内置函数一般要用select调用
内置函数
日期函数
current_date函数
current_date函数用于获取当前的日期。如下:
current_time函数
current_time函数用于获取当前的时间。如下:
current_timestamp函数
获取时间戳,会给我们转化成日期+时间的格式显示
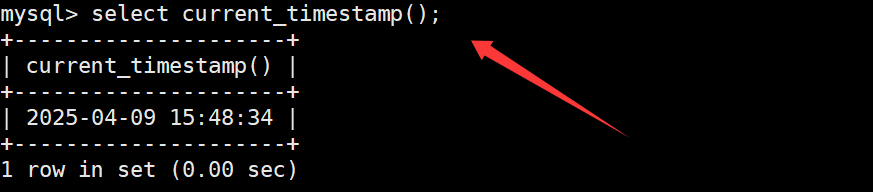
now函数
now函数用于获取当前的日期时间。如下:
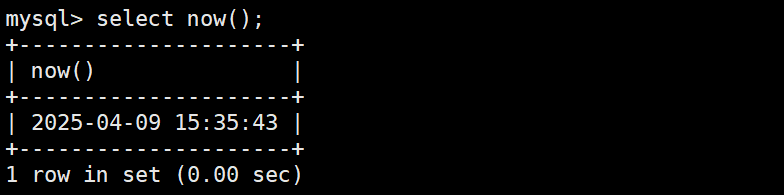
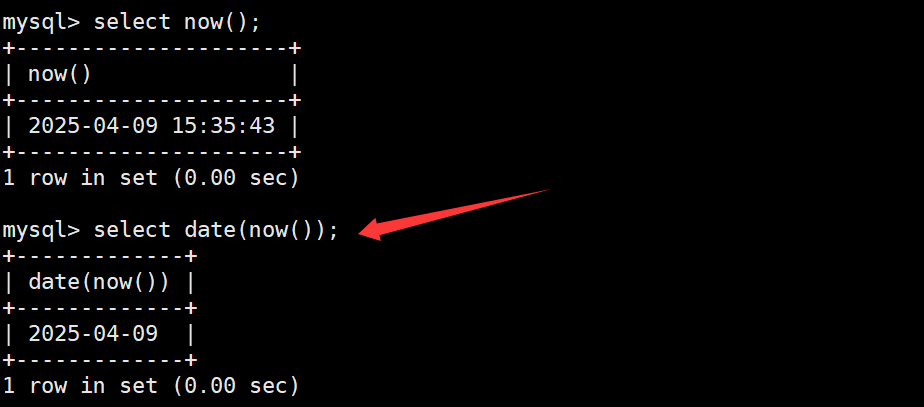
date函数
date函数用于获取当前的日期时间。如下:
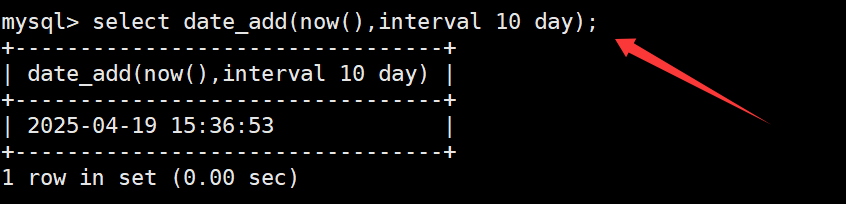
date_add函数
date_add函数用于在日期的基础上添加日期或时间。如下:
如果在date_add函数中添加的日期/时间为负值,则相当于在日期的基础上减去日期/时间。如下:
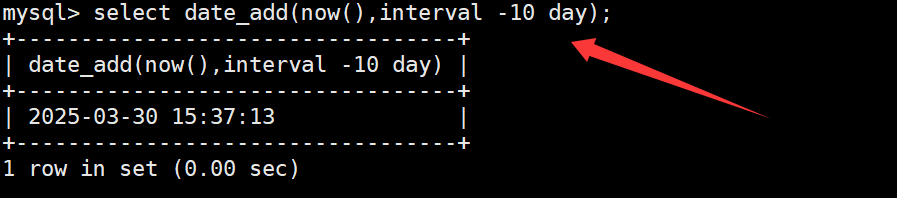
date_sub函数
date_sub函数用于在日期的基础上减去日期或时间。如下:
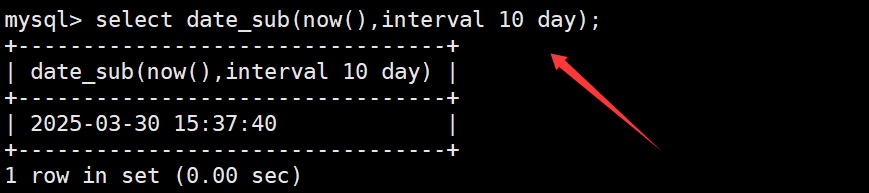
如果在date_sub函数中减去的日期/时间为负值,则相当于在日期的基础上添加日期/时间。如下:
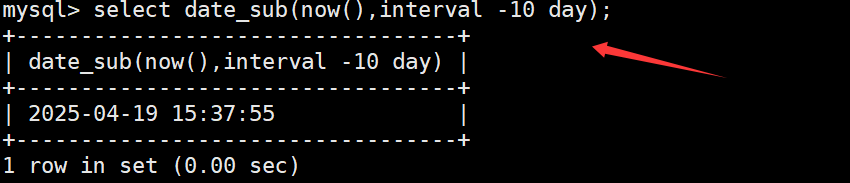
datediff函数
datediff函数用于获取两个日期的差,单位是天。如下:
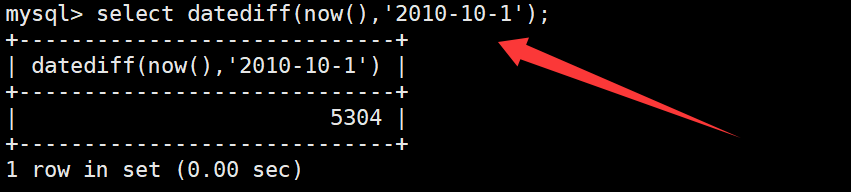
综合案例
创建一个评论表,表中包含自增长的主键id、昵称、评论内容和评论时间。如下:
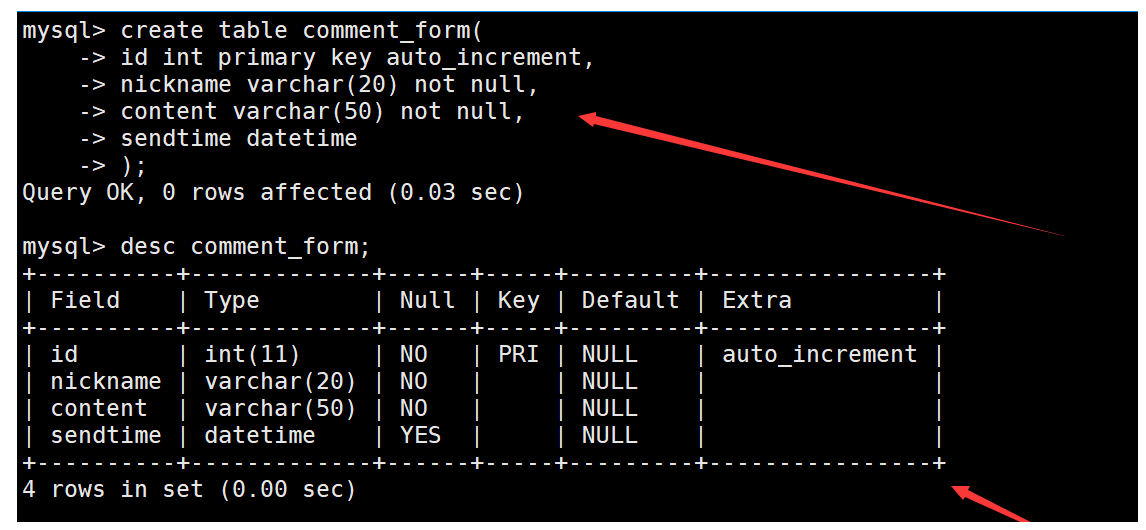
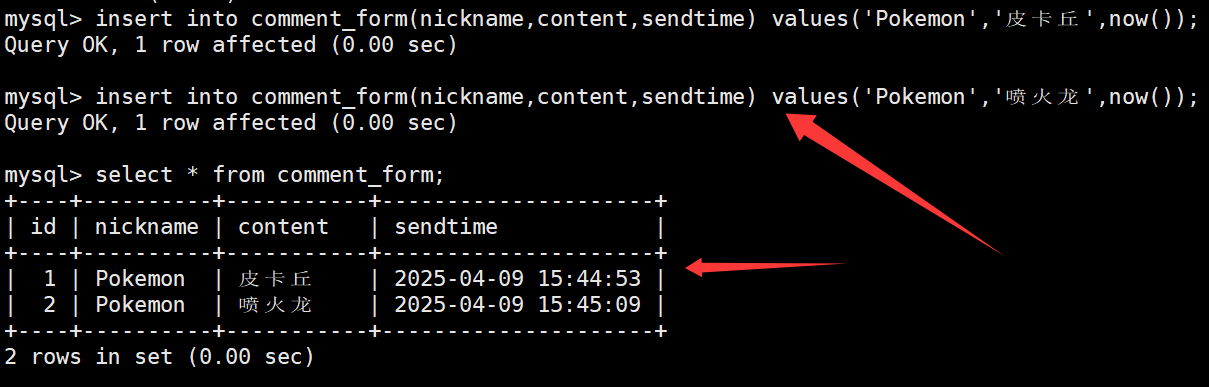
向表中插入一些数据,插入时直接通过now函数指明评论时间。如下:
在显示评论信息时,如果只想显示评论的日期而不显示评论的时间,可以在查询sendtime字段时,通过date函数截取sendtime的日期部分进行显示。如下:

再不定时向表中插入一些数据。如下:
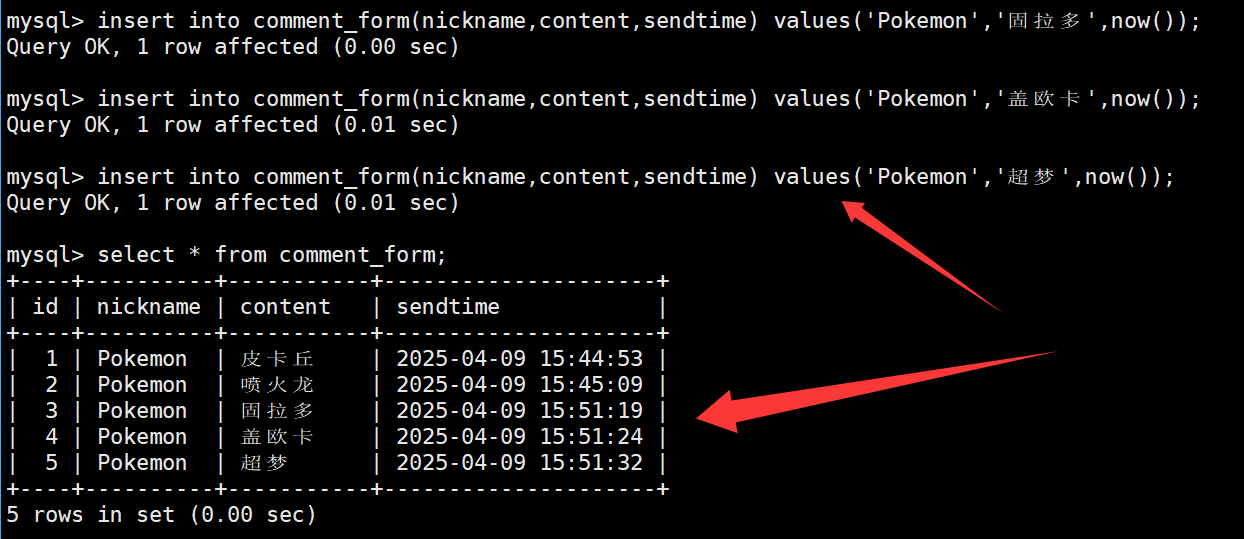
怎么才能在显示评论信息时,查询2分钟内发布的评论信息?
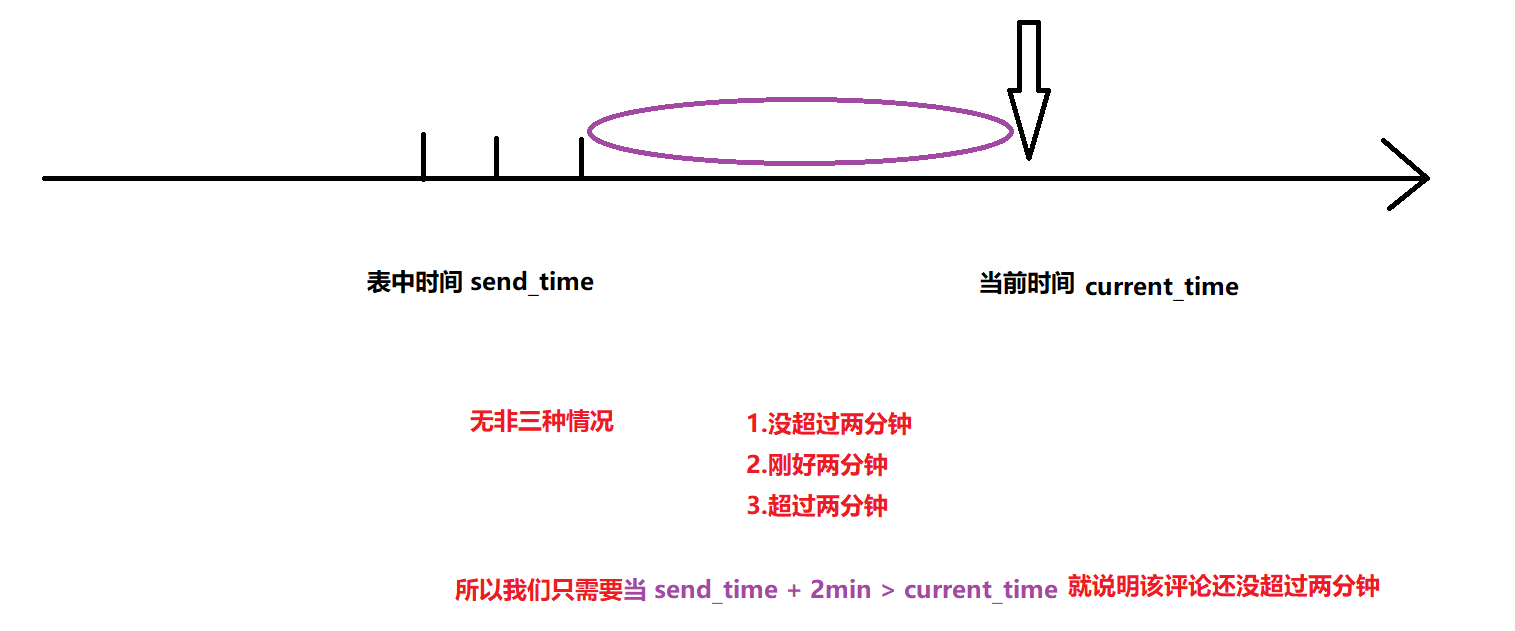
实际就是要筛选出评论时间加上2分钟后大于当前时间的评论,这时需要同时借助date_add和now函数。如下:
sql
select * from msg where date_add(sendtime, interval 2 minute) > now();
字符串函数
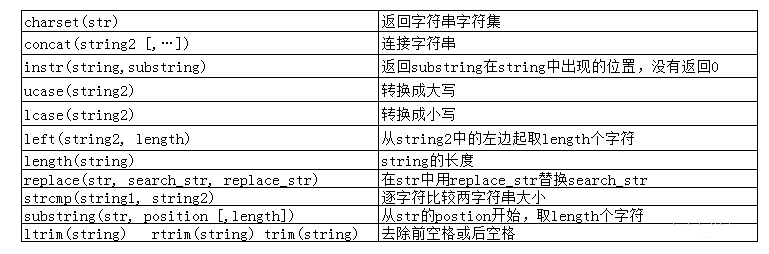
charset函数
现有如下员工表,要求获取员工表中ename列使用的字符集。如下:
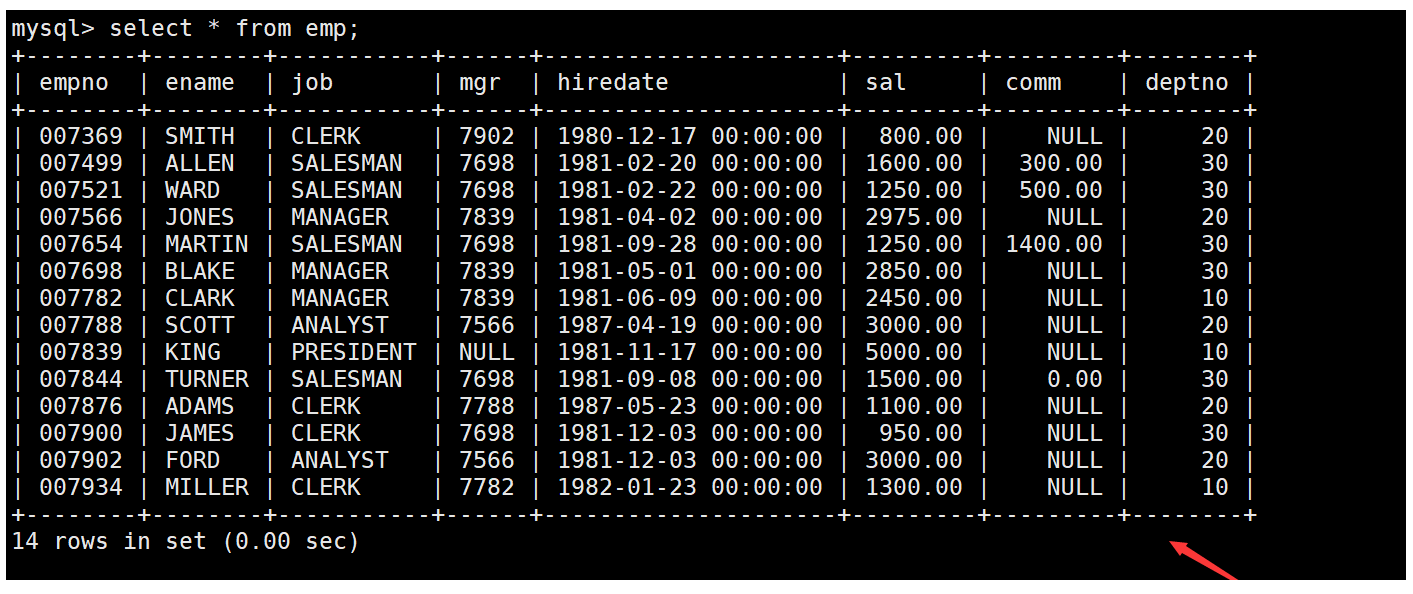
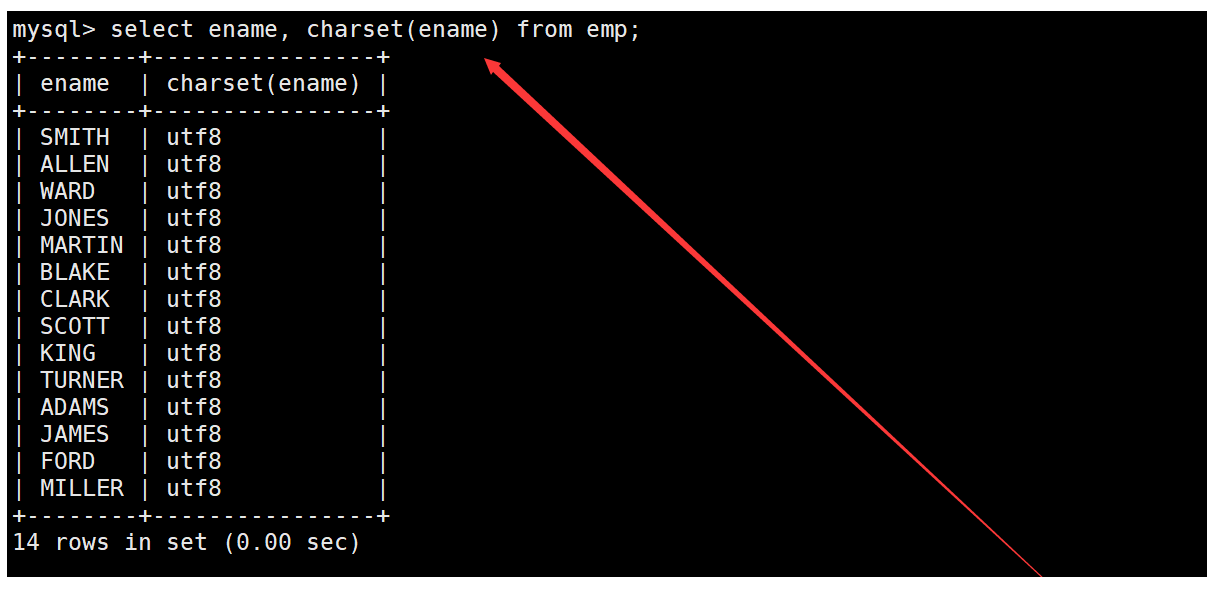
在查询员工表中的信息时,使用charset函数获取ename列使用的字符集即可。如下:
concat函数
现有如下成绩表,要求以"XXX的语文是XX分,数学是XX分,英语是XX分"的格式显示成绩表中的信息。如下:
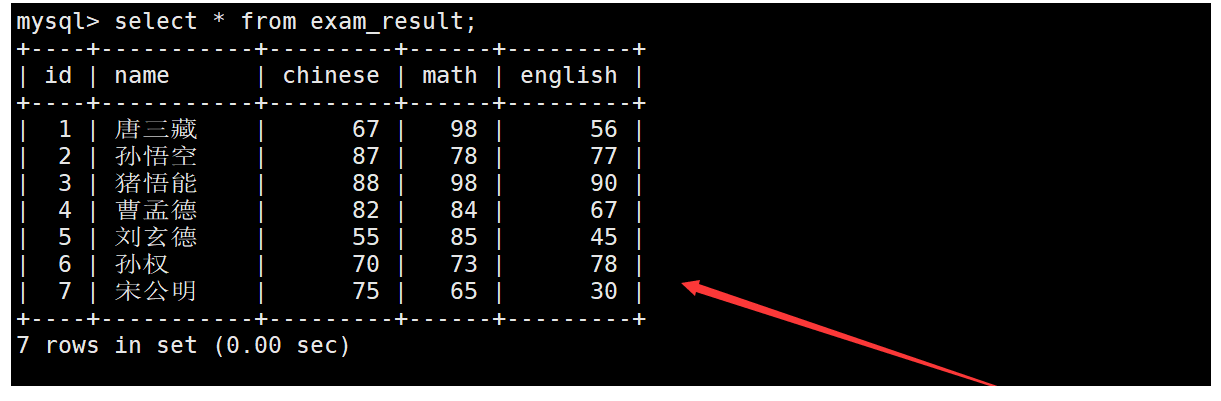
在查询成绩表中的信息时,使用concat函数按要求进行字符串连接即可。如下:

instr函数
instr函数用于获取一个字符串在另一个字符串中首次出现的位置,如果没有出现则返回0。如下:
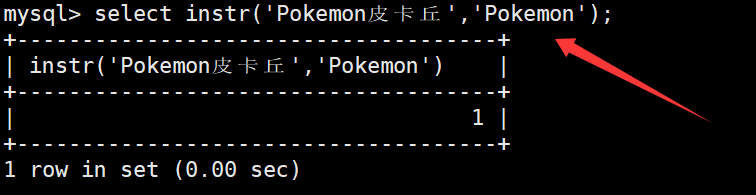
未找到的情况
ucase函数
ucase函数用于获取转换成大写后的字符串。如下:

lcase函数
lcase函数用于获取转换成小写后的字符串。如下:

left函数
left函数用于从字符串的左边开始,向后截取指定个数的字符。如下:

right函数
right函数用于从字符串的右边开始,向后截取指定个数的字符。如下:

length函数
length函数用于获取字符串占用的字节数。如下:
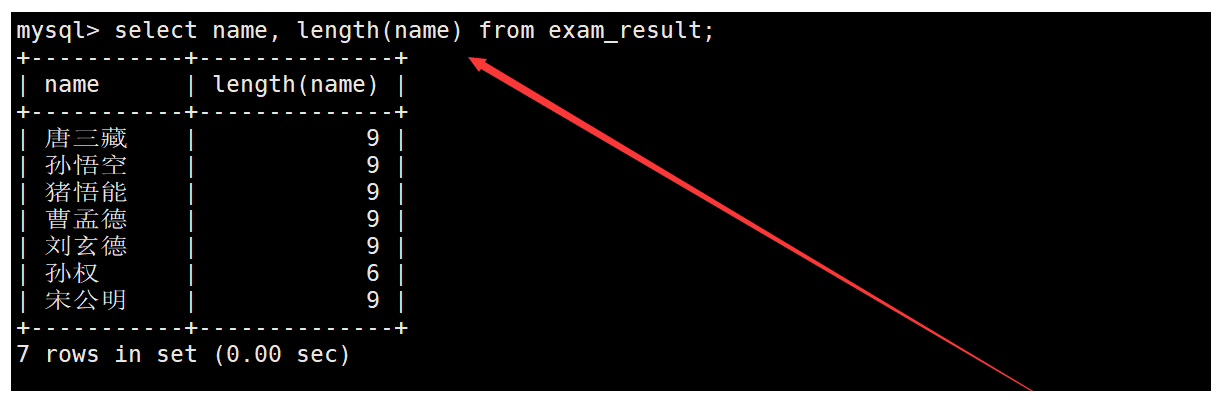
**注意:**length函数返回字符串长度,以字节为单位。如果是多字节字符则计算多个字节数;如果是单字 节字符则算作一个字节。比如:字母,数组算作一个字节,中文表示多个字节数(与字符集编码有关)
replace函数
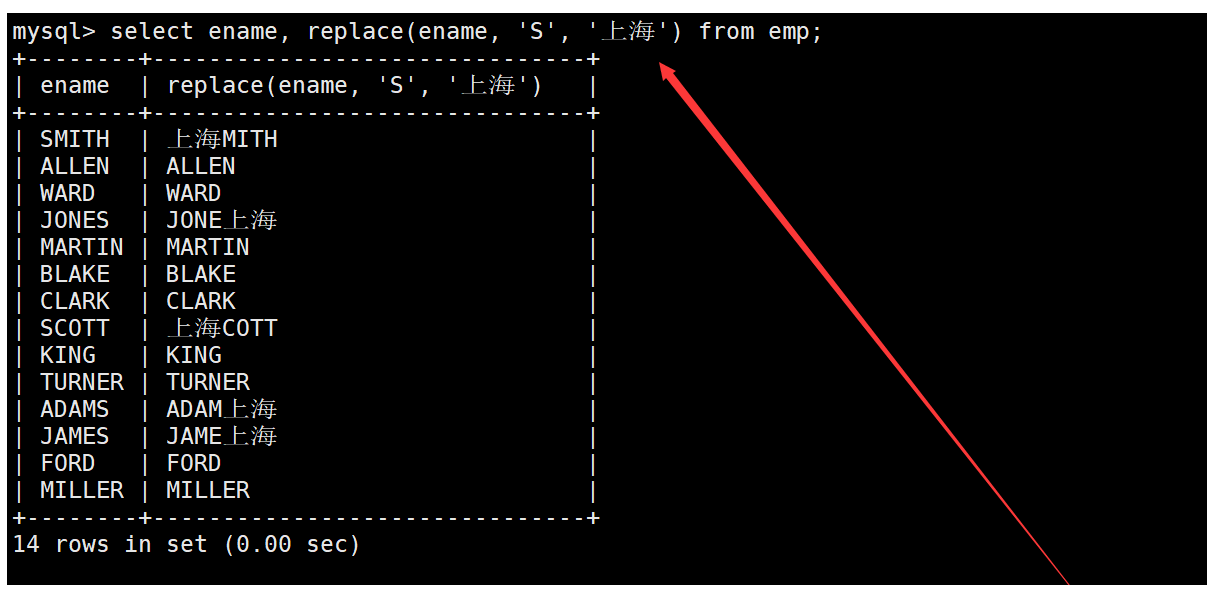
replace函数用于将字符串中的指定子字符串替换成另一个字符串,例如将员工表中所有名字中的"S"替换成"上海"。如下:
strcmp函数
strcmp函数用于逐字符按照ASCII码比较两个字符串的大小,两个字符串大小相等返回0,前者大返回1,后者大返回-1。如下:
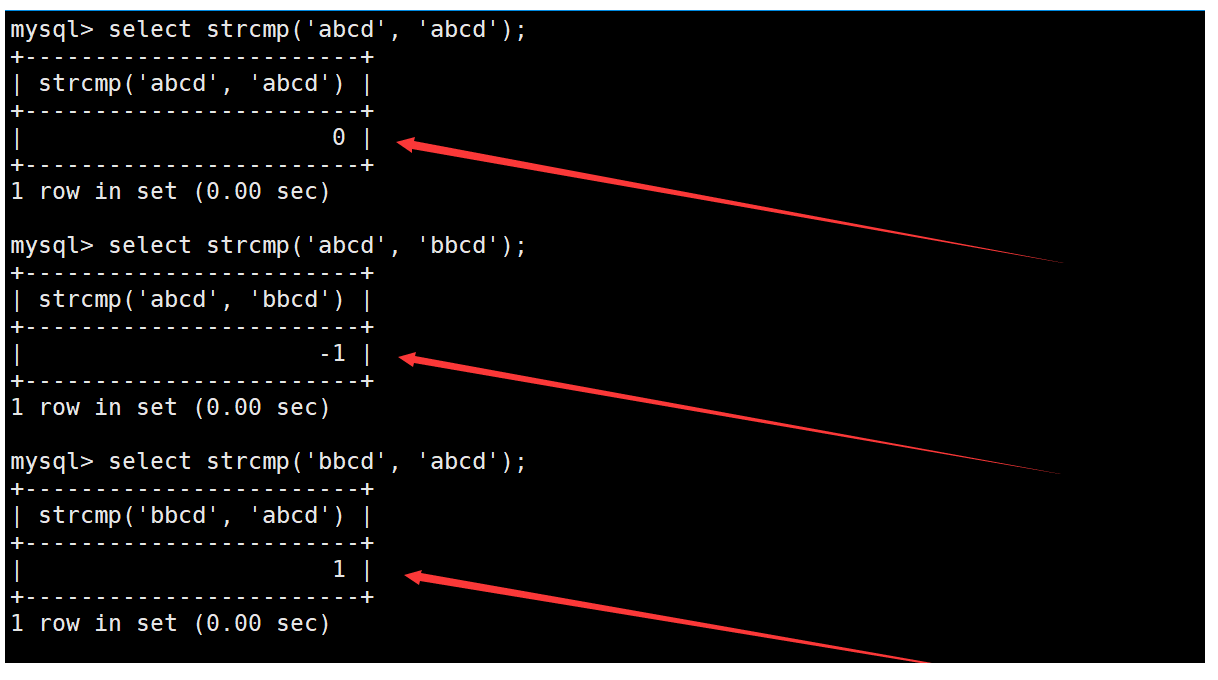
需要注意的是,strcmp函数在比较时是不区分大小写的。如下:

substring函数
substring函数用于从字符串的指定位置开始,向后截取指定个数的字符。如下:
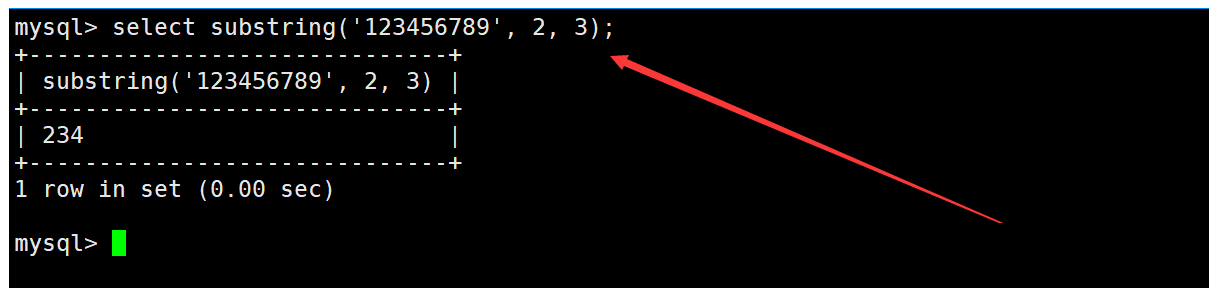
使用substring函数时,如果没有指定要截取的字符个数,则默认从指定位置开始截取到最后。如下:

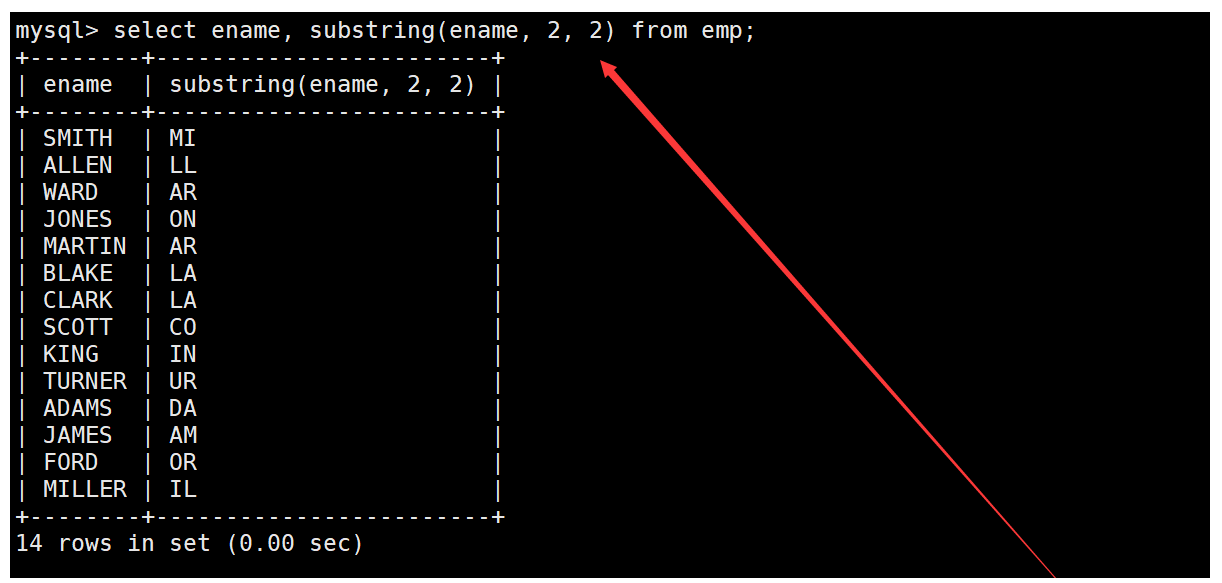
例如截取员工表中ename字段的第二个到第三个字符。如下:
ltrim、rtrim和trim函数
trim函数用于去除字符串的前后空格。ltrim和rtrim函数分别用于去除字符串的前空格和后空格。如下:

数学函数
其他函数
复合查询(重点)
基本查询
对同一张表做笛卡尔积
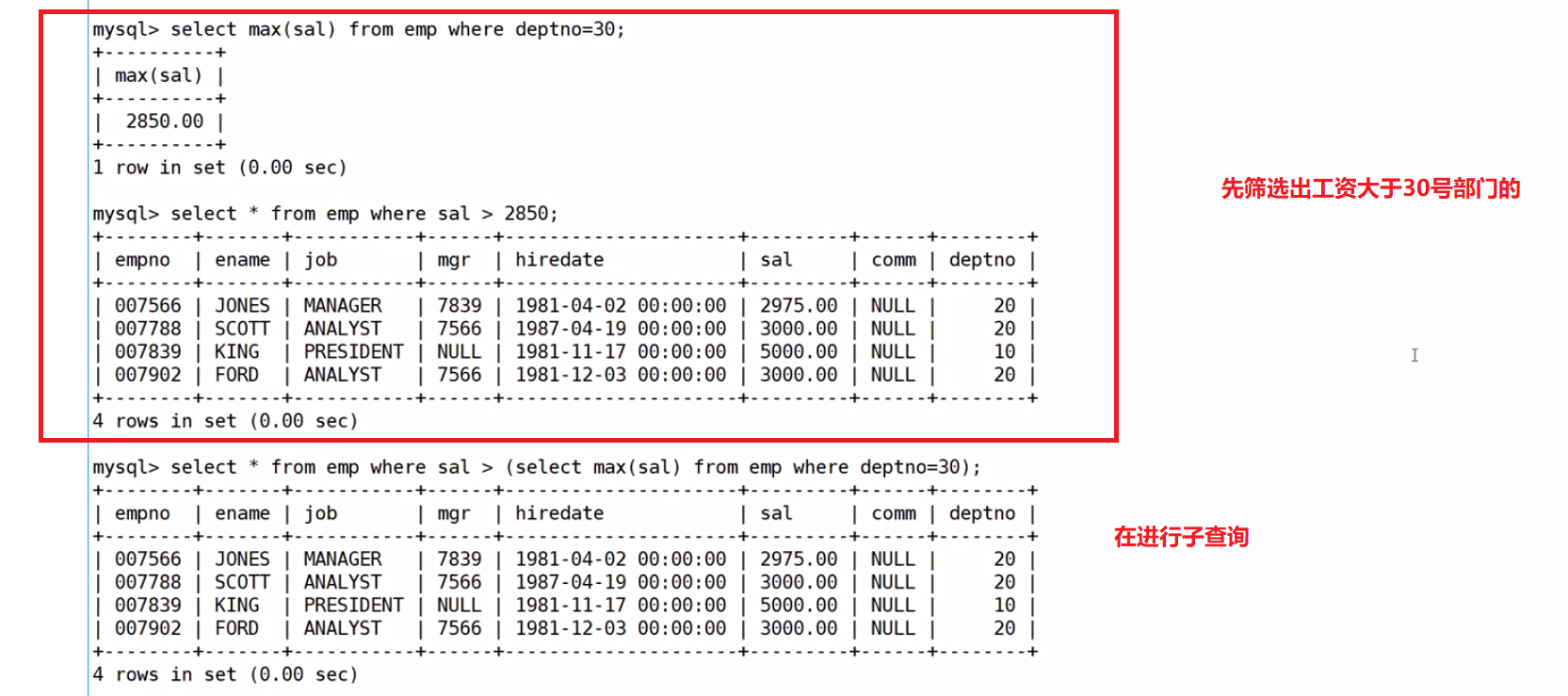
all关键字;显示工资比部门30的所有员工的工资高的员工的姓名、工资和部门号
先用基本的方法写
多列子查询
单行子查询是指子查询只返回单列,单行数据;多行子查询是指返回单列多行数据,都是针对单列而言的,而多列子 查询则是指查询返回多个列数据的子查询语句
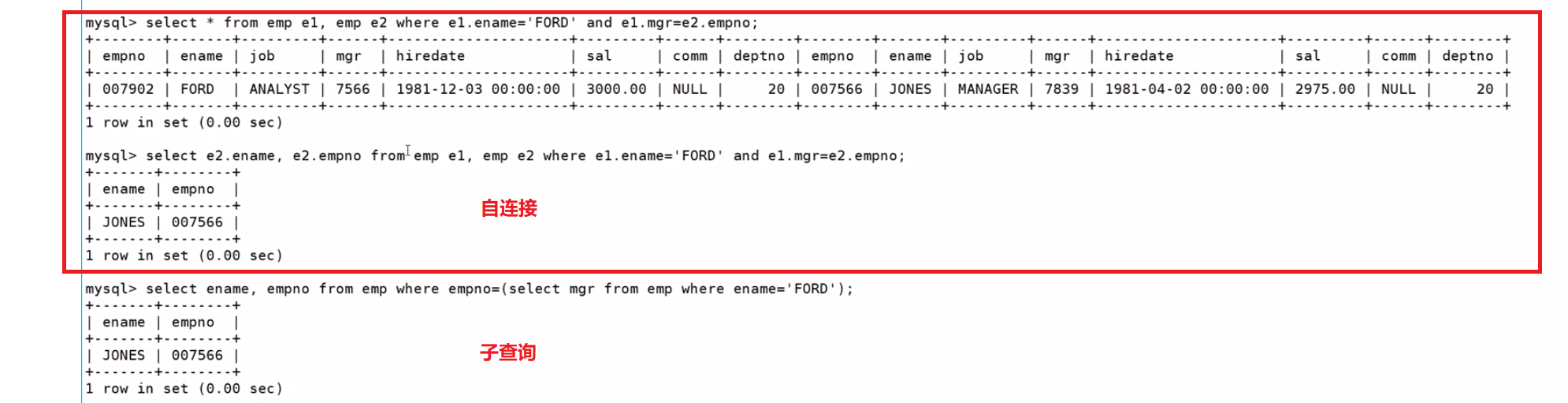
查询和SMITH的部门和岗位完全相同的所有雇员,不含SMITH本人
查询思路:先查询SMITH属于哪个部门的,然后再用多列子查询,查询出来和SMITH的部门和岗位完全相同的所有雇员,最后再排除SMITH本人
sql
mysql> select ename from EMP where (deptno, job)=
(select deptno, job from EMP where ename='SMITH') and ename <> 'SMITH';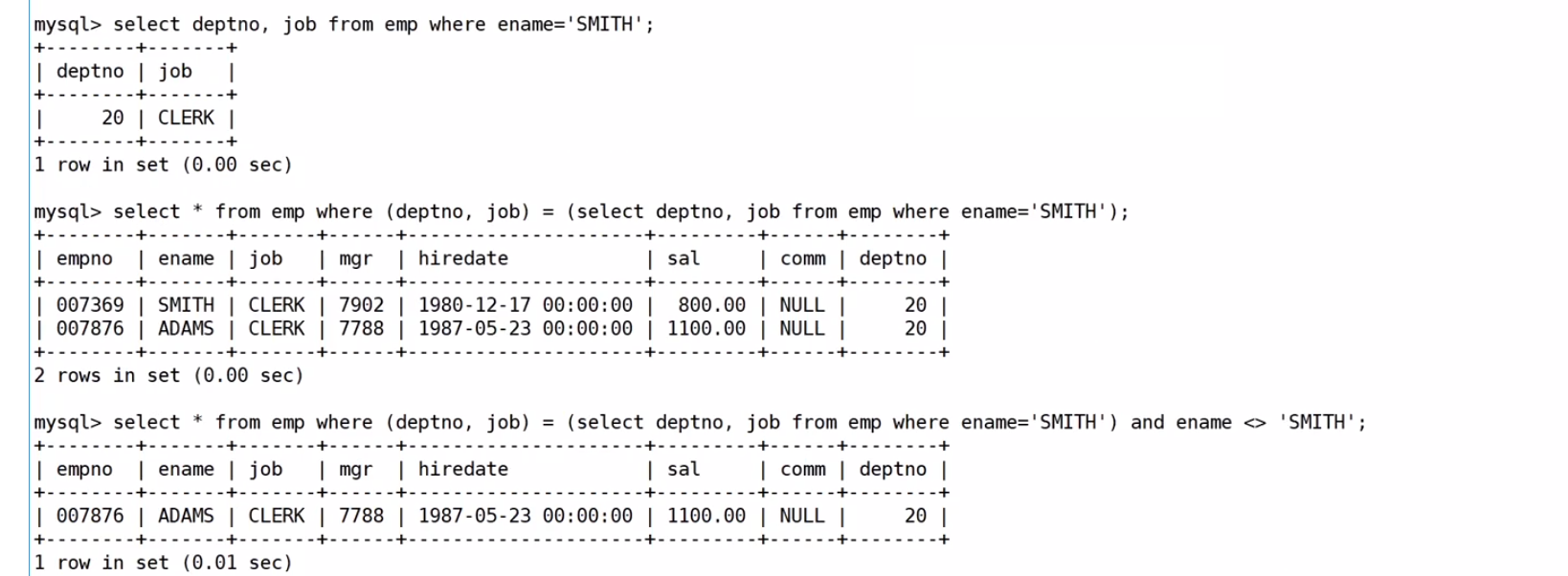 也可以用in 把 和SMITH的部门和岗位完全相同的所有雇员看成一对
也可以用in 把 和SMITH的部门和岗位完全相同的所有雇员看成一对
 总结: 目前全部的子查询,全部都在where子句中,充当判断条件。任何时刻,查询出来的临时结构,本质在逻辑上也是表结构。MySQL中一切皆表
总结: 目前全部的子查询,全部都在where子句中,充当判断条件。任何时刻,查询出来的临时结构,本质在逻辑上也是表结构。MySQL中一切皆表
在from子句中使用子查询
显示每个高于自己部门平均工资的员工的姓名、部门、工资、平均工资
思路过程: 第一步:先查找所有部门的平均薪资,然后再分组查找每个部门的平均薪资,最后再把每个部门的平均薪资的结果充当个临时表,搭配from。注意要起别名
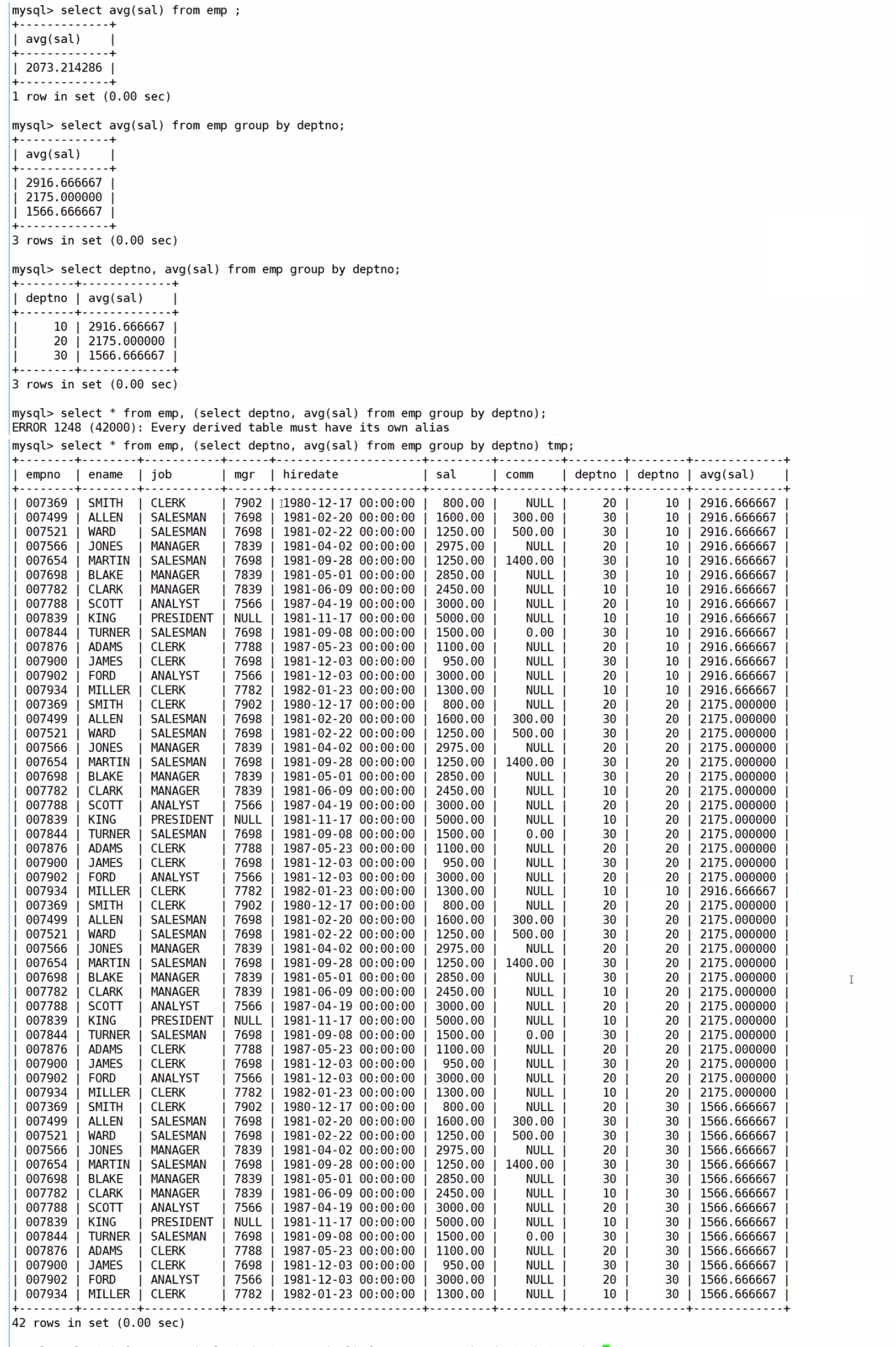
第二步:有些数据是没意义的,就好比SMITH是20号部门的,你给她个10号部门的平均薪资,是没有意义的,所以我们要用笛卡尔积给去除掉
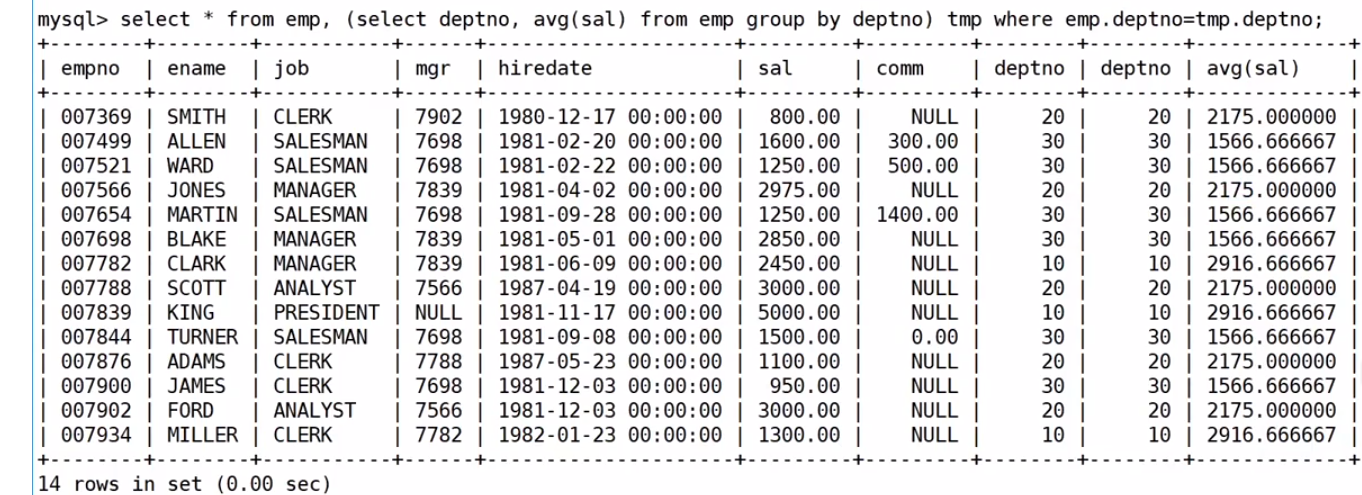 最后在进行筛选大于平均工资的
最后在进行筛选大于平均工资的

附加条件:顺便显示在哪个地方工作
部门的工作地点是在dept中,所以是先用笛卡尔积,我们上面按照需要筛选出来的员工跟部门表进行合并,起个别名为t1

然后去掉无效信息

再按照所要求的信息。需要符合要求的员工名称,部门地点,部门

查找每个部门工资最高的人的姓名、工资、部门、最高工资
sql
select EMP.ename, EMP.sal, EMP.deptno, ms from EMP,
(select max(sal) ms, deptno from EMP group by deptno) tmp
where EMP.deptno=tmp.deptno and EMP.sal=tmp.ms;肯定是先聚合,先把每个部门工资的薪资先找到

把这个结果作为临时表与emp表进行笛卡尔积组合
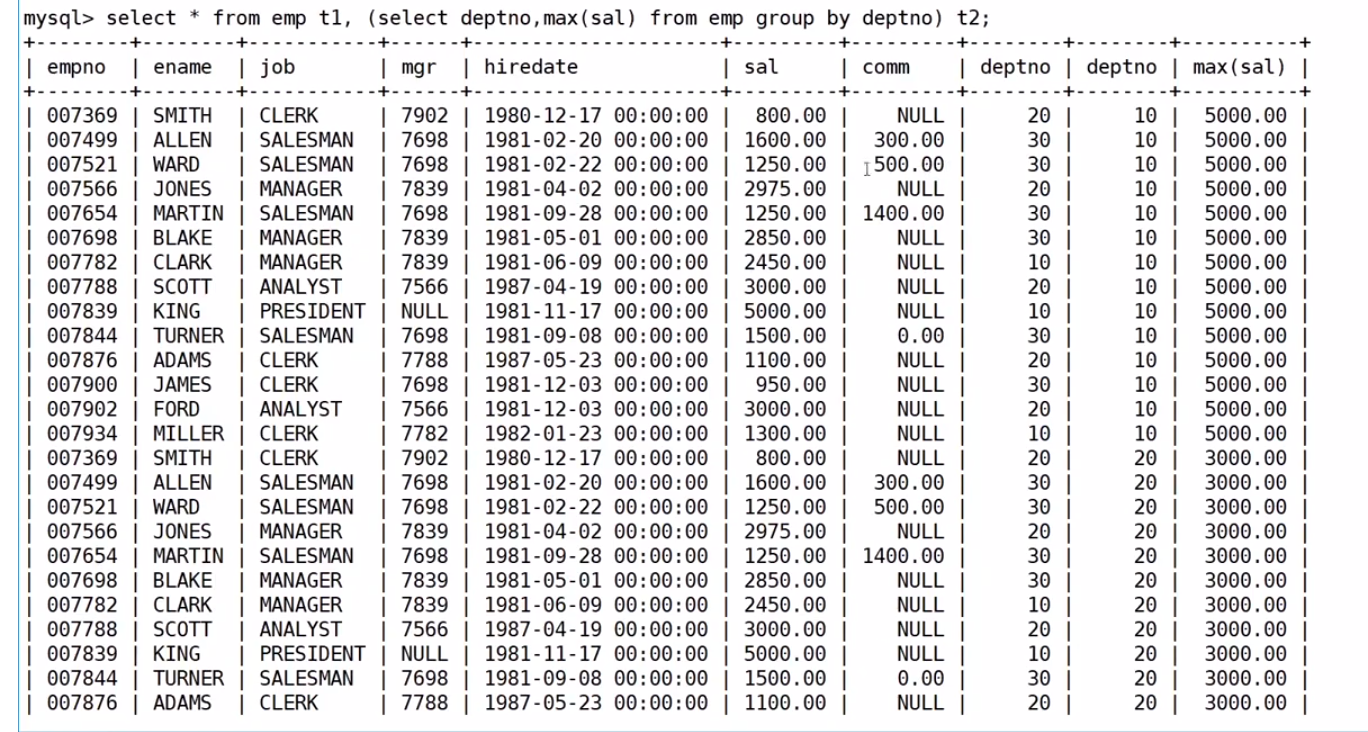
然后进行筛选去掉无效信息
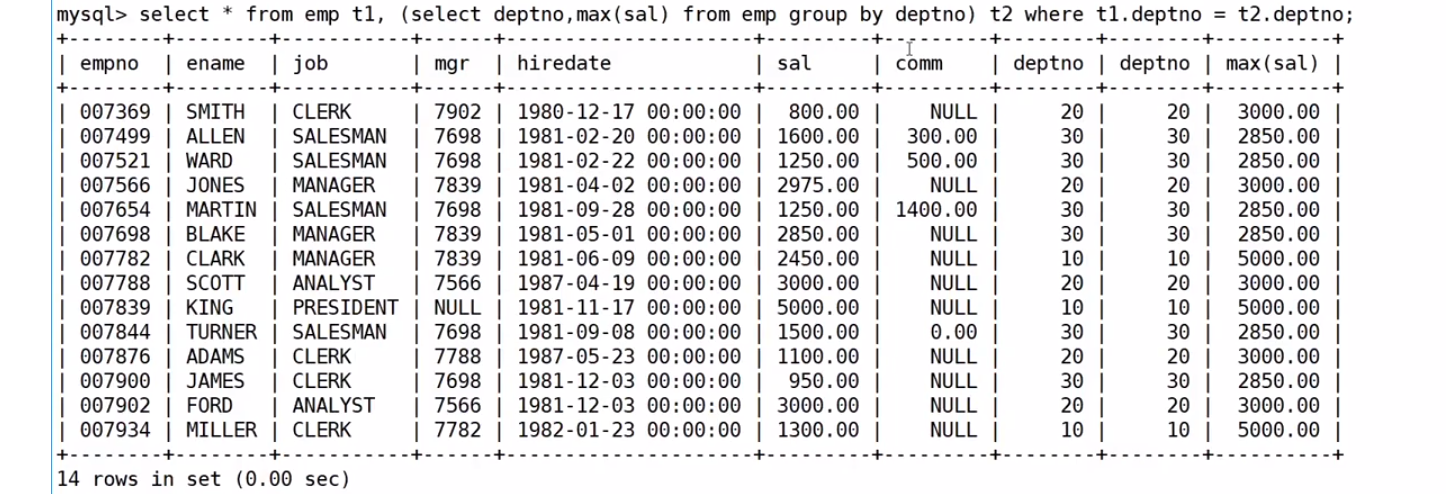
最后按照要求
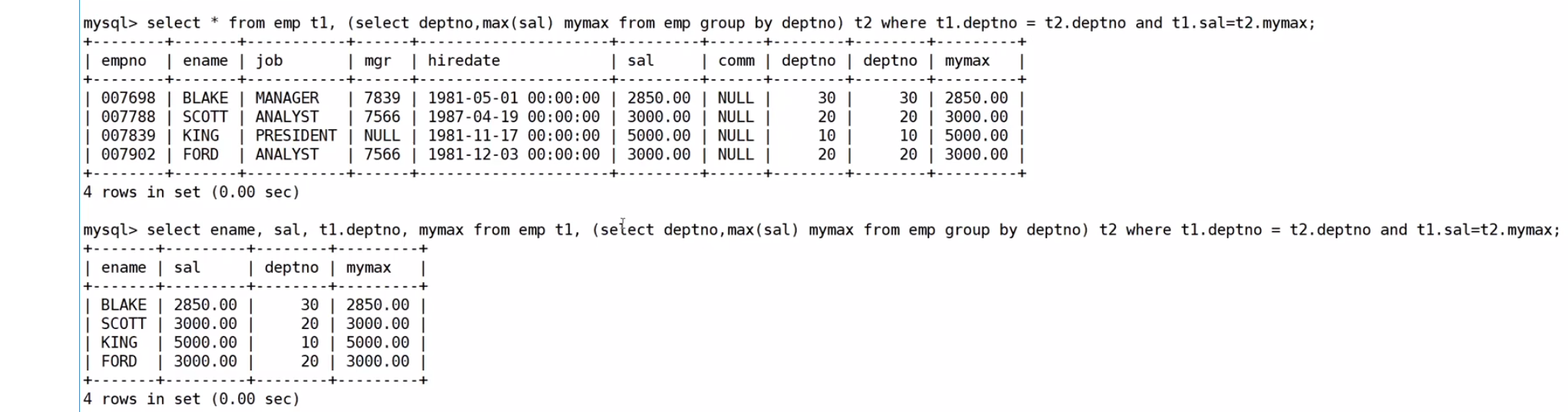
显示每个部门的信息(部门名,编号,地址)和人员数量
方法1:使用多表(不推荐,因为为了要照顾group by语法结构,还需要对多个数据进行分组)
sql
select DEPT.dname, DEPT.deptno, DEPT.loc,count(*) '部门人数' from EMP, DEPT
where EMP.deptno=DEPT.deptno
group by DEPT.deptno,DEPT.dname,DEPT.loc;过程:先统计每个部门有多少人,然后按照部门分组
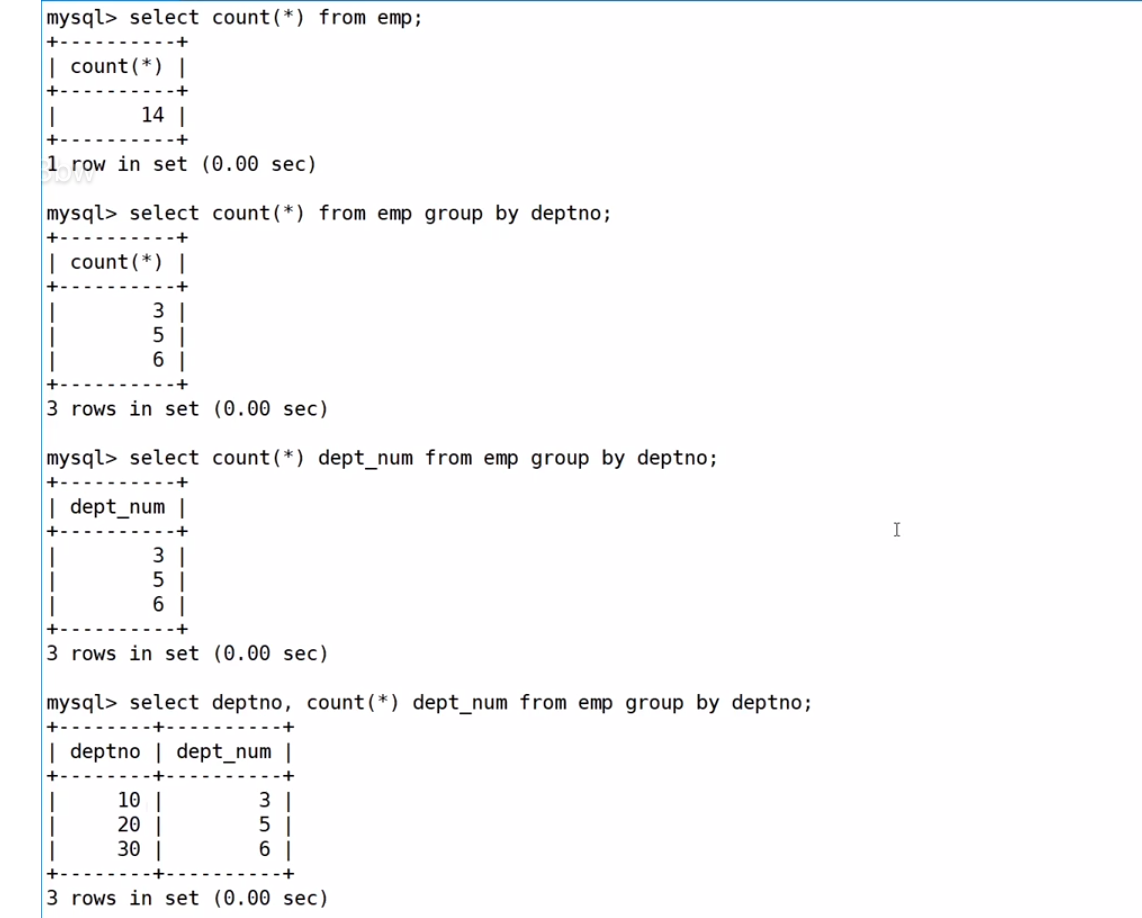
然后进行笛卡尔积,把两个表放在一起,去除无效信息
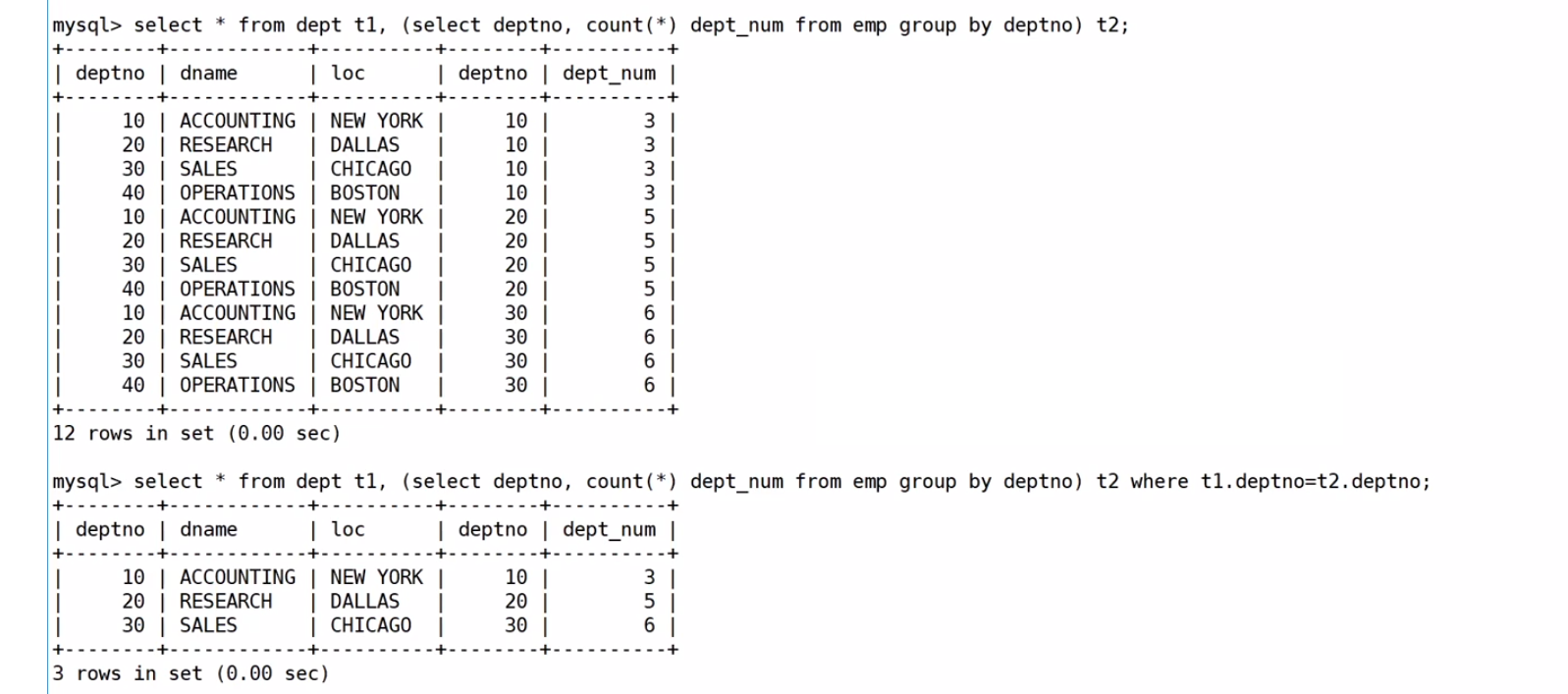
最后再按照要求

方法2:使用子查询
先进行分组计算每个部门的人数,然后进行聚合

最后再按照要求

解决多表问题的本质:想办法将多表转换成单表,所以mysql中,所有select的问题全部都可以转换成单表问题(多表查询的指导思想)
合并查询(用得不多)
在实际应用中,为了合并多个select的执行结果,可以使用集合操作符 union,union all
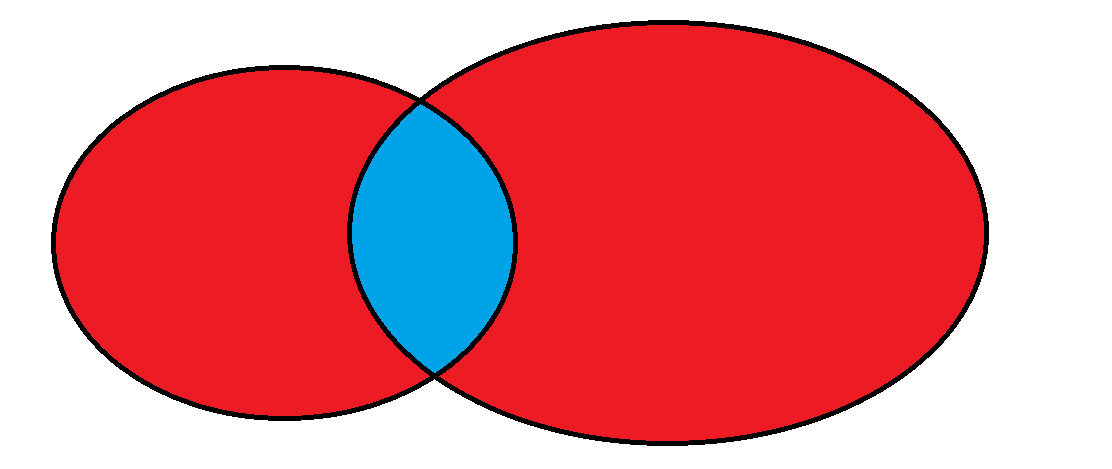
union
该操作符用于取得两个结果集的并集。当使用该操作符时,会自动去掉结果集中的重复行。
将工资大于2500或职位是MANAGER的人找出来
sql
mysql> select ename, sal, job from EMP where sal>2500 union
-> select ename, sal, job from EMP where job='MANAGER';//去掉了重复记录步骤如下,union会帮你去重

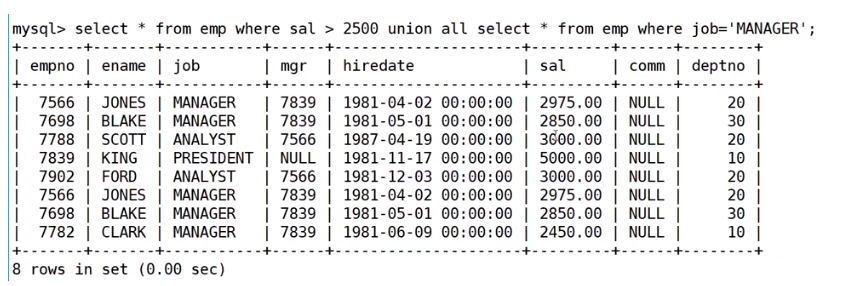
union all
该操作符用于取得两个结果集的并集。当使用该操作符时,不会去掉结果集中的重复行。
案例:将工资大于25000或职位是MANAGER的人找出来
sql
mysql> select ename, sal, job from EMP where sal>2500 union all
-> select ename, sal, job from EMP where job='MANAGER';