目录
[六. 模型的泛化能力](#六. 模型的泛化能力)

在上一篇中提到了常见的任务和算法,本篇我们就用线性回归来解决数值预测(回归)问题
| 分类问题 | 回归问题 | 聚类问题 | 各种复杂问题 |
|---|---|---|---|
| 决策树√ | 线性回归√ | K-means√ | 神经网络√ |
| 逻辑回归√ | 岭回归 | 密度聚类 | 深度学习√ |
| 集成学习√ | Lasso回归 | 谱聚类 | 条件随机场 |
| 贝叶斯 | 层次聚类 | 隐马尔可夫模型 | |
| 支持向量机 | 高斯混合聚类 | LDA主题模型 |
一.回归问题
回归分析(Regression Analysis): 用函数模型拟合样本数据,获得目标变量与自变量(即特征)之间的关系。用于预测新的特征值对应的目标变量值。目标变量值是连续的数据。

二.一元线性回归
(1)一元线性回归的定义
通过拟合一个目标变量 和一个特征 之间最佳的线性关系来预测目标变量值。
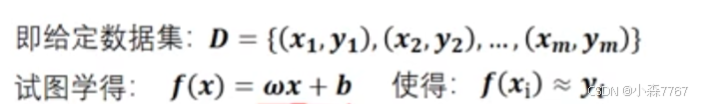

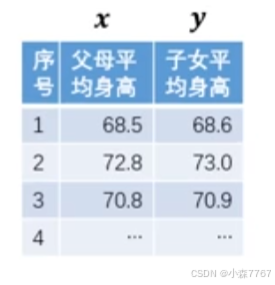
**例如:**以下一元线性回归模型可以利用父母平均身高来预测其子女平均身高。
给定数据集:D={(68.5,68.6),(72.8,73.0),......}
试图学得:f(x)=ωx+b 使得:f(xi)≈yi
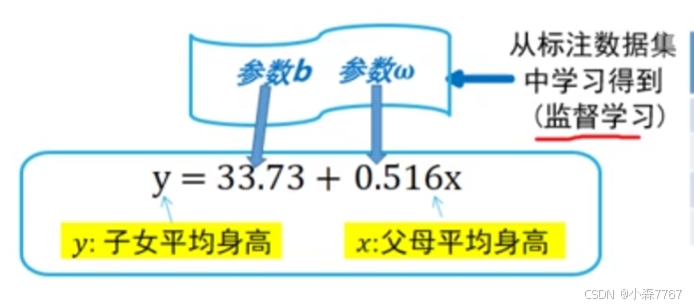
**模型实际意义解释:**基础身高33.73英寸,父母平均身高每增加1英寸,子女平均身高增加0.516英寸。
(2)一元线性回归模型的参数学习

这样参数学习的问题就转化成了求损失函数最小值的问题
(3)一元线性回归模型的参数学习---正规方程法
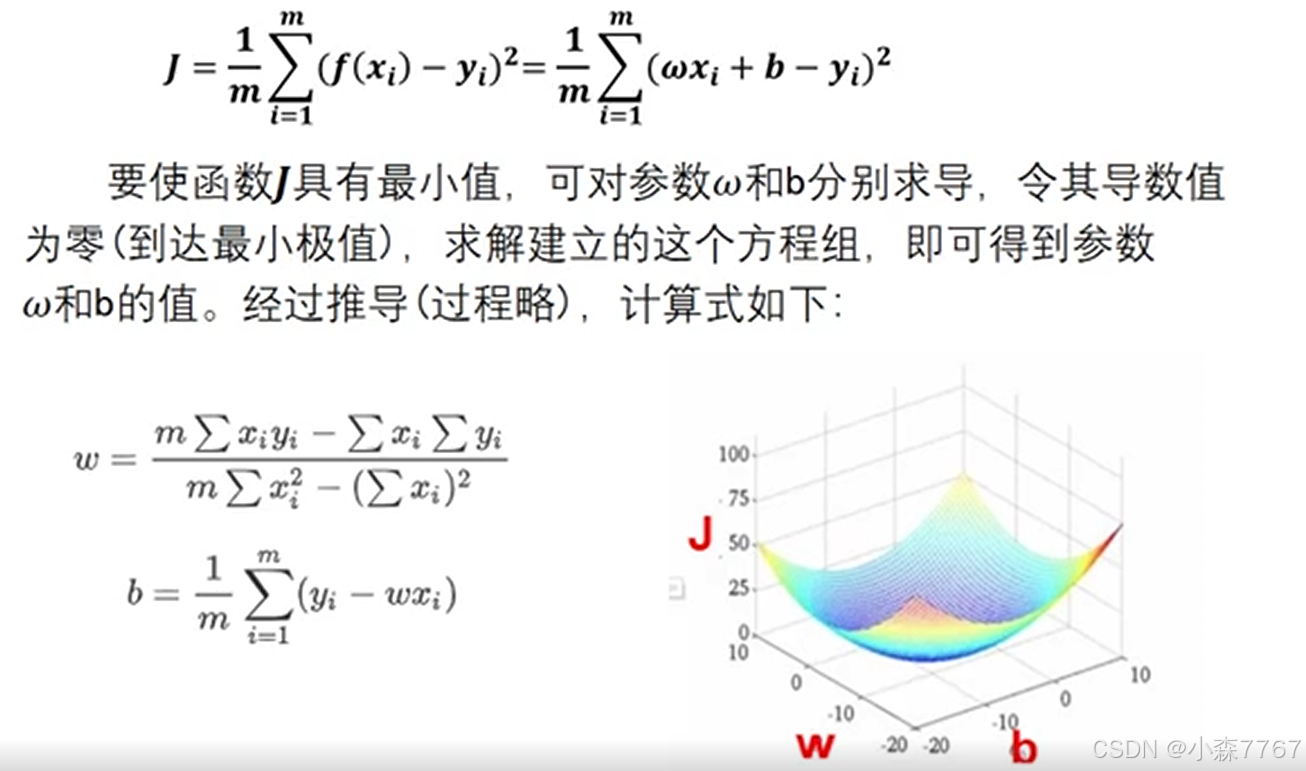
这里的算式我们称为天才算法,直接求解!只要样本数大于参数个数,即可求得任意多元线性回归参数。但参数多时(如大于一万)计算量很大
(4)一元线性回归模型的参数学习---梯度下降法
在处理大量参数时,传统的数学解法存在计算量过大的问题。为了解决这一难题,研究人员提出了梯度下降法作为更为通用的参数学习方法。这种方法通过不断迭代优化,逐步接近最优解------即损失函数的极小值。以类似摇床的图形为例,该过程涉及选择初始参数组合(如欧米伽),并根据其计算出相应的损失函数值;随后调整参数使其损失函数值降低最多,从而找到最佳参数组合。

具体来说,通过调整学习速率(阿尔法)和当前参数值(如B),可以确定每次迭代时参数变化的具体步长。这一过程涉及计算损失函数关于目标变量(如B)的偏导数,以此来判断下一步应该在哪条路径上前进。每一次迭代都使模型参数向着损失函数曲线最低处移动一小步,最终达到全局最优解或局部极小值。简而言之,这种方法不断更新参数,使其沿梯度方向逐步逼近最佳结果。
(5)一元线性回归模型的参数学习---批量梯度下降法
另一种常见的梯度下降方式------批量梯度下降,其特点是所有训练数据都会被用于每一次的参数更新。

虽然梯度下降是一种有效的寻找最优解的方法,但选择合适的步长以及理解何时停止迭代对于确保算法的有效性和效率至关重要。
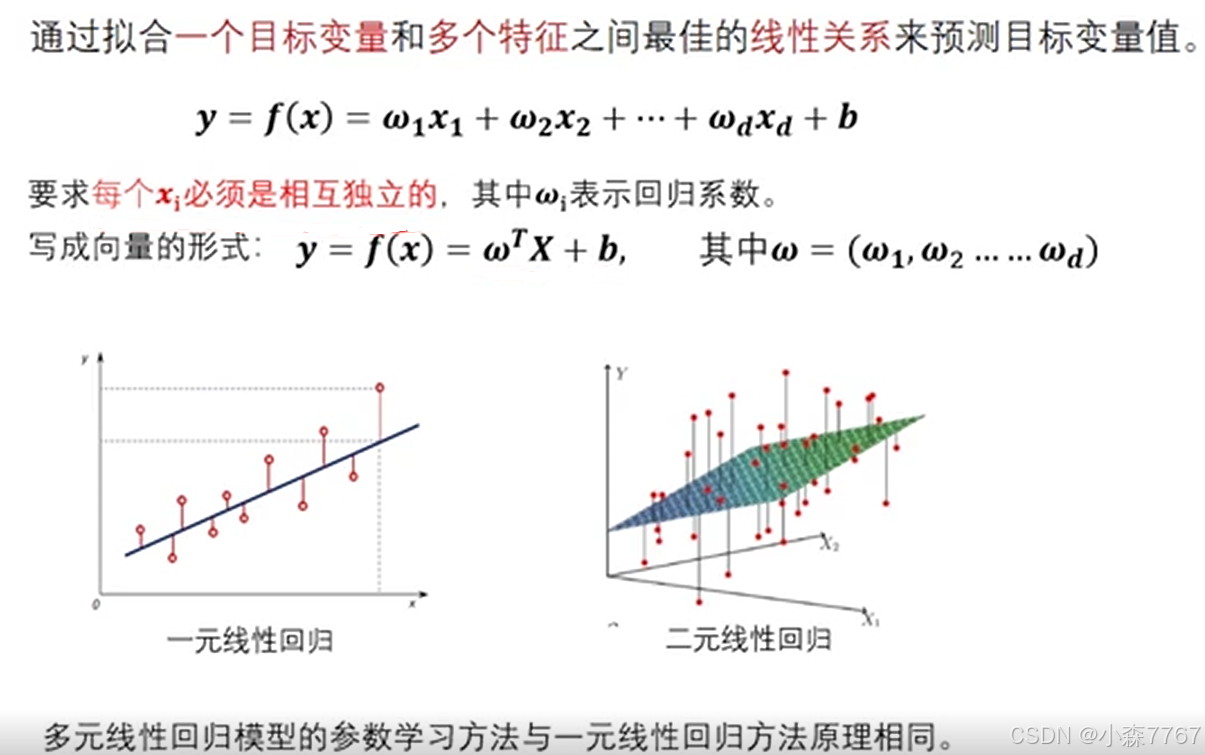
三.多元线性回归
多元线性回归能够建立目标变量与其多个特征之间的一般线性关系,公式形式上类似于一元线性回归但扩展至更多维度。
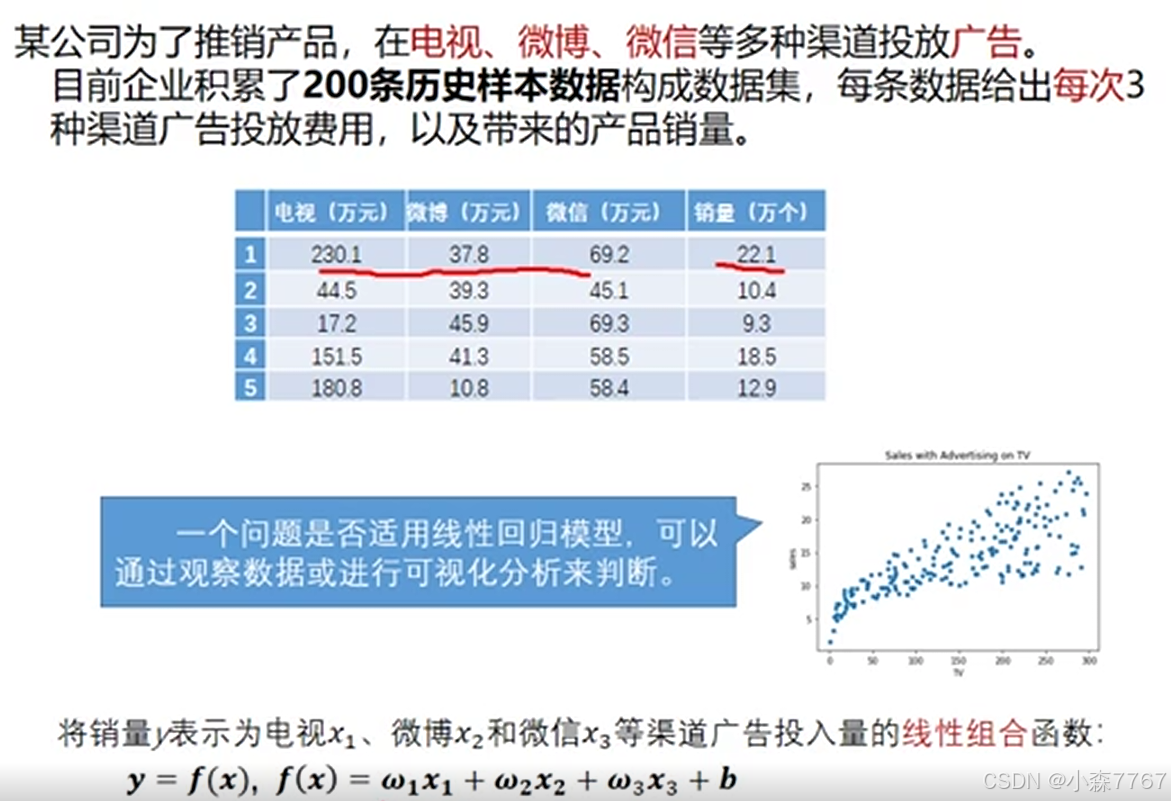
多元线性回归案例:广告公司收益预测:
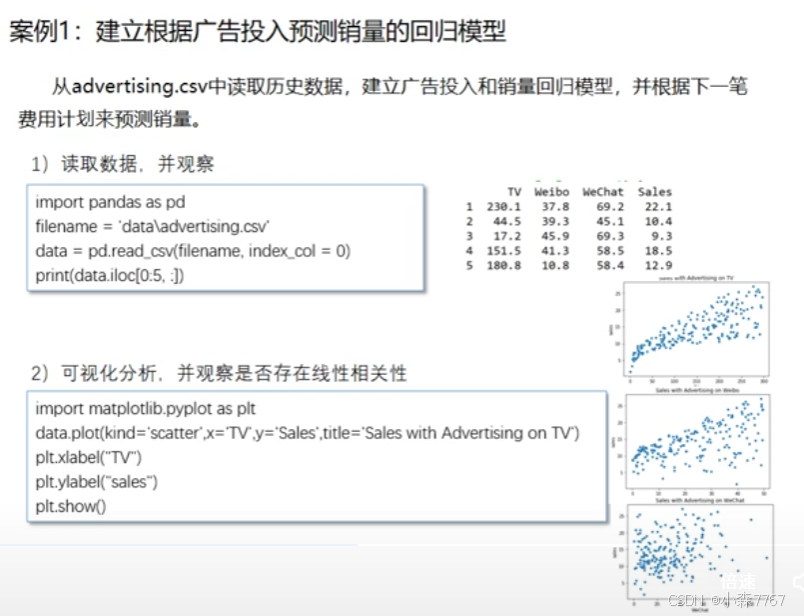
四.用python实现线性回归
下面介绍采用Python语言基于Scikit-learn库实现线性回归建模和应用的方法,对建模过程和相关支持函数,数据集分割、模型的性能评价等问题进行介绍
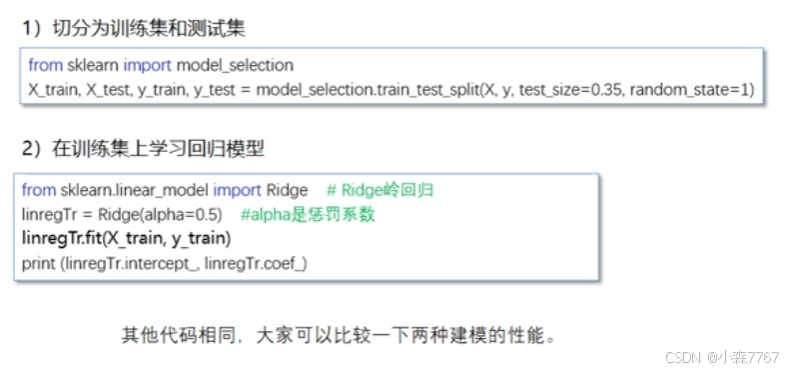
(1)基于scikit-learn实现线性回归

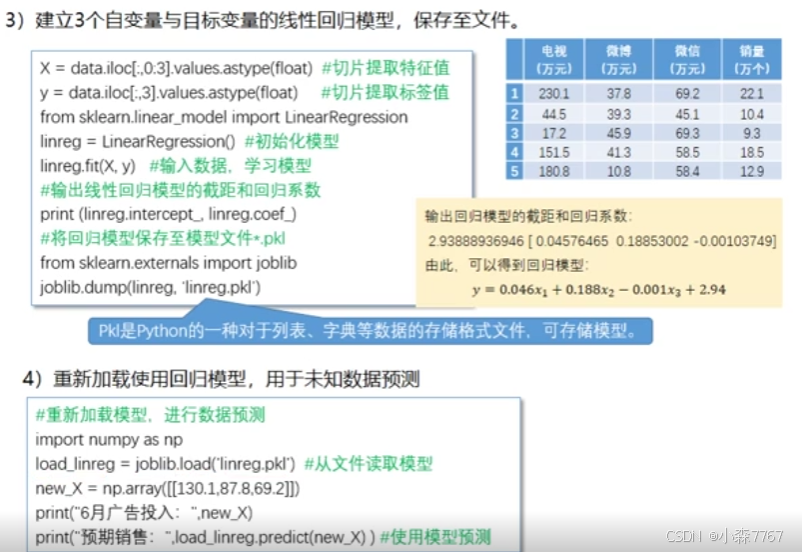
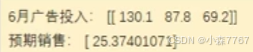
(2)线性回顾模型的性能评估
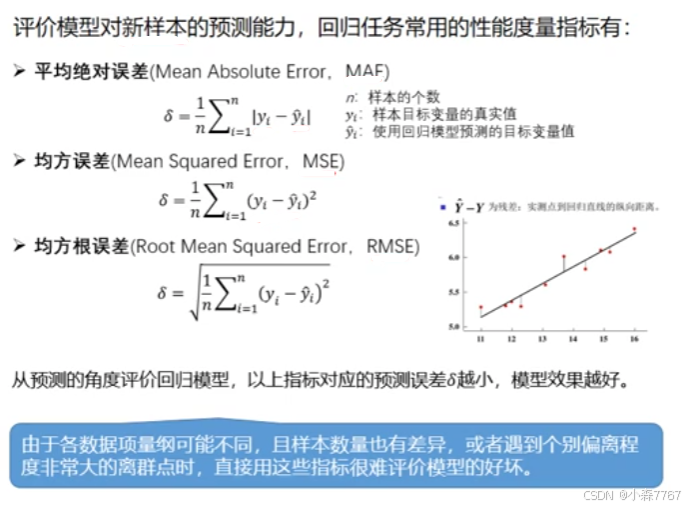
谈到模型的性能评价,就必须要知道训练集与测试集, 为了更准确地评价模型性能,通常将原始数据切分为两部分。
训练集:用于学习获得回归模型
测试集:视为未知数据,用于评估模型性能

常用留出法拆分数据集
直接将数据集划分为互斥的集合,如选70%作为训练集 ,30%作为测试集。注意保持划分后集合数据分布的一致性,避免引入额外的偏差。

下面我们继续用案例1来举例
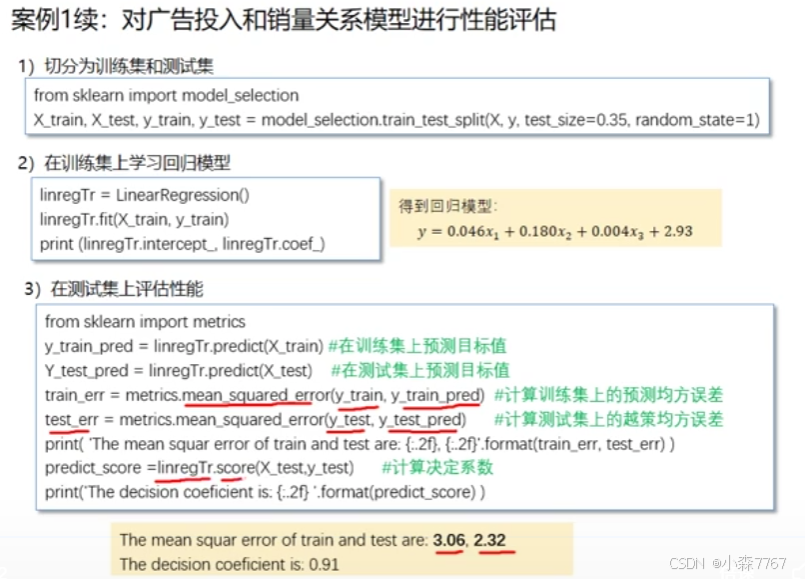
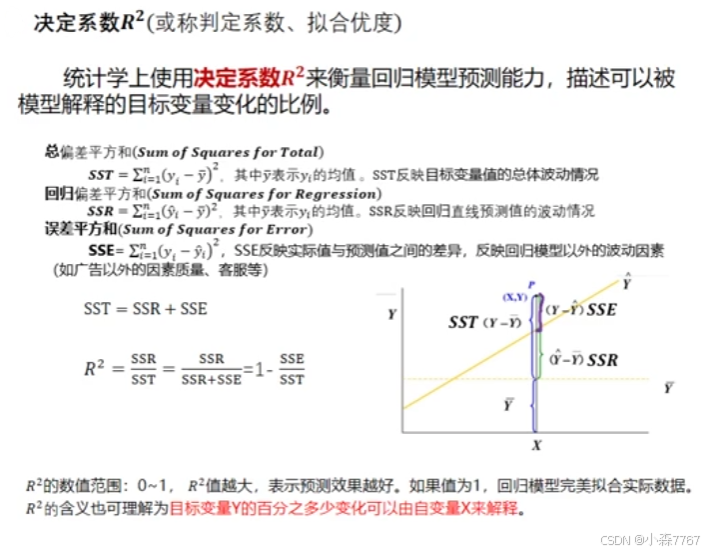
这里决定系数越接近1越好,值越大表示模型对目标变量变化的解释力越强。
五.广义线性回归
(1)广义线性回归的定义
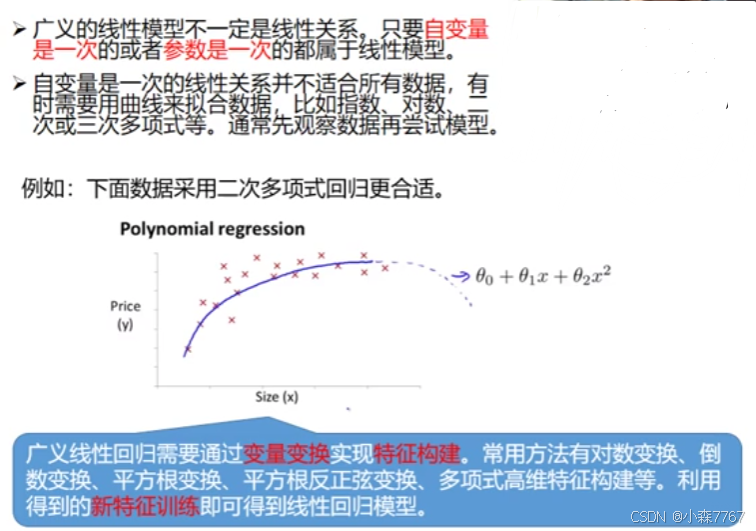
(2)多项式的高维特征构建


六. 模型的泛化能力
(1)泛化能力
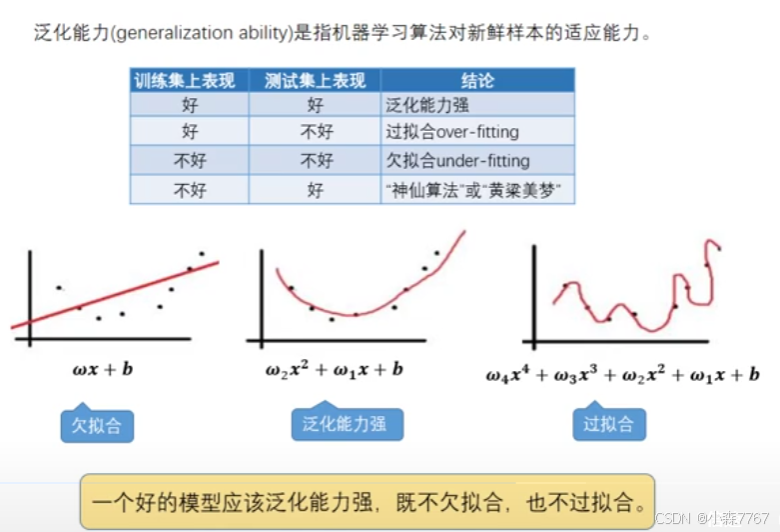
(2)过拟合和欠拟合的解决办法

(3)用python实现岭回归