1.使用正则完成下列内容的匹配
-
匹配陕西省区号 029-12345
-
匹配邮政编码 745100
-
匹配身份证号 62282519960504337X
python
import re
# 定义各类内容的正则表达式规则
patterns = {
# 1. 匹配陕西省区号(029-开头,后跟5位数字)
"陕西区号": r"^029-\d{5}$",
# 2. 匹配邮政编码(6位数字,国内邮编规则)
"邮政编码": r"^\d{6}$",
# 3. 匹配邮箱(用户名@域名,支持字母/数字/下划线,域名支持多级)
"邮箱": r"^[a-zA-Z0-9_]+@[a-zA-Z0-9]+\.[a-zA-Z0-9.]+$",
# 4. 匹配身份证号(18位,最后一位支持数字/X/x)
"身份证号": r"^\d{17}[\dXx]$"
}
# 测试用例(包含符合规则和不符合规则的示例)
test_cases = {
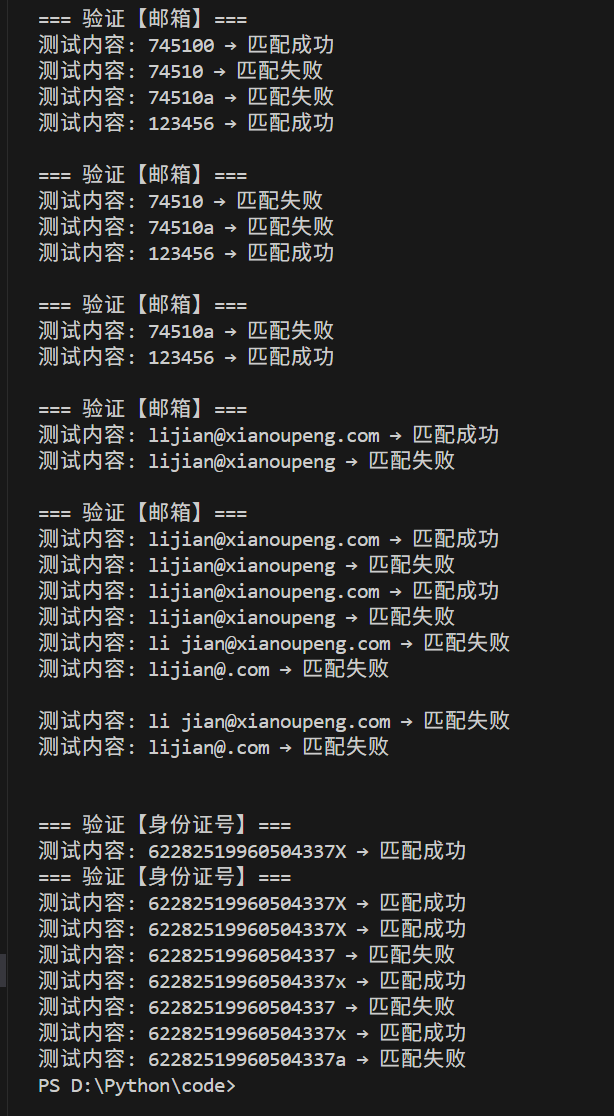
"陕西区号": ["029-12345", "029-1234", "010-12345", "029-1234a"],
"邮政编码": ["745100", "74510", "74510a", "123456"],
"邮箱": ["lijian@xianoupeng.com", "lijian@xianoupeng", "li jian@xianoupeng.com", "lijian@.com"],
"身份证号": ["62282519960504337X", "62282519960504337", "62282519960504337x", "62282519960504337a"]
}
# 遍历测试并输出结果
if __name__ == "__main__":
for type_name, pattern in patterns.items():
print(f"\n=== 验证【{type_name}】===")
for case in test_cases[type_name]:
# 执行正则匹配
match = re.match(pattern, case)
result = "匹配成功" if match else "匹配失败"
print(f"测试内容: {case} → {result}")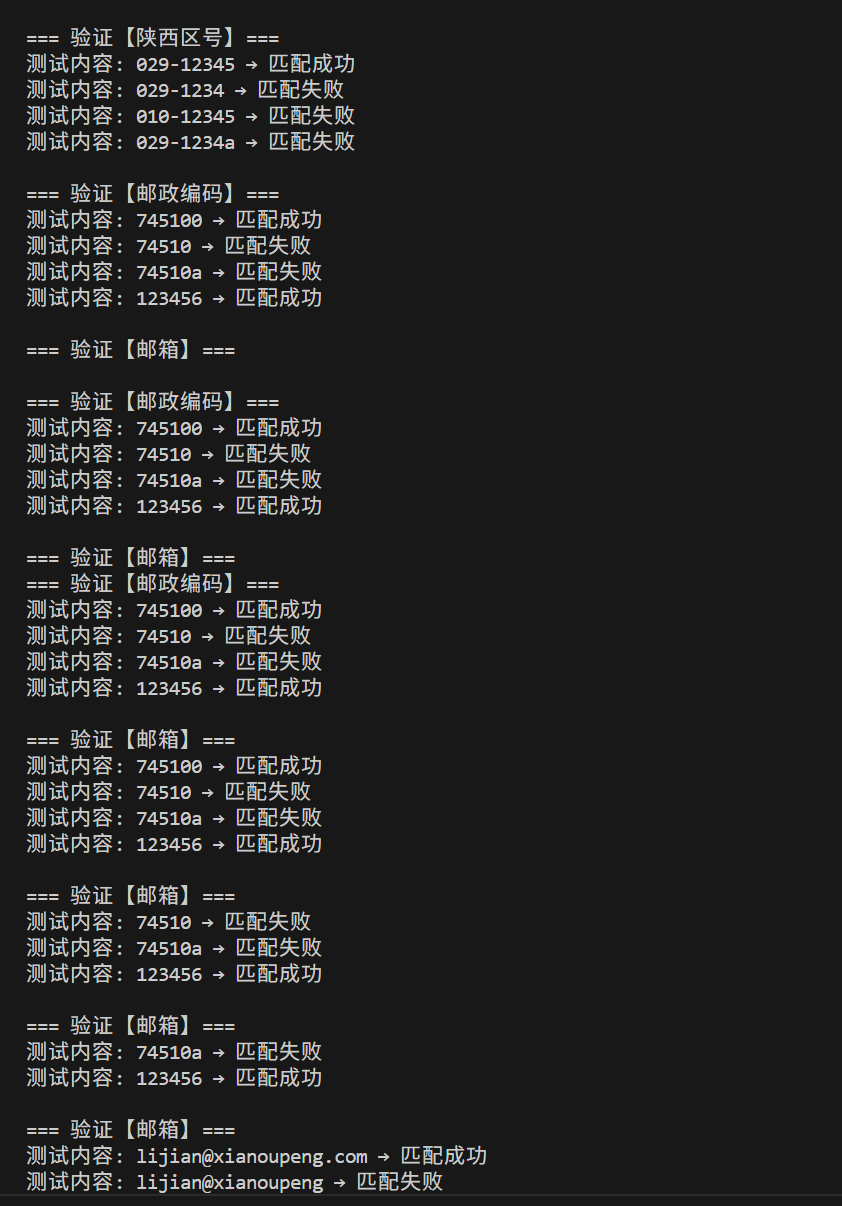
2.爬取学校官网,获取所有图片途径并将路径存储在本地文件中,使用装饰器完成
python
import requests
from bs4 import BeautifulSoup
import time
import functools
# -- 装饰器定义 --
def crawl_decorator(func):
@functools.wraps(func) # 保留原函数的元信息
def wrapper(url, save_file):
# 初始化日志信息
crawl_info = {
"start_time": time.strftime("%Y-%m-%d %H:%M:%S"),
"url": url,
"success": False,
"img_count": 0,
"error_msg": "",
"end_time": ""
}
try:
print(f"\n=== 开始爬取 {url} ===")
# 调用原爬取函数,获取图片路径列表
img_urls = func(url, save_file)
# 更新爬取信息
crawl_info["success"] = True
crawl_info["img_count"] = len(img_urls)
crawl_info["end_time"] = time.strftime("%Y-%m-%d %H:%M:%S")
# 打印摘要
print(f"爬取成功!")
print(f"共爬取到 {len(img_urls)} 张图片")
print(f"图片路径已保存到 {save_file}")
except Exception as e:
# 捕获异常并记录
crawl_info["error_msg"] = str(e)
crawl_info["end_time"] = time.strftime("%Y-%m-%d %H:%M:%S")
print(f"爬取失败!错误信息:{e}")
finally:
# 打印装饰器日志(也可写入日志文件)
print(f"\n=== 爬取日志 ===")
print(f"爬取地址:{crawl_info['url']}")
print(f"开始时间:{crawl_info['start_time']}")
print(f"结束时间:{crawl_info['end_time']}")
print(f"爬取状态:{'成功' if crawl_info['success'] else '失败'}")
if crawl_info['error_msg']:
print(f"错误信息:{crawl_info['error_msg']}")
print(f"图片数量:{crawl_info['img_count']}\n")
return crawl_info # 返回爬取信息,方便后续扩展
return wrapper
# -------------------------- 核心爬取函数 --------------------------
@crawl_decorator # 应用装饰器
def crawl_img_urls(target_url, save_file):
# 1. 设置请求头,模拟浏览器访问(避免被反爬)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
# 2. 发送请求获取网页内容
response = requests.get(target_url, headers=headers, timeout=10)
response.raise_for_status() # 若请求失败(如404/500),抛出异常
response.encoding = response.apparent_encoding # 自动识别编码,避免乱码
# 3. 解析HTML,提取所有img标签的src属性
soup = BeautifulSoup(response.text, "html.parser")
img_tags = soup.find_all("img") # 找到所有img标签
img_urls = []
for img in img_tags:
img_src = img.get("src") # 获取图片路径
if img_src: # 过滤空路径
# 处理相对路径:如果src是相对路径,拼接成完整URL
if not img_src.startswith(("http://", "https://")):
img_src = requests.compat.urljoin(target_url, img_src)
img_urls.append(img_src)
# 4. 将图片路径写入本地文件
with open(save_file, "w", encoding="utf-8") as f:
for idx, img_url in enumerate(img_urls, 1):
f.write(f"{idx}. {img_url}\n") # 按序号写入,方便查看
return img_urls
# -- 主程序调用 --
if __name__ == "__main__":
# 配置参数
target_url = "https://nhjcxy.tingshuokj.com/" # 目标爬取网站
save_file = "img_urls.txt" # 本地保存图片路径的文件
# 执行爬取(装饰器会自动生效)
crawl_img_urls(target_url, save_file)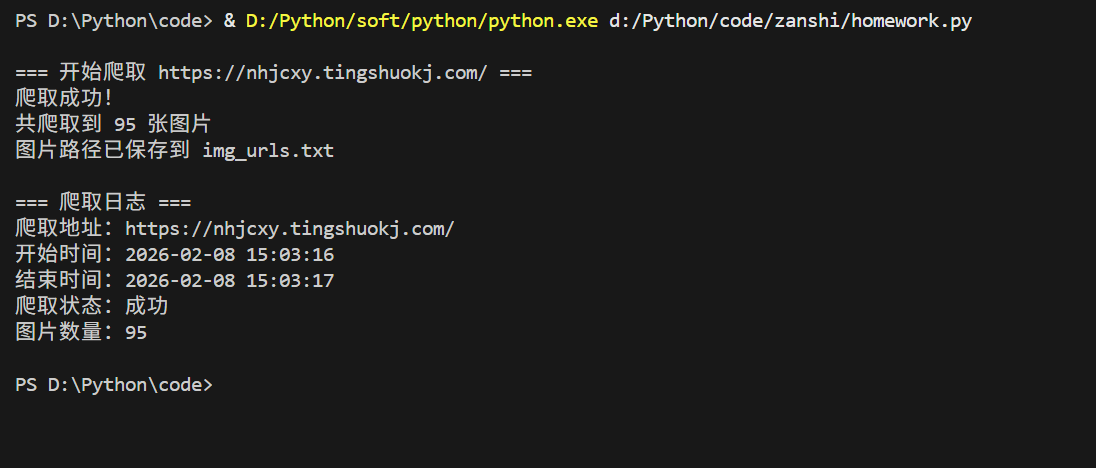
3.未每日一讲的同学,自行录制视频并上传
每日一讲