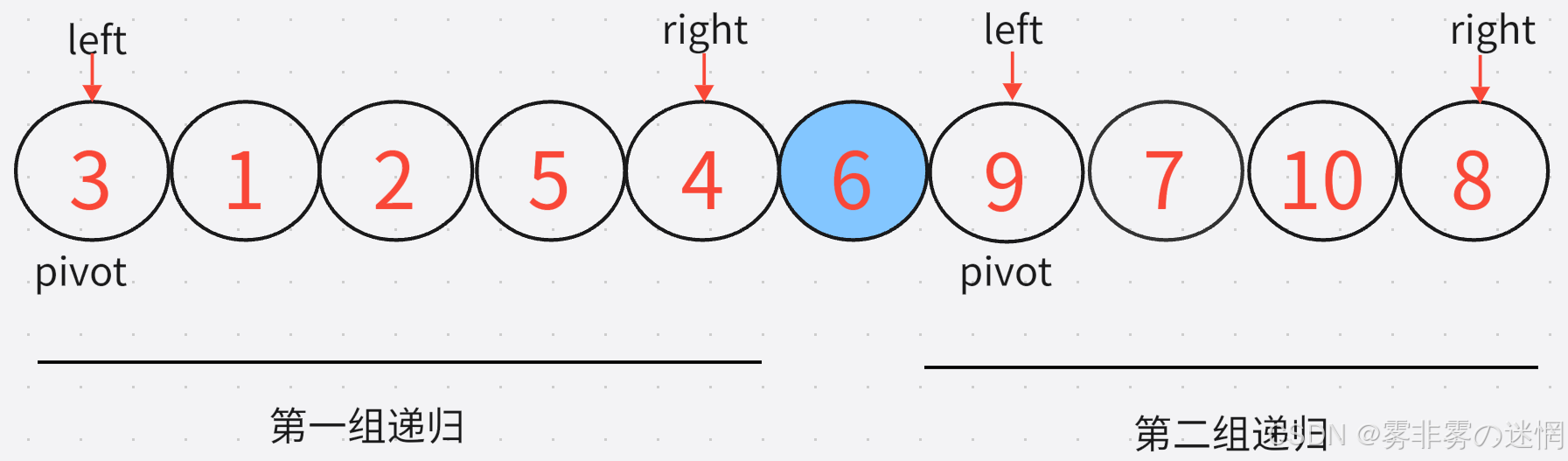
(1)我们的left-- right++ 每次排序已经移到了一起,但是我们每次递归需要从原先的位置开始(这里我不好用语言形容,大家看下面的图!)所以咱们需要记录left right的初始位置,每次调用函数可以初始化
(2)我们递归需要有结束条件,这个结束条件就是left <= right ,我们循环的条件刚好是left > right,反过来就行!
递归的实现,我们知道第一组结束之后,我们左边的分组起始地点是left ,末尾是pivot-1 ;我们右边的分组初始为pivot+1 ,末尾是right( 如下图理解**)**
第一次排序结束

第n次排序开始

cpp
void Hoare(int* arr, int left, int right, int size)
{
assert(arr);
//递归结束
if (left >= right)
{
return;
}
//记录
int begin = left;
int end = right;
int pivot = left;
//单趟
......
//调用递归
//左边
Hoare(arr, begin, pivot - 1, size);
//右边
Hoare(arr, pivot + 1, end, size);
}
代码优化:
首先我们看下面这个问题:
每次选 pivot 都是选的数组的初始位置,然后不论有序还是无序,每次分区只能减少一个元素,导致递归深度为O(n),时间复杂度写死了为O(n^2)
优化方式:如果我们随机选择 pivot 那么可以使得最坏情况发生的概率为 n^2 / 1,从而保证平均时间复杂度为 O(n logn)
解释:为哈选择随机位置之后需要交换 pivot 处的数据与数据开始的位置?
(1)简化逻辑分区,我们是将基准值的位置作为分区的起点,左分区从【left ,pivot-1 】开始移动,寻找大于等于基准值的元素;右分区从【pivot+1 , right】开始移动,找小于等于基准值的元素
(2)避免额外判断,如果基准值保留在原位置,分区时需要处理pivot跨越数组界限的问题,交换到初始位置后,分区逻辑只需要关注左右left right的移动
cpp
//记录
int begin = left;
int end = right;
//随机生成下标
int randIndex = left + rand() % (right - left + 1);
//交换生成的下标与数组初始位置
Exchange(&arr[left], &arr[randIndex]);
int pivot = left;优缺点分析:
Hoare排序是一种高效的平均O(n logn )排序算法,原地排序,适合大数据,但是它属于不稳定排序,未优化之前可能出现O(n^2)的时间复杂度,总的来说优化性能更佳,处理重复元素表现更好
小编寄语
数据排序的精妙还未结束,【上篇】的算法对比【中篇】,难度又提升了!但是小编已经将思路进行了拆分讲解,相信看几遍也可以理解,再也不用担心自己在哪个细节会犯错了!随着难度的升级,【下篇】将更加精彩,是指针排序?还是又是你从未见过的新排序?关注我,带你揭开【下篇】的面纱!