一般情况下,爬虫会使用云服务器来运行,这样可以保证爬虫24h不间断运行。但是如何把爬虫放到云服务器上面去呢?有人说用FTP,有人说用Git,有人说用Docker。但是它们都有很多问题。
FTP:使用FTP来上传代码,不仅非常不方便,而且经常出现把方向搞反,导致本地最新的代码被服务器代码覆盖的问题。
Git:好处是可以进行版本管理,不会出现代码丢失的问题。但操作步骤多,需要先在本地提交,然后登录服务器,再从服务器上面把代码下载下来。如果有很多服务器的话,每个服务器都登录并下载一遍代码是非常浪费时间的事情。
Docker:好处是可以做到所有服务器都有相同的环境,部署非常方便。但需要对Linux有比较深入的了解,对新人不友好,上手难度比较大。
为了简化新人的上手难度,本次将会使用Scrapy官方开发的爬虫部署、运行、管理工具:Scrapyd。
一、Scrapyd介绍与使用
1. Scrapyd的介绍
Scrapyd是Scrapy官方开发的,用来部署、运行和管理Scrapy爬虫的工具。使用Scrapyd,可以实现一键部署Scrapy爬虫,访问一个网址就启动/停止爬虫。Scrapyd自带一个简陋网页,可以通过浏览器看到爬虫当前运行状态或者查阅爬虫Log。Scrapyd提供了官方API,从而可以通过二次开发实现更多更加复杂的功能。
Scrapyd可以同时管理多个Scrapy工程里面的多个爬虫的多个版本。如果在多个云服务器上安装Scrapyd,可以通过Python写一个小程序,来实现批量部署爬虫、批量启动爬虫和批量停止爬虫。
2. 安装Scrapyd
安装Scrapyd就像安装普通的Python第三方库一样容易,直接使用pip安装即可:
pip install scrapyd
由于Scrapyd所依赖的其他第三方库在安装Scrapy的时候都已经安装过了,所以安装Scrapyd会非常快。
Scrapyd需要安装到云服务器上,如果读者没有云服务器,或者想在本地测试,那么可以在本地也安装一个。
接下来需要安装scrapyd-client,这是用来上传Scrapy爬虫的工具,也是Python的一个第三方库,使用pip安装即可:
pip install scrapyd-client这个工具只需要安装到本地计算机上,不需要安装到云服务器上。
3. 启动Scrapyd
接下来需要在云服务器上启动Scrapyd。在默认情况下,Scrapyd不能从外网访问,为了让它能够被外网访问,需要创建一个配置文件。
对于Mac OS和Linux系统,在/etc下创建文件夹scrapyd,进入scrapyd,创建scrapyd.conf文件。对于Windows系统,在C盘创建scrapyd文件夹,在文件夹中创建scrapyd.conf文件,文件内容如下:

除了bind_address这一项外,其他都可以保持默认。bind_address这一项的值设定为当前这台云服务器的外网IP地址。
配置文件放好以后,在终端或者CMD中输入scrapyd并按Enter键,这样Scrapyd就启动了。此时打开浏览器,输入"http://云服务器IP地址:6800"格式的地址就可以打开Scrapyd自带的简陋网页。
4. 部署爬虫
Scrapyd启动以后,就可以开始部署爬虫了。打开任意一个Scrapy的工程文件,可以看到在工程的根目录中,Scrapy已经自动创建了一个scrapy.cfg文件,打开这个文件,其内容如图所示。
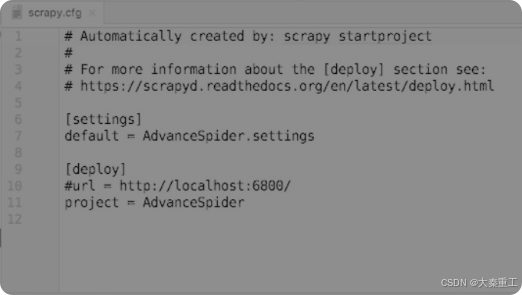
现在需要把第10行的注释符号去掉,并将IP地址改为Scrapyd所在云服务器的IP地址。
最后,使用终端或者CMD进入这个Scrapy工程的根目录,执行下面这一行命令部署爬虫:
scrapyd-deploy命令执行完成后,爬虫代码就已经在服务器上面了;如果服务器上面的Python版本和本地开发环境的Python版本不一致,那么部署的时候需要注意代码是否使用了服务器的Python不支持的语法;最好的办法是使用本地和服务器一样的版本开发环境(推荐使用 Conda)。需要记住,Scrapyd只是一个管理Scrapy爬虫的工具而已,只有能够正常运行的爬虫放到Scrapyd上面,才能够正常工作。
5.启动/停止爬虫
在上传了爬虫以后,就可以启动爬虫了。对于Mac OS和Linux系统,启动和停止爬虫非常简单。要启动爬虫,需要在终端输入下面这一行格式的代码:
curl http://云服务器IP地址:6800/schedule.json-d project=爬虫工程名-d spider=爬虫名执行完成命令以后,打开Scrapyd的网页,进入Jobs页面,可以看到爬虫正在运行。单击右侧的Log链接,可以看到当前爬虫的Log。需要注意的是,这里显示的Log只能是在爬虫里面使用logging模块输出的内容,而不会显示print函数打印出来的内容。
如果爬虫的运行时间太长,希望提前结束爬虫,那么可以使用下面格式的命令来实现:
x
curl http://云服务器IP地址:6800/schedule.json-d project=爬虫工程名-d spider=爬虫名运行以后,相当于对爬虫按下了Ctrl+C组合键的效果。如果爬虫本身已经运行结束了,那么执行命令以后的返回内容中,"prevstate"这一项的值就为null,如果运行命令的时候爬虫还在运行,那么这一项的值就为"running"。对于Windows系统,启动和停止爬虫稍微麻烦一点,这是由于Windows的CMD功能较弱,没有像Mac OS和Linux的终端一样拥有curl这个发起网络请求的自带工具。但既然是发起网络请求,那么只需要借助Python和requests就可以完成。先来看看启动爬虫的命令:
curl http://192.168.31.210:6800/schedule.json -d project=DeploySpider -d spider=Example显而易见,其中的"http://192.168.31.210:6800/schedule.json"是一个网址,后面的-d中的d对应的是英文data数据的首字母,project=DeploySpider和spider=Example又刚好是Key、Value的形式,这和Python的字典有点像。而requests的POST方法刚好有一个参数也是data,它的值正好也是一个字典,所以使用requests的POST方法就可以实现启动爬虫。由于部署爬虫的时候直接执行scrapyd-deploy命令,所以如何使用Python来自动化部署爬虫呢?其实也非常容易。在Python里面使用os这个自带模块就可以执行系统命令,如图:
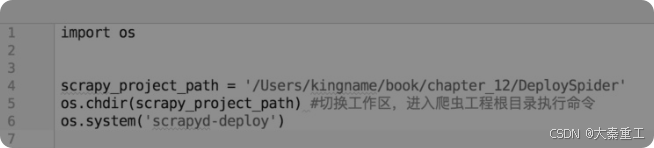
使用Python与requests的好处不仅在于可以帮助Windows实现控制爬虫,还可以用来实现批量部署、批量控制爬虫。假设有一百台云服务器,只要每一台上面都安装了Scrapyd,那么使用Python来批量部署并启动爬虫所需要的时间不超过1min。这里给出一个批量部署并启动爬虫的例子,首先在爬虫的根目录下创建一个scrapy_template.cfg文件,其内容如图所示。
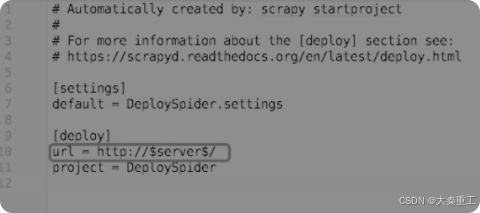
scrapy_template.cfg与scrapy.cfg的唯一不同之处就在于url这一项,其中的IP地址和端口变成了server。接下来编写批量部署和运行爬虫的脚本,如图所示。
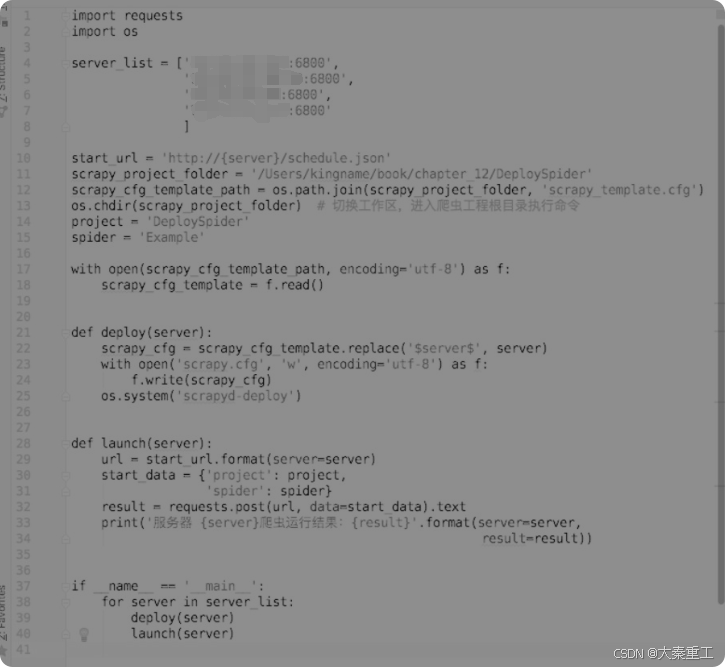
这个脚本的作用是逐一修改scrapy.cfg里面的IP地址和端口,每次修改完成以后就部署并运行爬虫。运行完成以后再使用下一个服务器的IP地址修改scrapy.cfg,再部署再运行,直到把爬虫部署到所有的服务器上并运行。
二、权限管理
在整个使用Scrapyd的过程中,只要知道IP地址和端口就可以操作爬虫。如果IP地址和端口被别人知道了,那岂不是别人也可以随意控制你的爬虫?确实是这样的,因为Scrapyd没有权限管理系统。任何人只要知道了IP地址和端口就可以控制爬虫。为了弥补Scrapyd没有权限管理系统这一短板,就需要借助其他方式来对网络请求进行管控。带权限管理的反向代理就是一种解决办法。能实现反向代理的程序很多,本次以Nginx为例来进行说明。
1. Nginx的介绍
Nginx读作Engine X,是一个轻量级的高性能网络服务器、负载均衡器和反向代理。为了解决Scrapyd的问题,需要用Nginx做反向代理。所谓"反向代理",是相对于"正向代理"而言的。前面章节所用到的代理是正向代理。正向代理帮助请求者(爬虫)隐藏身份,爬虫通过代理访问服务器,服务器只能看到代理IP,看不到爬虫;反向代理帮助服务器隐藏身份。用户只知道服务器返回的内容,但不知道也不需要知道这个内容是在哪里生成的。使用Nginx反向代理到Scrapyd以后,Scrapyd本身只需要开通内网访问即可。用户访问Nginx, Nginx再访问Scrapyd,然后Scrapyd把结果返回给Nginx, Nginx再把结果返回给用户。这样只要在Nginx上设置登录密码,就可以间接实现Scrapyd的访问管控了,如图所示。

这个过程就好比是家里的保险箱没有锁,如果把保险箱放在大庭广众之下,谁都可以去里面拿钱。但是现在把保险箱放在房间里,房间门有锁,那么即使保险箱没有锁也没关系,只有手里有房间门钥匙的人才能拿到保险箱里面的钱。Scrapyd就相当于这里的"保险箱",云服务器就相当于这里的"房间", Nginx就相当于"房间门",而登录账号和密码就相当于房间门的"钥匙"。为了完成这个目标,需要先安装Nginx。由于这里涉及爬虫的部署和服务器的配置,因此仅以Linux的Ubuntu为例。一般不建议Windows做爬虫服务器,也不建议购买很多台苹果计算机(因为太贵了)来搭建爬虫服务器。
2.Nginx的安装
在Ubuntu中安装Nginx非常简单,使用一行命令即可完成:
sudo apt-get install nginx安装好以后,需要考虑以下两个问题。(1)服务器是否有其他的程序占用了80端口。(2)服务器是否有防火墙。对于第1个问题,如果有其他程序占用了80端口,那么Nginx就无法启动。因为Nginx会默认打开80端口,展示一个安装成功的页面。当其他程序占用了80端口,Nginx就会因为拿不到80端口而报错。要解决这个问题,其办法有两个,关闭占用80端口的程序,或者把Nginx默认开启的端口改为其他端口。如果云服务器为国内的服务器,建议修改Nginx的默认启动端口,无论是否有其他程序占用了80端口。这是因为国内服务器架设网站是需要进行备案的,而80端口一般是给网站用的。如果没有备案就开启了80端口,有可能导致云服务器被运营商停机。
比如,讲监听端口从80修改为81;然后使用下列命令重启Nginx
sudo systemctl restart nginx重启Nginx可以在1~2s内完成。完成以后,使用浏览器访问格式为"服务器IP:81"的地址,如果出现图所示的页面,表示服务器没有防火墙,Nginx架设成功。
如果浏览器提示网页无法访问,那么就可能是服务器有防火墙,因此需要让防火墙对81端口的数据放行。不同的云服务器提供商,其防火墙是不一样的。例如Vultr,它没有默认的防火墙,Nginx运行以后就能用;国内的阿里云,CentOS系统服务器自带的防火墙为firewalld; Ubuntu系统自带的防火墙是Iptables;亚马逊的AWS,需要在网页后台开放端口;而UCloud,服务器自带防火墙的同时,网页控制台上还有对端口的限制。因此,要开放一个端口,最好先看一下云服务器提供商使用的是什么样的防火墙策略,并搜索提供商的文档。如果云服务器提供商没有相关的文档,可以问 AI ,比如:Deepseek 。
开放了端口以后,就可以开始配置环境了。
3.配置反向代理
首先打开/etc/scrapyd/scrapyd.conf,把bind_address这一项重新改为127.0.0.1,并把http_port这一项改为6801,如图所示。
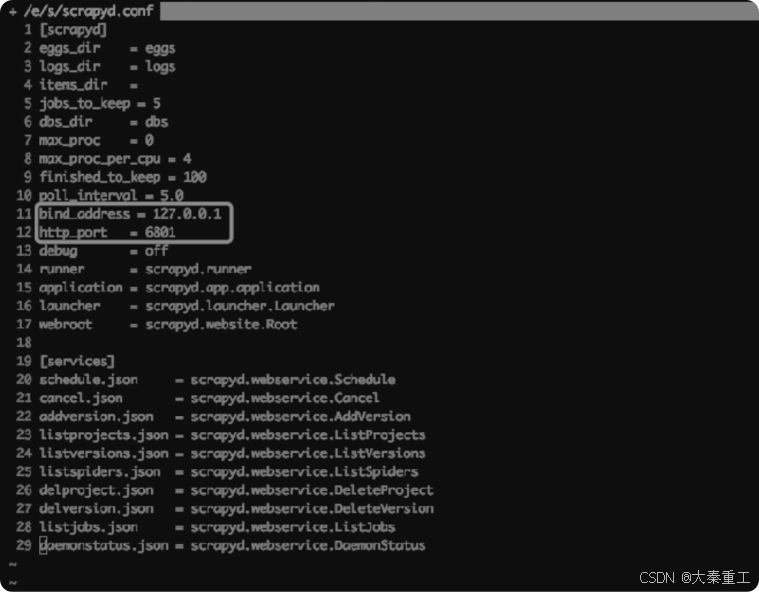
这样修改以后,如果再重新启动Scrapyd,只能在服务器上向127.0.0.1:6801发送请求操作Scrapyd,服务器之外是没有办法连上Scrapyd的。接下来配置Nginx,在/etc/nginx/sites-available文件夹下创建一个scrapyd.conf,其内容为:
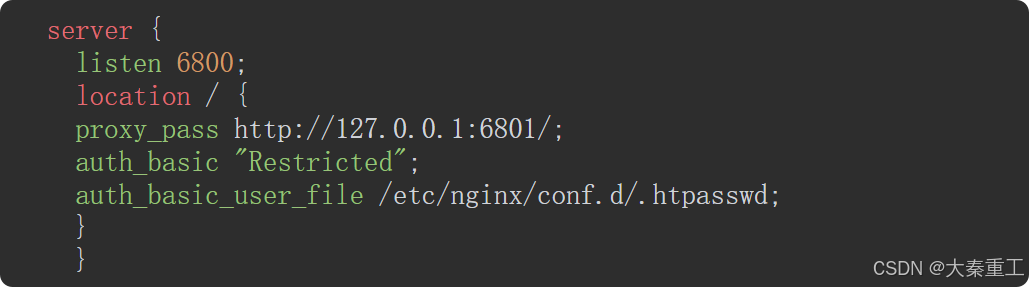
这个配置的意思是说,使用basic auth权限管理方法,对于通过授权的用户,将它对6800端口的请求转到服务器本地的6801端口。需要注意配置里面的记录授权文件的路径这一项:

在后面会将授权信息的记录文件放在/etc/nginx/conf.d/.htpasswd这个文件中。写好这个配置以后,保存。接下来,执行下面的命令,在/etc/nginx/sites-enabled文件夹下创建一个软连接:

软连接创建好以后,需要生成账号和密码的配置文件。
首先安装apache2-utils软件包:

安装完成apache2-utils以后,cd进入/etc/nginx/conf.d文件夹,并执行命令为用户kingname生成密码文件:

屏幕会提示输入密码,与Linux的其他密码输入机制一样,在输入密码的时候屏幕上不会出现*号,所以不用担心,输入完成密码按Enter键即可。
上面的命令会在/etc/nginx/conf.d文件夹下生成一个.htpasswd的隐藏文件。有了这个文件,Nginx就能进行权限验证了。接下来重启Nginx:

重启完成以后,启动Scrapyd,再在浏览器上访问格式为"http://服务器IP:6800"的网址,可以看到图所示的页面。
在这里输入使用htpasswd生成的账号和密码,就可以成功登录Scrapyd。
4.配置Scrapy工程
由于为Scrapyd添加了权限管控,涉及的部署爬虫、启动/停止爬虫的地方都要做一些小修改。首先是部署爬虫,为了让scrapyd-deploy能成功地输入密码,需要修改爬虫根目录的scrapy.cfg文件,添加username和password两项,其中username对应账号,password对应密码,如图所示。
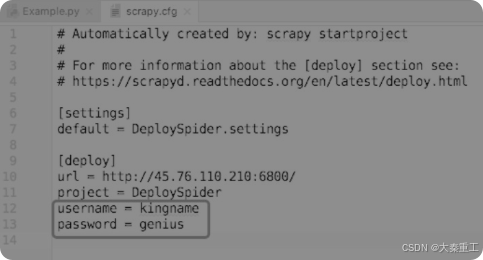
配置好scrapy.cfg以后,部署爬虫的命令不变,还是进入这个Scrapy工程的根目录,执行以下代码即可:
scrapyd-deploy使用curl启动/关闭爬虫,只需要在命令上加上账号参数即可。账号参数为"-u用户名:密码"。所以,启动爬虫的命令为:
curl http://192.168.31.210:6800/schedule.json-d project=工程名-d spider=爬虫名 -u kingname:genius停止爬虫的命令为:
curl http://192.168.31.210:6800/cancel.json-d project=工程名-d job=爬虫JOBID-u kingname:genius如果使用Python与requests编写脚本来控制爬虫,那么账号信息可以作为POST方法的一个参数,参数名为auth,值为一个元组,元组第0项为账号,第1项为密码:
result = requests.post(start_url, data=start_data, auth=('kingname', 'genius')).text
result = requests.post(end_url, data=end_data, auth=('kingname', 'genius')).text三、分布式架构介绍
之前讲到了把目标放到Redis里面,然后让多个爬虫从Redis中读取目标再爬取的架构,这其实就是一种主---从式的分布式架构。使用Scrapy,配合scrapy_redis,再加上Redis,也就实现了一个所谓的分布式爬虫。实际上,这种分布式爬虫的核心概念就是一个中心结点,也叫Master。它上面跑着一个Redis,所有的待爬网站的网址都在里面。其他云服务器上面的爬虫(Slave)就从这个共同的Redis中读取待爬网址。只要能访问这个Master服务器,并读取Redis,那么其他服务器使用什么系统什么提供商都没有关系。例如,使用Ubuntu作为爬虫的Master,用来做任务的派分。使用树莓派、Windows 10 PC和Mac来作为分布式爬虫的Slave,用来爬取网站,并将结果保存到Mac上面运行的MongoDB中。
其中,作为Master的Ubuntu服务器仅需要安装Redis即可,它的作用仅仅是作为一个待爬网址的临时中转,所以甚至不需要安装Python。在Mac、树莓派和Windows PC中,需要安装好Scrapy,并通过Scrapyd管理爬虫。由于爬虫会一直监控Master的Redis,所以在Redis没有数据的时候爬虫处于待命状态。当目标被放进了Redis以后,爬虫就能开始运行了。由于Redis是一个单线程的数据库,因此不会出现多个爬虫拿到同一个网址的情况。
严格来讲,Master只需要能运行Redis并且能被其他爬虫访问即可。但是如果能拥有一个公网IP则更好。这样可以从世界上任何一个能访问互联网的地方访问Master。但如果实在没有云服务器,也并不是说一定得花钱买一个,如果自己有很多台计算机,完全可以用一台计算机来作为Master,其他计算机来做Slave。Master也可以同时是Slave。Scrapy和Redis是安装在同一台计算机中的。这台计算机既是Master又是Slave。Master一定要能够被其他所有的Slave访问。所以,如果所有计算机不在同一个局域网,那么就需要想办法弄到一台具有公网IP的计算机或者云服务器。在中国,大部分情况下,电信运营商分配到的IP是内网IP。在这种情况下,即使知道了IP地址,也没有办法从外面连进来。在局域网里面,因为局域网共用一个出口,局域网内的所有共用同一个公网IP。对网站来说,这个IP地址访问频率太高了,肯定不是人在访问,从而被网站封锁的可能性增大。而使用分布式爬虫,不仅仅是为了提高访问抓取速度,更重要的是降低每一个IP的访问频率,使网站误认为这是人在访问。所以,如果所有的爬虫确实都在同一个局域网共用一个出口的话,建议为每个爬虫加上代理。在实际生产环境中,最理想的情况是每一个Slave的公网IP都不一样,这样才能做到既能快速抓取,又能减小被反爬虫机制封锁的机会。
四、爬虫开发中的法律与道德问题
全国人民代表大会常务委员会在2016年11月7日通过了《中华人民共和国网络安全法》,2017年6月1日正式实施。爬虫从过去游走在法律边缘的灰色产业,变得有法可循。在开发爬虫的过程中,一定要注意一些细节,否则容易在不知不觉中触碰道德甚至是法律的底线。
1. 数据采集的法律问题
如果爬虫爬取的是商业网站,并且目标网站使用了反爬虫机制,那么强行突破反爬虫机制可能构成非法侵入计算机系统罪、非法获取计算机信息系统数据罪。如果目标网站有反爬虫声明,那么对方在被爬虫爬取以后,可以根据服务器日志或者各种记录来起诉使用爬虫的公司。这里有几点需要注意。
(1)目标网站有反爬虫声明。
(2)目标网站能在服务器中找到证据(包括但不限于日志、IP)。
(3)目标网站进行起诉。如果目标网站本身就是提供公众查询服务的网站,那么使用爬虫是合法合规的。但是尽量不要爬取域名包含.gov的网站。
2. 数据的使用
公开的数据并不一定被允许用于第三方盈利目的。例如某网站可以供所有人访问,但是如果一个开发把这个网站的数据爬取下来,然后用于盈利,那么可能会面临法律风险。成熟的大数据公司在爬取并使用一个网站的数据时,一般都需要专业的律师对目标网站进行审核,看是否有禁止爬取或者禁止商业用途的相关规定。
3. 注册及登录可能导致的法律问题
自己能查看的数据,不一定被允许擅自拿给第三方查看。例如登录很多网站以后,用户可以看到"用户自己"的数据。如果开发把自己的数据爬取下来用于盈利,那么可能面临法律风险。因此,如果能在不登录的情况下爬取数据,那么爬虫就绝不应该登录。这一方面是避免反爬虫机制,另一方面也是减小法律风险。如果必须登录,那么需要查看网站的注册协议和条款,检查是否有禁止将用户自己后台数据公开的相关条文。
4. 数据存储
根据《个人信息和重要数据出境安全评估办法(征求意见稿)》第九条的规定,包含或超过50万人的个人信息,或者包含国家关键信息的数据,如果要转移到境外,必须经过主管或者监管部门组织安全评估。
5. 内幕交易
如果开发通过爬虫抓取某公司网站的公开数据,分析以后发现这个公司业绩非常好,于是买入该公司股票并赚了一笔钱。这是合法的。如果开发通过爬虫抓取某公司网站的公开数据,分析以后发现这个公司业绩非常好。于是将数据或者分析结果出售给某基金公司,从而获得销售收入。这也是合法的。如果开发通过爬虫抓取某公司网站的公开数据,分析以后发现这个公司业绩非常好,于是首先把数据或者分析结果出售给某基金公司,然后自己再买被爬公司的股票。此时,该开发涉嫌内幕交易,属于严重违法行为。之所以出售数据给基金公司以后,开发就不能在基金公司购买股票之前再购买被爬公司股票,这是由于"基金公司将要购买哪一只股票"属于内幕消息,使用内幕消息购买股票将严重损坏市场公平,因此已被定义为非法行为。而开发自身是没有办法证明自己买被爬公司的股票是基于对自己数据的信心,而不是基于知道了某基金公司将要购买该公司股票这一内幕消息的。在金融领域,有一个词叫作"老鼠仓",与上述情况较为类似。
五、道德协议
在爬虫开发过程中,除了法律限制以外,还有一些需要遵守的道德规范。虽然违反也不会面临法律风险,但是遵守才能让爬虫细水长流。
robots.txt协议robots.txt是一个存放在网站根目录下的ASCII编码的文本文件。爬虫在爬网站之前,需要首先访问并获取这个robots.txt文件的内容,这个文件里面的内容会告诉爬虫哪些数据是可以爬取的,哪些数据是不可以爬取的。要查看一个网站的robots.txt,只需要访问"网站域名/robots.txt",例如知乎的robots.txt地址为https://www.zhihu.com/robots.txt,访问后的结果如图所示。
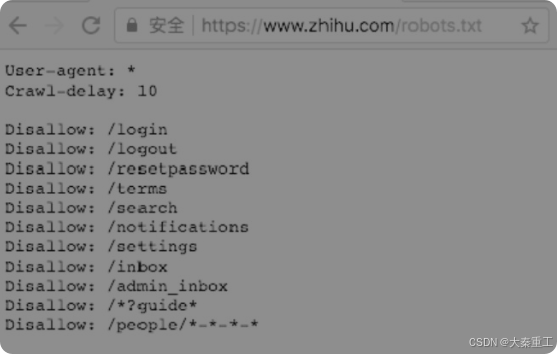
这个robots.txt文件表示,对于任何爬虫,允许爬取除了以Disallow开头的网址以外的其他网址,并且爬取的时间间隔为10s。Disallow在英文中的意思是"不允许",因此列在这个页面上的网址是不允许爬取的,没有列在这里的网址都是可以爬取的。在Scrapy工程的settings.py文件中,有一个配置项为"ROBOTSTXT_OBEY",如果设置为True,那么Scrapy就会自动跳过网站不允许爬取的内容。robots.txt并不是一种规范,它只是一种约定,所以即使不遵守也不会受到惩罚。但是从道德上讲,建议遵守。
新手开发在开发爬虫时,往往不限制爬虫的请求频率。这种做法一方面很容易导致爬虫被网站屏蔽,另一方面也会给网站造成一定的负担。如果很多爬虫同时对一个网站全速爬取,那么其实就是对网站进行了DDOS(Distributed Denial-of-Service,分布式拒绝服务)攻击。小型网站是无法承受这样的攻击的,轻者服务器崩溃,重者耗尽服务器流量。而一旦服务器流量被耗尽,网站在一个月内都无法访问了。
开源是一件好事,但不要随便公开爬虫的源代码。因为别有用心的人可能会拿到被公开的爬虫代码而对网站进行攻击或者恶意抓取数据。网站的反爬虫技术也是一种知识产权,而破解了反爬虫机制再开源爬虫代码,其实就相当于把目标网站的反爬虫技术泄漏了。这可能会导致一些不必要的麻烦。
在爬虫开发和数据采集的过程中,阅读网站的协议可以有效发现并规避潜在的法律风险。爬虫在爬取网站的时候控制频率,善待网站,才能让爬虫运行得更长久。
没有自由的秩序和没有秩序的自由,同样具有破坏性。
