在我们做算法题的时候,会碰到这样的一个问题:有两个字符串txt、tar,问字符串tar是否在字符串
txt中出现过,如果出现了的话,则返回成功匹配时的下标,若没有则返回-1。这就是经典的字符串
匹配问题。而如果深入了解过字符串匹配问题的话,那就一定听说过KMP算法,那么这篇文章就是
介绍了我对于KMP算法的理解,希望可以对想要了解KMP算法的读者提供一点帮助。前言中的题目是leetcode中的一道题目:28.找出字符串中第一个匹配项的下标
KMP介绍
KMP(Knuth-Morris-Pratt)算法是一种用于字符串匹配的高效算法,由 Donald Knuth、Vaughan Pratt 和 James H. Morris 在 1977 年共同开发。该算法主要用于在一个主字符串(文本串)中查找一个模式字符串的出现位置,相较于传统的暴力匹配算法,它在时间复杂度上有显著的优化。
传统的暴力算法无非就是遍历txt字符串,当遍历到某一个位置时,我们就从当前位置开始跟tar字符串匹配,如果匹配成功则返回,不成功,则继续向后遍历直到末尾,时间复杂度O(M * N)M为字符串txt的长度,N为字符串tar的长度。
而KMP算法通过记录一些信息从而让字符串匹配过程中的效率大大增加,时间复杂度可以做到O(M + N)。
KMP算法的使用
上面介绍说,KMP算法通过记录一些信息,可以使得匹配过程中效率大大增加,而这个信息就是字符串tar中每个位置之前的子串中的最大相等前后缀长度,这句话对于初次遇到的人来说可能有点拗口。不要着急,我们慢慢来理解上面的含义。
前后缀
上面那句话中我们提到了前缀和后缀,我们先要清楚的认识前缀和后缀是什么:
前缀:包含首字符并且不包含尾字符的子串
后缀:包含尾字符并且不包含首字符的子串下面让我来举一个例子,比如tar = "abcabdabc";
那么tar的前缀就有:
a
ab
abc
abca
abcab
abcabd
abcabda
abcabdab后缀则是:
c
bc
abc
dabc
bdabc
abdabc
cabdabc
bcabdabc很多人在学习KMP算法的时候误把找后缀的顺序认定为从结尾开始向左的方向进行,这与与后缀的方向正好相反,要能够注意到这一点细节。
而我们也不难发现上述字符串tar的最大相等前后缀的长度就是3(前缀中的abc与后缀中的abc相等)。这就是前后缀与最大相等前后缀的长度。
字符串tar中每个位置之前的子串中的最大相等前后缀长度
现在让我们来理解这句话,这里我依然举一个例子,比如字符串tar = "issip";
它的每个位置的子串意思就是包含首字符与当前位置字符的子串,那么tar的子串有:
i
is
iss
issi
issip
而每个字串的最大相等前后缀我们也可以得到:
i : 0(单个字符既没有前缀也没有后缀,所以是0)
is: 0
iss: 0
issi: 1
issip 0这样的话我们就得到了tar中每个位置之前的子串中的最大相等前后缀长度了,在编程语言中我们可以用数组把他们存起来,得到一张表,这张表就叫做部分匹配表。
那么tar的部分匹配表就是:{0, 0, 0, 1, 0}。下面我们就来使用这一张表来模拟KMP算法的过程,在这里我们假设字符串txt = "mississippi"。
模拟KMP算法
上述过程中我们明确了txt = "mississippi",tar = "issip"。并且获得了tar的部分匹配表{0, 0, 0, 1, 0},接下来我们就来模拟KMP算法。
总体的流程我们依然是遍历txt与tar两个字符串,只是在字符匹配的过程中有了差异。
接下来我们有一个下标指向txt的某一个字符,j指向tar的某一个字符,两者初始值都为0,然后向后遍历比较:
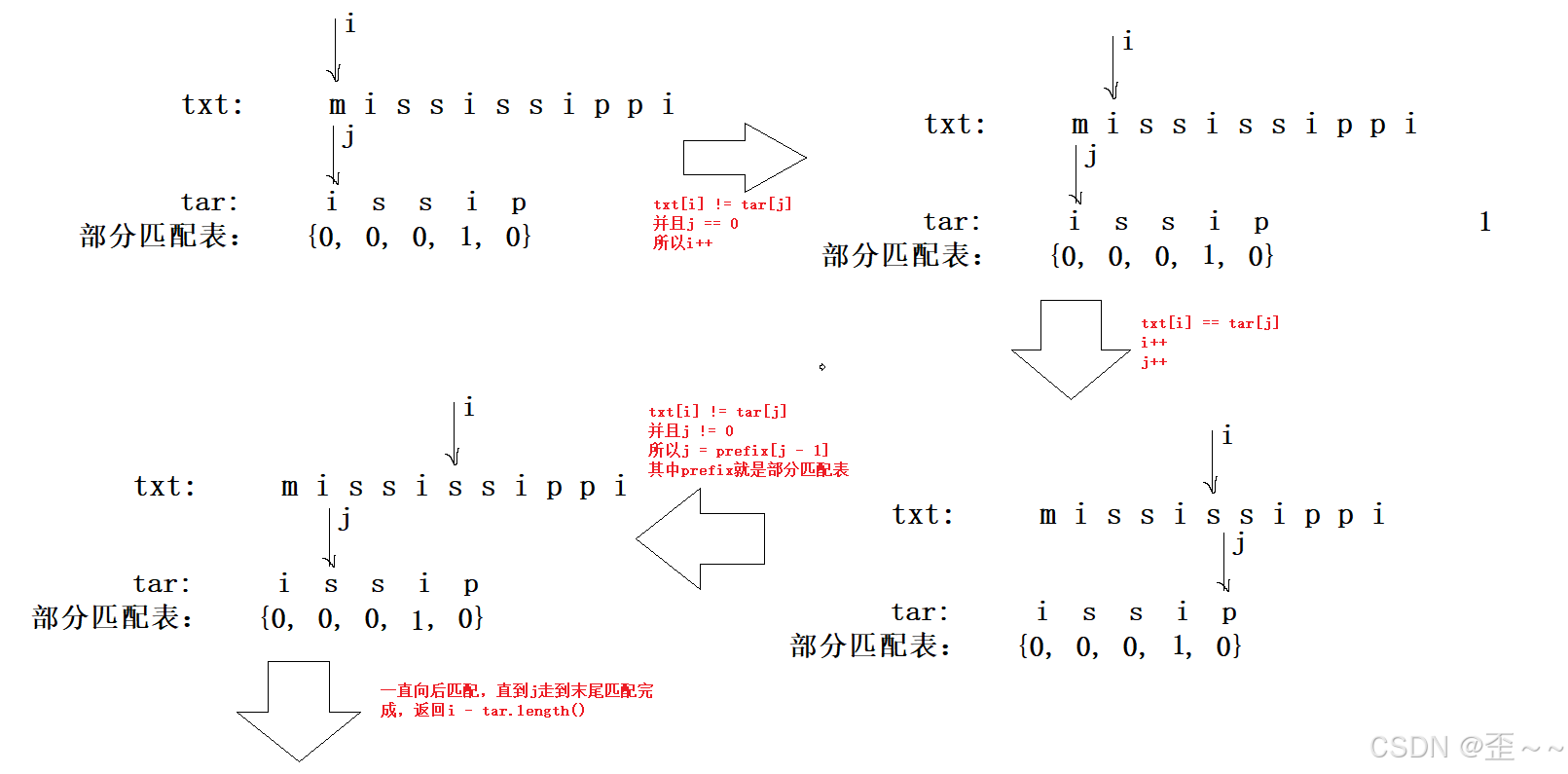
j = prefixj - 1的原因
这张图里我们其中一个过程用到了部分匹配表,让我来解释一下为什么当在匹配过程中txti != tarj && j > 0时,就可以让j = prefixj - 1呢?
我们来再次分析一下部分匹配表中的含义,部分匹配表中存储的当前下标的最大相等前后缀长度,那这就意味着,在某一个下标i构成的子串处,k = prefixi,那么一定有该子串的前k个子字符串和后k个子字符串是相等的,那么当我们在匹配过程中出现了字符不相等的情况,在暴力匹配中,我们应该另j = 0,i等于开始当前开始匹配时的下一个字符。
而在上述KMP匹配过程中我们碰到了字符's' 和字符 'p'不匹配的情况,这个时候我们要知道下标j之前的字符我们是匹配成功的,也就是tar字符串从下标0到j - 1我们都是匹配成功的,而我们又知道下标j - 1的最大相等前后缀长度,这就意味着其实我们不需要让j再回到起始位置。
因为字符串tar从下标0到下标prefixj - 1 - 1构成的子串 "i" 和从下标j - prefixj - 1到下标j - 1构成的子串是相等的
并且我们也知道字符串txt从下标i - prefixj - 1到下标i - 1构成的子串 "i" 与tar从下标j - prefixj - 1到下标j - 1构成的子串 "i" 也一定是相等的。
所以对于tar前prefixj - 1个字符我们就不需要重复匹配了,而是直接从tar的下标prefixj - 1继续向后匹配就可以了。
至此tar不需要回退的原因我们已经找到了那就是由于部分匹配表的存在
i不需要回退的原因
但是或许有人就有疑问了,那为什么txt的下标不需要回退呢?在暴力匹配过程中,假如我们选定一个下标start开始匹配,当字符串出现不匹配的情况时,我们需要从start + 1开始继续匹配,但是在KMP算法中,似乎没有这一步,它为什么能够排除这种情况呢:假如我们依旧开始从start开始匹配,匹配到i(i > start)位置时出现不匹配的情况,他凭什么不把start回退到start + 1(又或者是start + x(start + x < i))开始匹配,而是可以直接从i开始继续匹配呢。
其实这一件事情部分匹配表也帮我们做了,当我们按照上述过程到了i位置出现不匹配,假定此时tar下标为j,那就意味着txt下标从start开始到i - 1构成的子字符串与tar从下标0开始到j - 1构成的子字符串是相等的,tar从下标0开始到j - 1构成的子字符串的最大相等前后缀长度与txt下标从start开始到i - 1构成的子字符串是一致的。
现在我们按照上面的设想继续从start + 1开始匹配,我们发现这其实就是tar从下标0开始到j - 2构成的子字符串与tar从下标1开始到下标j - 1判定是否相等吗,换句话说这不就是判定tar从下标0开始到j - 1构成的子字符串的最长的前缀和后缀是否相等吗?到了这里我想一切都豁然开朗了,这两个子串相不相等部分匹配表不就已经记录了啊,如果相等的话部分匹配表prefixj - 1会记录该最大相等前后缀的长度(也就是上述最长前缀的长度),那我们本来就不用回退让start为start + 1,因为部分匹配表告诉我们这两个不相等我们直接让txt的下标i和tar的下标prefixj - 1继续向后匹配就可以了,如果不相等的话那就意味着部分匹配表prefixj - 1的值小于上述最长前缀(或后缀)的长度,那我们更不用匹配了,因为我们已经知道他俩不相等了。那么以此类推为什么不把start回退到start + x(start + x < i)开始匹配,而是可以直接从i开始继续匹配的子问题我们也都是类似的解决方案,一切都在部分匹配表中。
KMP算法
接下来我附上KMP算法的C++代码:
cpp
int strStr(vector<int>& prefix, string& txt, string &tar)
{
int l = 0, r = 0;
while(l < txt.size())
{
if(r == tar.size())
break;
else if(txt[l] == tar[r])
{
l++;
r++;
}
else
{
if(r == 0)
l++;
else r = prefix[r - 1];
}
}
return r == tar.size() ? l - tar.size() : -1;
}到这里就完了吗?如果你去认真了解过KMP算法的话,就会知道学会KMP算法本身其实是不难理解的,在上面的讲述过程中,我们一直都在说KMP算法本身,但是一直没有详细说部分匹配表,但是部分匹配表出问题的人又不会给你,需要我们自己解决,而KMP算法中,求得部分匹配表才是比较难理解的部分。
部分匹配表的获取
如果我们使用最简单无脑的方式,那就是依旧是遍历tar字符串,当遍历到某一个下标时,找出它所有的前后缀,然后对应长度前后缀逐一比对找到当前下标的最大相等前后缀,这一套操作下来,时间复杂度直接打到O(N ^ 3)。这样一来不就本末倒置了,整体时间复杂度大致还不如暴力匹配呢。
所以我们一定有着更有的解法,那就是使用动态规划,但是这其中不仅仅是简单的动态规划,他还融入了KMP算法,这正是部分匹配表难理解的原因。
至于为什么能够想到使用动态规划,其实我也不知道(我也是个小菜鸟),但是我能够知道它为什么可以使用动态规划。
为什么可以使用动态规划
现在我们依旧是在遍历tar字符串,然后寻找每个下标构成的子串的最大相等前后缀长度。既然是这样的方式,那也就意味着,我们在寻找下标为i构成的子串的最大相等前后缀长度时,我们就已经获取了下标0到i - 1的构成的子串的最大相等前后缀长度。
根据上面的认识,当我们遍历到下标i的时候,我们可以发现这一点:那就是当前下标的最大相等前后缀的长度绝对不会大于下标i - 1的最大相等前后缀的长度加一。
这一点我们是可以证明的(上面提到的下标i是大于0的,因为如果下标等于0的话,长度为一的子串的最大相等前后缀永远是0)。
假设我们当前遍历到下标i,并且下标i - 1的最大相等前后缀长度是k,那就意味着下标从0开始到i - 1构成的子串中,前k个字符构成的子串和后k个字符构成的子串是相等的:
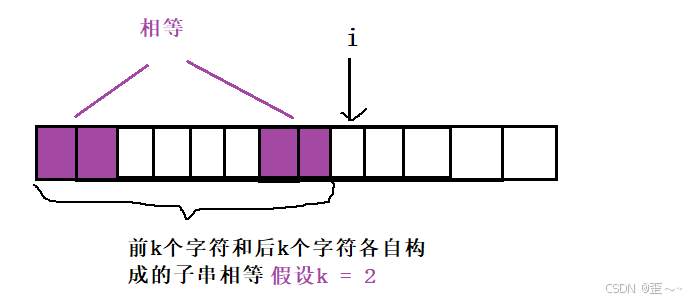
这里的k其实就是prefixi - 1。
既然上上图中k给定数值2,那我们就可以断定当前下标i的最大相等前后缀长度不会超过3。
我们可以想一下,假如当前下标的最大相等前后缀长度大于3,假如是4,那就对应下图中的情况:

如果是这样的情况,那么prefixi - 1一定是3:
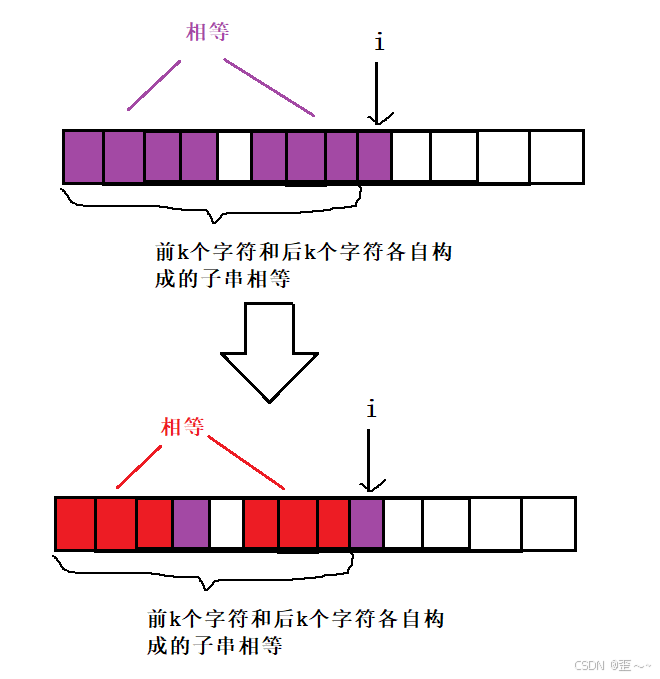
显然这是不可能的,所以我上述的结论是正确的。
而有了这一点,那当我们在判断当前下标i的最大相等前后缀长度时,只需要从长度prefixi - 1 + 1的前后缀开始判断就可以了,所以我们使用动态规划,可以进行简单的优化。
但是这样的优化够吗?我们发现,就算我们能排除一部分遍历的情况,但是当面对prefixi - 1很大的情况下,在我们寻找当前最大相等前后缀长度时,最坏的情况可以遍历prefixi - 1 + 1次,我们仍然可以进行优化,那就是使用KMP算法。
在寻找当前最大相等前后缀长度时应用KMP算法
刚刚提到,当面对prefixi - 1很大的情况下,在我们寻找当前最大相等前后缀长度时,最坏的情况可以遍历prefixi - 1 + 1次,那就是当前遍历到的下标字符,不存在于由下标0到下标prefixi - 1 + 1构成的子串中:

这才会遍历那么多次。但是我们实际上不需要遍历那么多次,在最开始介绍获取部分匹配表的时候,我就说过,当我们遍历到i时,0到i - 1的部分匹配表就已经获取好了,我们现在再来从一开始的匹配来看上面这张图:
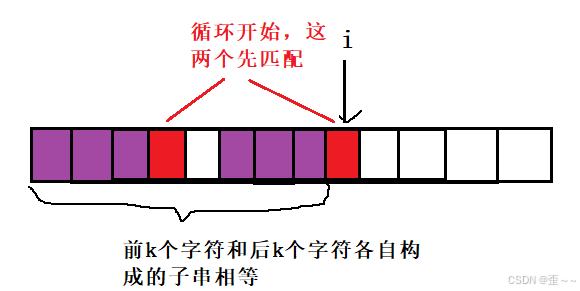
按照我们以前的思路,如果我们匹配成功,那不用继续往下找了,这就是最大的,是4,但是如果不匹配我们需要继续缩短前后缀,直到前后缀的末尾字符匹配成功。
但是其实失败之后我们是不需要一个一个进行遍历的。我们其实可以将这一个过程想象成KMP算法的过程,即下标从0开始到下标prefixi - 1构成的子串在tar字符串中找第二个匹配的过程,而我们刚好在匹配过程中碰到了下标i与即下标从0开始到下标prefixi - 1构成的子串的下标j不匹配,那此时我们在KMP算法中该如何进行呢?不就是查部分前缀表prefixj - 1吗?
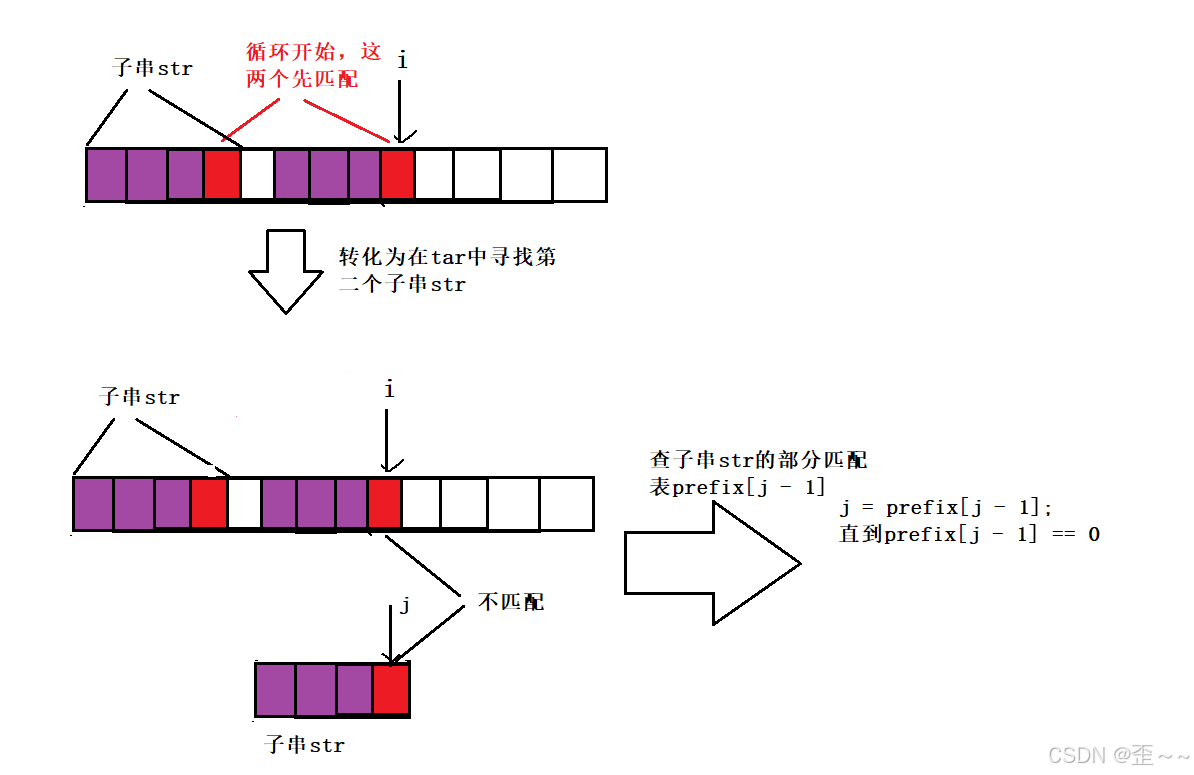
在让j = prefixj - 1的过程中,一旦出现strj == tari,那就说明我们找到最大相等前后缀长度了,那就是j + 1。而这个部分匹配表我们刚好有,所以这个算法是成立的。现在我们的获取tar字符串的部分匹配表的算法就完成了,附上代码:
需要注意: 这里的函数中的prefix的长度已经是预先初始化为跟字符串s同等大小了
cpp
void getPrefix(vector<int> & prefix, string &s)
{
if(prefix.size() == 0)
return;
// 长度为1的字符串最大相等前后缀长度始终为0
prefix[0] = 0;
// 记录上一个位置的最大相等前后缀长度
int j = 0;
for(int i = 1; i < s.size(); i++)
{
while(j > 0 && s[i] != s[j])
{
j = prefix[j - 1];
}
if(s[i] == s[j]) ++j;
prefix[i] = j;
}
}KMP算法完全版
其实KMP算法的使用过程也可以跟上面获取部分匹配表的代码相同,这是最开始的我的代码:
cpp
int strStr(vector<int>& prefix, string& txt, string &tar)
{
int l = 0, r = 0;
while(l < txt.size())
{
if(r == tar.size())
break;
else if(txt[l] == tar[r])
{
l++;
r++;
}
else
{
if(r == 0)
l++;
else r = prefix[r - 1];
}
}
return r == tar.size() ? l - tar.size() : -1;
}最终的KMP算法代码:
cpp
void getPrefix(vector<int> & prefix, string &s)
{
if(prefix.size() == 0)
return;
// 长度为1的字符串最大相等前后缀长度始终为0
prefix[0] = 0;
// 记录上一个位置的最大相等前后缀长度
int j = 0;
for(int i = 1; i < s.size(); i++)
{
while(j > 0 && s[i] != s[j])
{
j = prefix[j - 1];
}
if(s[i] == s[j]) ++j;
prefix[i] = j;
}
}
int strStr(string& txt, string &tar)
{
if(tar.size() > txt.size())
return -1;
vector<int> prefix(tar.size());
getPrefix(prefix, tar);
for(int i = 0, j = 0; i < txt.size(); i++)
{
while (j > 0 && txt[i] != tar[j])
{
j = pi[j - 1];
}
if (txt[i] == tar[j])
{
j++;
}
if (j == tar.size())
{
return i - tar.size() + 1;
}
}
return -1;
}这就是我对KMP算法的全部理解,如果有不对的地方,请指正。