导 读INTRODUCTION

2月28日,哈尔滨工业大学举办了"大模型原理、技术与应用------从GPT到DeepSeek"主题讲座,邀请哈工大人工智能研究院副院长、计算学部赛尔实验室副主任车万翔教授作为主讲嘉宾,讲座从自然语言处理的概念和发展历史出发,逐步深入,举GPT系列为例来讲解大模型的基本原理,引出如今炙手可热的DeepSeek-R1的技术细节,最后展望了人工智能发展的未来趋势。可谓干货满满。相信我,看完这个讲座,你会发现你对DeepSeek-R1模型的理解从未如此透彻!
如果感兴趣的话,根据下方提示可以自取哈。
点击下载 →哈工大:《大模型原理、技术与应用---从GPT到DeepSeek》
开启你的 DeepSeek 之旅吧!
以下是对这些核心内容的简要概述:

一、自然语言处理的概念和发展历史
语言是人类交流思想、表达情感最自然、最深刻、最方便的工具。自然语言处理(Natural Language Processing,NLP)指的是用计算机来理解和生成自然语言的各种理论和方法,需要更强的抽象和推理能力。随着技术的发展,自然语言处理成为制约人工智能取得更大突破和更广泛应用的瓶颈。


二、GPT系列模型
GPT(Generative Pre-trained Transformer)是OpenAI在2018年公布的预训练模型,采用语言模型预训练任务,实现了三大创新:使用建模能力更强的 Transformer 模型、在目标任务上精调整个预训练模型、接入的下游任务模型可以非常简单。2020年,OpenAI联合微软推出GPT-3,该模型达到了1750亿参数,无需训练,便可完成"文本"生成任务。但并不能克服深度学习模型鲁棒性差、可解释性弱、推理缺失的瓶颈,在深层次语义理解上与人类认知水平还相去较远。
2022年11月,ChatGPT的推出,初步给出了解决方案。ChatGPT有三大关键的核心技术:无监督学习、有监督学习和强化学习。
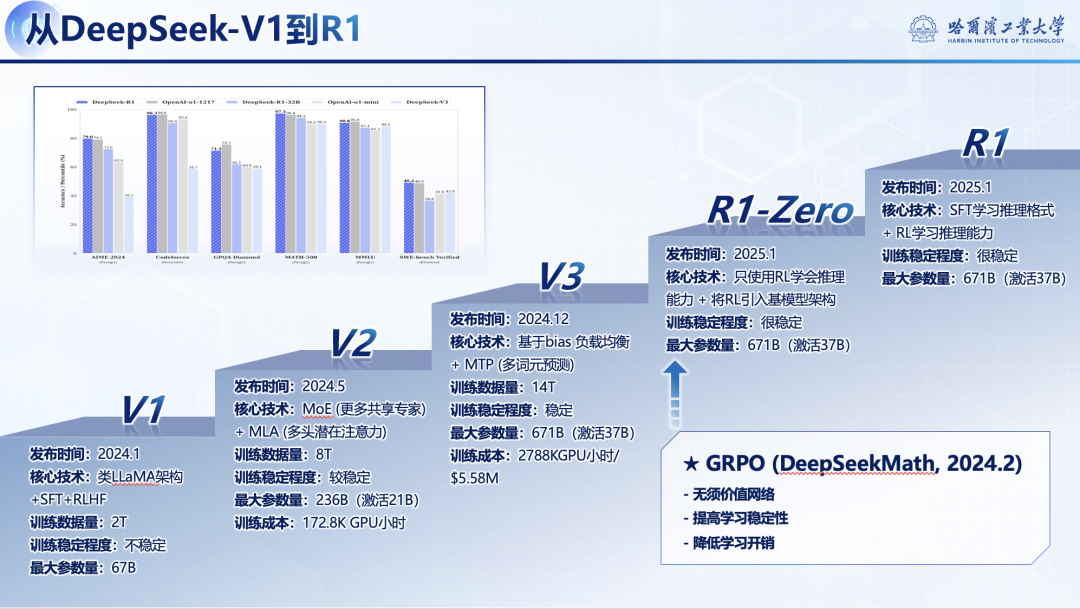
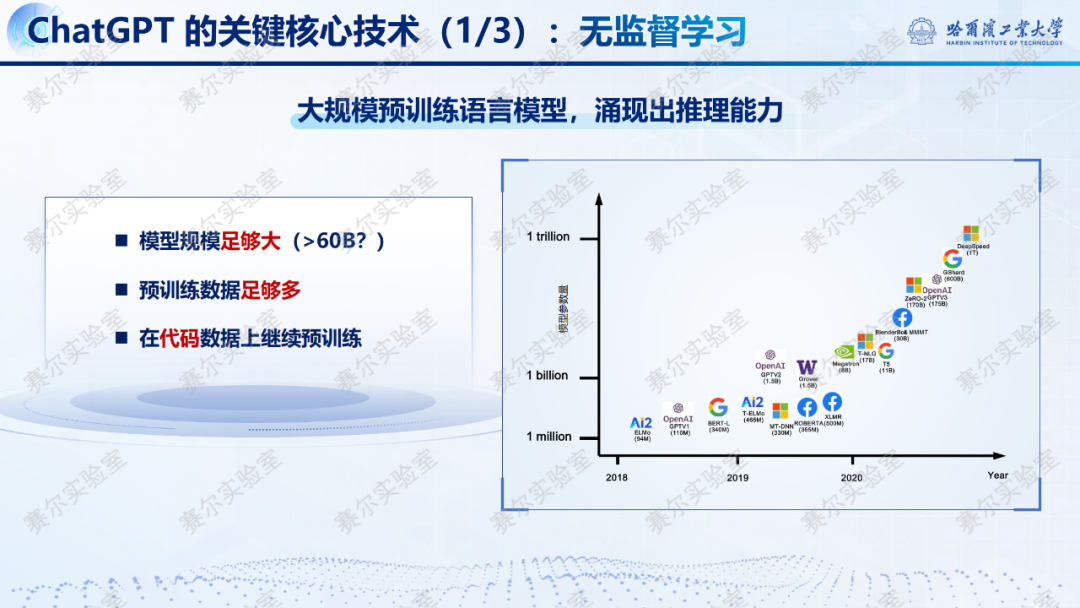
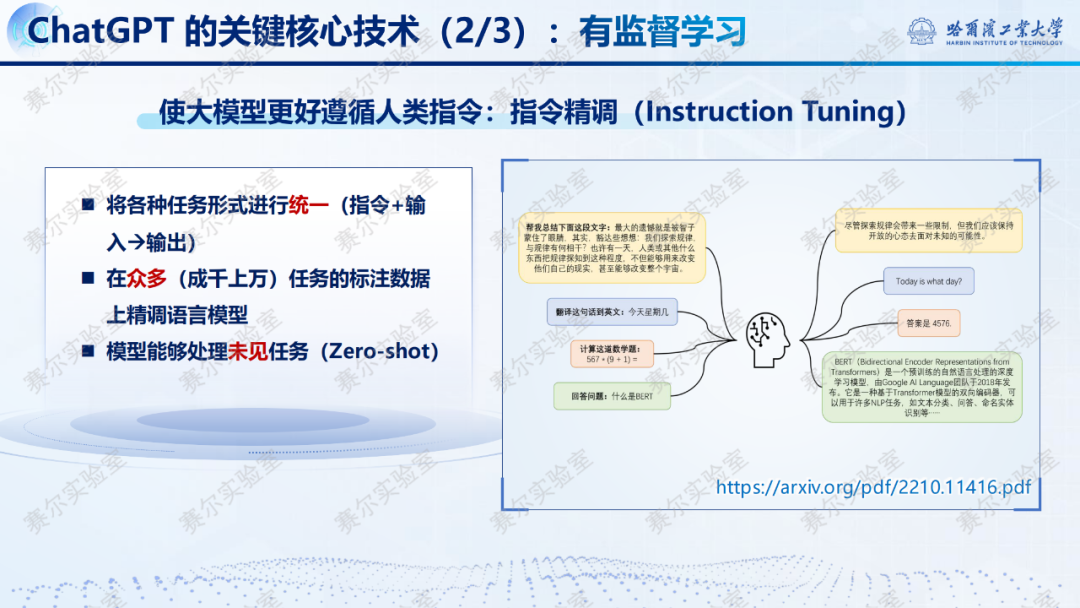
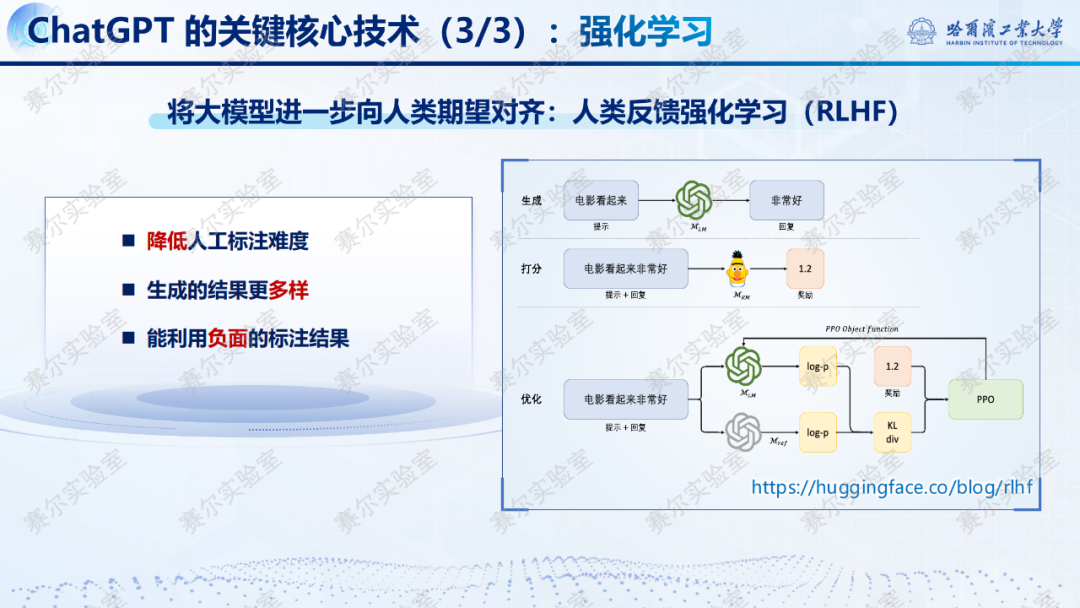
三、DeepSeek-R1和DeepSeek-R1-Zero
ChatGPT的出现引爆了"百模大战"。2025年初,DeepSeek-R1横空出世,被Nature News评价为:"中国的廉价且开源的大型语言模型震撼了科学界!"。

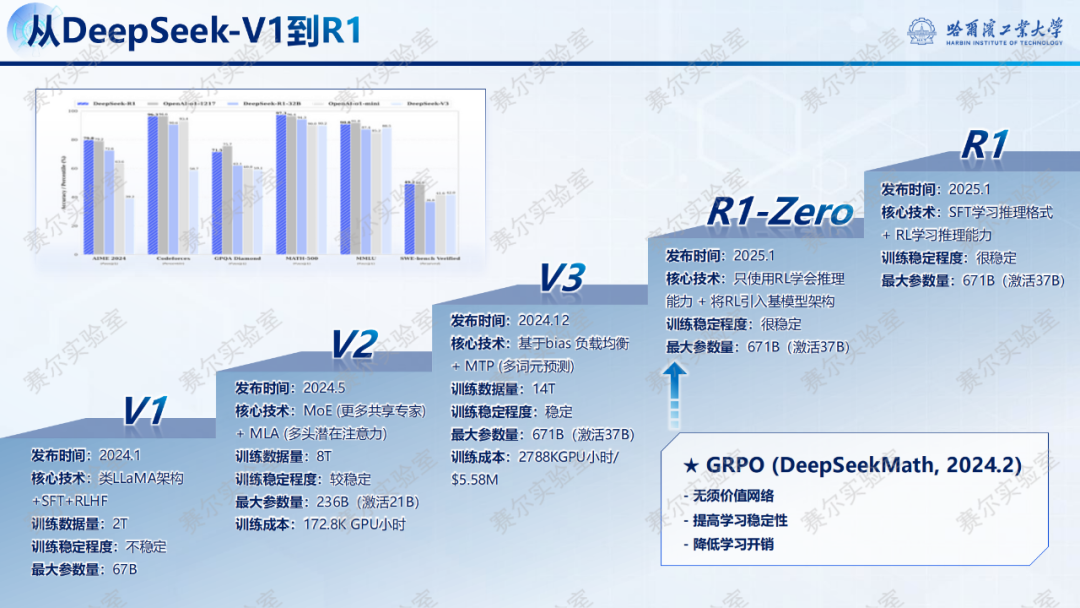
DeepSeek-R1的核心贡献有以下三点:
-
只用RL习得推理能力------只使用强化学习(RL),模型自主学习到推理能力,性能接近o1模型;
-
极致的模型架构优化------训练、推理速度更快,远超o1类模型,极大节约硬件成本 ;
-
开源模型及蒸馏模型------DeepSeek坚持开源精神,开放了 R1模型及其蒸馏出的子模型。
DeepSeek-R1的出现,还引发了自然语言处理的第六次范式变迁,而其中最核心的就是推理采用的思维链技术(Chain-of-Thought, COT)。除此以外,讲座还详细介绍了DeepSeek的强化学习实现的技术细节:GRPO框架、奖励模型、训练的技术路线和模型架构优化技术等。
四、大模型的应用
这一部分主要介绍了大模型在当今社会的应用情况,包括:Prompt工程、检索增强生成、AI智能体等;并介绍了哈工大SCIR大模型方向规划,实现的成果包括:"活字"对话大模型、"珠算"代码大模型、"本草"医学大模型、人机融合医疗会诊平台、软硬一体机器脑系统、基于大模型的精神健康计算系统等。
五、人工智能未来的发展方向
讲座的最后总结了人工智能未来的发展方向,即探索通往通用人工智能的道路------如何使模型具有创新能力?
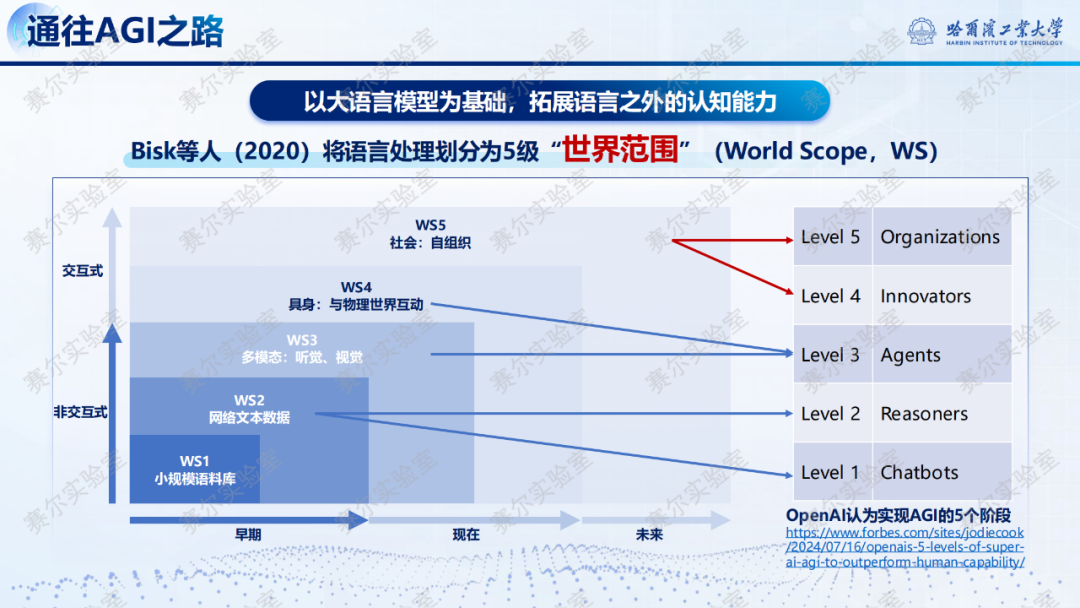
篇幅有限以上只是部分内容概览
来源:哈尔滨工业大学社会计算与交互机器人研究中心、赛尔实验室