目录
1.启动epoll模型
需求:
客户端: - 浏览器
通IP和端口访问服务器上的某个目录或者文件
- 访问目录:
// 192.168.1.100:8888 这个服务器提供了一个资源目录, 里边有子目录hello/world
-
192.168.1.100:8888/hello/world/
-
访问文件:
//192.168.1.100 这个服务器提供了一个资源目录,里边有子目录hello, 这里边有文件 a.html
192.168.1.100:8888/hello/a.html
服务器: - C语言
-
客户端的是浏览器: 使用的协议必须是http
-
服务器提供什么功能?
-
接受多客户端的连接
-
应用程层使用http, 传输层协议tcp
-
基于epoll写 / 基于libev
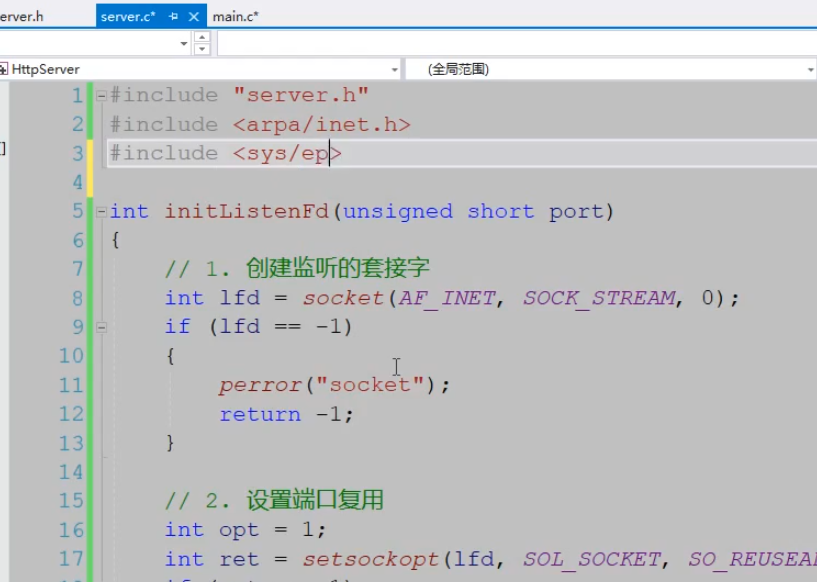
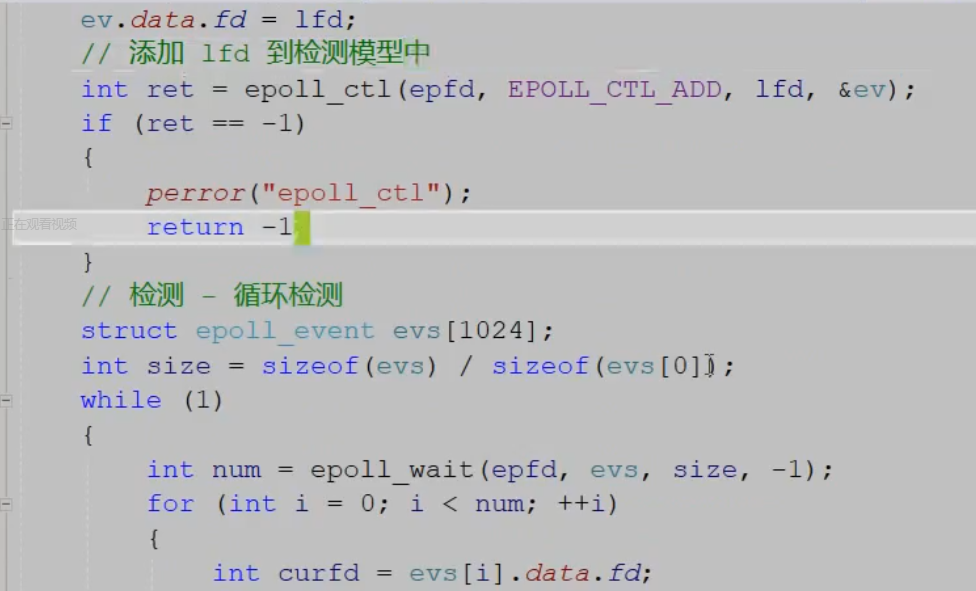
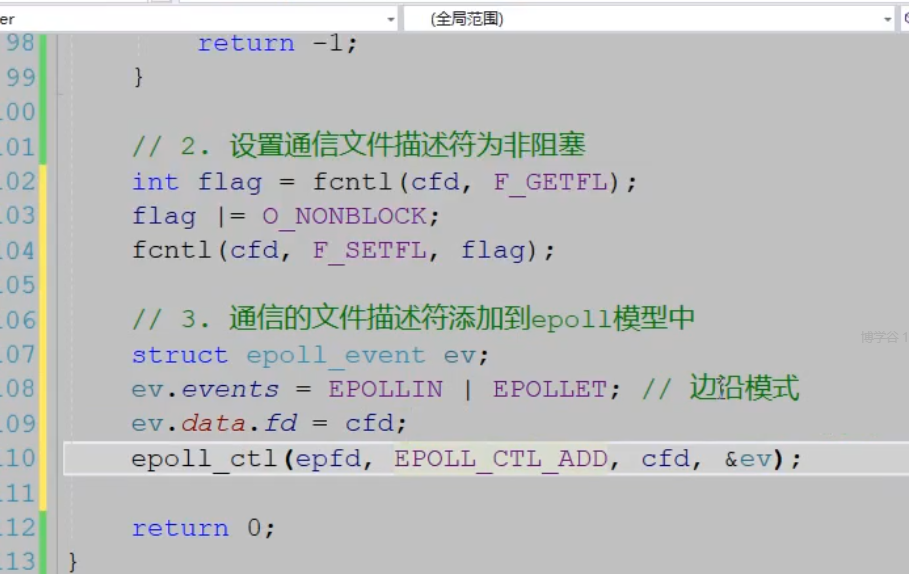
2.和客户端建立新连接
-
在epoll中
-
接受新连接 -> 客户端(浏览器)
-
通信
-
接收浏览器发送过来 http 请求
-
浏览器只给服务器发送get请求
-
判断是不是get请求
-
判断客户端访问的是不是服务器的某个资源目录
-
需要将这个目录中的所有的文件信息发送给浏览器
-
回复数据的时候, 需要使用http响应消息对回复的数据进行包装
-
要保证的数据是什么格式?
-
回复一个动态网页
-
是一个列表 -><table>
-
判断客户端访问的是不是服务器资源目录中的某个文件
-
服务器需要将这个文件发送给浏览器
-
回复数据的时候, 需要使用http响应消息对回复的数据进行包装
3.接受客户端Http请求数据
-
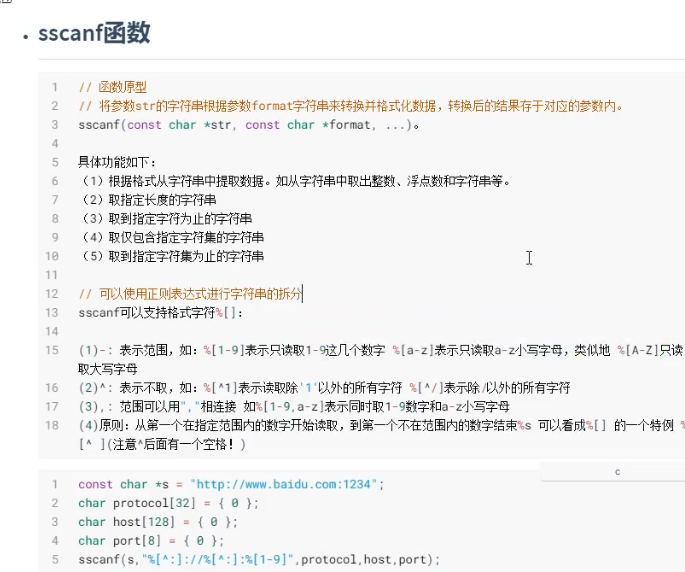
sscanf函数
```c
// 函数原型
// 将参数str的字符串根据参数format字符串来转换并格式化数据,转换后的结果存于对应的参数内。
sscanf(const char *str, const char *format, ...)。
具体功能如下:
(1)根据格式从字符串中提取数据。如从字符串中取出整数、浮点数和字符串等。
(2)取指定长度的字符串
(3)取到指定字符为止的字符串
(4)取仅包含指定字符集的字符串
(5)取到指定字符集为止的字符串
sscanf可以支持格式字符%\[\]:
(1)-: 表示范围,如:%1-9表示只读取1-9这几个数字 %a-z表示只读取a-z小写字母,类似地 %A-Z只读取大写字母
(2)^: 表示不取,如:%\^1表示读取除'1'以外的所有字符 %\^/表示除/以外的所有字符
(3),: 范围可以用","相连接 如%1-9,a-z表示同时取1-9数字和a-z小写字母
(4)原则:从第一个在指定范围内的数字开始读取,到第一个不在范围内的数字结束%s 可以看成%\[\] 的一个特例 %\^ (注意^后面有一个空格!)
```
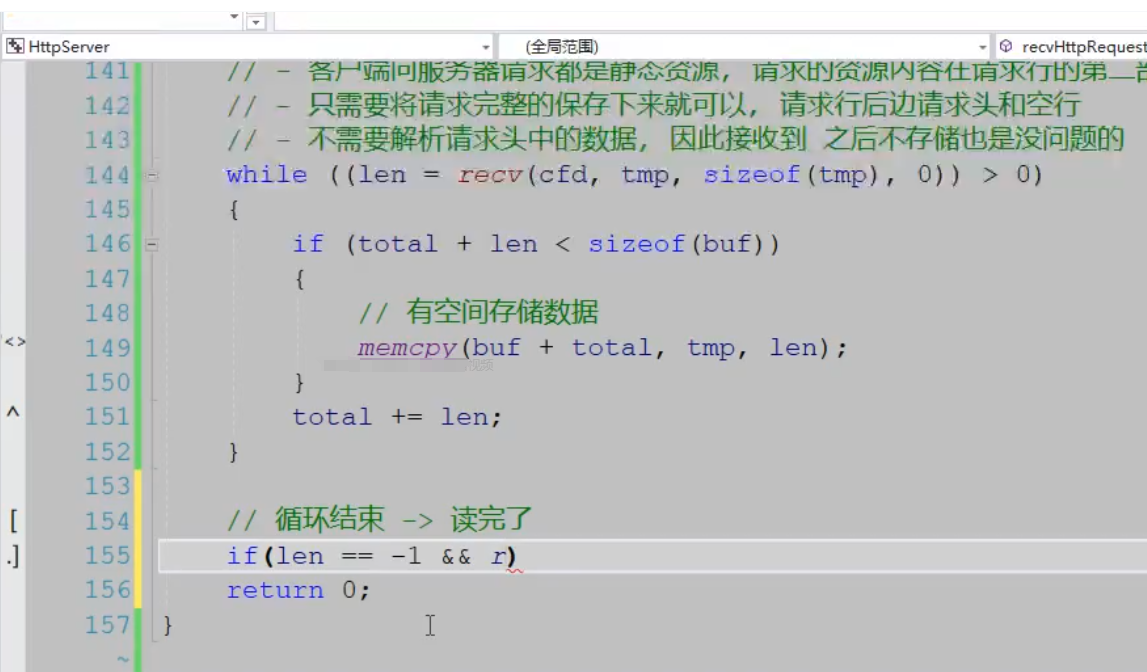
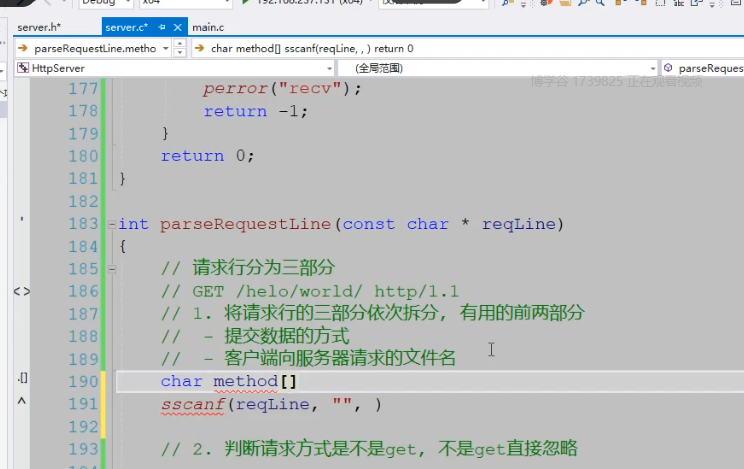
4.代码回顾从接受的数据中读出请求行
```c
const char *s = "http://www.baidu.com:1234";
char protocol32 = { 0 };
char host128 = { 0 };
char port8 = { 0 };
sscanf(s,"%\^:://%\^::%1-9",protocol,host,port);
printf("protocol: %s\n",protocol);
printf("host: %s\n",host);
printf("port: %s\n",port);
///
sscanf("123456 abcdedf", "%\^ ", buf);
printf("%s\n", buf);
结果为:123456
///
sscanf("123456abcdedfBCDEF", "%1-9a-z", buf);
printf("%s\n", buf);
结果为:123456abcdedf
///
sscanf("123456abcdedfBCDEF", "%\^A-Z", buf);
printf("%s\n", buf);
结果为:123456abcdedf
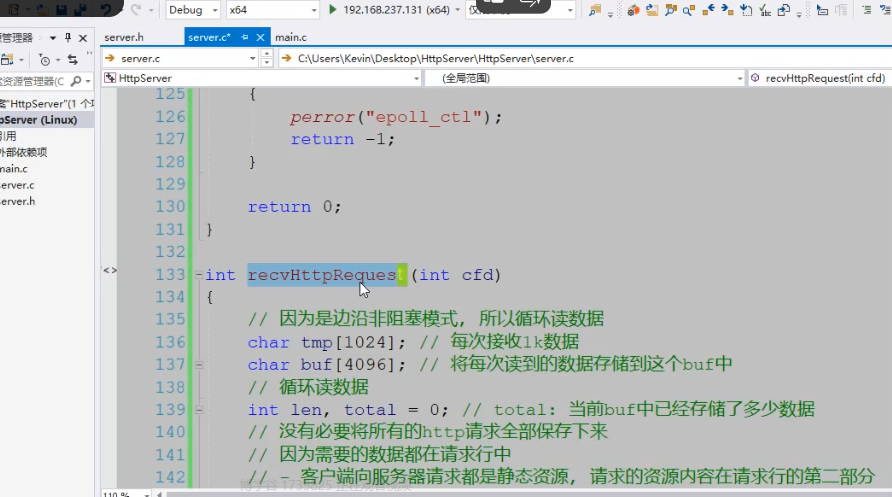
5.请求行解析
scandir函数
```c
// 头文件
#include <dirent.h>
//函数定义
/*
函数scandir扫描dir目录下以及dir子目录下满足filter过滤模式的文件,返回的结果是compare函数经过排
序的,并保存在 namelist中。注意namelist是通过malloc动态分配内存的,所以在使用时要注意释放内存。
alphasort和versionsort 是使用到的两种排序的函数。
当函数成功执行时返回找到匹配模式文件的个数,如果失败将返回-1。
*/
int scandir(const char *dir,struct dirent **namelist,int (*filter)(const void *b),
int (* compare)(const struct dirent **, const struct dirent **));
int alphasort(const void *a, const void *b);
int versionsort(const void *a, const void *b);
```
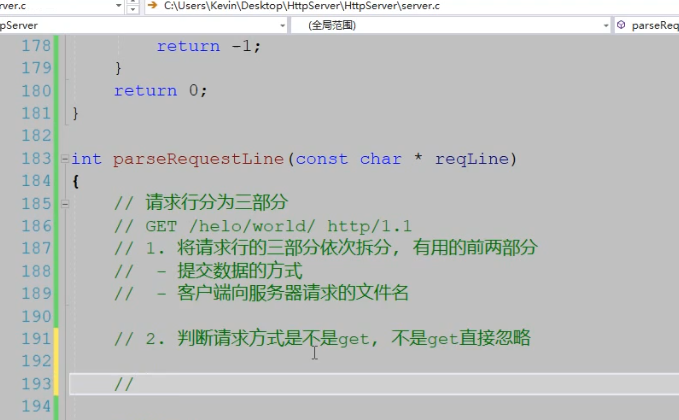
6.正则表达式以及匹配
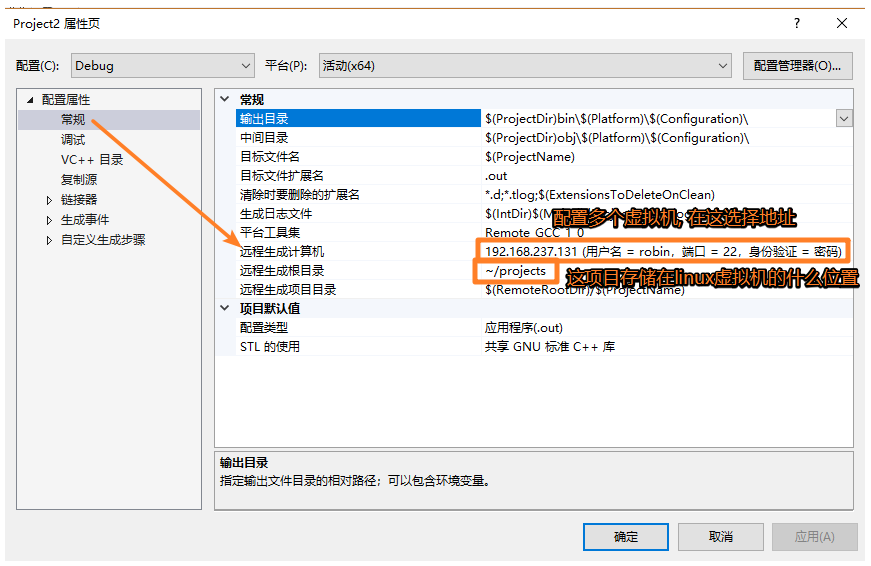
7.解析请求行以及后续处理
> 超文本标记语言(**H**yper **T**ext **M**arkup **L**anguage),标准通用标记语言下的一个应用。HTML 不是一种编程语言,而是一种标记语言 (markup language),是网页制作所必备的。
>
> 超文本就是指页面内可以包含图片、链接,甚至音乐、程序等非文字元素。
>
> 超文本标记语言的结构包括**"**头"部分(英语:Head)、和"主体"部分(英语:Body),其中"头"部提供关于网页的信息,"主体"部分提供网页的具体内容。
-
html 特点
-
语法非常简洁、比较松散,以相应的英语单词关键字进行组合
-
有很多标签, 不同标签表达的意义不同, 每个标签的功能都是固定不变的
-
不按照标准格式写网页, 也可以被解析
-
html标签不区分大小写
-
大多数标签是成对出现的, 有开始, 有结束
-
<html></html>
-
特殊的单标签: <img> <hr> <br>
-
成对的标签
-
不成对出现的称之为短标签
-
html文件命名
-
`xxx.html`
-
`xxx.htm`

8.对path处理说明
-
html文件命名
-
`xxx.html`
-
`xxx.htm`
-
注释
```html
<!-- 这是一个注释 -->
```
- 结构
```html
<html> <!-- 根标签, 代表网页的开始 -->
<head>
<!-- tab页的标题, 和网页的一些属性设置 -->
<title>握手标题</title>
</head>
<body>
<!-- 在网页中显示的内容 -->
</body>
</html>
```
9.如何回复响应数据
1.2 文字和标题标签
```html
<!-- 标题标签 , h1最大的, h6最小的 -->
<h1></h1>
<h2></h2>
<h3></h3>
......
<h6></h6>
<!-- 文字 , 习惯上将属性的值放到单引号, 或者双引号中 -->
<font color="blue" size="5">hello,world</font>
属性:
color: 文字颜色
□ 表示方式:
® 英文单词: red green blue......
® 使用16进制的形式表示颜色: #ffffff
size: 文字大小
□ 范围 1 -- 7
® 1最小, 7最大
<!-- 段落 自动换行 -->
<p></p>
<!-- 换行 单标签, 末尾有没有/都可以 -->
<br/> or <br>
<!-- 水平线 单标签, 末尾有没有/都可以 -->
<hr/> or <hr>
<!-- 文本格式 -->
加粗:
<strong></strong>
<b></b>
文本倾斜标签
<em></em>
<i></i>
删除线标签
<del></del>
<s></s>
下划线标签
<ins></ins>
<u></u>
```
10.对文件对应content-type如何查询
```http
POST / HTTP/1.1
Host: 192.168.1.8:6789
Connection: keep-alive
Content-Length: 98
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
Origin: null
Content-Type: application/x-www-form-urlencoded
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.106 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
username=subwen%40qq.com&phone=1111111&email=sub%40qq.com&date=2020-01-01&sex=male&class=1&rule=on
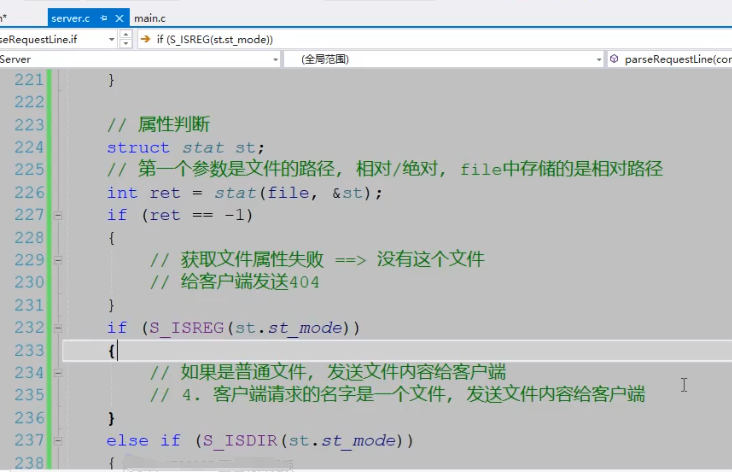
11.服务器处理流程梳理
第 2-9 行: 响应头(消息报头)
-
Content-Type: 服务器给客户端回复的数据块的格式 == http响应第四部分的数据块格式
-
text/plain; ==> 纯文本
-
charset=iso-8859-1 ==> 数据的字符编码
-
iso-8859-1 ==> 不支持中文
-
utf8: 支持中文
-
Content-Length: 服务器给客户端回复的数据块的长度 == http响应第四部分的数据块字节数
-
对应的value值必须是正确的数值
-
如果不知道数据块的字节数, 可以指定-1
第 11-16 行: 服务器给客户端回复的响应数据
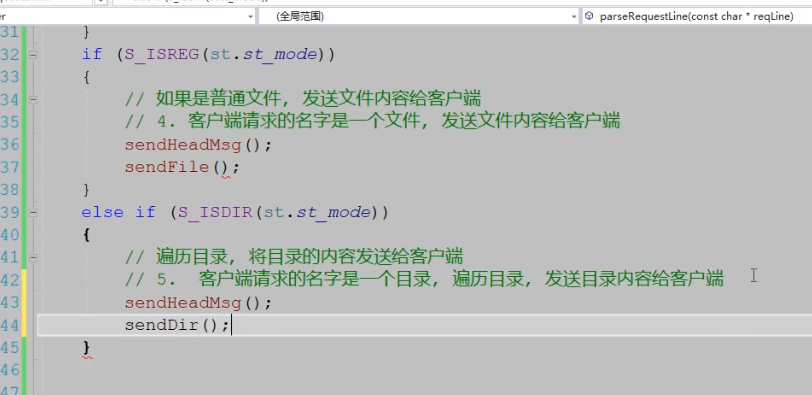
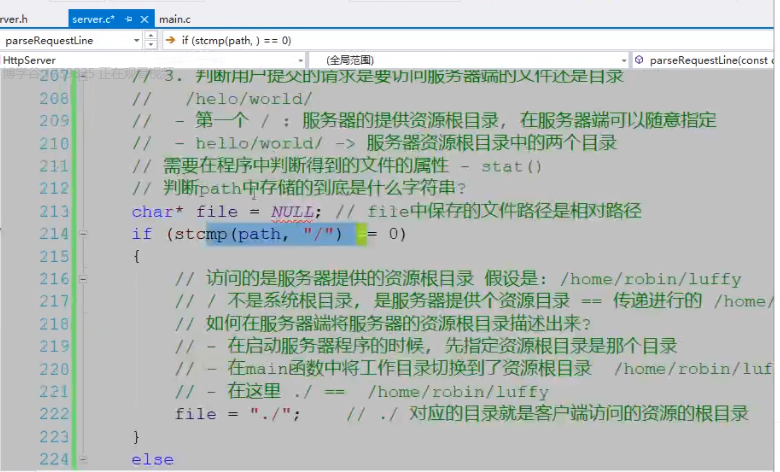
12.和客户端断开连接处理
- http状态码
> 状态代码有三位数字组成,第一个数字定义了响应的类别,共分五种类别:
>
> - 1xx:指示信息--表示请求已接收,继续处理
> - 2xx:成功--表示请求已被成功接收、理解、接受
> - 3xx:重定向--要完成请求必须进行更进一步的操作
> - 4xx:客户端错误--请求有语法错误或请求无法实现
> - 5xx:服务器端错误--服务器未能实现合法的请求
> 常见状态码:
>
> - 200 OK 客户端请求成功
> - 400 Bad Request 客户端请求有语法错误,不能被服务器所理解
> - 401 Unauthorized 请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用
> - 403 Forbidden 服务器收到请求,但是拒绝提供服务
> - 404 Not Found 请求资源不存在,eg:输入了错误的URL
> - 500 Internal Server Error 服务器发生不可预期的错误
> - 503 Server Unavailable 服务器当前不能处理客户端的请求,一段时间后可能恢复正常
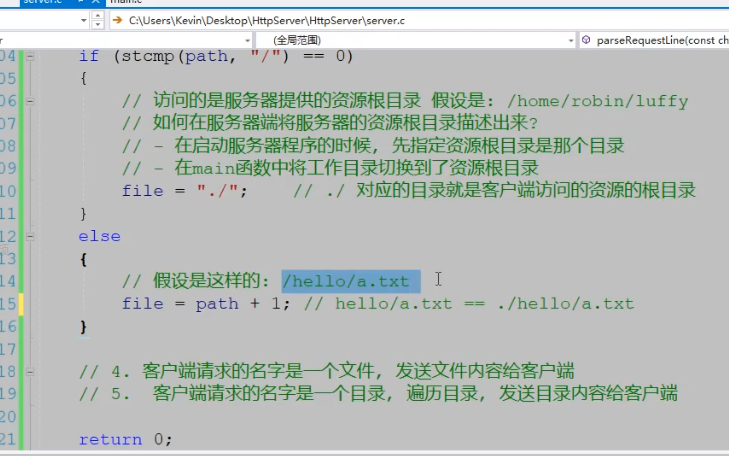
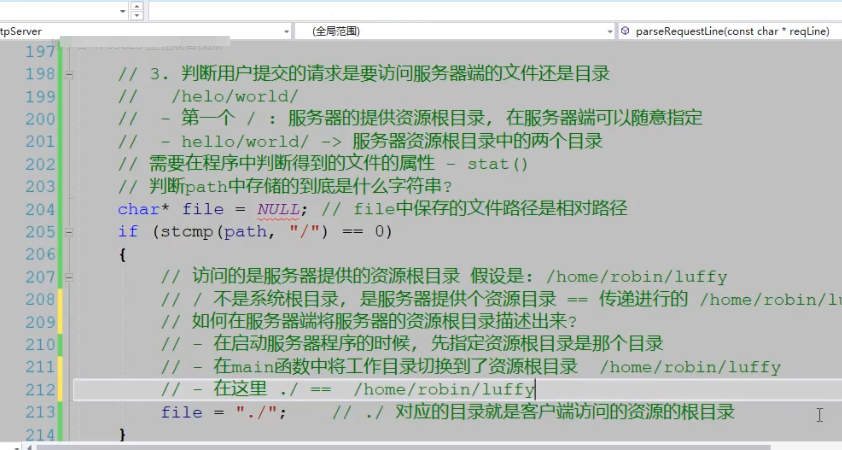
13.http请求处理流程回顾
```c
/*
客户端: 浏览器
-
通过浏览器访问服务器:
-
访问方式: 服务器的IP地址:端口
-
应用层协议使用: http, 数据需要在浏览器端使用该协议进行包装
-
响应消息的处理也是浏览器完成的 => 程序猿不需要管
-
客户端通过url访问服务器资源
-
客户端访问的路径:
-
访问服务器提供的资源目录的根目录
-
并不是服务器上的 / 目录
-
这个目录根据服务器端的描述应该是: /home/robin/luffy 目录
-
请求行:
GET / HTTP/1.1
-
端口后边的/代表服务器的资源根目录
-
在服务器端路径: /home/robin/luffy 目录
-
客户端要访问服务器上的a.txt的文件
-
a.txt 这个文件在服务器提供的资源目录中
-
服务器上的路径: /home/robin/luffy/a.txt
-
请求行:
GET /a.txt HTTP/1.1
-
http://192.168.1.100:8989: 服务器地址
-
/hello/a.txt
-
/: 服务器端提供的资源根目录
-
hello: 资源根目录的子目录
-
a.txt: 在hello目录中
-
请求行:
GET /hello/a.txt HTTP/1.1
-
http://192.168.1.100:8989: 服务器地址
-
/hello/world/
-
/: 服务器端提供的资源根目录
-
hello: 资源根目录的子目录
-
world/: 如果world后边有/代表这是一个目录, 这个目录在hello目录中
-
请求行:
GET /hello/world/ HTTP/1.1
*/
14.发送状态行和响应头
// 服务器端处理的伪代码
int main()
{
// 1. 创建监听的fd
socket();
// 2. 绑定
bind();
// 3. 设置监听
listen();
// 4. 创建epoll模型
epoll_create();
epoll_ctl();
// 5. 检测
while(1)
{
epoll_wait();
// 监听的文件描述符
accept();
// 通信的
// 接收数据->http请求消息
recvAndParseHttp();
}
return 0;
}
15.根据文件获取content-type和发送文件
```http
HTTP/1.1 200 Ok
Server: micro_httpd
Date: Fri, 18 Jul 2014 14:34:26 GMT
Content-Type: text/plain; charset=iso-8859-1 (必选项)
Content-Length: 32
Location: https://www.biadu.com
Content-Language: zh-CN
Last-Modified: Fri, 18 Jul 2014 08:36:36 GMT
Connection: close
#include <stdio.h>
int main(void)
{
printf("hello world!\n");
return 0;
}
```
16.程序调试和访问文件测试