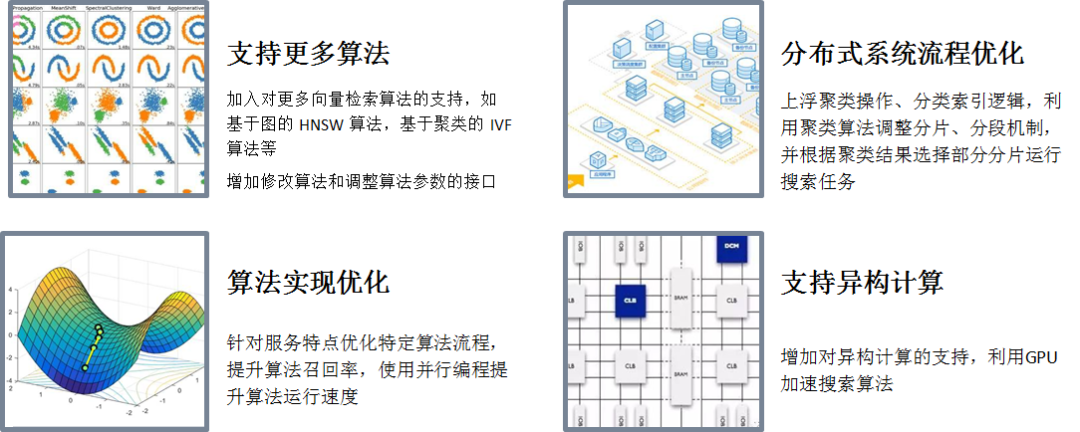
基于ElasticSearch的向量检索技术实践
作者:Tableau
图片、视频、语音、文本等非结构化数据可以通过人工智能技术(深度学习算法)提取特征向量,然后通过对这些特征向量的计算和检索来实现对非结构化数据的分析与检索。 针对向量检索常见的应用场景有:
-
图片识别:以图搜图,通过图片检索图片;人脸识别
-
自然语言处理:基于语义的文本检索。
-
声纹匹配:音频检索。
-
电商推荐:提取用户个性化特征或是商品的个性化属性,提高推荐模型的准确性,获得更加精确的推荐结果。
-
知识图谱:智能搜索,智能问答,个性化推荐。

后续研究实践,以人脸为例,进行讨论介绍。
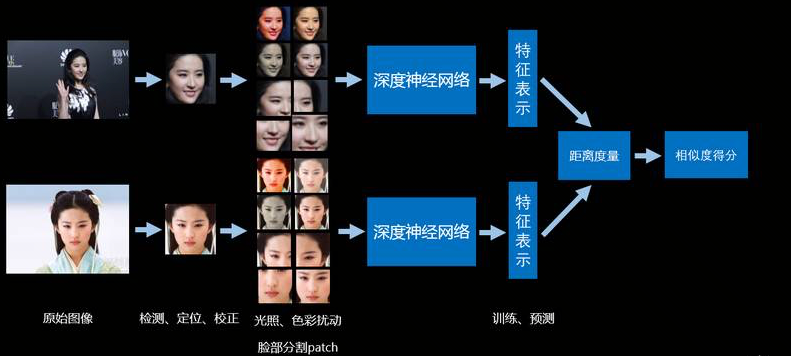
向量检索面临的挑战主要在以下几个方面
-
高维数据:向量数据维度通常是 256/512 维。
-
海量数据:在电商场景图片搜索或者商品知识图谱等,
-
向量数据通常在千万到亿别级别。
-
高召回:为保证检索效果,精度召回率通常要求 95% 以上。
-
高性能:为保证用户体验,向量检索的响应要求毫秒级。
工程落地面临的挑战
-
系统高可用:需要实现一个分布式高可用系统
-
向量检索算法:需要根据不同场景,召回率和性能要求使用不同算法,并进行性能优化
-
通用的向量检索:适用于各种场景
-
与传统搜索结合:在向量检索的同时,需要其他一些业务字段的查询,过滤,和排序
向量检索简介
向量检索与机器学习分类问题
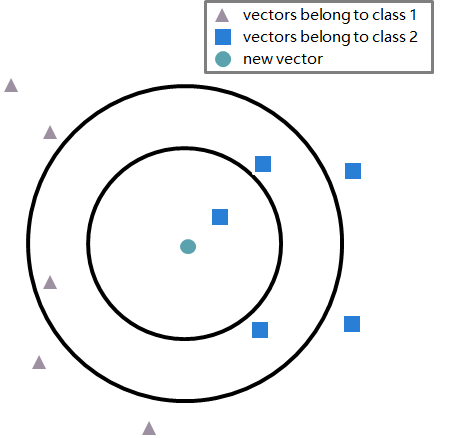
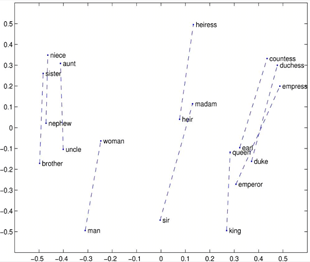
在人脸识别的过程中,输入的人脸图片会转化为人脸特征值向量保存在计算机中作为人脸库,假设右图方块表示小王的多个人脸图片的特征值向量,三角表示小李的多个人脸特征值向量绿色向量表示输入的一张未知人脸图片的特征值向量。使用两向量的距离评估两向量表示的人脸的相似度在右图中与绿色新向量距离最近的为一方块向量,因此认为新输入的图片最有可能是小王的人脸图片。与人脸识别问题类似的其他的机器学习分类问题中,向量检索也是应用流程中的重要环节。
向量距离
KNN 检索最重要的子问题是如何评估任两个向量间的距离,机器学习聚类算法中最常用的距离是欧式距离和余弦距离。对某二维平面上两点

**欧式距离:两向量终点连线的长度
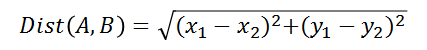
**余弦距离:两向量夹角的余弦值
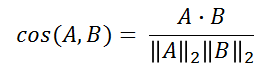
即:在向量归一化后,欧式距离与余弦距离等效,但在进行向量距离的矩阵运算时,欧式距离有明显的性能优势,因此向量检索系统统一使用欧式距离作为评判标准。
FAISS库介绍
Faiss是Facebook AI团队开源的针对聚类和相似性搜索库,针对稠密向量设计和优化,可以提供高效的聚类运算和搜索运算,也是当前最受欢迎的近似近邻搜索库,使用C++开发,源码逻辑清晰结构简单提供C++和Python两种接口,提供了搜索算法的GPU实现,可扩展性强我们可以通过Jni封装来实现ES的Faiss插件。
Faiss支持众多搜索算法,主流的算法有:
-
IndexFlatL2 和IndexFlatIP:使用BLAS库优化的暴力搜索。
-
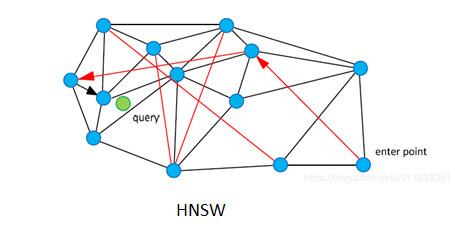
IndexHNSWFLat:HNSW(Hierarchical Navigable Small World)算法占用空间大,召回率高,索引时间长,搜索时间短。
-
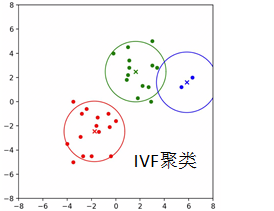
IndexIVFFlat:基于聚类的子空间搜索算法。
-
IndexLSH:局部敏感hash,基于hash的子空间搜索算法。
-
IndexPQ:类PCA的量化搜索算法。
-
IndexIVFPQ:基于积量化的子空间搜索算法。
搜索算法优化的本质都是在空间、时间和召回率上的取舍需要根据不同业务场景,召回率和性能要求使用不同算法,并在样本集上面进行参数调优。
向量检索服务设计
以常见的人脸识别服务为例,介绍分析不同的向量检索方式;
传统向量检索方案
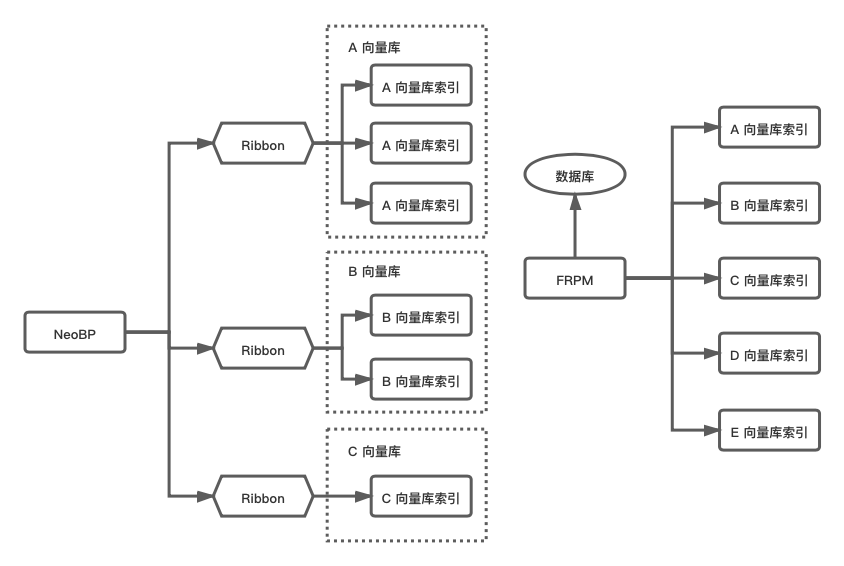
数据保存在数据库中,索引使用 Flann 构建每台服务器负责固定检索任务每个向量库仅由一台机器负责检索,若机器宕机,相关服务将无法访问Flann 搜索效率低下,浪费了大量的计算资源无法均衡负载单机内存受限无法扩展当前的向量检索系统 。 索引使用 Faiss 构建,保存在多台服务器上通过Ribbon控制搜索请求的负载均衡添加和更新文档时需要所有保存该索引的服务器同时生效,无法保证数据一致性每台机器都是全量数据还是突破不了单机内存的限制,系统重启逻辑复杂向量检索现有解决方案介绍(含竞对)。
向量检索现有解决方案介绍(含竞对)

ElasticSearch
概念介绍
-
节点:单个ES实例
-
集群:由一个或多个节点组成,他们具有相同的 cluster.name 并协同工作。集群会感知节点的加入和退出并自动处理数据同步和负载均衡
-
分片:ES分布式系统中的存储最小单位,一个分片就是一个Lucene实例,是ES的最小工作单元 分片分为主分片和副本分片,副本分片是主分片的复制和备份。副本分片可以有多个但主分片有且仅有一个
-
索引:任意个分片的集合
-
分片对用户不可见,是ES构成分布式系统的内部组件,多个分片作为一个索引与用户交互
-
希望可以使用分布式服务解决问题,保证数据和检索服务的冗余性和一致性
向量检索系统解决方案
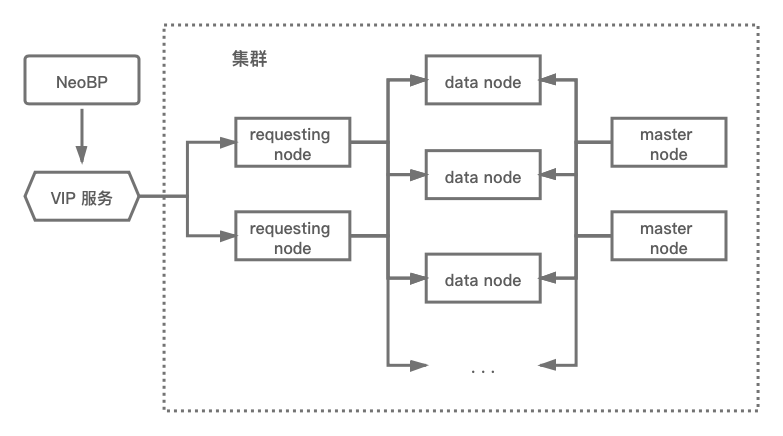
集群中共包含 Master 节点、Data 节点、Requesting 节点三种角色
-
Master 节点负责管理集群和数据的同步
-
Data 节点加载 Faiss 实例负责执行向量搜索工作
-
Requesting 节点负责接收请求并均衡 Data 节点负载
ElasticSearch 正好满足我们的分布式需求,但是原始的 ElasticSearch 不支持向量检索。
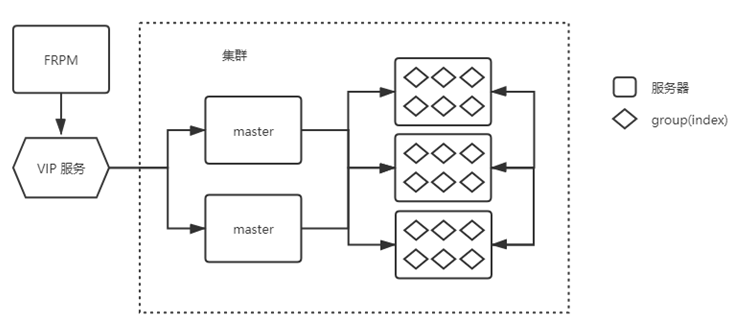
人脸搜索集群设计
-
ES充当系统中分布式数据库和分布式索引库的角色,ES负责数据的备份,保证数据的安全性。
-
ES中的最小可访问单元为index,单个index不限制存储数据量,index内部通过增加分片来保证搜索的低延时性,多分片分布式搜索的再排序过程由ES中的master节点负责,取消上层平台的group分片机制与再排序过程
-
每个index包含至少一个主分片和两倍的副本分片,数据三倍冗余
-
ES使用轮询机制处理负载均衡
-
ES负责分片的备份和同步
-
集群共8台机器,其中2台负责负载均衡、
-
同步协调等工作,6台负责搜索
-
系统保证在两台搜索机器同时宕机的情况下仍可正常提供服务
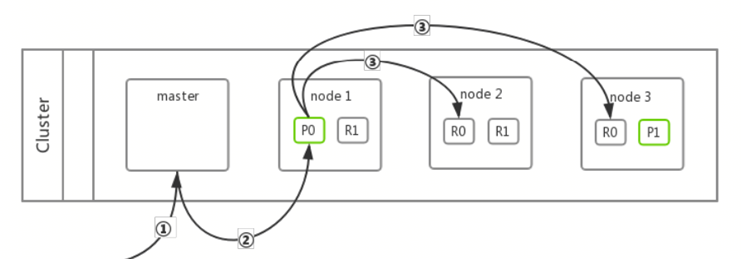
集群原理与鲁棒性--数据同步
-
master收到请求
-
master通过hash函数确定分片位置,转发请求
-
node1更新主分片并发送副本分片更新请求给node2、node3
-
增、删、改操作先在主分片上成功完成,然后复制到副本分片
-
每次更改时向副本分片的同步过程都是将整个分片完整复制
-
本质上不支持修改操作,通过删除和增加间接实现
-
本质上不支持删除操作,通过增加删除标记实现和index重建来实现
集群原理与鲁棒性--基础搜索与负载均衡
-
master收到请求
-
master通过hash函数确定主分片和副本分片位置,根据轮询机制确定执行节点,转发请求
-
node2执行检索并返回结果到master
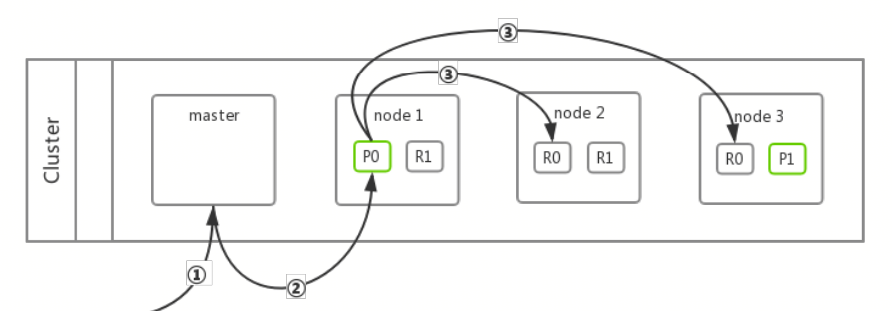
- 示意图中使用单个master节点指代集群的requesting node
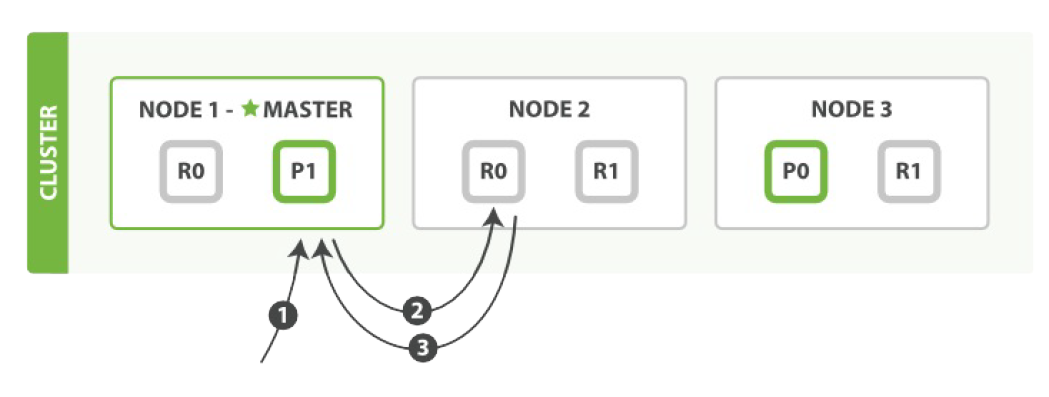
- 示意图中使用单个master节点指代集群的requesting node 集群原理与鲁棒性--分布式搜索(多分片搜索)
-
Query
-
master收到请求
-
master确定分片位置并转发请求
-
node1、node2执行搜索并返回结果到master
-
-
Fetch
-
master向node1、node2请求搜索结果中的文档原文
-
node1、node2返回文档
-
master对所有备选文档再排序后返回给客户端
-
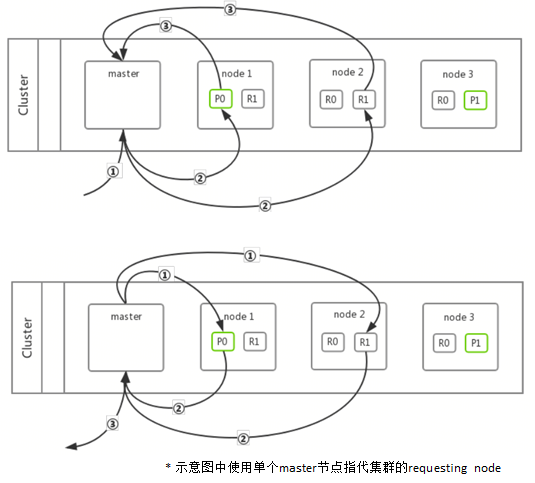
集群原理与鲁棒性--集群横向扩展
-
如果请求量增大或数据量增加,可以对集群进行横向扩展。向集群中增加 Worker 类型节点,新增节点设置与原集群相同的 cluster.name。
-
集群会自动发现新节点并向其分配分片以均衡负载。
集群原理与鲁棒性--故障处理
-
由于节点宕机或节点掉线造成访问超时视为节点退出集群。
-
集群管理节点发现异常后检查是否所有主分片都存在。
-
若发现主分片缺失将提升对应副本分片为新的主分片。

向量检索插件实现
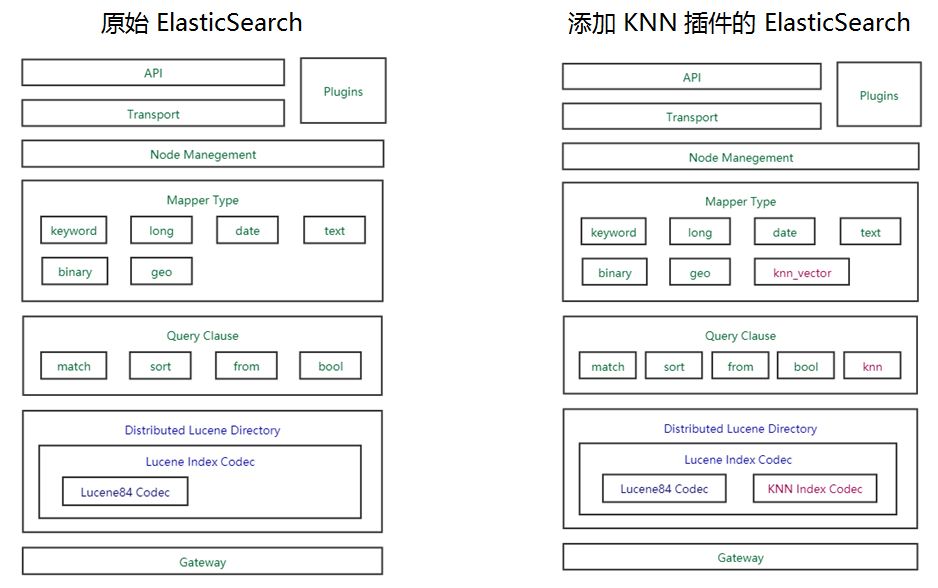
Lucene 层次实现 -- 利用 codec 扩展机制
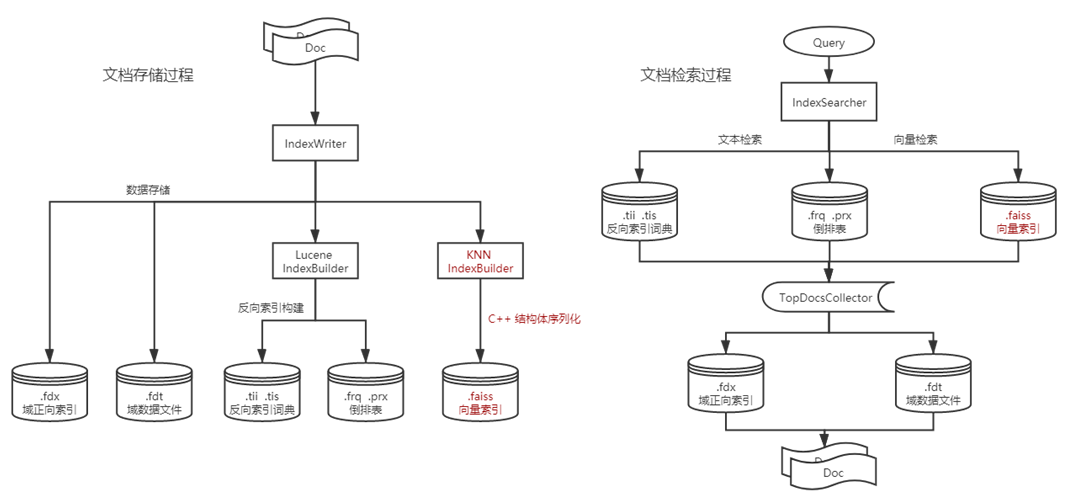
集成 KNN 插件后的向量检索逻辑流程
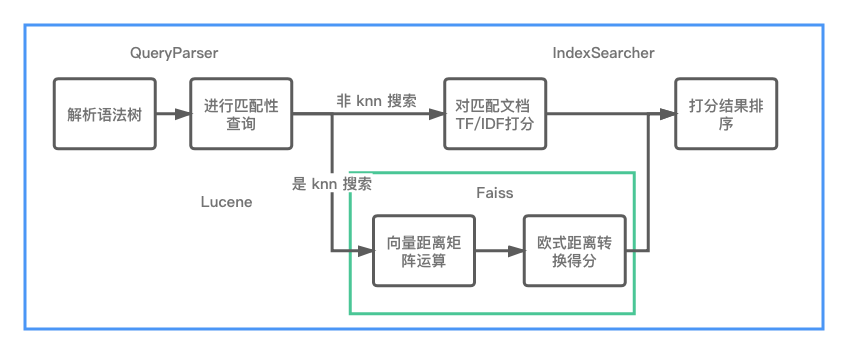
向ES添加插件
-
ES具有扩展插件的功能,在ES的 org.elasticsearch.plugins.Plugin 包中,定义了常用的一些插件的基类和接口。
-
ES支持API Extension Plugins ,即API扩展插件,通过这个扩展可以实现自定义的搜索功能
-
public class KNNPlugin extends Plugin implements MapperPlugin, SearchPlugin, ActionPlugin
-
为了添加自定义数据类型和搜索方法,继承Plugin 类并使用java语言实现相关接口:public class KNNPlugin extends Plugin implements MapperPlugin, SearchPlugin, ActionPlugin
-
将编译好的插件jar包放置在ES的plugin目录下,重启ES即可自动加载插件 扩展Lucene功能
ES的搜索功能实际上是Lucene实现的
-
Lucene可以通过扩展codec来提供对自定义检索和自定义存储的支持。
-
常见的高性能搜索框架都是使用C/C++实现的,使用Java语言继承Lucene的codec基类并实现相关功能,涉及到索引的部分通过Jni调用C++搜索库来实现。
具体实现方法:
-
继承org.apache.lucene.search.IndexSearcher、org.apache.lucene.search.Query、 org.apache.lucene.search.ScoreMode、org.apache.lucene.search.Weight、org.apache.lucene.codecs.Codec等类并实现对应方法来扩展Lucene的codec。
-
通过Jni调用C++完成具体索引的构建和使用。
ElasticSearch 层次实现 -- 利用 ElasticSearch Plugin 机制
为了在ElasticSearch中添加 KNN 插件的入口,我们定义了 knn_vector 这种 mapper type(数据类型) 和 knn 这种 query clause(查询子句)

KNN 插件兼容性测试
KNN 插件完美兼容 ElasticSearch 及 Lucene,可与 Lucene 内置的各种检索方法自由组合

生产部署与监控
生产部署:
目前,基于ES向量检索系统生产部署使用自运维方式,需要手动将ES安装包和插件拷到机器上面,然后进行配置。
监控:
prometheus(普罗米修斯) 和grafana可视化看板,需要在机器上面安装ES的探针
如何提升性能?
-
合理设置分片数量
-
尽量使用过滤器
-
过滤器经常用在查询分类结果上。它可以用查询子句限制来替换,区别在于使用Query将影响文档的得分,而Filter不会
-
预热
-
提前进行搜索
-
段合并
-
索引中拥有更少的Segment,搜索速度将更快
如何估算向量检索机器内存和磁盘?
-
ES JVM大约12G到16G。
-
1千万512维向量大约占20G,两倍数据冗余需要内存乘以3。
-
faiss IVF算法,训练需要额外内存。
-
ES会保存额外倒排索引,词字典等额外索引信息,一些小文件会常驻内存。
-
对于不常用索引,会从内存中卸载。
-
磁盘占用包括:ES lucene的索引文件,faiss 向量序列化文件。
向量检索后续探索实践