智能客服系统中的意图识别与分类技术详解
- 智能客服系统中的意图识别与分类技术详解
-
- 一、智能客服系统概述
-
- [1. 问题处理流程](#1. 问题处理流程)
- [2. 关键角色分工](#2. 关键角色分工)
- 二、分类任务技术解析
-
- [1. 分类任务基本概念](#1. 分类任务基本概念)
- [2. 分类模型实现示例](#2. 分类模型实现示例)
- [3. 性能优化关键点](#3. 性能优化关键点)
- 三、意图识别核心技术
- 四、数据标注与模型优化
- 五、行业实践建议
-
- [1. 实施路径规划](#1. 实施路径规划)
- [2. 典型问题解决方案](#2. 典型问题解决方案)
- 六、未来发展方向
- 七、意图识别模型评估体系详解
-
- [1. 评估指标数学原理](#1. 评估指标数学原理)
- [2. 核酸检测案例解析](#2. 核酸检测案例解析)
- [3. 电商客服案例评估](#3. 电商客服案例评估)
- 八、数据标注与模型优化实践
-
- [1. 数据质量关键要素](#1. 数据质量关键要素)
- [2. 数据质量影响实验](#2. 数据质量影响实验)
- [3. 模型优化技术路线](#3. 模型优化技术路线)
- 九、关键问题深度思考
-
- [1. 规则与模型的选择标准](#1. 规则与模型的选择标准)
- [2. 训练数据量影响因素](#2. 训练数据量影响因素)
- [3. 负向样本的核心价值](#3. 负向样本的核心价值)
- 十、行业实施建议
-
- [1. 数据标注最佳实践](#1. 数据标注最佳实践)
- [2. 模型迭代策略](#2. 模型迭代策略)
- [3. 异常情况处理](#3. 异常情况处理)
智能客服系统中的意图识别与分类技术详解

一、智能客服系统概述
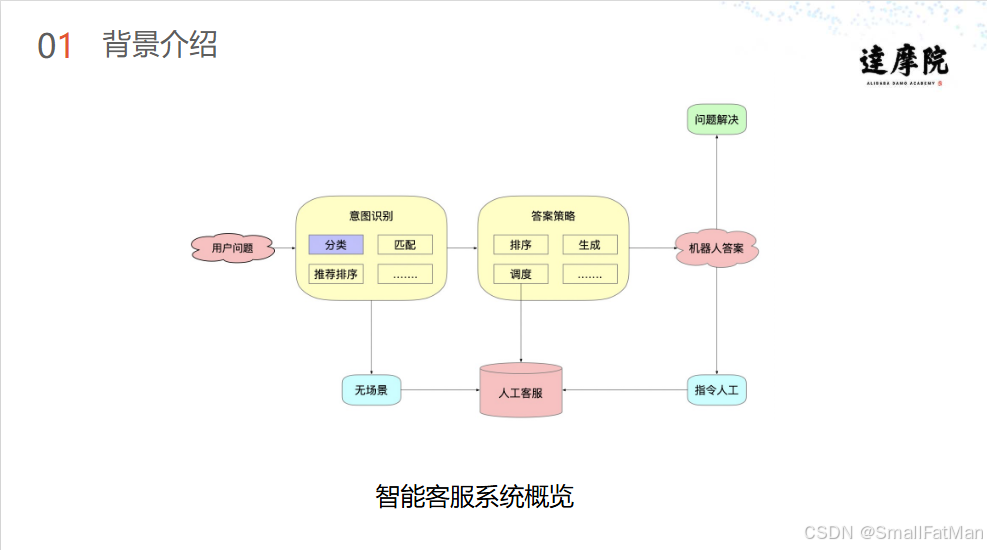
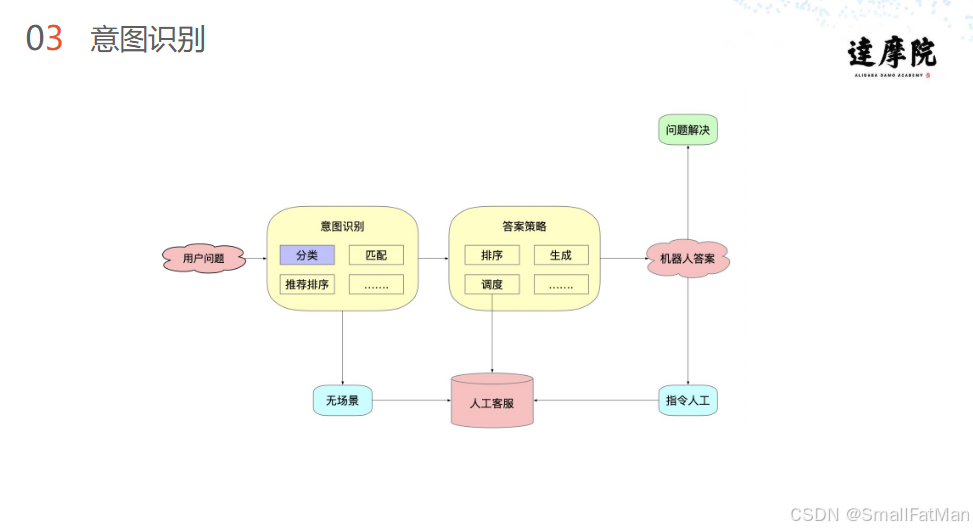
现代智能客服系统已成为企业客户服务的重要组成部分,其核心架构主要包含三大模块:
1. 问题处理流程
用户问题 意图识别 分类匹配 推荐排序 答案策略 机器人答案
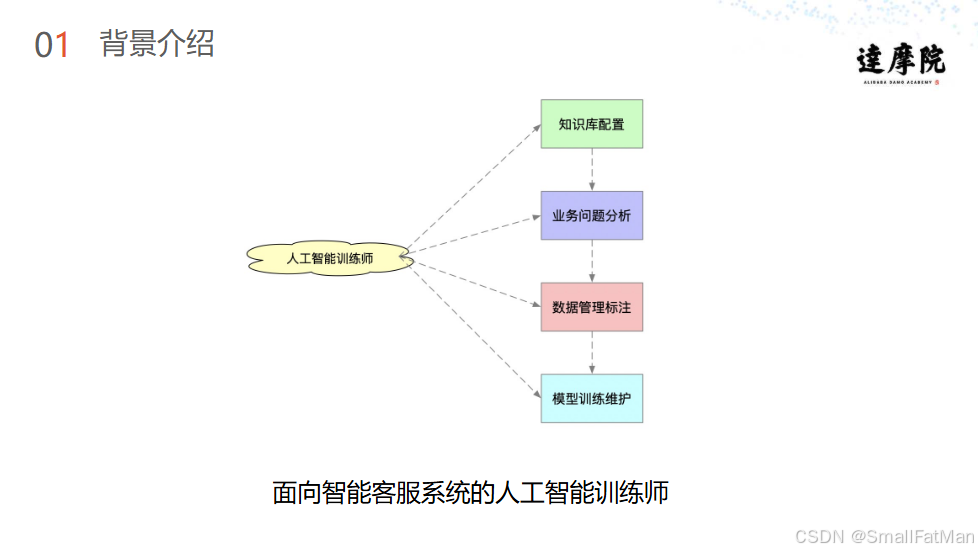
2. 关键角色分工
-
人工智能训练师:
- 知识库配置与维护
- 业务问题分析
- 数据标注与管理
- 模型训练监控
-
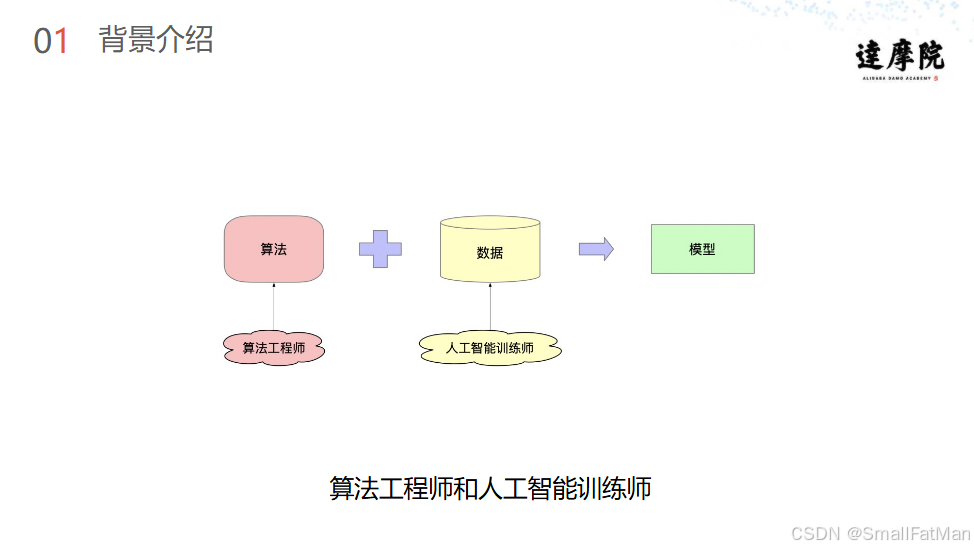
算法工程师:
- 数据处理与特征工程
- 模型架构设计与优化
- 算法性能调优
两者协同工作,形成"业务理解-数据准备-模型开发"的闭环。
二、分类任务技术解析


1. 分类任务基本概念
分类任务的核心是为输入数据打上预定义的标签,主要分为:
| 分类类型 | 特点 | 典型应用 |
|---|---|---|
| 二分类 | 非此即彼的判断 | 垃圾邮件检测 |
| 多分类 | 单标签多类别 | 情感分析(愤怒/平静/高兴) |
| 多标签 | 多标签并行 | 新闻主题标注(体育+C罗+欧冠) |
2. 分类模型实现示例
以图像分类为例:
python
from transformers import ViTForImageClassification
model = ViTForImageClassification.from_pretrained('google/vit-base-patch16-224')
inputs = processor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits # 分类logits3. 性能优化关键点
- 类别不平衡处理
- 标签噪声过滤
- 领域自适应迁移
三、意图识别核心技术
1. 意图识别流程
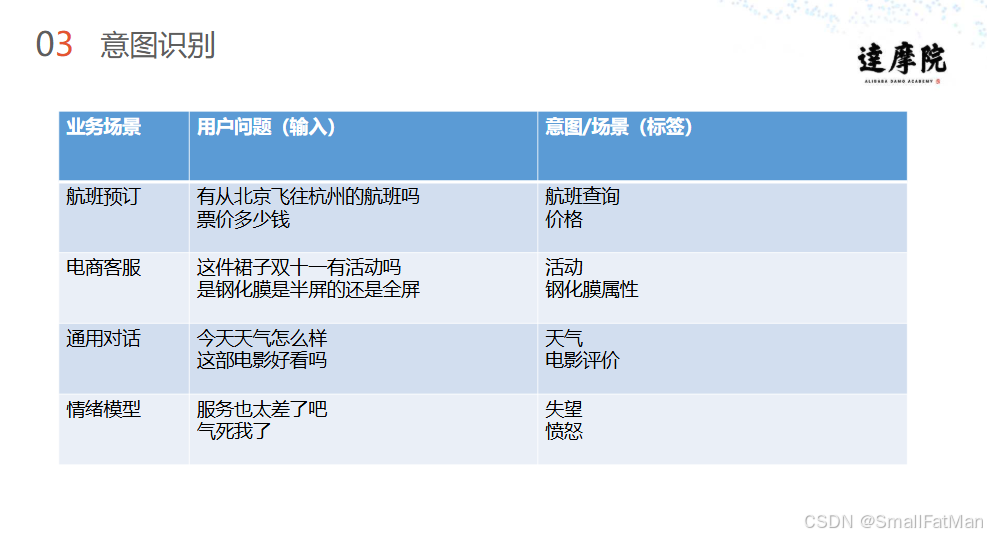
用户输入 → 文本预处理 → 特征提取 → 意图分类 → 槽位填充 → 结构化输出2. 典型业务场景案例
航班预订场景
| 用户输入 | 识别意图 | 关键槽位 |
|---|---|---|
| "有从北京飞往杭州的航班吗票价多少钱" | 航班查询价格 | 出发地:北京, 目的地:杭州 |
电商客服场景
| 用户输入 | 识别意图 | 关键槽位 |
|---|---|---|
| "这件裙子双十一有活动吗" | 活动查询 | 商品类型:裙子, 时间:双十一 |
| "钢化膜是半屏的还是全屏的" | 商品属性查询 | 商品类型:钢化膜, 属性:屏幕覆盖率 |
3. 行业特定模型构建
电子行业示例:
是 否 用户输入 是否包含专业术语? 行业模型处理 通用模型处理 识别'半屏/全屏'等专业表述 处理退换货等通用问题
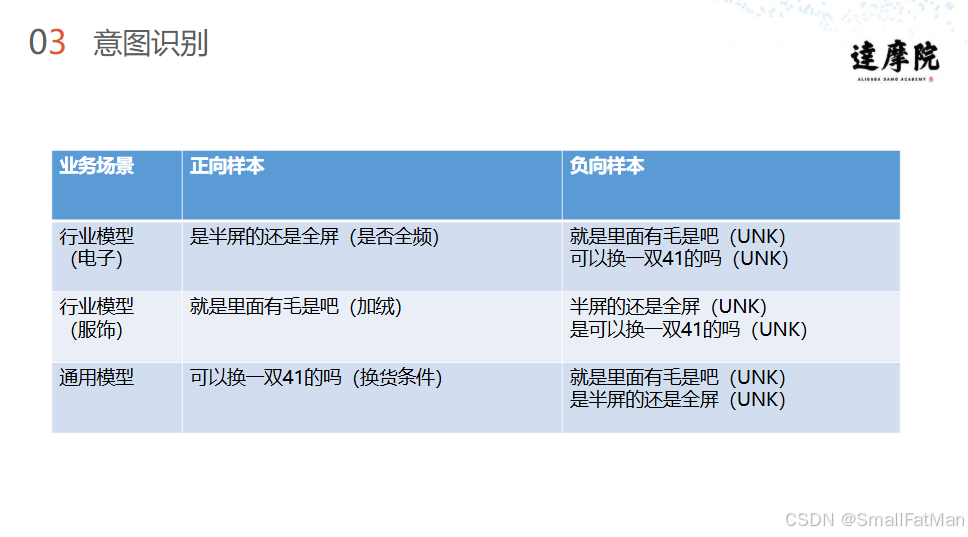
正负样本对比分析:
| 行业 | 正向样本 | 负向样本 | 识别关键 |
|---|---|---|---|
| 电子 | "是半屏的还是全屏的" | "可以换一双41的吗" | 专业术语敏感度 |
| 服饰 | "就是里面有毛是吧" | "半屏的还是全屏的" | 材质属性理解 |
四、数据标注与模型优化
1. 高质量数据标注原则
- 领域覆盖:确保各业务场景均衡
- 歧义处理:明确标注边界案例
- 一致性检查:多人标注交叉验证
2. 模型优化技术路线
文本分类优化策略
python
# 数据增强示例
from nlpaug import Augmenter
aug = Augmenter('contextual_word_embs', model_type='bert')
# 模型微调示例
from transformers import Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset
)
trainer.train()意图识别优化方向
- 多任务学习(联合训练意图分类和槽位填充)
- 领域自适应预训练
- 小样本学习技术应用


3. 评估指标体系
| 指标类型 | 计算公式 | 关注重点 |
|---|---|---|
| 准确率 | (TP+TN)/(P+N) | 整体分类效果 |
| 召回率 | TP/(TP+FN) | 漏检情况 |
| F1值 | 2*(P*R)/(P+R) | 不平衡数据评估 |
| 混淆矩阵 | - | 具体错误类型分析 |
五、行业实践建议
1. 实施路径规划
- 业务需求分析:明确核心场景和关键意图
- 数据体系建设:构建领域特定语料库
- 模型选型验证:对比传统ML与深度学习方案
- 上线监控迭代:建立数据飞轮机制
2. 典型问题解决方案
场景 :新业务冷启动问题
方案:
- 使用通用意图模型作为基础
- 结合少量标注数据微调
- 主动学习选择高价值样本
场景 :方言和口语化表达
方案:
- 构建本地化表达词典
- 数据增强生成变体
- 语音识别后处理优化
六、未来发展方向
-
多模态意图理解:
- 结合语音语调识别情绪
- 图像辅助商品咨询
-
动态意图识别:
graph LR A[用户输入] --> B[静态意图识别] A --> C[对话状态跟踪] B + C --> D[动态意图调整] -
可解释性增强:
- 意图判定依据可视化
- 置信度阈值自适应
-
自学习系统:
- 自动发现新意图
- 持续优化模型
智能客服系统中的意图识别技术正朝着更精准、更智能的方向发展。随着大语言模型技术的进步,未来将实现更深层次的语义理解和更自然的交互体验。建议企业从垂直场景切入,建立领域知识壁垒,同时保持技术架构的灵活性和可扩展性。
七、意图识别模型评估体系详解
1. 评估指标数学原理
意图识别模型的性能评估基于混淆矩阵,其核心指标计算如下:
混淆矩阵结构:
预测为正例 预测为负例
实际为正例 TP(真阳) FN(假阴)
实际为负例 FP(假阳) TN(真阴)核心指标公式:
- 准确率: A c c u r a c y = T P + T N T P + F P + F N + T N Accuracy = \frac{TP+TN}{TP+FP+FN+TN} Accuracy=TP+FP+FN+TNTP+TN
- 精确率: P r e c i s i o n = T P T P + F P Precision = \frac{TP}{TP+FP} Precision=TP+FPTP
- 召回率: R e c a l l = T P T P + F N Recall = \frac{TP}{TP+FN} Recall=TP+FNTP
- F1值: F 1 = 2 × P r e c i s i o n × R e c a l l P r e c i s i o n + R e c a l l F1 = 2 \times \frac{Precision \times Recall}{Precision + Recall} F1=2×Precision+RecallPrecision×Recall
2. 核酸检测案例解析
数据分布:
| 预测阳性 | 预测阴性 | |
|---|---|---|
| 实际阳性 | 30 | 5 |
| 实际阴性 | 10 | 55 |
指标计算:
python
# 准确率
accuracy = (30 + 55) / 100 = 0.85
# 精确率
precision = 30 / (30 + 10) = 0.75
# 召回率
recall = 30 / (30 + 5) = 0.857
# F1值
f1 = 2*(0.75*0.857)/(0.75+0.857) ≈ 0.83. 电商客服案例评估
标注与预测对比:
用户问句:怎么还不同颜色呢 标注:颜色种类 预测:颜色种类 用户问句:49.9是一件还是几件 标注:UNKNOWN 预测:UNKNOWN
性能分析:
- 准确率50%:4句中2句完全匹配
- 精确率33%:预测3个"颜色种类"中1个错误
- 召回率50%:实际2个"颜色种类"召回1个
八、数据标注与模型优化实践

1. 数据质量关键要素
高质量数据标准:
数据质量 无噪音 样本平衡 负例充足 标注一致
典型案例对比:
| 标准类型 | 正例 | 反例 |
|---|---|---|
| 优质数据 | "查询发货时间" | "发货地址是什么" |
| 问题数据 | 2000条发货时间 | 仅9条发货地址 |
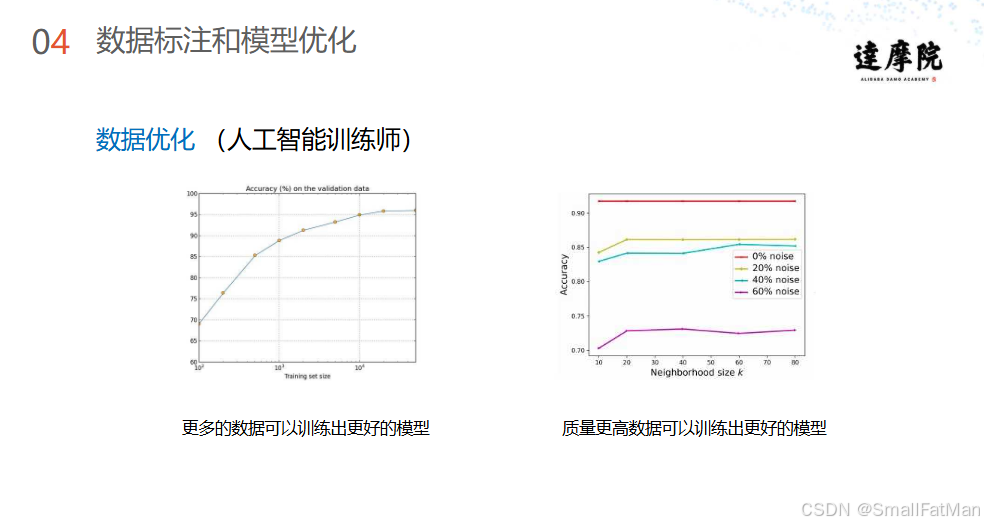
2. 数据质量影响实验
噪声实验数据:
python
# 噪声比例与准确率关系
noise_levels = [0%, 20%, 40%, 60%]
accuracy = [0.98, 0.85, 0.72, 0.55]数据量影响曲线:
准确率
↑
| ↗
| /
| /
| /
+----------------→ 数据量3. 模型优化技术路线
优化策略矩阵:
| 问题类型 | 解决方案 | 实施方法 |
|---|---|---|
| 样本不平衡 | 重采样 | SMOTE算法 |
| 标注噪声 | 数据清洗 | 置信度过滤 |
| 领域迁移 | 微调训练 | 领域自适应预训练 |
| 长尾分布 | 损失加权 | Focal Loss |
九、关键问题深度思考
1. 规则与模型的选择标准
决策树:
固定模式
明确边界
低频变更 语义复杂
变化频繁
需要泛化 业务问题 是否满足以下条件? 规则系统 机器学习模型
典型场景对比:
- 规则适用:固定话术识别、关键词过滤
- 模型适用:用户情绪分析、多意图理解
2. 训练数据量影响因素
数据量公式 :
D r e q u i r e d ∝ C ϵ 2 D_{required} \propto \frac{C}{\epsilon^2} Drequired∝ϵ2C
其中:
- C C C:问题复杂度(类别数×特征维度)
- ϵ \epsilon ϵ:目标错误率
关键因素:
- 意图类别数量
- 语言表达多样性
- 可接受的错误率
- 领域专业度要求
3. 负向样本的核心价值
作用机制:
Without Negative Samples:
模型倾向将所有输入预测为正类 → 召回率100%但精确率暴跌
With Negative Samples:
决策边界清晰 → 可识别"不属于任何已知意图"的情况实验数据:
| 负样本比例 | 精确率 | 召回率 |
|---|---|---|
| 0% | 0.15 | 1.0 |
| 20% | 0.68 | 0.92 |
| 50% | 0.85 | 0.86 |
十、行业实施建议
1. 数据标注最佳实践
标注流程优化:
- 制定详细的标注规范
- 进行多轮标注培训
- 实施交叉验证(至少3人独立标注)
- 建立争议解决机制
质量检查指标:
- 内部一致性 > 85%
- 与金标准吻合度 > 90%
- 每日产出审核率 ≥ 10%
2. 模型迭代策略
持续优化框架:
python
class IntentModel:
def __init__(self):
self.version = 1.0
self.monitor = PerformanceTracker()
def update(self, new_data):
while self.monitor.accuracy < 0.95:
self.train(new_data)
self.evaluate()
if self.improvement < 0.01:
self.architecture_upgrade()3. 异常情况处理
常见问题解决方案:
- 意图冲突:建立优先级规则
- 新增意图:主动学习采样
- 领域漂移:定期全量更新
智能客服系统的意图识别能力直接决定了用户体验。通过建立科学的评估体系、严格的数据质量控制和持续的模型优化机制,可以构建出准确率超过90%的生产级系统。未来发展方向包括:
- 多模态意图理解(结合语音/图像)
- 零样本意图识别
- 自适应对话管理
- 可解释性增强
建议企业从核心业务场景入手,先建立基准系统,再逐步扩展意图覆盖范围,最终实现全渠道智能客服能力。
