一、下载数据集
CIFAR-10 and CIFAR-100 datasets,选择CIFAR-10 python 版本,163M
二、CIFAR-10 数据集简介
CIFAR-10 数据集由 10 个类的 60000 张 32x32 彩色图像组成,每个类有 6000 张图像。有 50000 张训练图像和 10000 张测试图像。
数据集分为 5 个训练批次和 1 个测试批次,每个批次有 10000 张图像。测试批次包含每个类中随机选择的 1000 张图像。训练批次包含按随机顺序排列的剩余图像,但某些训练批次可能包含来自一个类的图像多于另一个类的图像。在它们之间,训练批次包含来自每个类的 5000 张图像。
以下是数据集中的类,以及每个类的 10 张随机图像:

三、下载代码并储存照片
python
import numpy as np
import pickle
import os
from torchvision import datasets
from imageio import imwrite
# 数据集放置路径
data_save_pth = "./data"
train_pth = os.path.join(data_save_pth, "train")
test_pth = os.path.join(data_save_pth, "test")
# 创建必要的目录
def create_dir(path):
if not os.path.exists(path):
os.makedirs(path)
create_dir(train_pth)
create_dir(test_pth)
# 解压路径
data_dir = os.path.join(data_save_pth, "cifar-10-batches-py")
# 数据集下载
def download_data():
datasets.CIFAR10(root=data_save_pth, train=True, download=True)
# 解压缩数据
def unpickle(file):
with open(file, "rb") as fo:
return pickle.load(fo, encoding="bytes")
# 保存图像
def save_images(data, output_dir, offset):
for i in range(0, 10000):
img = np.reshape(data[b'data'][i], (3, 32, 32)).transpose(1, 2, 0)
label = str(data[b'labels'][i])
label_dir = os.path.join(output_dir, label)
create_dir(label_dir)
img_name = f'{label}_{i + offset}.png'
img_path = os.path.join(label_dir, img_name)
imwrite(img_path, img)
if __name__ == '__main__':
download_data()
for j in range(1, 6):
path = os.path.join(data_dir, f"data_batch_{j}")
data = unpickle(path)
print(f"{path} is loading...")
save_images(data, train_pth, (j - 1) * 10000)
print(f"{path} loaded")
test_data_path = os.path.join(data_dir, "test_batch")
test_data = unpickle(test_data_path)
save_images(test_data, test_pth, 0)
print("test_batch loaded")下载完就是这个目录结构,不过速度有点慢

四、CIFAR-10数据集的分类
python
import torch as t
import torchvision as tv
import torchvision.transforms as transforms
from torchvision.transforms import ToPILImage
import matplotlib.pyplot as plt # 导入 matplotlib 库
import multiprocessing
# 在Windows上需要添加这行来支持多进程
if __name__ == '__main__':
multiprocessing.freeze_support()
show = ToPILImage() # 可以把Tensor转成Image,方便可视化
# 第一次运行程序torchvision会自动下载CIFAR-10数据集,大约100M。
# 如果已经下载有CIFAR-10,可通过root参数指定
# 定义对数据的预处理
transform = transforms.Compose([
transforms.ToTensor(), # 转为Tensor
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), # 归一化
])
# 训练集
trainset = tv.datasets.CIFAR10( # PyTorch提供的CIFAR-10数据集的类,用于加载CIFAR-10数据集。
root='B:/Ama_AI/data/', # 设置数据集存储的根目录。
train=True, # 指定加载的是CIFAR-10的训练集。
# download=True, # 如果数据集尚未下载,设置为True会自动下载CIFAR-10数据集。
transform=transform) # 设置数据集的预处理方式。
# 数据加载器
trainloader = t.utils.data.DataLoader(
trainset, # 指定了要加载的训练集数据,即CIFAR-10数据集。
batch_size=4, # 每个小批量(batch)的大小是4,即每次会加载4张图片进行训练。
shuffle=True, # 在每个epoch训练开始前,会打乱训练集中数据的顺序,以增加训练效果。
num_workers=2) # 使用2个进程来加载数据,以提高数据的加载速度。
# 测试集
testset = tv.datasets.CIFAR10(
'B:/Ama_AI/data/',
train=False,
# download=True,
transform=transform)
testloader = t.utils.data.DataLoader(
testset,
batch_size=4,
shuffle=False,
num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
'''
(data, label) = trainset[100] # 从训练集中获取第100个样本的数据(图像)和标签。
print(classes[label])
# (data + 1) / 2是为了还原被归一化的数据,将之前归一化的数据重新映射到0到1的范围内。
show((data + 1) / 2).resize((200, 200))
'''
dataiter = iter(trainloader)
images, labels = next(dataiter) # 返回4张图片及标签
print(','.join('%11s' % classes[labels[j]] for j in range(4)))
# 使用 matplotlib 显示图像
grid_image = tv.utils.make_grid((images + 1) / 2)
plt.imshow(show(grid_image).resize((400, 100)))
plt.show()

五、定义resnet
python
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)#输入通道数为3,输出通道数为6,卷积核大小为5x5的卷积层
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16*5*5, 120)#输入大小为16x5x5,输出大小为120的全连接层。
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))#先经过第一个卷积层,然后应用ReLU激活函数和2x2的最大池化操作。
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(x.size()[0], -1) # -1表示会自适应的调整剩余的维度
x = F.relu(self.fc1(x))#依次经过两个全连接层,并使用ReLU激活函数进行非线性变换。
x = F.relu(self.fc2(x))
x = self.fc3(x)#最后一层是一个全连接层,输出大小为10,对应CIFAR-10数据集的10个类别。
return x
net = Net()
print(net)
'''结果展示:
Net(
(conv1): Conv2d(3, 6, kernel_size=(5, 5), stride=(1, 1))
(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(fc1): Linear(in_features=400, out_features=120, bias=True)
(fc2): Linear(in_features=120, out_features=84, bias=True)
(fc3): Linear(in_features=84, out_features=10, bias=True)
)
'''六、更新网参&训练阶段的损失值
python
import torch as t
import torchvision as tv
import torchvision.transforms as transforms
from torchvision.transforms import ToPILImage
import matplotlib.pyplot as plt # 导入 matplotlib 库
import multiprocessing
# 定义数据预处理
transform = transforms.Compose([
transforms.ToTensor(), # 转为Tensor
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), # 归一化
])
def main():
show = ToPILImage() # 可以把Tensor转成Image,方便可视化
# 训练集
trainset = tv.datasets.CIFAR10(
root='B:/Ama_AI/data/',
train=True,
transform=transform)
# 数据加载器
trainloader = t.utils.data.DataLoader(
trainset,
batch_size=4,
shuffle=True,
num_workers=2)
# 测试集
testset = tv.datasets.CIFAR10(
'B:/Ama_AI/data/',
train=False,
transform=transform)
testloader = t.utils.data.DataLoader(
testset,
batch_size=4,
shuffle=False,
num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
dataiter = iter(trainloader)
images, labels = next(dataiter) # 返回4张图片及标签
print(','.join('%11s' % classes[labels[j]] for j in range(4)))
# 使用 matplotlib 显示图像
grid_image = tv.utils.make_grid((images + 1) / 2)
plt.imshow(show(grid_image).resize((400, 100)))
plt.show()
#定义网络resnet
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(x.size()[0], -1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
#定义损失函数和优化器(loss和optimizer)
from torch import optim
criterion = nn.CrossEntropyLoss()# 创建了一个交叉熵损失函数的实例,用于计算分类任务中的损失。它将模型的输出与真实标签进行比较,并计算出一个数值作为损失值,用来衡量模型预测与真实标签之间的差异。
net = Net()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)#创建了一个随机梯度下降(SGD)优化器的实例。lr=0.001是学习率(learning rate),控制每次参数更新的步长大小。momentum=0.9表示动量(momentum)参数,用于加速优化过程并避免陷入局部最优解。
t.set_num_threads(8)# 设置线程数为 8,以加速训练过程。
# 训练网络并更新网络参数
for epoch in range(2):# 指定训练的轮数为 2 轮(epoch),即遍历整个数据集两次。
running_loss = 0.0# 记录当前训练阶段的损失值
for i, data in enumerate(trainloader, 0):
inputs, labels = data # 输入数据
optimizer.zero_grad()# 梯度清零#:每个 batch 开始时,将优化器的梯度缓存清零,以避免梯度累积
outputs = net(inputs)
loss = criterion(outputs, labels)# 进行前向传播,然后计算损失函数 loss
loss.backward()# 自动计算损失函数相对于模型参数的梯度
optimizer.step()# 更新参数
running_loss += loss.item()# loss 是一个scalar,需要使用loss.item()来获取数值,不能使用loss[0]
if i % 2000 == 1999:# 每2000个batch打印一下训练状态
print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
if __name__ == '__main__':
multiprocessing.freeze_support()
main()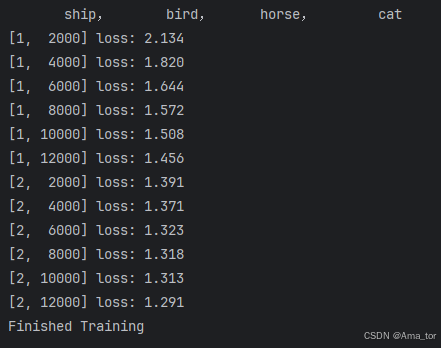
七、训练准确值VS随机
python
correct = 0 # 预测正确的图片数
total = 0 # 总共的图片数
# 使用 torch.no_grad() 上下文管理器,表示在测试过程中不需要计算梯度,以提高速度和节约内存
with t.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = t.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum()
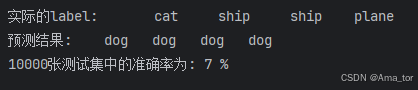
print('10000张测试集中的准确率为: %d %%' % (100 * correct / total))
dataiter = iter(testloader)
images, labels = next(dataiter) # 一个batch返回4张图片
print('实际的label: ', ' '.join( \
'%08s' % classes[labels[j]] for j in range(4)))
show(tv.utils.make_grid(images + 1) / 2).resize((400, 100))
# 计算图片在每个类别上的分数
outputs = net(images)
# 得分最高的那个类
_, predicted = t.max(outputs.data, 1)
print('预测结果: ', ' '.join('%5s' \
% classes[predicted[j]] for j in range(4)))训练后准确率52%

随机准确率仅7%
八、 拓展_enumerate函数
在机器学习或深度学习中,enumerate函数常常与循环结合使用,用于遍历数据集或批次数据,并同时获取数据的索引值。这在模型训练过程中很有用,可以方便地记录当前处理的数据的位置信息。
python
fruits = ['A', 'B', 'C']
for index, fruit in enumerate(fruits):
print(index, fruit)
GRAMMER:
enumerate(iterable, start=0)
文章参考链接: