引入
通过上一篇Spark核心数据结构:RDD,我们深入了解了Spark最核心的RDD,并留下了梳理归类 Transformations 算子和Actions 算子的小作业,下面我把常用的 RDD 算子归类整理到了下面的表格中,结合每个算子的分类、用途和适用场景,这张表格可以让小伙伴们更快、更高效地选择合适的算子来实现业务逻辑。
| 算子类型 | 适用范围 | 算子用途 | 算子集合 | ||
|---|---|---|---|---|---|
| Transformations | 任意RDD | 单个RDD数据转换 | map mapPartitions mapPartitionsWithIndex | filter | flatMap |
| Transformations | 任意RDD | 与其他RDD进行组合 | union intersection | join cogroup cartesian | |
| Transformations | 任意RDD | 数据采样 | sample | distinct | |
| Transformations | 任意RDD | 数据分片的重分布 | coalesce | repartition repartitionAndSortWithinPartitions | |
| Transformations | Paired RDD | 单个RDD数据聚合 | groupByKey sortByKey | reduceByKey aggregateByKey | |
| Actions | 任意RDD | 收集数据到SparkDriver | collect first take | takeSample takeOrdered | count |
| Actions | 任意RDD | 数据持久化到存储系统 | saveAsTextFile saveAsSequenceFile saveAsObjectFile | ||
| Actions | 任意RDD | 函数式编程副作用操作 | foreach |
本文我们先来学习同一个 RDD 内部的数据转换。掌握 RDD 常用算子是做好 Spark 应用开发的基础,而数据转换类算子则是基础中的基础。
学习 RDD 算子也是一样,要想动手操作这些算子,咱们得先有 RDD 才行。所以,接下来我们就先看看 RDD 是怎么创建的。
创建 RDD
在 Spark 中,创建 RDD 的典型方式有两种:
- 通过 SparkContext.parallelize 在内部数据之上创建 RDD;
- 通过 SparkContext.textFile 等 API 从外部数据创建 RDD
这里的内部、外部是相对应用程序来说的。开发者在 Spark 应用中自定义的各类数据结构,如数组、列表、映射等,都属于"内部数据";而"外部数据"指代的,是 Spark 系统之外的所有数据形式,如本地文件系统或是分布式文件系统中的数据,再比如来自其他大数据组件*(Hive、Hbase、RDBMS 等)*的数据。
parallelize
第一种创建方式的用法非常简单,只需要用 parallelize 函数来封装内部数据即可。
Scala实现案例
java
object TestTransformations {
/**
* 程序的入口点。
*
* @param args 命令行参数,在本程序中未使用。
*/
def main(args: Array[String]): Unit = {
// 创建一个 Spark 配置对象,设置应用程序名称为 "TestTransformations",并使用本地模式运行,使用所有可用的 CPU 核心
val conf = new SparkConf().setAppName("TestTransformations").setMaster("local[*]")
// 使用配置对象创建一个 Spark 上下文对象
val sc = new SparkContext(conf)
// 定义一个包含字符串的数组
val words: Array[String] = Array("a","b","c","d")
// 将数组并行化为一个 RDD(弹性分布式数据集),以便在 Spark 集群上进行分布式处理
val rdd: RDD[String] = sc.parallelize(words)
}
}Python实现案例
python
from pyspark import SparkConf, SparkContext
conf = SparkConf().setAppName("TestTransformations").setMaster("local[*]")
sc = SparkContext.getOrCreate(conf)
rdd=sc.parallelize(["a","b","c","d"])
print(rdd.collect())
Java实现案例
java
public class TestTransformations {
/**
* 程序的主入口点。
*
* @param args 命令行参数
*/
public static void main(String[] args) {
// 创建一个Spark配置对象
SparkConf conf = new SparkConf();
// 设置Spark应用程序的运行模式为本地模式
conf.setMaster("local[*]");
// 设置Spark应用程序的名称
conf.setAppName("TestTransformations");
// 使用配置对象创建一个JavaSparkContext实例
JavaSparkContext sc = new JavaSparkContext(conf);
// 使用SparkContext创建一个包含字符串元素的JavaRDD,并将其分区数设置为3
JavaRDD<String> words = sc.parallelize(Arrays.asList("a", "b", "c", "d"), 3);
}
}textFile
通常来说,在 Spark 应用内定义体量超大的数据集,其实都是不太合适的,因为数据集完全由 Driver 端创建,且创建完成后,还要在全网范围内跨节点、跨进程地分发到其他 Executors,所以往往会带来性能问题。因此 parallelize API 的典型用法,是在"小数据"之上创建 RDD。
要想在真正的"大数据"之上创建 RDD,我们还得依赖第二种创建方式,也就是通过 SparkContext.textFile 等 API 从外部数据创建 RDD。由于 textFile API 比较简单,而且它在日常的开发中出现频率比较高,因此我们使用 textFile API 来创建 RDD。在后续对各类 RDD 算子讲解的过程中,我们都会使用 textFile API 从文件系统创建 RDD。
我们在Spark的Why&How就使用了textFile的方法去创建RDD,为了方便小伙伴们查看,下面我们仅将相关核心代码贴过来。
Scala实现案例
Scala
// 读取 spark.txt 文件
val lines: RDD[String] = sc.textFile("D:\\SparkStudy\\src\\main\\resources\\spark.txt")Python实现案例
python
// 读取 spark.txt 文件
rdd=sc.textFile("D:\\SparkStudy\\src\\main\\resources\\spark.txt");
Java实现案例
java
// 读取 spark.txt 文件
JavaRDD<String> lines = sc.textFile("D:\\SparkStudy\\src\\main\\resources\\spark.txt");RDD 内的数据转换
首先,我们先来认识一下 map 算子。毫不夸张地说,在所有的 RDD 算子中,map的使用概率是最高的。因此我们必须要掌握 map 的用法与注意事项。
map:以元素为粒度的数据转换
我们先来说说 map 算子的用法:给定映射函数 f,map(f) 以元素为粒度对 RDD 做数据转换。其中 f 可以是带有明确签名的带名函数,也可以是匿名函数,它的形参类型必须与 RDD 的元素类型保持一致,而输出类型则任由开发者自行决定。
直接看介绍对新手不太友好,接下来我们用些小例子来更加直观地展示 map 的用法。
我们使用如下代码,把包含单词的 RDD 转换成元素为(Key,Value)对的 RDD,这类RDD被称为 Paired RDD。
Scala实现案例
Scala
val kvRDD: RDD[(String,Int)] = rdd.map(word =>(word,1))在上面的代码实现中,传递给 map 算子的形参,例如Scala代码中的 word => (word,1),就是我们上面说的映射函数 f。只不过,这里 f 是以匿名函数的方式进行定义的,其中左侧的 word
表示匿名函数 f 的输入形参,而右侧的(word,1)则代表函数 f 的输出结果。
如果我们把匿名函数变成带名函数的话,可能你会看的更清楚一些。这里我用一段Scala代码重新定义了带名函数 f。
Scala
def f(word:String):(String,Int) = {
return (word,1)
}
val kvRDD: RDD[(String,Int)] = rdd.map(f)可以看到,我们使用 Scala 的 def 语法,明确定义了带名映射函数 f,它的计算逻辑与刚刚的匿名函数是一致的。在做 RDD 数据转换的时候,我们只需把函数 f 传递给 map 算子即可。不管 f 是匿名函数,还是带名函数,map 算子的转换逻辑都是一样的。
学习要学会举一反三,我们可以通过定义任意复杂的映射函数f,然后在 RDD 之上通过调用 map(f) 去翻着花样地做各种各样的数据转换。比如通过定义如下的映射函数 f,我们就可以改写 Word Count 的计数逻辑,也就是把"chaos"这个单词的统计计数权重提高一倍:
Scala
def f(word:String):(String,Int) = {
if(word.equals("chaos")){
return (word,2)
}
return (word,1)
}
val kvRDD: RDD[(String,Int)] = rdd.map(f)下面我们看看 Python 和 Java 是如何实现的。
Python实现案例
Python的实现和 Scala 是非常类似,如下所示:
python
kv_rdd=rdd.map(lambda word:(word,1))上面那个特殊案例,也可以如下实现:
python
def f(word):
if word == "chaos":
return (word, 2)
else:
return (word, 1)
kv_rdd = rdd.map(f)Java实现案例
Java的实现会更麻烦一些,因为是强类型语言,在Java 8以前,也没有Scala那样强大的类型推断能力,所以实现的话会麻烦一些,相比前面两种语言的实现,会需要考虑更多,如下,Java来实现的话,可以有如下两种写法:
java
JavaRDD<Tuple2<String, Integer>> kvRDD = words.map(word -> new Tuple2<>(word, 1));
or
JavaPairRDD<String, Integer> kvRDD = rdd.mapToPair(word -> new Tuple2<>(word, 1));当然,也可以如下实现:
java
JavaPairRDD<String, Integer> kvRDD = rdd.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<>(word, 1);
}
});mapPartitions:以数据分区为粒度的数据转换
尽管 map 算子足够灵活,允许开发者自由定义转换逻辑。不过,就像我们刚刚说的,map(f) 是以元素为粒度对 RDD 做数据转换的,在某些计算场景下,这个特点会严重影响执行效率。为什么这么说呢?
我们来看一个具体的例子。
比方说,我们把 Word Count 的计数需求,从原来的对单词计数,改为对单词的哈希值计数,在这种情况下,我们的代码实现需要做哪些改动呢?
以Scala为例:
Scala
import java.security.MessageDigest
val kvRDD: RDD[(String,Int)] = rdd.map(word => (MessageDigest.getInstance("MD5").digest(word.getBytes).mkString,1))由于 map 是以元素为单元做转换的,那么对于 RDD 中的每一条数据记录,我们都需要实例化一个 MessageDigest 对象来计算这个元素的哈希值。
在生产环境中,一个 RDD 动辄包含上百万甚至是上亿级别的数据记录,如果处理每条记录都需要事先创建 MessageDigest,那么实例化对象的开销就会聚沙成塔,不知不觉地成为影响执行效率的罪魁祸首。
那么问题来了,有没有什么办法,能够让 Spark 在更粗的数据粒度上去处理数据呢?
有的,兄弟有的,mapPartitions 和 mapPartitionsWithIndex 这对"孪生兄弟"就是用来解决类似的问题。相比 mapPartitions,mapPartitionsWithIndex 仅仅多出了一个数据分区索引,因此接下来我们把重点放在 mapPartitions 上面。
还是老样子,我们先来说说 mapPartitions 的用法。mapPartitions,顾名思义,就是以数据分区为粒度,使用映射函数 f 对 RDD 进行数据转换。对于上述单词哈希值计数的例子,我们结合下面的代码,来看看如何使用 mapPartitions 来改善执行性能:
Scala实现案例
Scala
import java.security.MessageDigest
val kvRDD: RDD[(String,Int)] = rdd.mapPartitions(partition => {
// 注意!这里是以数据分区为粒度,获取MD5对象实例
val md5 = MessageDigest.getInstance("MD5")
val newPartition = partition.map(word =>{
// 在处理每一条数据记录的时候,可以复用同一个Partition内的MD5对象
(md5.digest(word.getBytes).mkString,1)
})
newPartition
})在上面的改进代码中,mapPartitions 以数据分区*(匿名函数的形参 partition)*为粒度,对 RDD 进行数据转换。具体的数据处理逻辑,则由代表数据分区的形参 partition 进一步调用 map(f) 来完成。
这和前一个版本的实现的本质上区别在于,我们把实例化 MD5 对象的语句挪到了 map 算子之外。如此一来,以数据分区为单位,实例化对象的操作只需要执行一次,而同一个数据分区中所有的数据记录,都可以共享该 MD5 对象,从而完成单词到哈希值的转换。
这样以数据分区为单位,mapPartitions 只需实例化一次MD5 对象,而 map 算子却需要实例化多次,具体的次数则由分区内数据记录的数量来决定。
对于一个有着上百万条记录的 RDD 来说,其数据分区的划分往往是在百这个量级,因此相比 map 算子,mapPartitions 可以显著降低对象实例化的计算开销,这对于 Spark 作业端到端的执行性能来说,无疑是非常友好的。
实际上。除了计算哈希值以外,对于数据记录来说,凡是可以共享的操作,都可以用 mapPartitions 算子进行优化。这样的共享操作还有很多,比如创建用于连接远端数据库的 Connections 对象,或是用于连接 Amazon S3 的文件系统句柄,再比如用于在线推理的机器学习模型等等。
相比 mapPartitions,mapPartitionsWithIndex 仅仅多出了一个数据分区索引,这个数据分区索引可以为我们获取分区编号,当你的业务逻辑中需要使用到分区编号的时候,就可以考虑使用这个算子来实现代码。除了这个额外的分区索引以外,mapPartitionsWithIndex在其他方面与 mapPartitions 是完全一样的。
Python实现案例
Python的实现相比Scala会复杂一些,需要手动实现类似 map 的逻辑,如下代码所示:
python
import hashlib
def map_partitions(partition):
md5 = hashlib.md5()
for word in partition:
md5.update(word.encode('utf-8'))
yield (md5.hexdigest(), 1)
kv_rdd = rdd.mapPartitions(map_partitions)Java实现案例
Java也是与Python类似,实现也很复杂,参考代码如下:
java
import java.security.MessageDigest
JavaPairRDD<String, Integer> kvRDD = rdd.mapPartitionsToPair(new PairFlatMapFunction<Iterator<String>, String, Integer>() {
@Override
public Iterator<Tuple2<String, Integer>> call(Iterator<String> iterator) throws Exception {
MessageDigest md5 = MessageDigest.getInstance("MD5");
List<Tuple2<String, Integer>> result = new ArrayList<>();
while (iterator.hasNext()) {
String word = iterator.next();
result.add(new Tuple2<>(md5.digest(word.getBytes()).toString(), 1));
}
return result.iterator();
}
});从Python和Java的实现可以更清晰的看到,我们针对每个数据分区,只用实例化一次对象,让对应数据分区可以共享实例化的 MD5 对象,从而完成单词到哈希值的转换。
介绍完 map 与 mapPartitions 算子之后,接下来,我们再来看一个与这两者功能类似的算子:flatMap。
flatMap:从元素到集合、再从集合到元素
flatMap 其实和 map 与 mapPartitions 算子类似,在功能上,与 map 和 mapPartitions一样,flatMap 也是用来做数据映射的,在实现上,对于给定映射函数 f,flatMap(f) 以元素为粒度,对 RDD 进行数据转换。
不过,与前两者相比,flatMap 的映射函数 f 有着显著的不同。对于 map 和 mapPartitions 来说,其映射函数 f 的类型,都是(元素) => (元素),即元素到元素。而 flatMap 映射函数 f 的类型,是(元素) => (集合),即元素到集合(如数组、列表等)。因此,flatMap 的映射过程在逻辑上分为两步:
- 以元素为单位,创建集合;
- 去掉集合"外包装",提取集合元素。
这么说比较抽象,我们还是来举例说明。假设,我们再次改变 Word Count 的计算逻辑,由原来统计单词的计数,改为统计相邻单词共现的次数,例如:
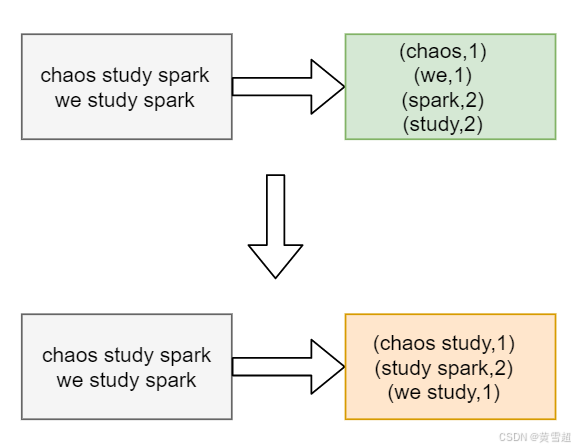
对于这样的计算逻辑,我们可以使用 flatMap 去实现,这里我们先给出代码实现,然后再分阶段地分析 flatMap 的映射过程:
Scala实现案例
Scala
val wordPairRDD: RDD[String] = rdd.flatMap(line =>{
val words: Array[String] = line.split(" ")
for (i <- 0 until words.length-1) yield words(i) + " " + words(i+1)
})在上面的代码中,我们采用匿名函数的形式,来提供映射函数 f。这里 f 的形参是 String 类型的 line,也就是源文件中的一行文本,而 f 的返回类型是 ArrayString,也就是String 类型的数组。在映射函数 f 的函数体中,我们先用 split 语句把 line 转化为单词数组,然后再用 for 循环结合 yield 语句,依次把单个的单词,转化为相邻单词词对。
通过案例我们就能很直观的理解前面的元素到集合,再从集合到元素的转换,下面我们看下Python和Java如何实现:
Python实现案例
python
word_pair_rdd = line_rdd.flatMap(lambda line: [
f"{words[i]} {words[i+1]}" for i in range(len(words)-1)
if len(words) > 1
] if (words := line.split(" ")) else [])Java实现案例
Java的实现看起来整个过程就会更清晰很多,代码如下:
java
JavaRDD<String> wordPairRDD= rdd.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String line) throws Exception {
List<String> result = new ArrayList<>();
String[] words = line.split(" ");
for (int i = 0; i < words.length-1; i++) {
result.add(words[i]+" "+words[i+1]);
}
return result.iterator();
}
});得到包含词对元素的 wordPairRDD 之后,我们就可以沿用 Word Count 的后续逻辑,去计算相邻词汇的共现次数。这里留个小作业,请实现完整版的"相邻词汇计数统计"。
filter:过滤 RDD
最后我们来学习一下,与 map 一样常用的算子:filter。
filter,顾名思义,这个算子的作用,是对 RDD 进行过滤。就像是 map 算子依赖其映射函数一样,filter 算子也需要借助一个判定函数 f,才能实现对 RDD 的过滤转换。
所谓判定函数,它指的是类型为(RDD 元素类型) => (Boolean)的函数。可以看到,判定函数 f 的形参类型,必须与 RDD 的元素类型保持一致,而 f 的返回结果,只能是True 或者 False。在任何一个 RDD 之上调用 filter(f),其作用是保留 RDD 中满足 f(也就是 f 返回 True)的数据元素,而过滤掉不满足 f(也就是 f 返回 False)的数据元素。
老规矩,我们还是结合示例来讲解 filter 算子与判定函数 f。
假如我们的数据里有用一些特殊符号,例如"&、|、#"等来标识这个数据是测试数据,我们要过滤掉所有包含特殊符号的内容,具体实现代码如下:
Scala实现案例
Scala
val list: List[String] = List("&", "|", "#")
rdd.filter(word => !word.contains(list(0)) && !word.contains(list(1)) && !word.contains(list(2)))Python实现案例
python
list = ["&", "|", "#"]
rdd.filter(lambda words: not any(word in words for word in list))Java实现案例
java
JavaRDD<String> words = rdd.flatMap(line -> Arrays.stream(line.split(" ")).iterator());
List<String> list = Arrays.asList("&", "|", "#");
JavaRDD<String> filterWord = words.filter(word -> list.stream().noneMatch(word::contains));掌握了 filter 算子的用法之后,就可以定义任意复杂的判定函数 f,然后在 RDD 之上通过调用 filter(f) 去变着花样地做数据过滤,从而满足不同的业务需求。
总结
本文我们重点讲解了同一个 RDD 内部数据转换的 map、mapPartitions、flatMap、filter。这 4 个算子几乎囊括了日常开发中 99% 的数据转换场景,剩下的就需要小伙伴们结合文章的案例,和实际业务需求去多多实践熟悉。