绪论:冲击蓝桥杯一起加油!!
每日激励:"不设限和自我肯定的心态:I can do all things。 --- Stephen Curry"
**绪论:早关注不迷路,话不多说安全带系好,发车啦(建议电脑观看)。**

递归
1. 什么是递归
简单来说:就是函数自己调用自己
2. 为什么会用到递归
常见的递归有:二叉树的遍历、快排、归并
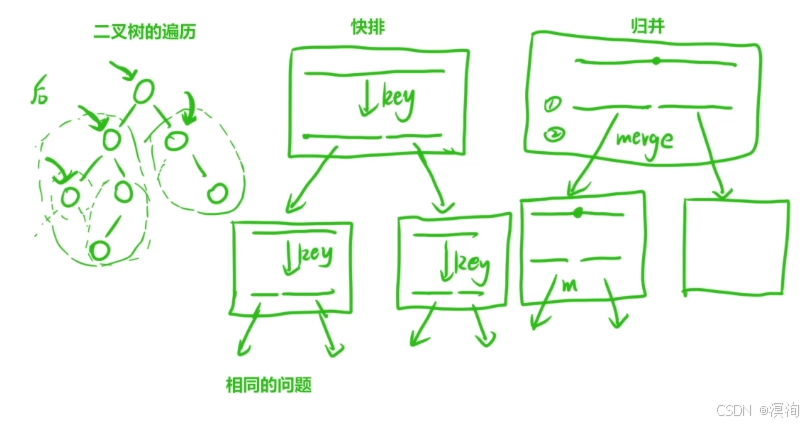
其中递归的本质:
- 解决主问题,衍生相同的子问题
- 在处理子问题的时候,又出现了相同的子问题
- 所以本质就是不断自己调用自己,通过缩小问题最终解决最小子问题
3. 如何理解递归(非常重要!)
对于理解递归,可以从下面三个方向理解:
- 递归展开的细节图
- 二叉树中的题目
- 宏观看待递归的过程
- 不要在意递归的展开图
- 把递归的函数当成一个黑盒(具体里面如何操作关心,给他数据,返回结果)
- 相信这个黑盒一定能完成这个任务
(这个后面慢慢的到来,请继续往后看)
4. 如何写好一个递归?
- 先找到相同的子问题
- 根据子问题:决定了函数头的设计
- 本质也就是分析题目,然后得出解决子问题可能需要用到的参数(一般来说可以先粗力度的得到一个函数头,然后再在编写代码中不断弥补)
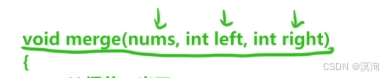
- 只关心某个子问题是如何解决的
- 把他看成一个黑盒,并相信他能够替你完成任务
- 也就决定了函数体的书写,我们仅仅去想某个子问题的解决方法
- 因为这样再次调用该函数的时候,虽然条件参数可能不同,但子问题的解决方法是一致的
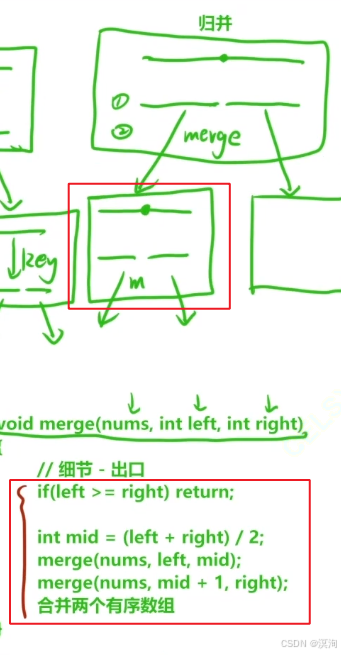
- 最后再注意一下递归函数的出口即可
- 也就是防止无限递归的情况
总结:解决简单递归的三步:
非常重要,不过通过大量练习相信你就能很好的理解(可能初次看会迷糊~)
- 通过题目写出dfs的函数头
- 根据子问题写出函数内部逻辑
- 注意一下递归出口
深度优先遍历 vs 宽度优先遍历 vs 暴搜
-
深度优先遍历(搜索)dfs(depth):
- 通俗的来说就是:一条路走到黑
- 通俗的来说就是:一条路走到黑
-
宽度优先遍历(搜索)bfs(Breadth):
- 本质也就是:一层一层的遍历树
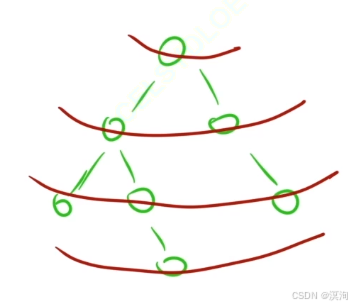
- 本质也就是:一层一层的遍历树
-
搜索(暴搜):
- 本质就是暴力枚举一遍所有的情况,或者说就是将树中的所有节点都进行一次遍历
-
搜索问题的拓展:
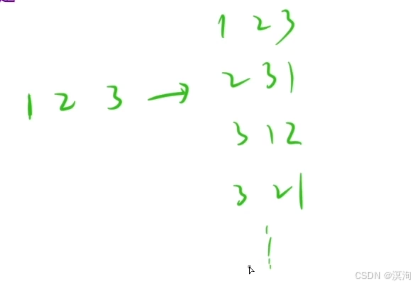
拿全排列问题举例:
全排列是将一组数中的所有情况排出来(如下图)
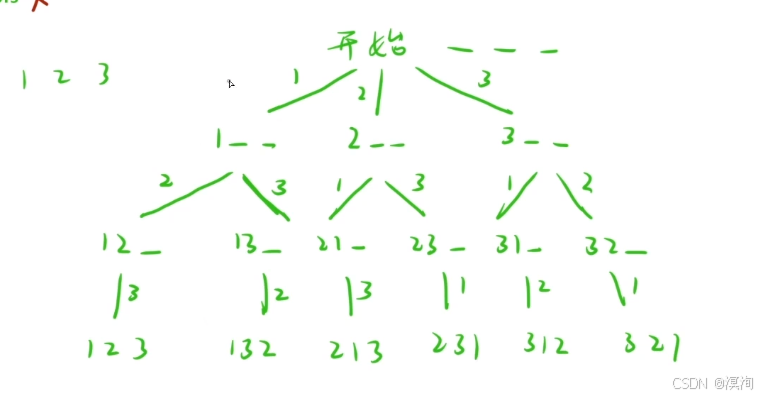
那么可以使用树状图(决策树)的方式解决具体如下图
此时画出来后,我们需要的答案最终就能通过递归搜索的方式获取到:
所以说我们不能对于dfs、bfs来说局限于二叉树,而是当我们能画出类似的决策树的形式画出来那么就能使用dfs/bfs
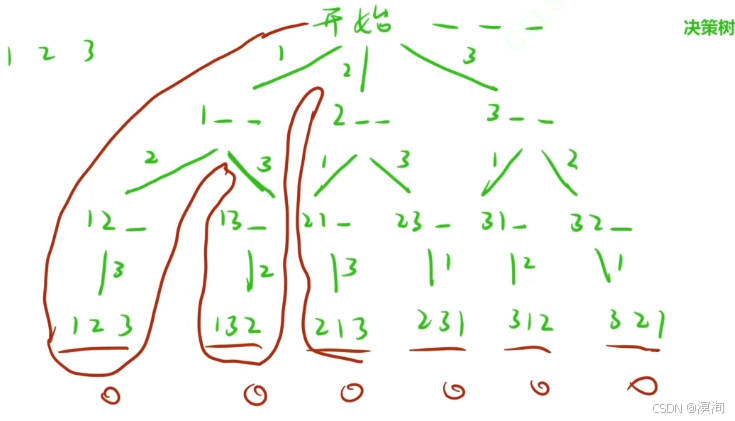
回溯与剪枝(非常重要!)
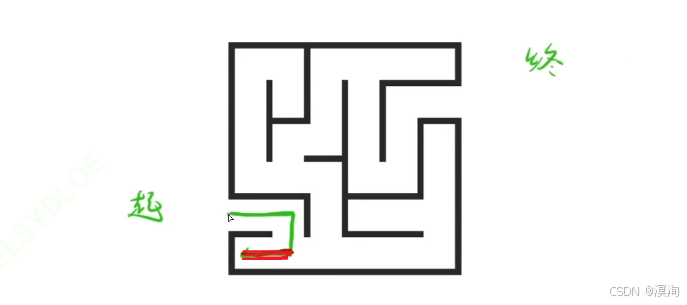
- 回溯的本质:其实就是深搜中当我们尝试某种情况时,发现这种情况行不通,退回到上一级的操作就是回溯
(如下图红线)
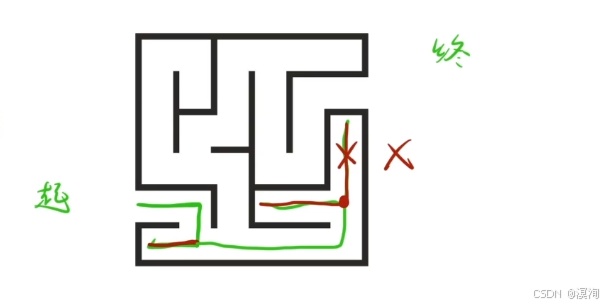
- 剪枝来说:在我们回溯过程后可能遇到两种可以走的情况,而其中一种情况已经走过了知道行不通,那么这条路就代表被剪枝了
(具体如下图)
下面将通过5道题目带你理解递归,其中注意理解递归的三步(函数头,函数体,递归出口)
具体训练:
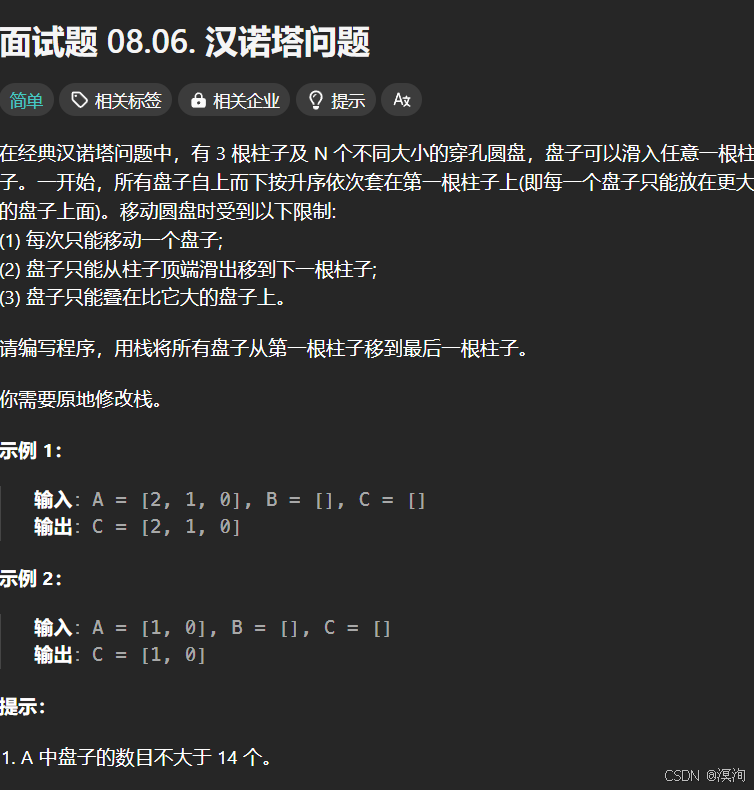
1. 汉诺塔
题目:
分析题目并提出,解决方法:

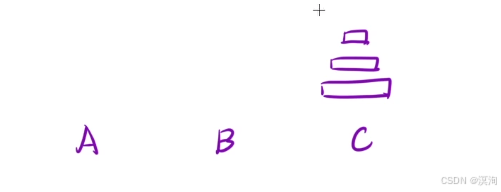
在过程中不允许大盘子摞在小盘子上面!
题解核心逻辑:
汉诺塔问题,可以用递归解决
如何来解决汉诺塔问题?
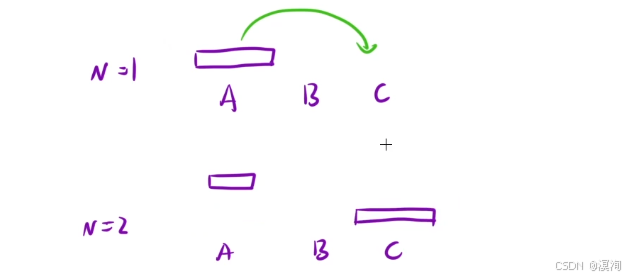
- 在N >= 2 时,我们要考虑先将最大的盘子放到 C柱上
问题就转移成了:
- 先把最大盘子上面的所有先放在B柱上,然后在移动 最大的盘子 到C柱
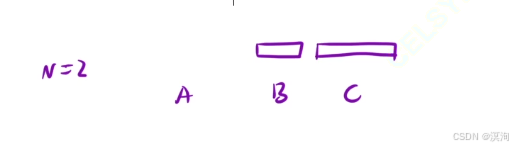
- 第三步就是将所有B柱上的盘子在移动到C柱上
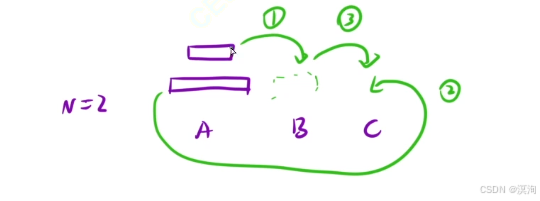
- 再次理解:当N = 3时,看最上面的两个盘子,它的本质其实就是N = 2的情况,只不过这次是移动到B柱

- 这里注意理解的是:操作1和操作3的本质是一样的,只不过借助的柱子不一样!
- 那么 N = ... 他们的本质都是一样了,他们都是:
- 执行步骤1,将最大盘子上面的小盘子全部转移到B
- 执行步骤2,将最大盘子全部转移到C
- 执行步骤3,再将B上的转移到C即可完成
- 所以为什么可以用递归:解决大问题的时候,出现了相同的子问题,解决子问题的时候又出现了相同的子问题
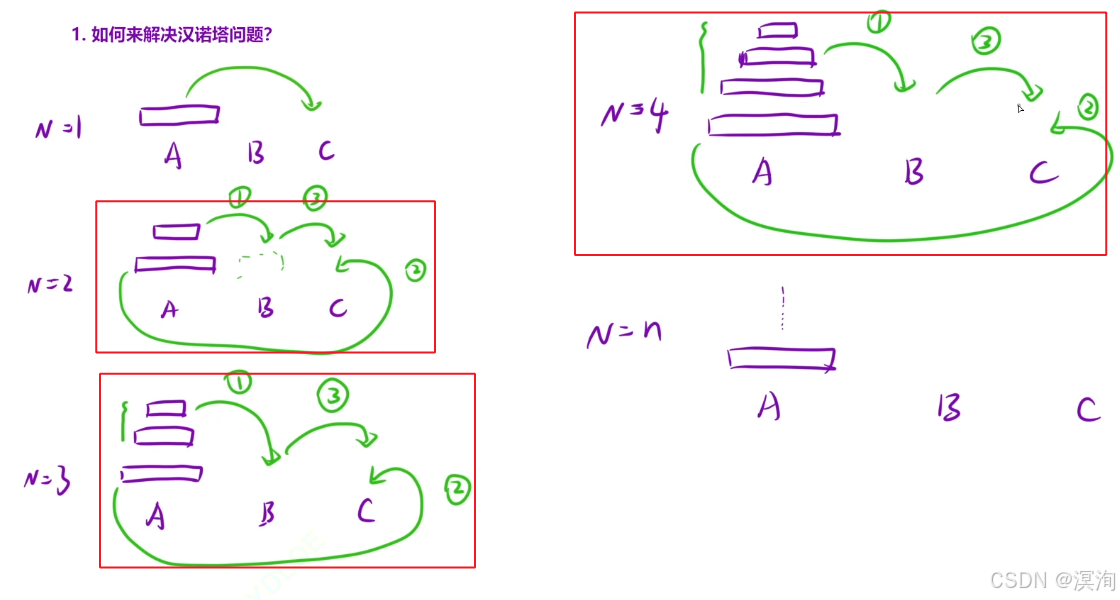
如何写代码:
- 挖掘重复子问题(函数头)
- 也就是上面的 步骤 1、 2、3所需要的
- 该题本质是:将 x 柱上的一堆盘子,借助 y 柱子,转移到 z 柱子上
- 那么函数头也就如下图
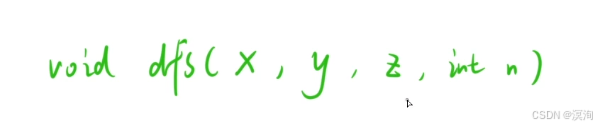
- 只关心某一个子问题在做什么(函数体)
- 宏观的分析三个步骤的具体:

- 宏观的分析三个步骤的具体:
- 函数出口
- 不难发现就是 N = 1 的时候是不同的,直接将A柱的盘子直接放到C柱上
- 那么当N=1时,将A柱的盘子直接放到C柱上,然后就可以退出了

具体步骤代码如下:
cpp
class Solution {
public:
//1. 挖掘重复子问题(得出函数头)
//将n个盘子移动到 借助柱子移动到目标柱子
void h(vector<int>& A, vector<int>& B, vector<int>& C,int n){
//出口:
if(n == 1){
// 将 A 上的移动到 C上
C.push_back(A.back());
A.pop_back();
return ;
}
//2. 分析子问题:(得到函数体所需要的操作,并且相信他能完成)
//先将 A 柱上的 n-1 个移动到 B盘
h(A,C,B,n-1);
//将 A 中的最后一个盘子移动到 C上
C.push_back(A.back());
A.pop_back();
//在将B上的盘子借助A全部移动到C上
h(B,A,C,n-1);
}
void hanota(vector<int>& A, vector<int>& B, vector<int>& C) {
h(A,B,C,A.size());
}
};2. 合并两个有序链表
题目:
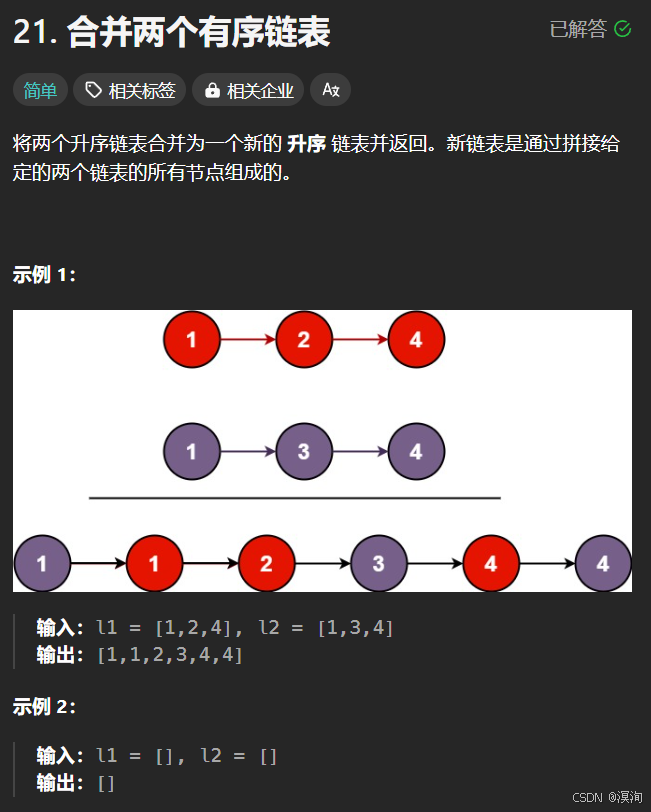
分析题目并提出,解决方法:
题目很好理解:就是拼接两个链表,过程中不允许创建空间
分析本题查看是否有重复子问题:
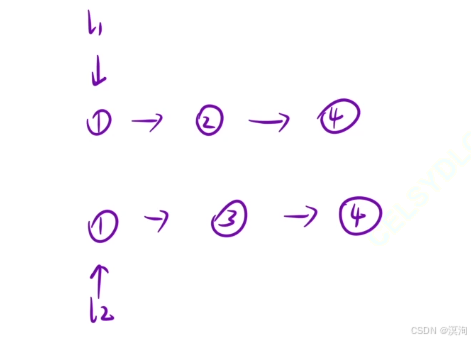
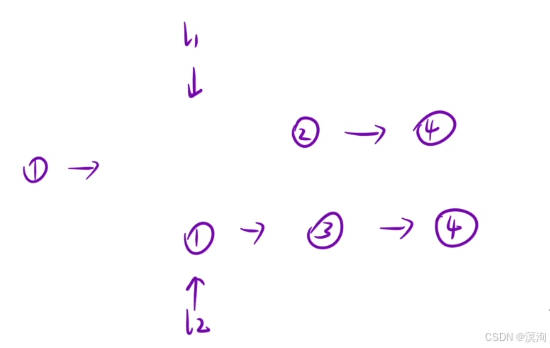
-
重复子问题(函数头的设计)
- 合并两个有序链表
- 那么也就仅需要两个 链表

-
只关心某个子问题(函数体的设计)
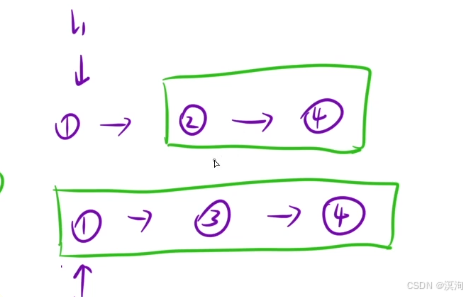
- 比大小(两个链表进行比较)得到较小的结点
- 将较小的结点看做合并后的链表头结点(通过修改该结点的next指针完成)
- 最终返回 较小的结点
-
递归出口
- 那个指针先为空返回另外一个指针
总结:递归 = 重复子问题 + 宏观看待递归问题
题解核心逻辑:
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
//分析函数的目的:合并两个链表:所以函数头就是 两个链表即可
ListNode* mergeTwoLists(ListNode* list1, ListNode* list2) {
//编写出口:判断那个链表先为空,返回另外一个
if(list1 == nullptr) return list2;
if(list2 == nullptr) return list1;
//编写子问题的具体操作:完成函数体
//1. 找到较小的
if(list1->val <= list2->val){
list1->next = mergeTwoLists(list1->next,list2);
return list1;
}else{
list2->next = mergeTwoLists(list1,list2->next);
return list2;
}
}
};小总结:
递归 VS 深搜
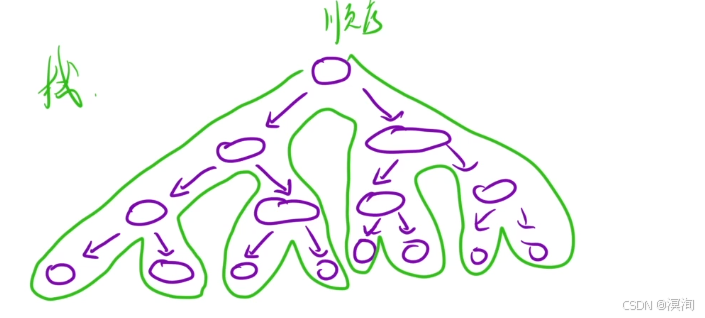
递归的展开图,其实就是对一棵树做一次深度优先遍历(dfs)
而在递归的过程中需要一个 栈 进行保存,历史数据
循环(迭代) vs 递归
它们是能相互转换的,那么什么时候,用哪一个呢?
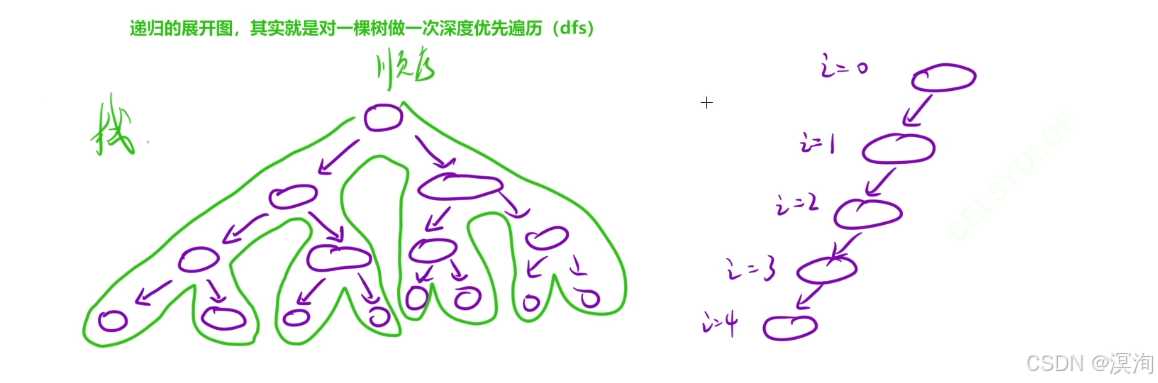
通过上面的分析和上图理解到:
- 当我们的一个遍历过程需要用到类似栈的东西进行保存数据时,就是比较麻烦的情况了,此时我们使用递归的形式就能很简单方便的写出程序
- 而当一些遍历过程比较简单,如上图右边结构,此时遍历仅仅只需要单方向的那么,此时就没必要使用递归,因为一个简单的遍历循环即可完成
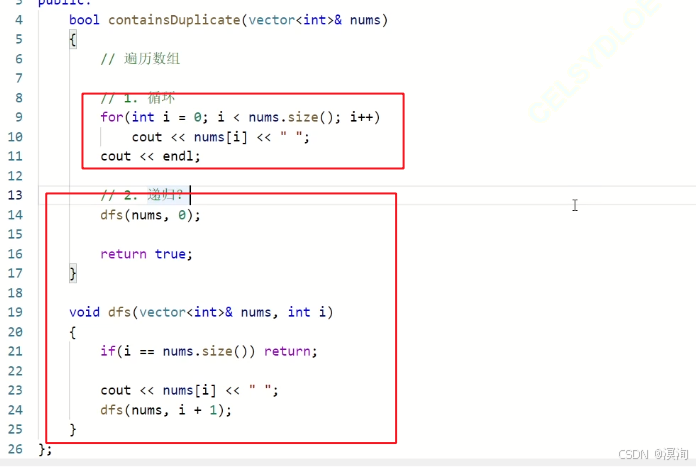
3. 反转链表
题目:
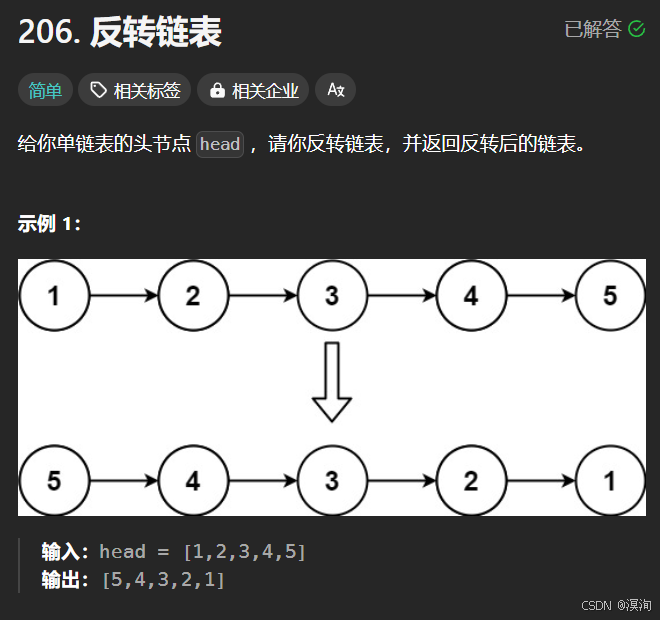
分析题目并提出,解决方法:
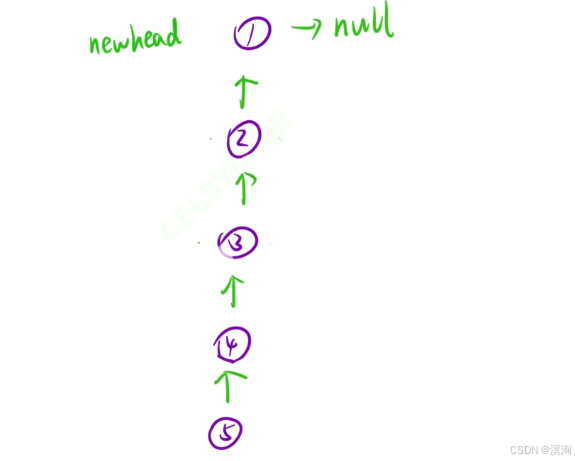
宏观角度看待问题:
- 让当前结点后面的链表先逆序,并且把头结点返回
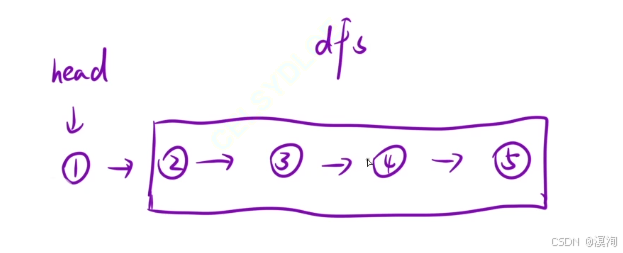
- 让当前结点添加到逆置后的链表
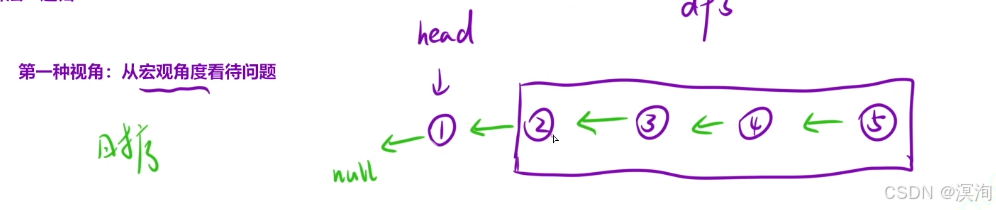
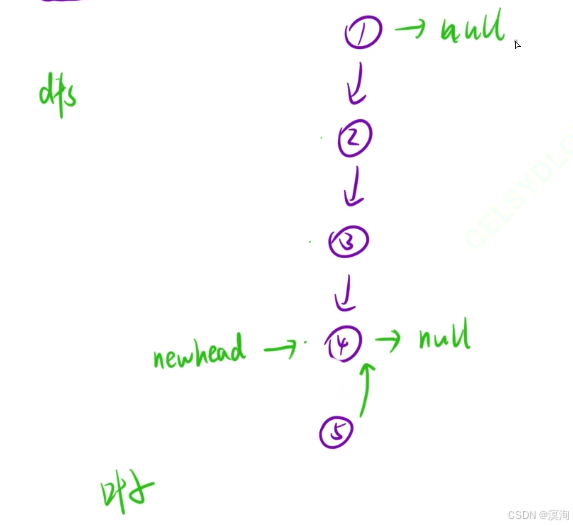
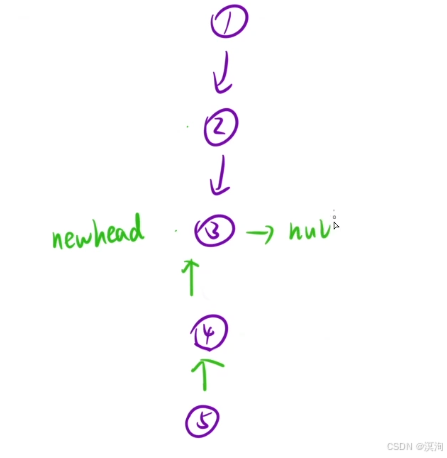
第二个视角:将链表看成一颗树:
- 不断深度遍历到最后一个结点
- 返回最后一个结点
- 到达倒数第二层:执行将自己下一个结点的next置为自己,然后自己置为null(这里置为是为了保持所以子操作一致)
题解核心逻辑:
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* reverseList(ListNode* head) {
//使用递归的方式
//宏观的看待问题:
//翻转链表(所以函数头就只需要一个链表即可,还需要返回新头结点)
//子问题(将自己的next的next置为自己,再将自己置为空,并且还需要将最后的头结点返回回来)
//出口:(当head为空时退出,表示遍历到了最后结点)
//head == nullptr 时为了防止没有结点的情况
if(head == nullptr || head->next == nullptr){
return head;//返回结点
}
ListNode* newhaed = reverseList(head->next);
head->next->next = head;
head->next = nullptr;
return newhaed;
}
};4. 两两交换链表中的节点
题目:
分析题目并提出,解决方法:
递归思想(宏观看待):
- 分析题目得到递归思想:将给到的链表中的两两进行交换顺序,那么也就仅需要一个链表参数即可
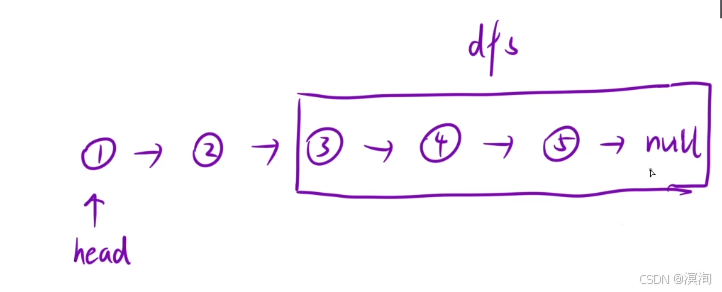
- 看待某个子问题:
- dfs会返回一个新的链表的结点,使用tmp记录
- 将当前head的next的next指向haed,再将head的next指向tmp(完成交换的目的)
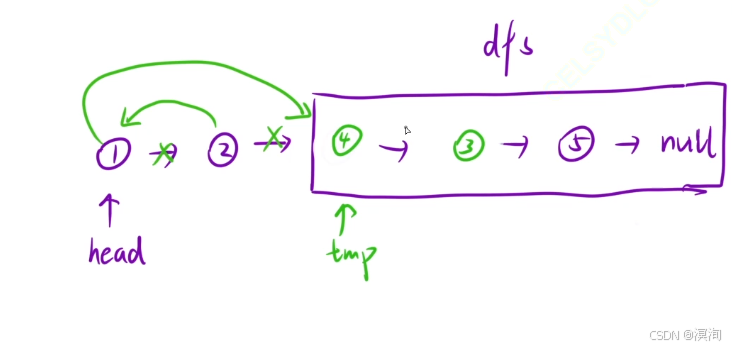
- 退出情况,当head为空是退出
- 注意其中是以两个结点看成一起的,所以退出条件是:
- 当 head为空 || head->next 为空
题解核心逻辑:
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* swapPairs(ListNode* head) {
//退出条件:
if(head == nullptr || head->next == nullptr){
return head;//返回当前结点
}
//子问题:
//1. 获取dfs后面的头结点
ListNode* tmp = swapPairs(head->next->next);
ListNode* ret = head->next;
ret->next = head;
head->next = tmp;
return ret;
}
};5. Pow(x, n)
题目:

分析题目并提出,解决方法:
很好理解 就是 求x n等于多少
解法1:暴力循环,让 x 乘 n 次即可(会超时)
解法二:
快速幂
快速幂的实现:
- 递归实现
- 循环实现
本题将递归实现:
例子:当我们要求 316:
- 就是将 316 不断的对半看(具体如下图)
先求出 38 这样 38 * 38 = 316 同理 38 = 34 * 34 。。。
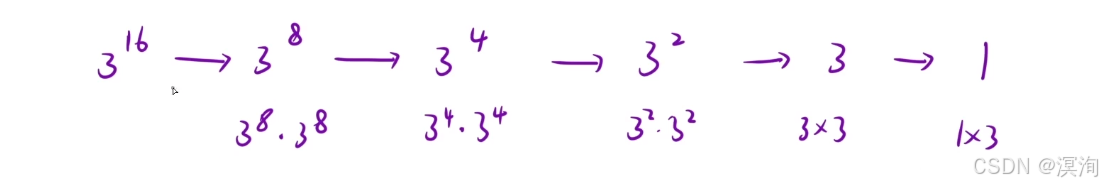
- 其中暴力解法要求 16 次,而使用这种方法只用求logn次
- 附:当 n 为奇数时:多乘一个自身即可
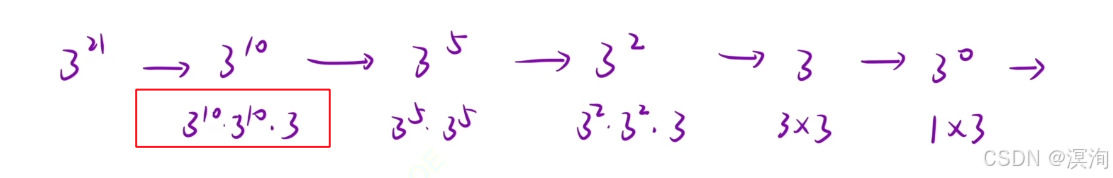
- 相同子问题 -->函数头
- 求一个 x的n次幂 ==> pow(x,n)
- 只关心每个子问题做了什么 -- > 函数体
- 其中需要 判断 n 的奇偶性
- 通过递归获取自身的值,并且判断奇偶性得出是否要多乘1位
- 递归出口
- 当 n == 0 时返回1(这样上层 n = 1 处等于 1 * x(1 * 1 * x))

特殊情况:
- 当 n == 0 时返回1(这样上层 n = 1 处等于 1 * x(1 * 1 * x))
- n 为负数:
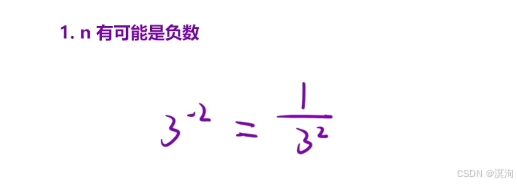
- n 可能是 -231 当变成整数就可能越界,所以得使用long long(整形的范围是 -231 ~ 231 - 1 )
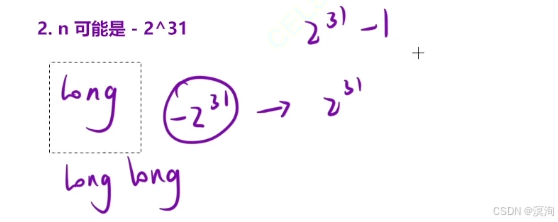
题解核心逻辑:
- 其中注意 -(long long)n 这里的操作:它是将 n 的类型转换成了long long(并且不能写在-前面,只能挨着n)
- 只有这样当 n = -231 时强转为正数后就不会溢出
cpp
class Solution {
public:
double myPow(double x, int n) {
//递归实现:
//将 x^n 看成 x^(n/2) * x^(n/2) ...
return n >= 0 ? pow(x,n) : 1/pow(x,-(long long)n);
}
double pow(double x,long long n){
if(n == 0) return 1;
double tmp= myPow(x,n/2);
return n % 2 == 0 ? tmp * tmp : tmp * tmp * x;
}
};