简介
Chromadb 是一个开源的嵌入式向量数据库,专为现代人工智能和机器学习应用设计,旨在高效存储、检索和管理向量数据。以下是关于它的详细介绍:
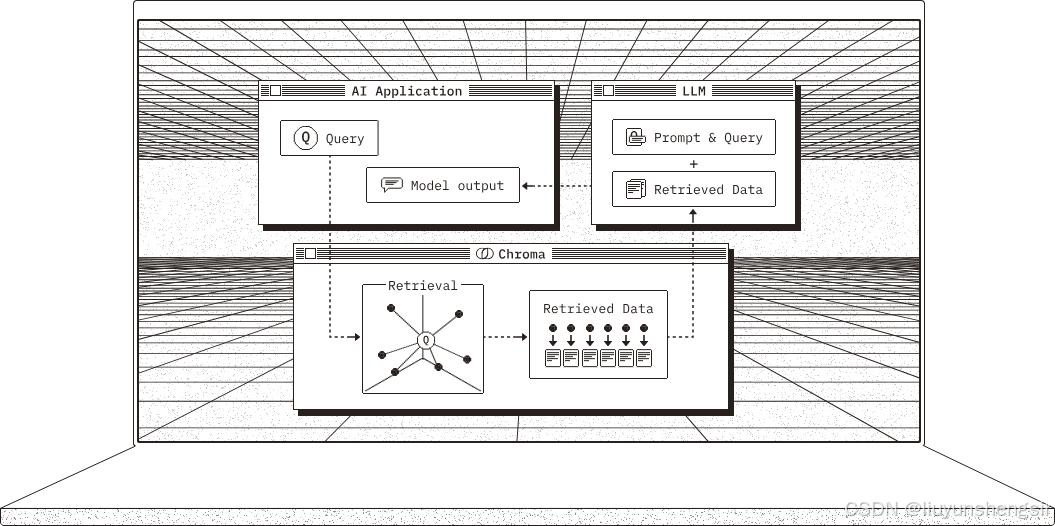
核心特性
- 易于使用:提供了简洁直观的 API,即使是新手也能快速上手,轻松实现向量数据的存储与查询。
- 高性能:采用了优化的索引结构和查询算法,能够在大规模向量数据集中实现快速的相似度搜索,有效满足实时应用的需求。
- 可扩展性:支持水平扩展和分布式部署,能随着数据量和查询负载的增长而灵活扩展,适应不同规模的应用场景。
- 多模态支持:不仅可以处理文本嵌入向量,还能支持图像、音频等多种模态的向量数据,为多模态应用提供了强大的支持。
- 数据持久化:提供了数据持久化功能,确保在系统重启或崩溃后数据不会丢失,保证数据的安全性和可靠性。
应用场景
- 语义搜索:在文档、文章、网页等文本数据中,根据语义相似性进行搜索,帮助用户快速找到最相关的信息。
- 推荐系统:通过分析用户的历史行为和偏好,计算物品之间的相似度,为用户提供个性化的推荐。
- 图像和视频检索:在图像和视频数据库中,根据视觉特征进行检索,帮助用户快速找到相似的图像或视频。
- 问答系统:在知识库中查找与用户问题最相似的答案,为用户提供准确的回答。
技术架构
Chromadb 的架构设计简洁高效,主要由以下几个部分组成:
- 客户端 API:提供了 Python、JavaScript 等多种编程语言的客户端 API,方便开发者集成到自己的应用中。
- 索引引擎:采用了高效的索引结构,如 HNSW(Hierarchical Navigable Small World),能够快速定位和检索向量数据。
- 存储引擎:支持多种存储后端,如本地文件系统、内存数据库等,用户可以根据自己的需求选择合适的存储方式。
- 分布式系统:支持分布式部署,通过分布式存储和计算,实现数据的水平扩展和高可用性。
社区与生态
Chromadb 拥有活跃的开源社区,开发者可以在社区中分享经验、提交问题和贡献代码。此外,Chromadb 还与许多其他开源项目和工具集成,如 LangChain、Hugging Face 等,形成了丰富的生态系统,为开发者提供了更多的选择和便利。
安装chromadb
pip install chromadb下载all-MiniLM-L6-v2 依赖模型
all-MiniLM-L6-v2 是一个小型语言模型,属于 MiniLM 系列,它通过知识蒸馏技术从更大的模型中压缩而来,旨在保持较高性能的同时减少计算资源需求。
all-MiniLM-L6-v2 是一个高效的轻量级语言模型,适合资源有限的环境,能够胜任多种 NLP 任务。
#SDK模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('wengad/all-MiniLM-L6-v2')然后
cp -r /mnt/workspace/.cache/modelscope/models/wengad/all-MiniLM-L6-v2 /root/.cache/chroma/onnx_models/all-MiniLM-L6-v2使用
import chromadb
chroma_client = chromadb.PersistentClient(path="/mnt/workspace/chromadbdata")
# switch `create_collection` to `get_or_create_collection` to avoid creating a new collection every time
collection = chroma_client.get_or_create_collection(name="my_collection")
# switch `add` to `upsert` to avoid adding the same documents every time
collection.upsert(
documents=[
"This is a document about pineapple",
"This is a document about oranges"
],
ids=["id1", "id2"]
)
results = collection.query(
query_texts=["This is a query document about florida"], # Chroma will embed this for you
n_results=2 # how many results to return
)
print(results)参考
https://docs.trychroma.com/docs/run-chroma/persistent-client
https://blog.csdn.net/2401_85390073/article/details/143560813