IDEA中编写Maven项目
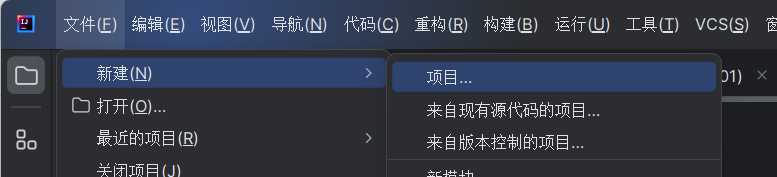
1.打开IDEA新建项目
2.选择java语言,构建系统选择Maven

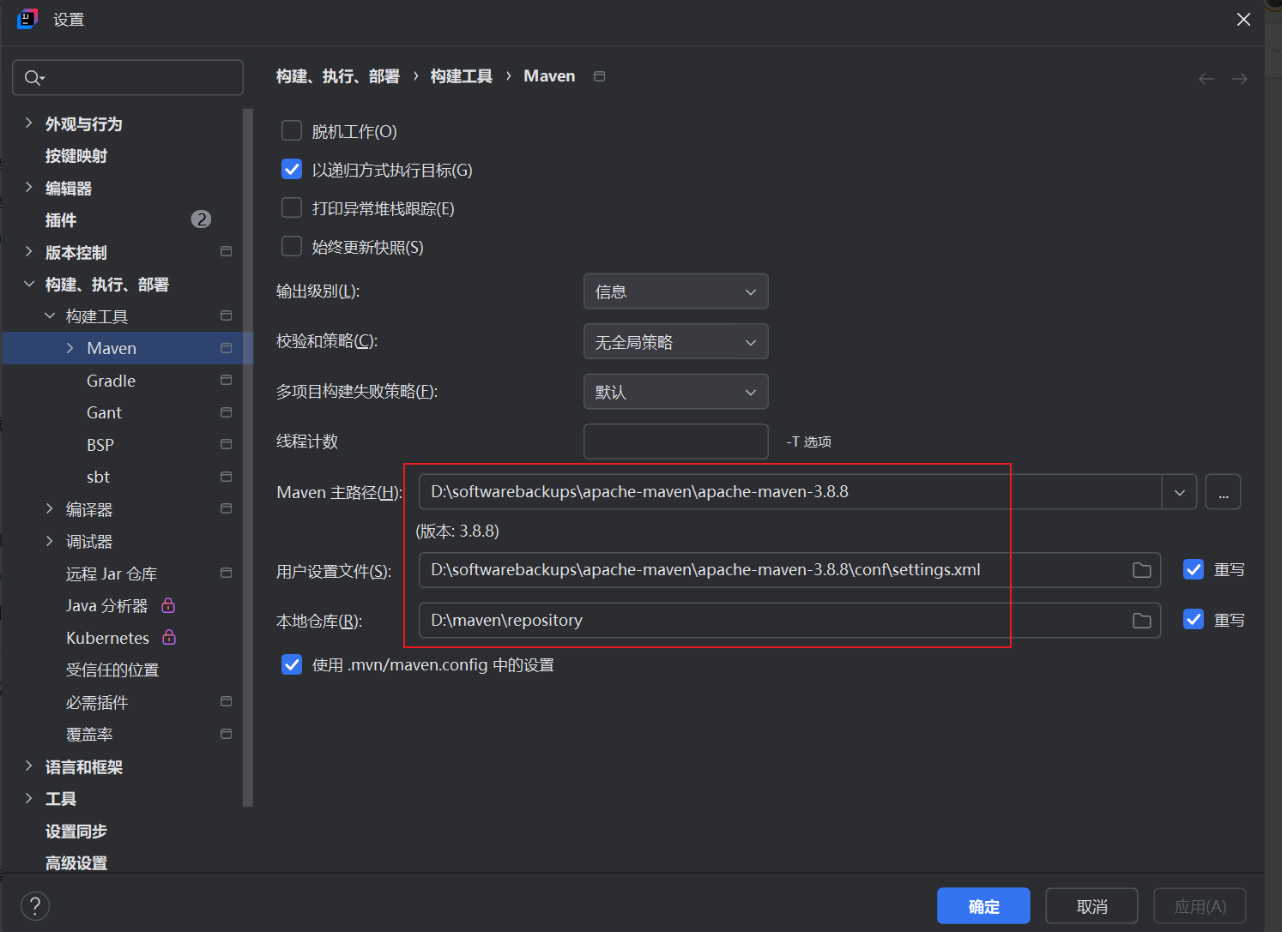
3.IDEA中配置Maven
注: 这些文件都是我们老师帮我们在网上找了改动后给我们的,大家可自行在网上查找
编写代码测试HDFS连接
1.在之前创建的pom.xml文件中添加下列代码
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency>
</dependencies>**注:**这里的dependencies要这一步中的hadoop-client要和我们前面客户端准备中下载的hadoop保持一致。
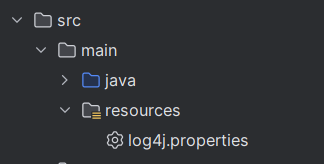
2.配置日志信息。在项目的src/main/resources目录下,新建一个文件,命名为"log4j.properties"。
在文件中填入如下配置信息:
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n3.创建包为org.example,并在下面创建Main类
编写代码如下:
package org.example;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
import java.net.URISyntaxException;
public class Main {
public static void main(String[] args) throws URISyntaxException, IOException, InterruptedException {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://hadoop100:8020"); // hadoop100是namenode所在的节点
conf.set("hadoop.job.ugi", "root");
FileSystem fs = FileSystem.get(conf);
FileStatus[] fileStatuses = fs.listStatus(new Path("/"));
// 打印文件信息
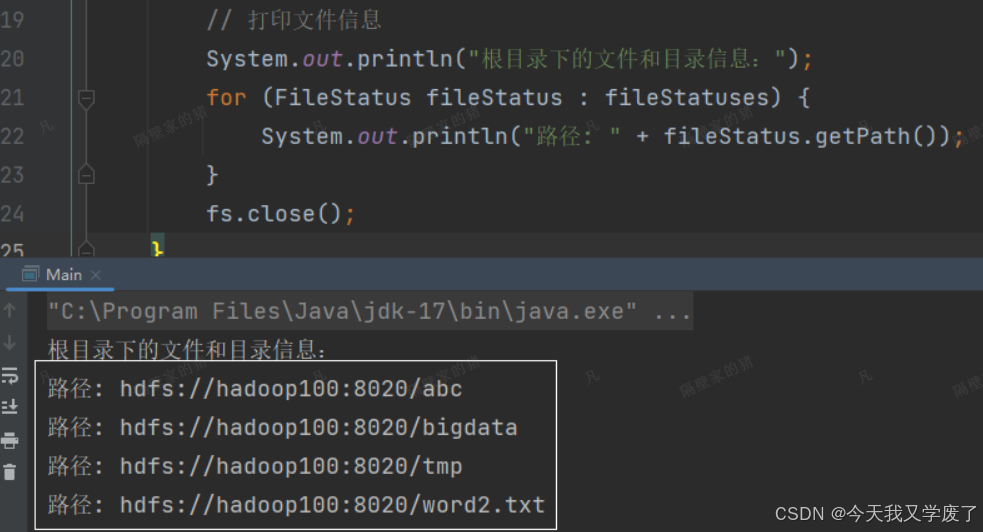
System.out.println("根目录下的文件和目录信息:");
for (FileStatus fileStatus : fileStatuses) {
System.out.println("路径: " + fileStatus.getPath());
}
fs.close();
}
}4.运行
如果程序执行没有错误,就会打印出如下目录