文章导读
在云原生架构逐渐成为主流的今天,越来越多企业开始将 Apache Kafka 与数据湖、Lakehouse 结合,构建实时数据分析能力。然而,Kafka 到 Iceberg 的这条链路却并不轻松:需要依赖 Flink、Spark 等复杂 ETL 工具,开发与运维成本都不低。
有没有更简单的解法?
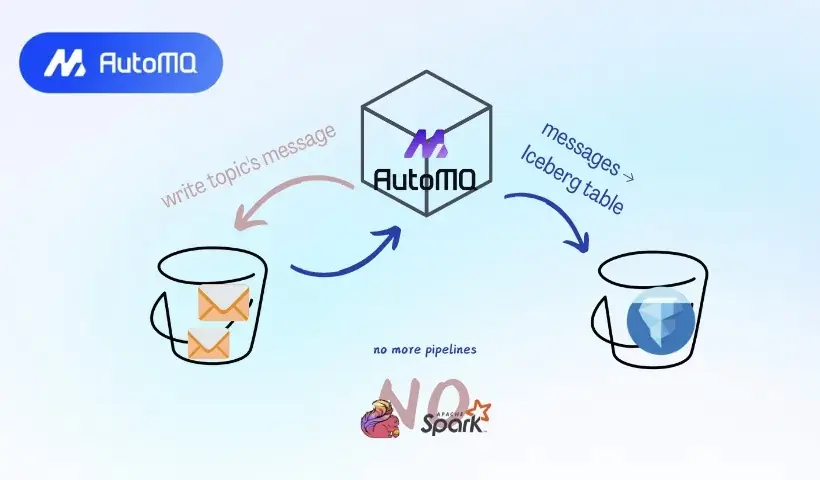
今天这篇来自海外开发者的深度好文,将带你深入了解 AutoMQ 推出的 Table Topic 功能------只需一个配置开关,就能自动将 Kafka Topic 中的数据转换为 Iceberg 表,无需任何额外 ETL 工具。
作为一款专为云而生的 Kafka,AutoMQ 在 GitHub 上已接近 6.8k Star,凭借高度兼容 Kafka 协议和对象存储优先的架构设计,正成为云上 Kafka 替代方案的新选择。
如果你正在关注 Kafka 入湖、Iceberg 实践,这篇文章值得一读。
注意:内容原始内容为英文,如需追求最原汁原味和准确的阅读体验,请直接点击底部 查看原文 阅读原始英文素材。
引言
长期以来,Kafka 一直是分布式消息系统的标准。它被广泛用于服务之间的通信场景,使得某个服务无需直接与数百个其他服务通信。
"我把想说的内容写入一个 Kafka 的 Topic。如果你们想看,就从 Kafka 里消费它们。"
许多公司依赖 Kafka 协议。人们也使用 Kafka 将数据导入分析系统,比如数据仓库、数据湖或 Lakehouse。
假设我们想要通过 Kafka 的 Record 构建一个分析 Dashboard,我们就必须构建一条数据链路,使用 Kafka Connect、Spark 或 Flink 从 Kafka 的 Topic 消费数据,写入文件,并将这些文件推送到数据湖。
我们需要管理整个链路,并确保文件的物理布局是最优的。
除了 Kafka 开始使用 Object Storage 外,还有不少努力致力于简化 Kafka 的 Topic 数据到 Iceberg 表的转换过程。
本文将探讨 Kafka 架构从最初的 Shared Nothing 到 Shared Data 架构的演进。然后,我们将介绍 AutoMQ 推出的开源特性 Table Topic 背后的设计背景与实现原理,它帮助用户无需介入即可管理从 Kafka 到 Iceberg 的全链路。
Kafka 最初的设计
LinkedIn 产生了大量日志数据,既包括用户行为事件(如登录、页面浏览和点击),也包括运维指标(服务调用延迟、错误或者系统资源使用情况)。
这些日志数据最初用于跟踪用户参与度和系统性能,现在也用于提升搜索相关性、推荐系统和广告投放效果等功能。
为满足 LinkedIn 在日志处理方面的需求,Jay Kreps 领导的团队构建了一个叫做 Kafka 的消息系统。这个系统融合了传统日志聚合器与发布/订阅消息系统的优势。它被设计成具有高吞吐和可扩展性。
Kafka 提供了一个类似消息系统的 API,允许应用程序实时消费日志事件。
Kafka 的设计将计算和存储紧密耦合,这在当时是一种常见做法,因为那时的网络速度不像今天这么快。它通过利用操作系统的 Page Cache 和磁盘顺序访问模式实现高吞吐。
现代操作系统通常会使用未占用的内存(RAM)作为 Page Cache。这种缓存会存放频繁访问的磁盘数据,从而减少直接访问磁盘的次数。
因此,系统运行速度更快,降低了磁盘查找延迟带来的影响。
Kafka 的设计让写入(Producer 写数据)和读取(Consumer 读数据)都以顺序方式进行。
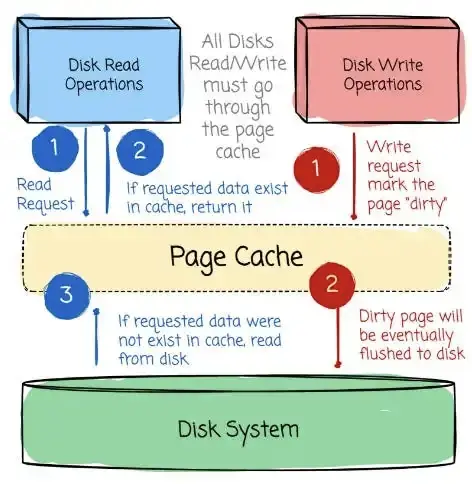
毫无疑问,随机访问比顺序访问在磁盘上慢很多,但如果是顺序访问,有时候磁盘性能甚至可以略微超过内存。
然而,Kafka 的初始设计很快暴露出一些局限。
Uber 的分层存储(Tiered Storage)
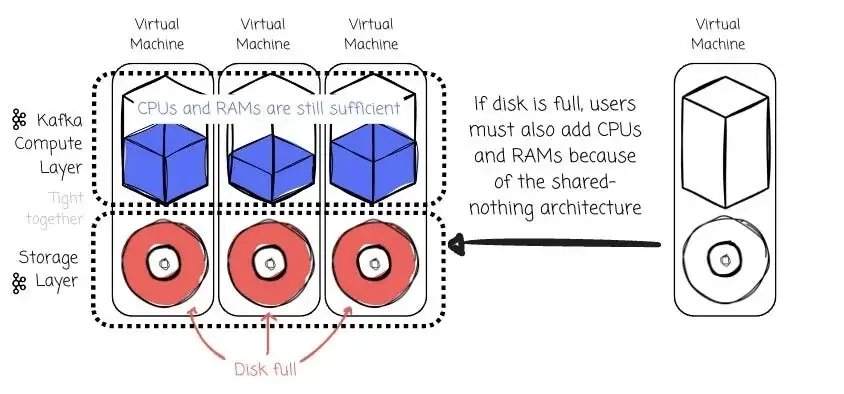
这种紧耦合设计意味着如果要扩展存储,就必须添加更多机器,这会导致资源利用效率低下。
Kafka 的设计也依赖副本机制来保证 Record 的持久性。每个 Partition 有一个 Leader 和若干 Follower(用于存储副本)。所有写入都必须发给该 Partition 的 Leader,而读取可以由 Leader 或 Follower 提供。
当 Leader 接收到 Producer 发来的 Record 后,它会将这些 Record 同步到 Follower。这保证了数据的持久性与可用性。
由于 Kafka 的存储与计算是耦合的,所以每当集群成员发生变更时,数据必须在网络中进行迁移。
当公司在云上运行 Kafka 时,这些问题会进一步放大:
ꔷ 由于计算和存储无法独立扩展,它无法充分利用云上按需计费的优势。
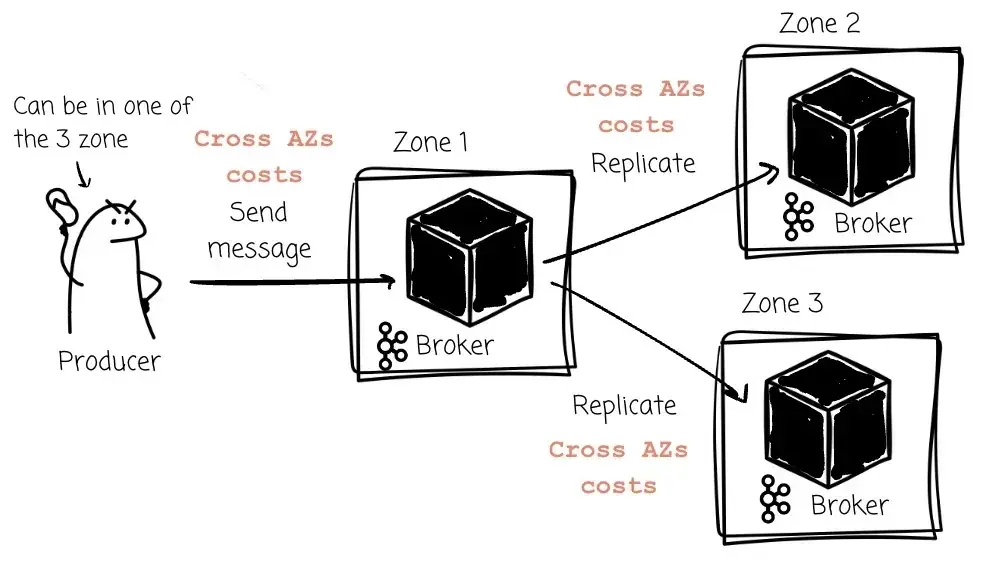
ꔷ 因为消息要跨不同的可用区(AZ)复制,可能会带来很高的跨 AZ 数据传输费用。
为了应对这些限制,Uber 提出了 Kafka 的 Tiered Storage(KIP-405),引入了两级存储体系:
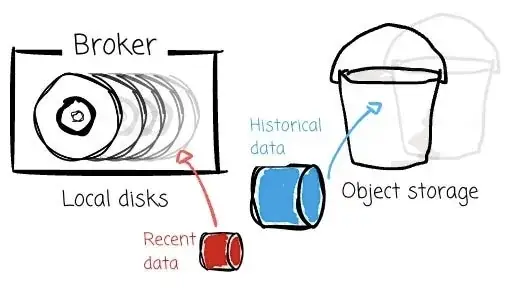
ꔷ 本地存储(Broker 磁盘)保存最近的数据;
ꔷ 远程存储(HDFS/S3/GCS)保存历史数据。
然而,这个问题并没有被完全解决,因为 Broker 依然是有状态的。
共享数据的趋势
2023 年,构建基于 Object Storage 的 Kafka 架构开始兴起。自那时以来,已有至少五家厂商推出了类似的解决方案。2023 年,我们看到了 WarpStream 和 AutoMQ 的发布;2024 年,又有 Confluent Freight Clusters、Bufstream 和 Redpanda Cloud Topics 的加入。
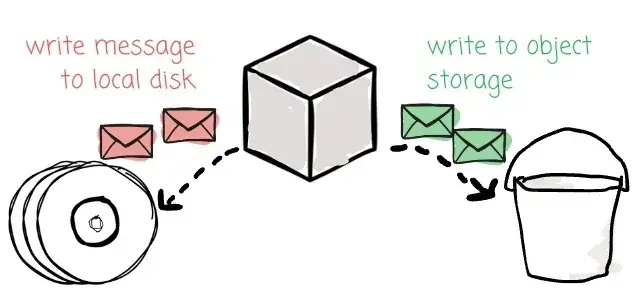
这些新系统承诺作为 Kafka 的替代方案,可以:
ꔷ 成本更低;
ꔷ 更易于维护和运维。
每家厂商都有自己的实现方式。从整体来看,这些系统都尝试兼容 Kafka 协议,并将完整数据存储到 Object Storage 中。Bufstream 和 WarpStream 从头开始重写 Kafka 协议;而 AutoMQ 则选择了一种完全不同的方法------复用 Kafka 协议层代码,以确保 100% 兼容性,同时重构底层存储,使 Broker 能够直接将数据写入 Object Storage,并通过引入 Write-Ahead Log 来避免带来额外延迟。
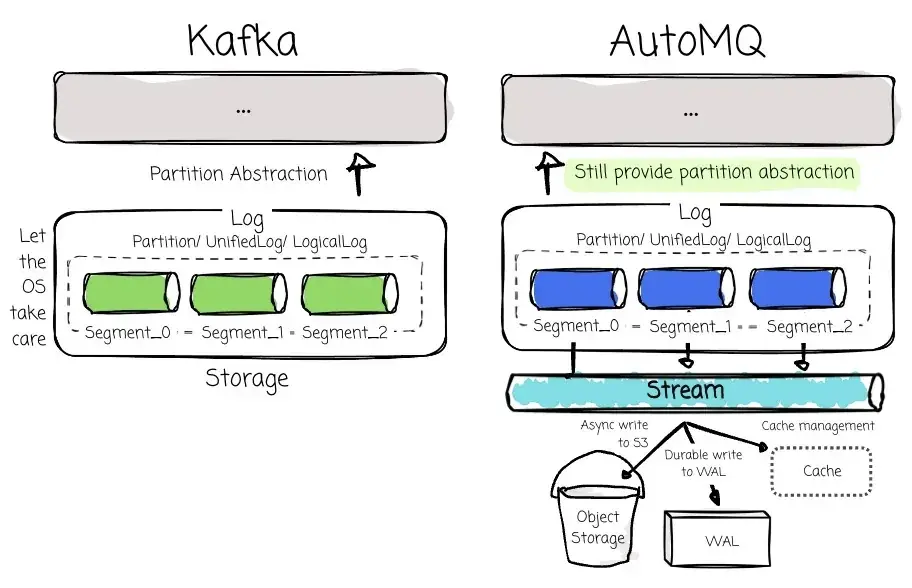
当然,在 Object Storage 上构建兼容 Kafka 的解决方案并非易事。确保 Kafka 协议兼容性本身就是一个挑战,因为它的核心技术设计就是基于本地磁盘:包括将 Record 追加到物理日志中、将 Topic 拆分为多个 Partition、在 Broker 之间进行副本复制、负载均衡、请求 Leader 信息进行写入、以及通过 Segment file 定位 Offset 来服务消费者等等。
因此,迁移至另一种存储介质(例如 Object Storage)并不容易。此外,还要考虑延迟、元数据管理、吞吐能力、缓存管理等多个方面。
如果你感兴趣,我曾写过一篇专门的文章,深入探讨构建像 AutoMQ 或 WarpStream 这类系统可能遇到的所有挑战:Deep dive into the challenges of building Kafka on top of S3。
共享数据
数据是新时代的石油。
每家公司都希望具备捕获、存储、处理和服务数据的能力,以支持关键业务决策。数据工程师需要整合来自多个来源的数据,对其进行存储、转换,并通过统一的数据平台对外提供服务。
过去,在构建分析数据仓库时,数据仓库通常是不二之选。但随着现代表格式的发展,这一格局正在被一种新方案取代------Lakehouse。1
Lakehouse 提出了一个简单的理念:使用一个巨大的存储(Object Storage)来无限存储数据(除了预算限制),你可以任意选择查询引擎进行处理。用户对数据拥有更多的控制权,同时具备更灵活的引擎选择空间。它融合了数据湖和数据仓库的优势。
然而,要将数据仓库的特性(如 ACID 事务语义、时间旅行等)引入数据湖并不容易。这两个系统的抽象方式不同:数据仓库面向的是表,而数据湖管理的则是文件。
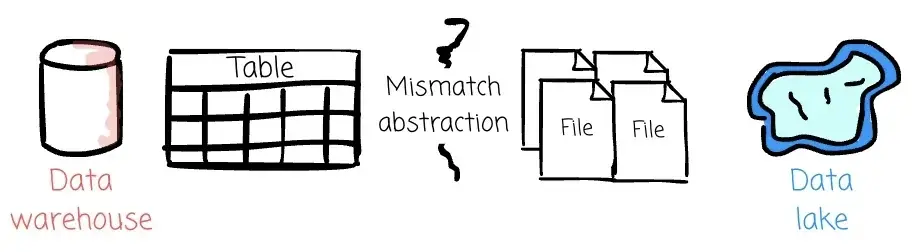
我们需要一个元数据层,把表的抽象带入数据湖。这正是 Delta Lake、Hudi 或 Iceberg 等表格式的价值所在。
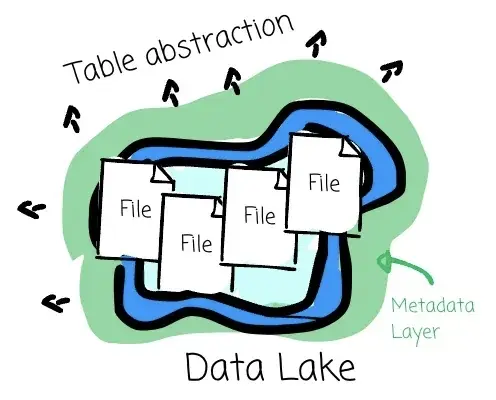
它们提供了 ACID 事务语义,并支持多种数据仓库功能,例如 Schema 演进、数据版本控制、时间旅行,以及针对性能的优化技术。
如果你想进一步了解这些开放表格式的兴起,可阅读这篇文章:2
Iceberg 正受到越来越多的关注,因为它能够良好地与多种系统协同工作。像 Google、Amazon、
Databricks、Snowflake 等厂商都原生支持与 Iceberg 表的交互。3
一家使用 Kafka 的公司,往往也会使用它将数据流式写入分析系统。随着 Lakehouse 模式的兴起,企业对将 Kafka 的 Record 写入 Iceberg 表的需求也在不断增长。
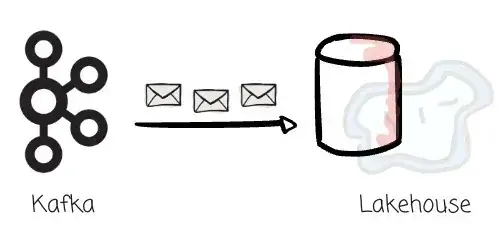
然而,Kafka 到 Iceberg 的数据链路并不简单。用户需要使用 Flink、Spark 或 Kafka Connect 等工具定义处理逻辑,还要运维这些系统,并确保 Iceberg 表的物理布局最优。
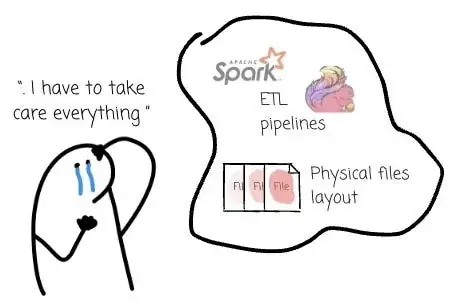
这也是为什么越来越多 Kafka 替代产品开始支持将 Kafka Topic Record 写入 Iceberg 表这一功能。
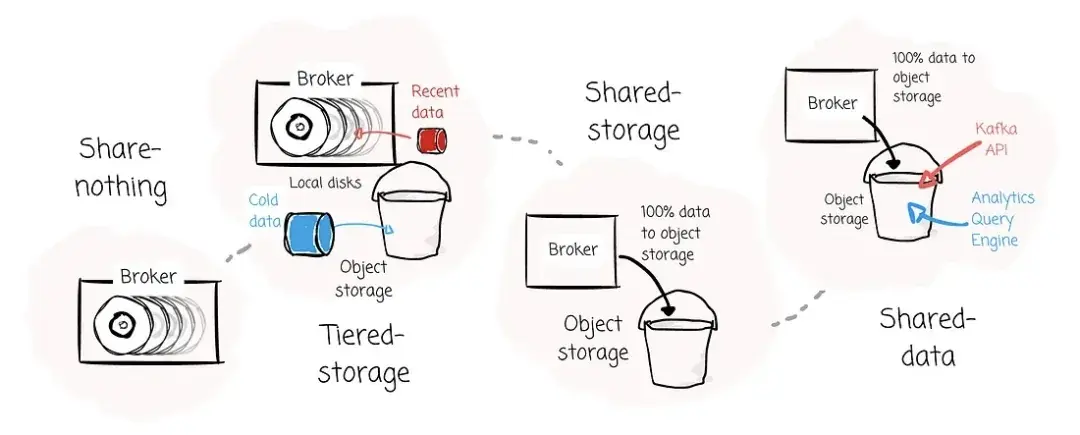
从最初的 Shared Nothing 架构,到 Tiered Storage(broker 仅保存部分数据),再到 Shared Storage(数据 100% offload 到 Object Storage),Kafka 的架构正在不断演进。现在,我们可能正处于下一阶段的开端------Shared Data 架构,数据既通过 Kafka API 提供实时访问,也可以作为 Iceberg 表被分析引擎消费。
鲜为人知的是,AutoMQ 是业内首个公开提出 Shared Data 架构的厂商。
AutoMQ 的 Kafka → Iceberg 路径
当 S3 TABLE 功能首次发布时,AutoMQ 同步推出了 Table Topic 功能,借助 S3 TABLE,可将 Kafka Topics 自动转换为 Iceberg Tables。
这一功能最初仅在企业版中可用。近期,AutoMQ 正式将 Table Topic 功能引入了开源版本(PR-2513)。他们认为,流到表(stream-to-table)能力将是 Kafka 的下一个关键趋势。
动机
AutoMQ 在与客户合作过程中观察到两个核心问题。
首先,企业在使用 Kafka 将数据写入 Lakehouse 时,存在真实的痛点,主要集中在 ETL 流程和数据管理层面。
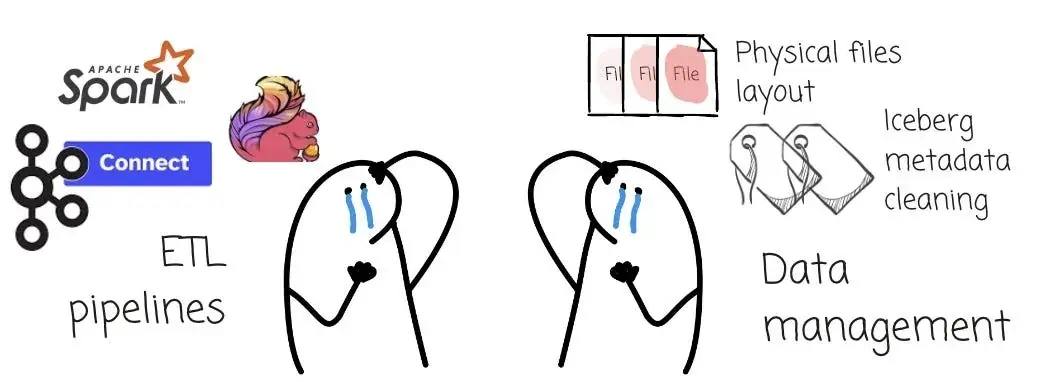
每个 Kafka Topic 都需要一条 ETL 流水线,将数据消费并转换为开放表格式。大量的 Topic 会产生大量 Spark/Flink 作业任务。管理、监控、运维和治理这些作业并不容易。而数据管理也同样棘手:如何处理脏数据或损坏的数据?如何应对 schema 的变更?
除了构建 ETL 所需的资源,每张表还需要独立资源来管理 Object Storage 上的数据:包括清理过期数据/元数据、合并小文件,以及优化读取性能等。
其次,企业内部存在数据共享的需求,需要在 API 与服务之间进行数据的共享与理解。Kafka 在业务数据共享场景中表现良好,微服务之间可以通过 Kafka 协议交换数据。
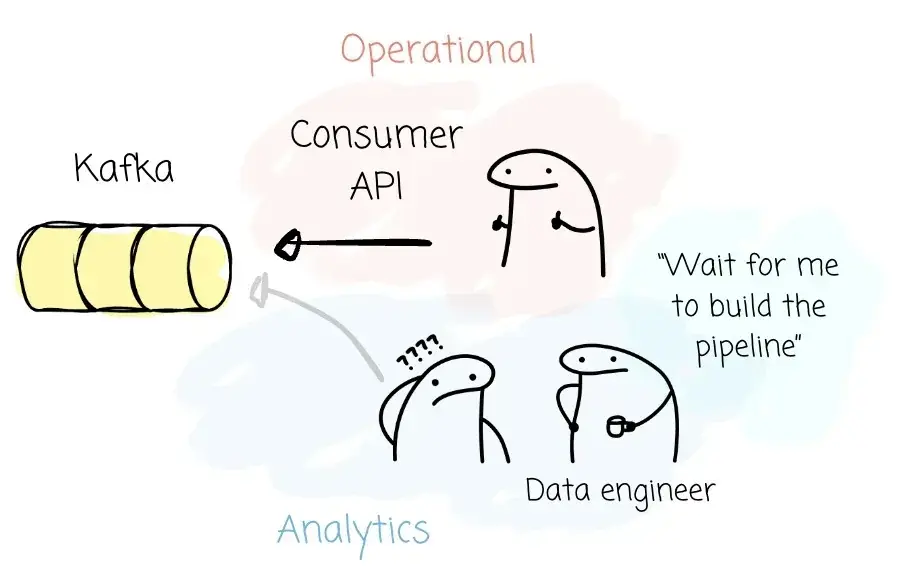
但在分析场景下,这远远不够。Apache Kafka 只是将你的 Record 视为字节数组,并不了解数据的 Schema 与语义。人们需要将 Kafka 中的数据转换成更适合分析的结构化格式,而 Iceberg 就是当前最有力的候选方案之一,因其在生态中的广泛适配。
概述
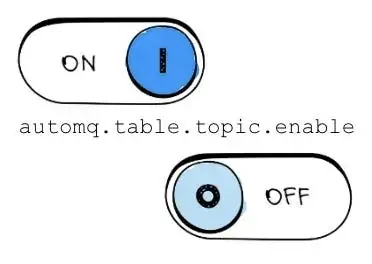
用户只需设置 automq.table.topic.enable 这一配置,即可启用 Kafka-Iceberg 的能力。
启用后,Producer 仍通过 Kafka 协议向 AutoMQ 写入数据。Broker 先将数据写入 Kafka Topic,然后在后台进行批量聚合后转换为 Iceberg 表。从此,查询引擎便可直接消费这张表,满足分析需求。
AutoMQ 会自动处理从 Schema 提取到写入 Iceberg catalog 的整个流程。用户无需再维护复杂的 ETL 作业,只需使用 Kafka API 生产数据,AutoMQ 就能自动将其转换为 Iceberg 表。
目前,AutoMQ 仅在 AWS 上支持 Table Topic,兼容的 Catalog 包括 REST、Glue、Nessie 和 Hive Metastore。未来还计划拓展至更多云平台。
自动管理 Schema
AutoMQ 使用 Kafka 原生的 Schema Registry 作为数据质量的守门机制。当 Producer 发送数据时,系统会检查其是否符合从 Schema Registry 获取的 Schema,如果不符合,则拒绝该条 Record。
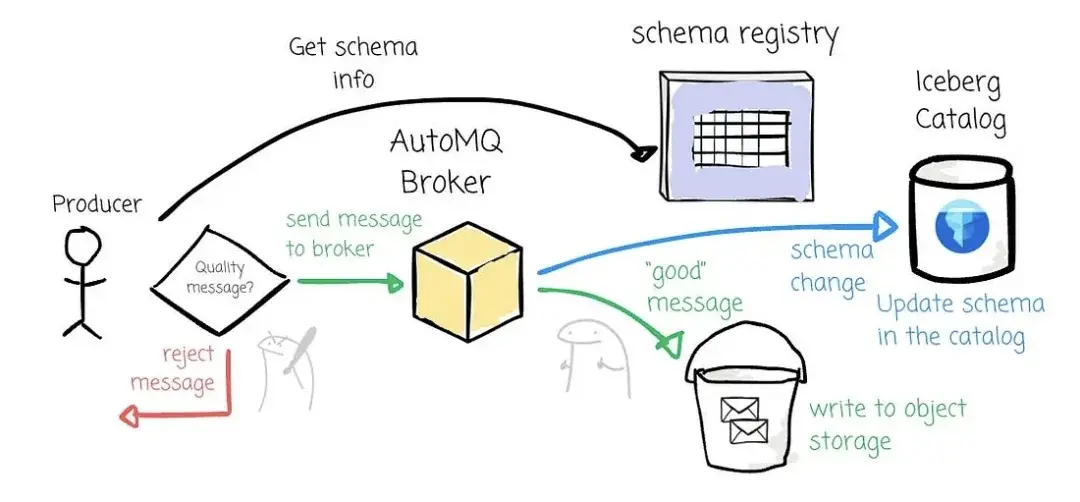
当 Schema 发生变更时,AutoMQ 会从 Kafka Record 中提取 Schema version,并通过 Schema Registry 获取新的 Schema 信息。随后更新 Iceberg 表的 Schema,从而实现数据持续写入不中断。
这得益于 Iceberg 等表格式对 Schema 演进的原生支持,允许在不重写整个数据集或中断下游任务的情况下,完成新增字段、删除字段、修改字段类型等变更。
与在 Flink/Spark 作业中硬编码表结构不同,AutoMQ 通过 Kafka Schema Registry 将原本分散在各处的 Schema 定义集中管理,构建统一的"单一事实源"。这显著减少了元数据维护工作,并确保 Kafka API 的实时访问与底层 Iceberg 表之间 Schema 的一致性。
Iceberg 分区
注意:这里的 Partition 概念描述的是 Iceberg 表中物理数据的组织方式,并非 Kafka 的 Partition。
在 OLAP 系统中,最常见的性能优化方式就是尽可能减少数据扫描量。为此,数据分区是一种广泛推荐的策略。假设一张表包含 6 年的数据,而用户只需查询最近一个月的数据,分区策略能帮助系统仅读取这部分数据,而无需全表扫描。
分区的作用就在于此:你可以配置某个字段(例如 Month 字段)为分区列,系统会将表拆分成多个独立区域并分别存储。这样,查询引擎就可以根据用户的查询条件,仅读取所需的分区数据。
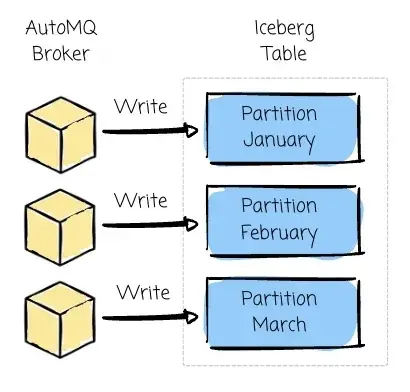
用户可以在 AutoMQ 中定义包含多列的 Iceberg 表分区方案,以便将 Kafka 的主题数据写入 Iceberg 的关联分区中。用户可以使用设置来配置分区策略 automq.table.topic.partition.by,例如 automq.table.topic.partition.by=month(date)。
高效的 Upsert
AutoMQ 还支持 Upsert 操作,用户可以指定 key 字段,Broker 将使用该 Key 进行插入、删除和修改操作。Iceberg 对数据修改的高效支持在这里起到关键作用。
多亏了 Iceberg,这一过程非常高效。数据修改可以通过写入包含变更记录的增量文件(Delta file)来完成,而不需要重写整个表。
无管理开销
为支持 Table Topic 功能,AutoMQ 引入了额外的系统组件:
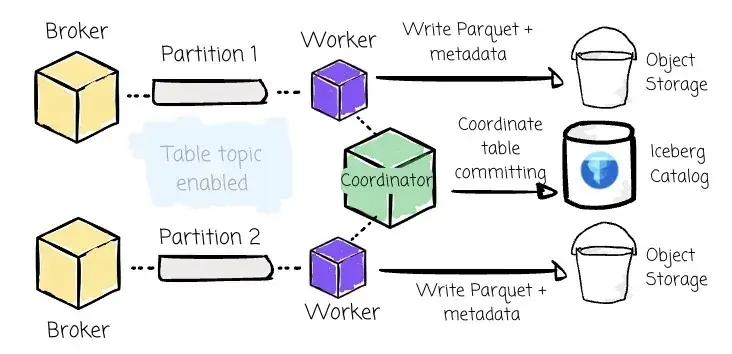
ꔷ Coordinator:负责同步进度与表提交。每个 Table Topic 的 partition 0 上绑定一个专属的 Coordinator,其职责是避免多个 Worker 独立提交带来的冲突和元数据膨胀。
ꔷ Worker:负责实际写入流程,包括将 Kafka record 转换为 Parquet 数据文件、上传至 Object Storage(如 S3)、并将元数据提交到 Iceberg catalog。当启用 Table Topic 功能时,AutoMQ 中每个 Partition 都会在同一进程中拥有一个对应的 Worker。
用户无需部署 Spark、Flink 或 Kafka Connect 作业。
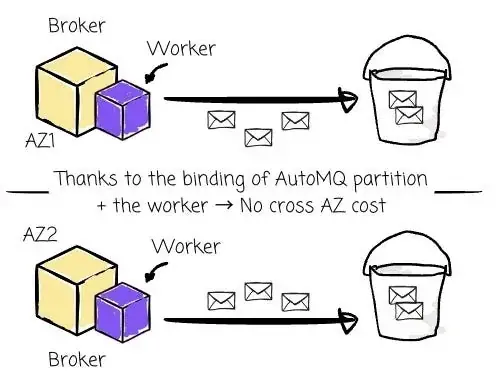
成本效益
通过将 Worker 与特定的 AutoMQ partition 绑定,可确保 Iceberg 表的读写操作发生在同一个可用区(AZ),从而避免跨 AZ 成本。
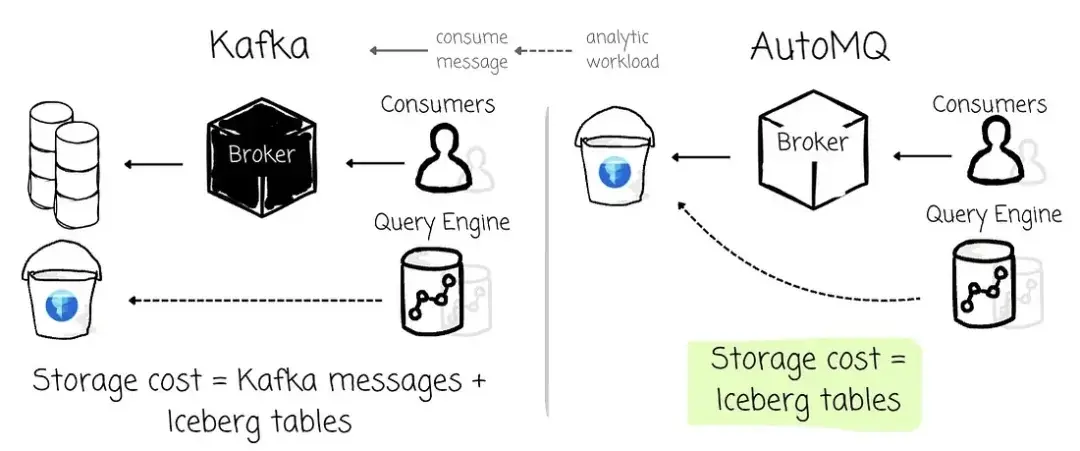
在传统架构下,从 Kafka 消费数据并写入 Iceberg 表时,数据工程师需要同时维护 Kafka Topic 存储与 Lakehouse 数据存储这两层系统。而在 AutoMQ 中,数据转换为 Iceberg 表之后,Broker 即可同时通过 Kafka API 服务 AutoMQ 消费者,也能被分析型引擎直接读取。
结语
本文带你回顾了 Kafka 架构的发展路径:从最初各自为战的 Shared Nothing 架构,到分层存储(Tiered Storage)、共享存储(Shared Storage),再到如今逐步落地的共享数据(Shared Data)模式。
随着数据湖和 Lakehouse 架构的兴起,像 Delta Lake、Apache Hudi,尤其是 Apache Iceberg 这样的开源表格式越来越受到青睐,让原本难以落地的湖仓分析变得可行。
Kafka 在这一过程中扮演了连接数据实时采集与分析的桥梁角色,Kafka → Iceberg 的数据流也因此成为热点话题,许多新一代 Kafka 系统都将其视为核心能力。
我们也进一步介绍了 AutoMQ 是如何提出 Shared Data 架构这一理念,以及它是如何实现将 Kafka 数据自动写入 Iceberg 表的关键技术路径。
希望这篇文章能帮你更好理解 Kafka 与 Iceberg 的融合趋势,我们下篇见!
参考资料
1 thanks to the evolution of modern table formats.
2 Why do we need open table formats like Delta Lake or Iceberg?
3 I spent 7 hours diving deep into Apache Iceberg.
4 AutoMQ | Streaming from Kafka Topic to Iceberg® Table
5 Jack Vanlightly, Tableflow: the stream/table, Kafka/Iceberg duality (2024)