flink介绍
1)Apache Flink 是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink 被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算。
2)在实时计算或离线任务中,往往需要与关系型数据库交互,例如 MySQL、PostgreSQL 等。Apache Flink 提供了 JDBC Connector,可以方便地将流式数据写入或读取数据库。
3)flink版本下载:https://archive.apache.org/dist/flink/
flink单机搭建
basic
## 1. 下载并解压flink
[root@localhost flink_soft]# mkdir /data/flink_soft
[root@localhost flink_soft]# tar -zxvf flink-1.16.1-bin-scala_2.12.tgz
## 2. 修改配置文件,把下面的三行全部去掉
[root@localhost flink-1.16.1]# cd /data/flink_soft/flink-1.16.1
[root@localhost flink-1.16.1]# vim /data/flink_soft/flink-1.16.1/conf/flink-conf.yaml
rest.port: 8081
rest.address: 0.0.0.0
rest.bind-address: 0.0.0.0
## 3. 启动flink
[root@localhost flink-1.16.1]# ./bin/start-cluster.sh
## 4. 查询进程是否存在
[root@localhost flink-1.16.1]# ps aux | grep flink
## 5. 访问http://192.168.112.162:8081/ 即可。
将已经适配dameng的jar包放到lib目录下
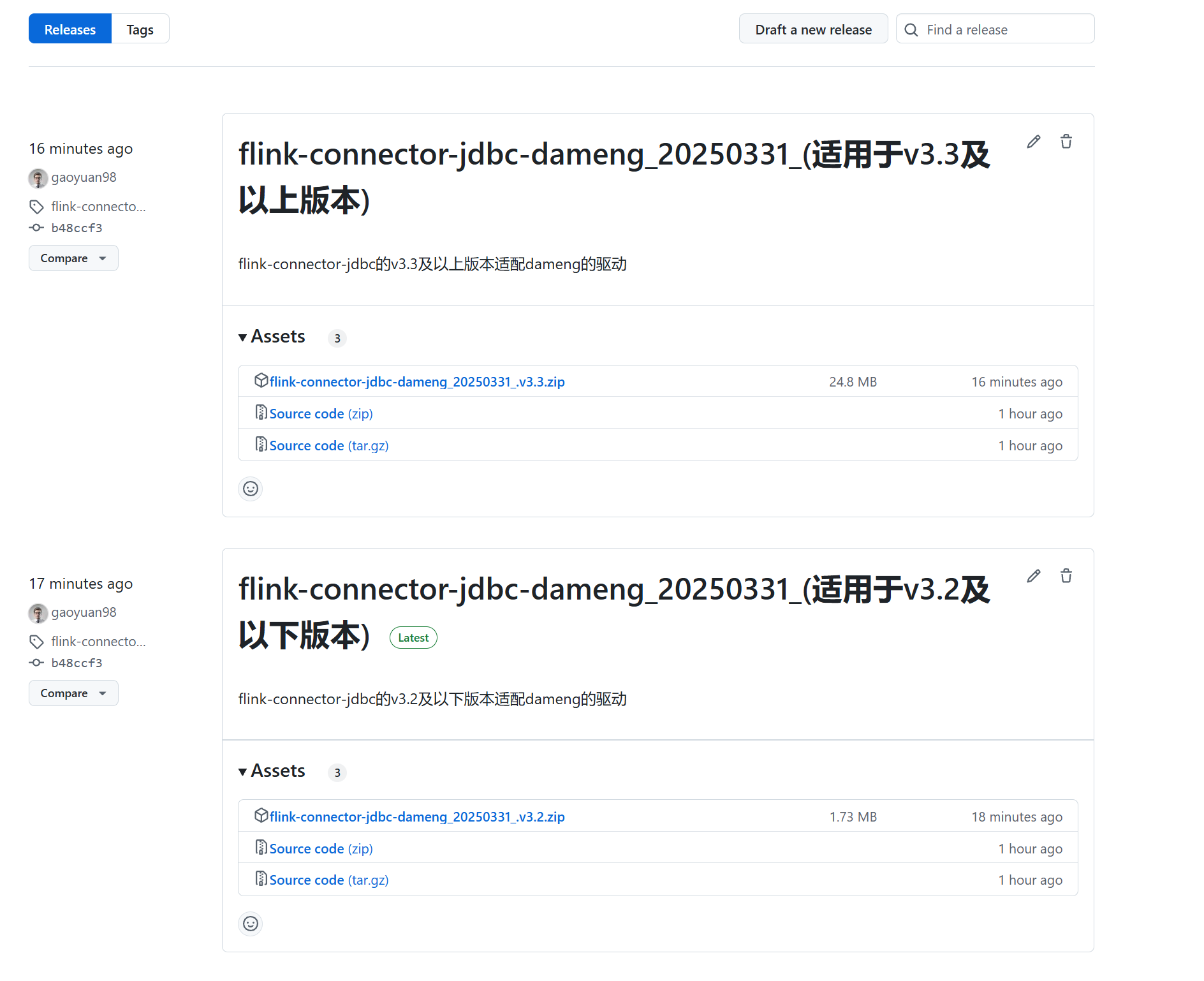
1)下载已经适配好的包https://github.com/gaoyuan98/flink-connector-jdbc-dameng/releases
提供了两个版本的dameng适配驱动包,一个是实现JdbcFactory接口,还有一个是实现JdbcDialectFactory接口。
2)截止发文v3.3版本官方还未正式发版,所以大概率是用这个版本:flink-connector-jdbc-dameng_20250331_(适用于v3.2及以下版本)
3)将下载好的适配包放到flink的lib目录下
DmJdbcDriver8.jar 达梦数据库jdbc驱动,可以更换为与数据库版本相同的驱动。
flink-connector-jdbc-3.1.jar flink使用jdbc方式连接数据库时的桥接包,如果项目本身已经有flink-connector-jdbc包可忽略该包。
flink-connector-jdbc-dameng-1.0.jar flink使用jdbc方式连接达梦数据库的适配包,源码基于flink-connector-jdbc.jar包进行调整,所以该包必须存在。
如项目中已经有flink-connector-jdbc的包,那么只需要使用DmJdbcDriver8.jar跟flink-connector-jdbc-dameng-1.0.jar的驱动包即可。
如项目中没有flink-connector-jdbc的包,就把这三个包全部放到lib下。
plain
[root@localhost lib]# cd /data/flink_soft/flink-1.16.1/lib
[root@localhost lib]# ll
total 204020
-rw-r--r--. 1 root root 1615303 Jan 17 00:30 DmJdbcDriver8.jar
-rwxrwxrwx. 1 root root 198857 Jan 19 2023 flink-cep-1.16.1.jar
-rwxrwxrwx. 1 root root 516144 Jan 19 2023 flink-connector-files-1.16.1.jar
-rw-r--r--. 1 root root 277945 Mar 28 23:46 flink-connector-jdbc-3.1-SNAPSHOT.jar
-rw-r--r--. 1 root root 13458 Mar 29 00:13 flink-connector-jdbc-dameng-1.0-SNAPSHOT.jar
-rwxrwxrwx. 1 root root 102470 Jan 19 2023 flink-csv-1.16.1.jar
-rwxrwxrwx. 1 root root 117107159 Jan 19 2023 flink-dist-1.16.1.jar
-rwxrwxrwx. 1 root root 180248 Jan 19 2023 flink-json-1.16.1.jar
-rwxrwxrwx. 1 root root 21052640 Jan 19 2023 flink-scala_2.12-1.16.1.jar
-rwxrwxrwx. 1 root root 10737871 Jan 13 2023 flink-shaded-zookeeper-3.5.9.jar
-rwxrwxrwx. 1 root root 15367504 Jan 19 2023 flink-table-api-java-uber-1.16.1.jar
-rwxrwxrwx. 1 root root 36249667 Jan 19 2023 flink-table-planner-loader-1.16.1.jar
-rwxrwxrwx. 1 root root 3133690 Jan 19 2023 flink-table-runtime-1.16.1.jar
-rwxrwxrwx. 1 root root 208006 Jan 13 2023 log4j-1.2-api-2.17.1.jar
-rwxrwxrwx. 1 root root 301872 Jan 13 2023 log4j-api-2.17.1.jar
-rwxrwxrwx. 1 root root 1790452 Jan 13 2023 log4j-core-2.17.1.jar
-rwxrwxrwx. 1 root root 24279 Jan 13 2023 log4j-slf4j-impl-2.17.1.jar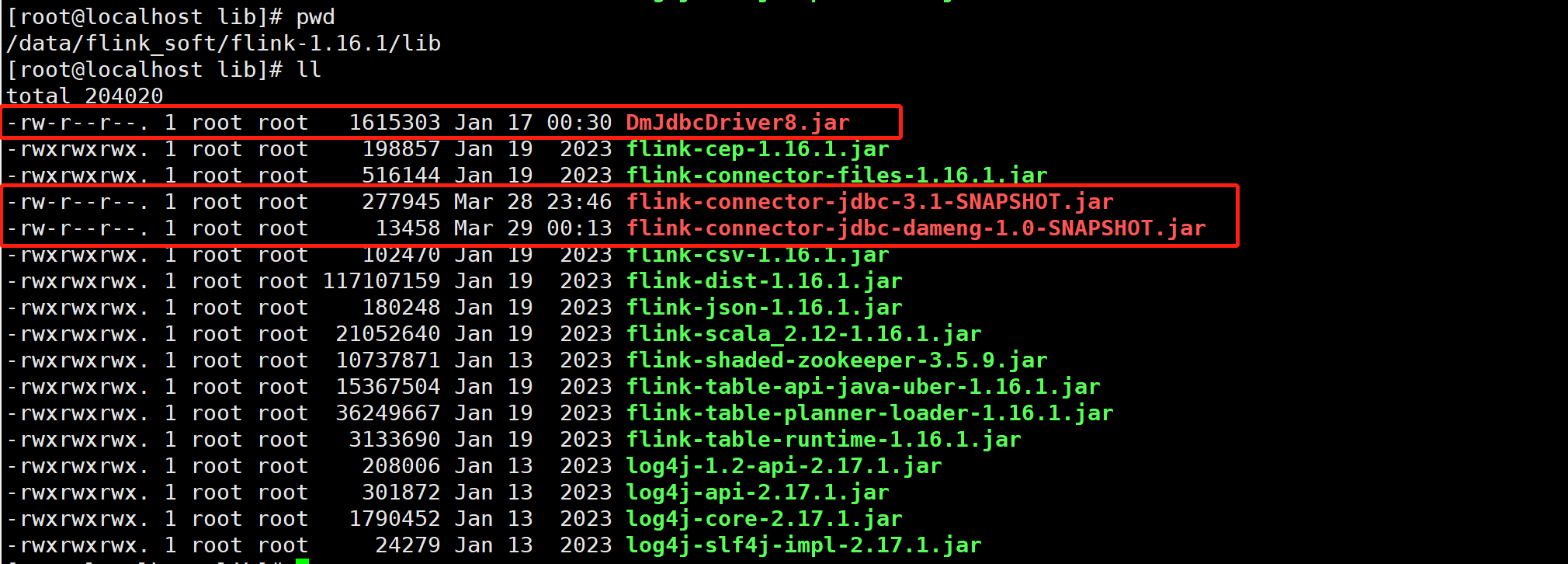
重启flink
plain
[root@localhost flink-1.16.1]# cd /data/flink_soft/flink-1.16.1
[root@localhost flink-1.16.1]# ./bin/stop-cluster.sh
[root@localhost flink-1.16.1]# ./bin/start-cluster.sh
## 如果报错的话查看这个日志
tail -f $FLINK_HOME/log/flink-*-taskexecutor-*.logflink驱动验证
在达梦数据库上创建表数据
sql
CREATE TABLE source_table (
id INT PRIMARY KEY,
name VARCHAR(50),
age INT
);
INSERT INTO source_table (id, name, age) VALUES (1, 'Alice', 30);
INSERT INTO source_table (id, name, age) VALUES (2, 'Bob', 25);
INSERT INTO source_table (id, name, age) VALUES (3, 'Charlie', 40);
COMMIT;在 Flink SQL CLI 中定义达梦表
sql
[root@localhost lib]# cd /data/flink_soft/flink-1.16.1/
[root@localhost flink-1.16.1]# ./bin/sql-client.sh embedded
CREATE TABLE source (
id INT,
name STRING,
age INT
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:dm://192.168.127.2:5236/SYSDBA',
'table-name' = 'source_table',
'driver' = 'dm.jdbc.driver.DmDriver',
'username' = 'SYSDBA',
'password' = 'SYSDBA123'
);
## 在 Flink SQL CLI 中查询数据
SELECT * FROM source;
## 筛选数据,比如 查询年龄大于 30 的用户:
SELECT id, name FROM source WHERE age > 30;
## 插入数据
INSERT INTO source (id, name, age) VALUES (3, '33', 33);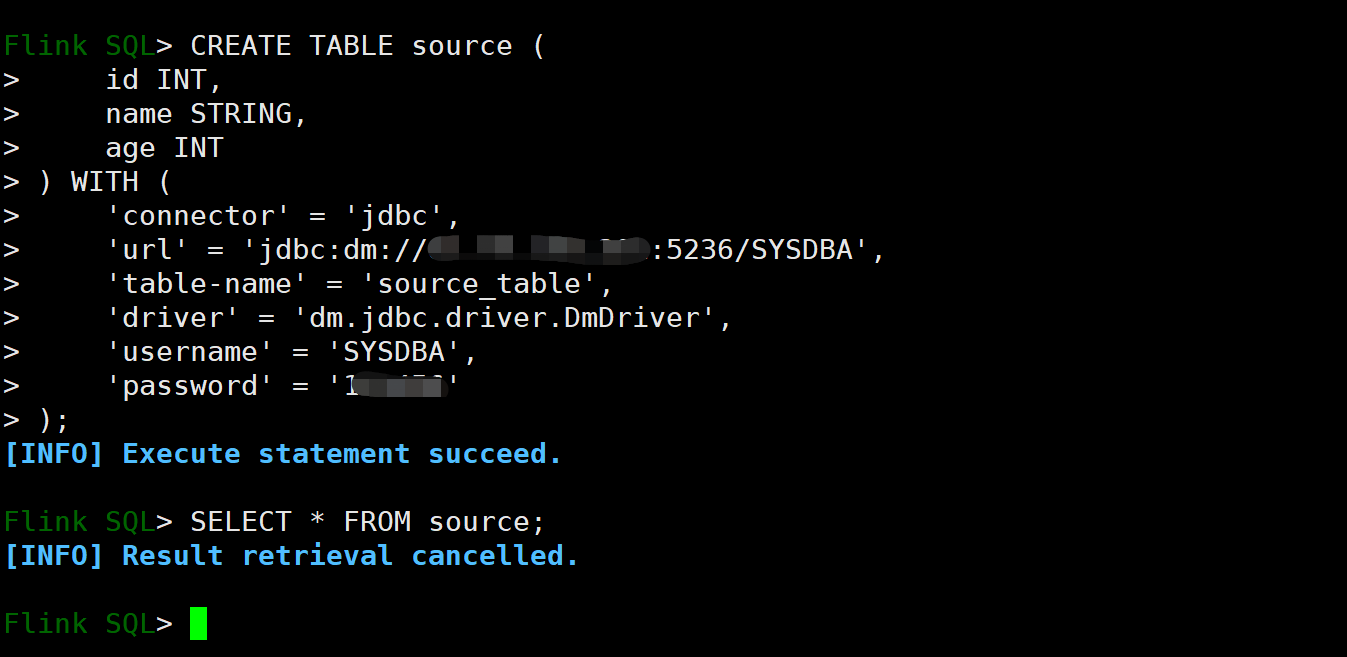

sql
CREATE TABLE source1 (
id INT,
name STRING,
age INT
) WITH (
'connector' = 'dameng',
'url' = 'jdbc:dm://81.70.105.201:5236/SYSDBA',
'table-name' = 'source_table',
'driver' = 'dm.jdbc.driver.DmDriver',
'username' = 'SYSDBA',
'password' = '123456'
);
SELECT * FROM source1;flink-jdbc-dameng选错会怎么?
目前flink-connector-jdbc中,v3.0 - v3.2 都是同一个实现思路,也就是只需要集成实现JdbcDialectFactory接口的方法即可,main分支的话是实现JdbcFactory接口函数,也就是需要适配两个版本。
因使用的是v3.3的dameng包,但flink-connector-jdbc是v3.2及以下版本,驱动包接口实现不对所以会报这个错。