1. 准备测试脚本
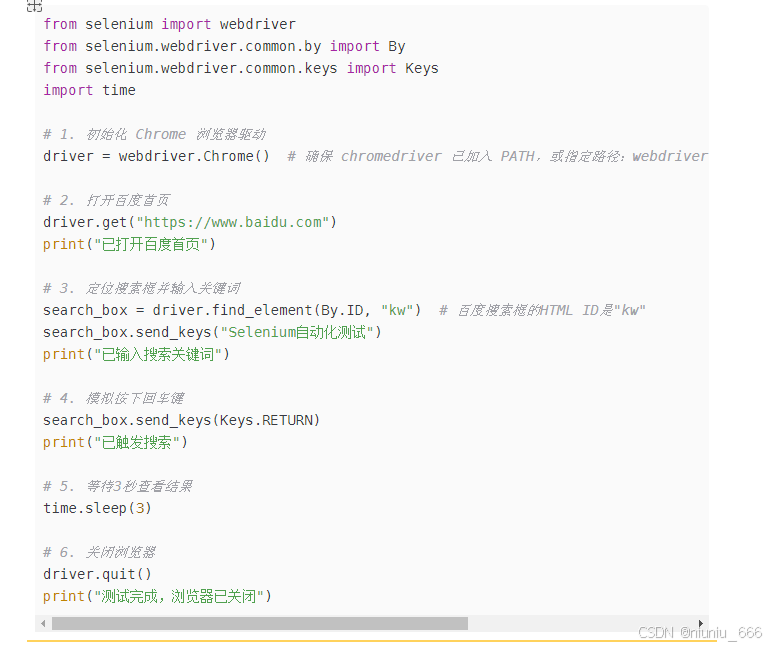
以下是一个完整的 Python 示例脚本,功能是 打开 Chrome 浏览器,访问百度并搜索关键词:
python
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
# 1. 初始化 Chrome 浏览器驱动
driver = webdriver.Chrome() # 确保 chromedriver 已加入 PATH,或指定路径:webdriver.Chrome(executable_path="chromedriver路径")
# 2. 打开百度首页
driver.get("https://www.baidu.com")
print("已打开百度首页")
# 3. 定位搜索框并输入关键词
search_box = driver.find_element(By.ID, "kw") # 百度搜索框的HTML ID是"kw"
search_box.send_keys("Selenium自动化测试")
print("已输入搜索关键词")
# 4. 模拟按下回车键
search_box.send_keys(Keys.RETURN)
print("已触发搜索")
# 5. 等待3秒查看结果
time.sleep(3)
# 6. 关闭浏览器
driver.quit()
print("测试完成,浏览器已关闭") 2. 运行步骤
-
确保环境正确:
-
Chrome 浏览器已安装(如版本 109)。
-
chromedriver版本与 Chrome 匹配(参考之前回答的版本建议)。 -
脚本保存为
.py文件(如test_baidu.py)。
-
-
执行脚本:
pythonpython test_baidu.py -
预期结果:
-
自动打开 Chrome 浏览器,访问百度。
-
输入关键词并搜索,停留3秒后关闭。
-
3. 关键点说明
(1) 元素定位方式
-
By.ID:通过 HTML 元素的id属性定位(如百度搜索框的id="kw")。 -
其他常用定位方式:
pythondriver.find_element(By.NAME, "wd") # 通过 name 属性 driver.find_element(By.CLASS_NAME, "s_ipt") # 通过 class 属性 driver.find_element(By.XPATH, "//input[@id='kw']") # 通过 XPATH
(2) 常见操作
-
输入文本 :
element.send_keys("文本") -
点击按钮 :
element.click() -
模拟按键 :
send_keys(Keys.RETURN)(回车键)
(3) 等待机制
-
强制等待 :
time.sleep(3)(简单但不推荐长期使用)。 -
隐式等待(全局生效):
pythondriver.implicitly_wait(10) # 最多等待10秒 -
显式等待(推荐):
pythonfrom selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC element = WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.ID, "kw"))
4. 可能遇到的问题及解决
问题1:WebDriverException: Message: 'chromedriver' executable needs to be in PATH
-
原因 :未正确配置
chromedriver路径。 -
解决:
-
将
chromedriver.exe放到 Python 安装目录的Scripts文件夹中。 -
或在代码中指定路径:
pythondriver = webdriver.Chrome(executable_path="C:/path/to/chromedriver.exe")
-
问题2:浏览器闪退
-
原因 :脚本结束后未调用
driver.quit()。 -
解决 :确保最后调用
driver.quit()释放资源。
问题3:元素找不到(NoSuchElementException)
-
原因:页面未加载完或定位方式错误。
-
解决:
-
添加等待(如显式等待)。
-
检查元素属性是否动态变化(用浏览器开发者工具确认)。
-
5. 扩展场景
示例:登录网站并截图
python
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://example.com/login")
# 输入用户名密码
driver.find_element(By.ID, "username").send_keys("testuser")
driver.find_element(By.ID, "password").send_keys("password123")
# 点击登录按钮
driver.find_element(By.XPATH, "//button[@type='submit']").click()
# 截图保存
driver.save_screenshot("login_success.png")
driver.quit() 总结
-
基础流程:启动浏览器 → 定位元素 → 操作 → 关闭。
-
核心技巧:合理使用等待、多种定位方式和异常处理。
-
调试工具:浏览器开发者工具(F12)检查元素属性。