一、决策树算法简介
1.1 算法介绍
决策树 是一种基于树形结构的监督学习算法,广泛应用于分类和回归任务。其核心思想是通过对数据特征的逐步划分,构建一棵树结构来模拟决策过程。树中的节点包括:
根节点:起始特征,代表最佳分割属性
内部节点:中间决策点,对应其他特征
叶节点:最终决策结果(类别或数值)
边:节点之间的连接,表示特征或属性的可能取值
路径:从根节点到叶节点的一条路径,表示一系列决策
1.2 构建过程
1.选择最佳特征
- 计算每个特征的信息增益、信息增益比或基尼指数
- 选择能够最大程度地减少数据集不纯度的特征
2.划分数据集
- 根据选择的特征和特征值将数据集划分为子集
- 每个特征值对应一个分支,每个分支代表一个可能的特征值
3.创建分支
- 对于每个特征值,创建一个分支,并将数据集分配给相应的分支
4.递归构建子树
- 对每个分支的数据子集,重复步骤1-3,直到满足停止条件
5.停止条件
- 所有样本都属于同一类别
- 没有剩余的特征可以用于进一步划分
- 达到预设的最大深度
- 子集中的样本数小于某个阈值
6.生成叶子节点
- 当满足停止条件时,为该节点创建一个叶子节点
- 叶子节点通常包含该子集中最常见的类别(对于分类树)或样本的平均值(对于回归树)
7.剪枝(可选)
- 为了防止过拟合,可以对生成的决策树进行剪枝
- 剪枝可以是预剪枝(在树生长过程中控制树的复杂度)或后剪枝(在树完全生长后剪去部分枝节)
8.验证和调整
- 使用验证集评估决策树的性能
- 根据需要调整模型参数,如特征选择标准、树的深度、最小样本分裂数等
1.3 特征选择方法
1.信息增益
信息增益是最常用的特征选择方法之一,它基于信息论中的熵概念。信息增益衡量的是通过某个特征分割数据集后,数据集的不确定性减少的程度
- 信息熵:衡量数据集的不确定性或混乱程度
其中,pk 是第 k 类样本在数据集 D 中的比例。
- 信息增益
其中,是特征A取值为v的子集。
2.信息增益比
信息增益比是信息增益的改进,它通过除以分裂信息来调整信息增益,从而避免偏向于选择取值较多的特征
- 分裂信息
- 信息增益比
3.基尼指数
基尼指数衡量数据集的不纯度,值越小表示数据集越纯。CART算法通常使用基尼指数作为特征选择的依据
- 基尼指数
- 基尼指数增益
4.卡方检验
卡方检验用于检验分类变量之间的独立性。在决策树中,它可以用来评估特征与目标变量之间的相关性
5.特征重要性
特征重要性是一种基于模型的特征选择方法,它根据特征对模型预测能力的贡献来评估特征的重要性。这种方法常用于基于树的集成方法,如随机森林和梯度提升树
二、决策树的分类方法
2.1 ID3算法
1.ID3算法的核心是使用信息增益来选择特征,构建决策树
2.信息增益计算公式
信息增益(D,A)=信息熵(D)−条件熵(D∣A)
3.实现步骤
(1)计算信息熵 :
信息熵(D)=
其中
是第 k 类样本在数据集 D 中的比例。
(2)计算条件熵:条件熵(D∣A)=
其中
(3)选择信息增益最大的特征,并递归构建决策树。
2.2 C4.5算法
1.C4.5算法是ID3的改进版本,主要改进是使用信息增益比来选择特征,以避免偏向于选择取值较多的特征
2.信息增益比计算公式
信息增益比(D,A) = 信息增益(D,A) / 分裂信息(D,A)
3.分裂信息计算公式
分裂信息(D,A) =
4.实现步骤
(1)计算信息增益比,选择信息增益比最大的特征
(2)递归构建决策树
2.3 CART算法
1.CART算法是一种流行的决策树算法,既可以用于分类(CART分类树)也可以用于回归(CART回归树)
2.特征选择
CART算法使用基尼指数来选择特征。基尼指数衡量数据集的不纯度,计算公式为:
其中,是第k类样本在数据集D中的比例
3.递归建立决策树
CART算法递归地构建决策树,直到满足停止条件(如子集中样本数小于预设阈值、达到预设的最大深度等)
4.剪枝
为了防止过拟合,CART算法通常采用剪枝技术。剪枝分为预剪枝(在树生长过程中控制树的复杂度)和后剪枝(在树完全生长后剪去部分枝节)
三、分类方法代码实现
3.1 数据转换
在实验中,需要对数据先进行将 dataset.txt 和 testset.txt 中的数值数据转换为适合决策树处理的格式,而数据表.xlsx中的数据可以直接用于分析,但需要将其转换为数值形式。
1.dataset.txt 和 testset.txt 中的每一行代表一个样本,每一列代表一个特征或标签
2.数据表.xlsx 中的特征需要转换为数值形式,例如:
- 年龄段:青年=0,中年=1,老年=2
- 有工作:否=0,是=1
- 有自己的房子:否=0,是=1
- 信贷情况:一般=0,好=1,非常好=2
- 类别(是否给贷款):否=0,是=1
3.2 数据加载函数
python
import math
# 数据加载函数
def load_data(file_path):
"""加载数据集"""
data = []
with open(file_path, 'r') as file:
for line in file:
row = list(map(int, line.strip().split(',')))
data.append(row)
return data3.3 计算信息熵、信息增益、分裂信息和信息增益比
python
# 计算信息熵
def calculate_entropy(data):
"""计算数据集的信息熵"""
label_counts = {}
for row in data:
label = row[-1]
if label not in label_counts:
label_counts[label] = 0
label_counts[label] += 1
entropy = 0.0
total_samples = len(data)
for count in label_counts.values():
probability = count / total_samples
entropy -= probability * math.log2(probability)
return entropy
# 计算信息增益
def calculate_information_gain(data, feature_index):
"""计算特征的信息增益"""
total_entropy = calculate_entropy(data)
feature_values = set(row[feature_index] for row in data)
weighted_entropy = 0.0
for value in feature_values:
subset = [row for row in data if row[feature_index] == value]
subset_entropy = calculate_entropy(subset)
weighted_entropy += (len(subset) / len(data)) * subset_entropy
information_gain = total_entropy - weighted_entropy
return information_gain
# 计算分裂信息
def calculate_split_info(data, feature_index):
"""计算分裂信息"""
feature_values = set(row[feature_index] for row in data)
split_info = 0.0
for value in feature_values:
subset = [row for row in data if row[feature_index] == value]
probability = len(subset) / len(data)
split_info -= probability * math.log2(probability)
return split_info
# 计算信息增益比
def calculate_information_gain_ratio(data, feature_index):
"""计算信息增益比"""
information_gain = calculate_information_gain(data, feature_index)
split_info = calculate_split_info(data, feature_index)
if split_info == 0:
return 0
return information_gain / split_info3.4 构建ID3决策树
python
# 构建ID3决策树
def build_id3_tree(data):
"""构建ID3决策树"""
if len(set(row[-1] for row in data)) == 1:
return data[0][-1] # 如果所有样本属于同一类别,返回该类别
best_feature = max(range(len(data[0]) - 1), key=lambda i: calculate_information_gain(data, i))
tree = {best_feature: {}}
for value in set(row[best_feature] for row in data):
subset = [row for row in data if row[best_feature] == value]
tree[best_feature][value] = build_id3_tree(subset)
return tree3.5 构建C4.5决策树
python
# 构建C4.5决策树
def build_c45_tree(data):
"""构建C4.5决策树"""
if len(set(row[-1] for row in data)) == 1:
return data[0][-1] # 如果所有样本属于同一类别,返回该类别
best_feature = max(range(len(data[0]) - 1), key=lambda i: calculate_information_gain_ratio(data, i))
tree = {best_feature: {}}
for value in set(row[best_feature] for row in data):
subset = [row for row in data if row[best_feature] == value]
tree[best_feature][value] = build_c45_tree(subset)
return tree3.6 预测函数并计算精度
python
# 预测函数
def predict(tree, sample):
if not isinstance(tree, dict):
return tree
feature_index = list(tree.keys())[0]
feature_value = sample[feature_index]
if feature_value in tree[feature_index]:
return predict(tree[feature_index][feature_value], sample)
else:
return None
# 精确度计算函数
def calculate_accuracy(predictions, actuals):
"""计算精确度"""
correct = sum(1 for pred, actual in zip(predictions, actuals) if pred == actual)
return correct / len(actuals)3.7 主程序
python
if __name__ == "__main__":
dataset_path = r"C:\Users\林欣奕\Desktop\dataset.txt"
testset_path = r"C:\Users\林欣奕\Desktop\testset.txt"
# 加载数据
train_data = load_data(dataset_path)
test_data = load_data(testset_path)
# 训练ID3模型
id3_tree = build_id3_tree(train_data)
id3_predictions = [predict(id3_tree, sample) for sample in test_data]
id3_actuals = [sample[-1] for sample in test_data]
id3_accuracy = calculate_accuracy(id3_predictions, id3_actuals)
# 训练C4.5模型
c45_tree = build_c45_tree(train_data)
c45_predictions = [predict(c45_tree, sample) for sample in test_data]
c45_actuals = [sample[-1] for sample in test_data]
c45_accuracy = calculate_accuracy(c45_predictions, c45_actuals)
# 输出测试结果
print("ID3模型的测试结果:")
print(f"测试结果实际值: {id3_actuals}")
print(f"模型预测值: {id3_predictions}")
print(f"精确度: {id3_accuracy}")
print("\nC4.5模型的测试结果:")
print(f"测试结果实际值: {c45_actuals}")
print(f"模型预测值: {c45_predictions}")
print(f"精确度: {c45_accuracy}")四、代码效果展示
4.1 截图展示
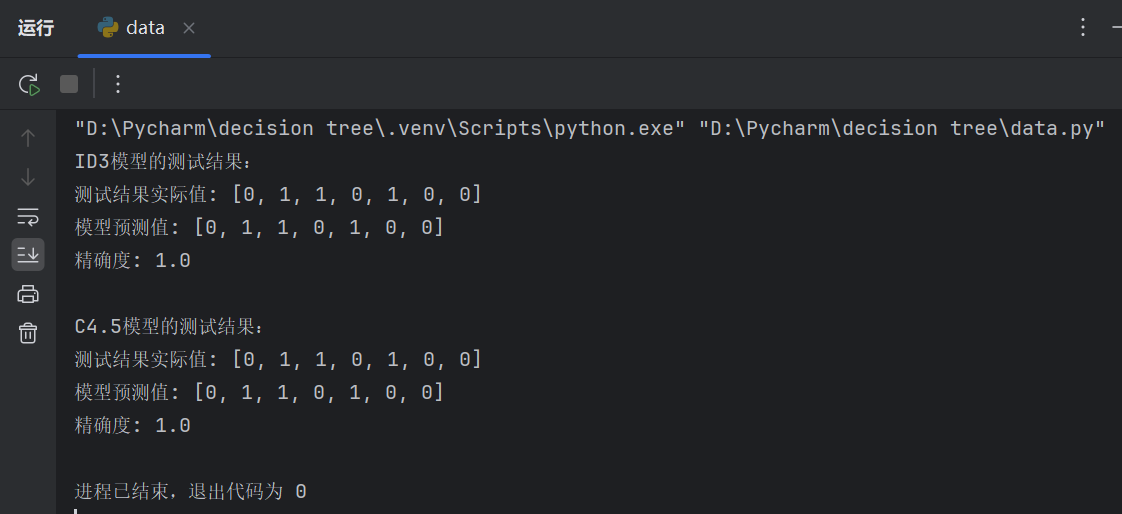
4.2 测试结果分析
依据上图的程序运行截图,对ID3模型和C4.5模型的测试结果进行分析,可得
1.精确度 :在实验中,所选取的两个模型最后的计算精确度均为1.0,这意味着模型对所有测试样本的预测都是正确的。这是一个非常理想的结果,表明模型在当前测试集上的表现非常优秀。
2.预测值与实际值对比 :从预测值与实际值的对比来看,无论是ID3模型还是C4.5模型,它们的预测结果与实际结果完全一致。这表明在这次测试中,两个模型都能够准确地对数据进行分类。
3.模型性能 :由于ID3和C4.5模型在这次测试中表现相同,这可能意味着在当前数据集上,两个模型的性能相当。然而,这并不意味着在所有情况下两个模型都会表现相同。C4.5通常在处理连续值和缺失值时表现更好,而ID3则更简单,易于理解和实现。
4.过拟合风险:虽然在这次测试中模型表现完美,但在实际应用中,需要警惕过拟合的风险。过拟合是指模型在训练数据上表现很好,但在未见过的数据上表现不佳。为了防止过拟合,可以考虑使用交叉验证、剪枝等技术。