C题 化工厂生产流程的预测和控制
问题背景
在化工厂的生产流程中,往往涉及到多个反应釜、管道和储罐等设备。在流水线上也有每个位置的温度、压力、流量等诸多参数。只有参数处于正常范 围时,最终的产物才是合格的。这些参数很容易受到外部随机因素的干扰,所以需要实时调控。但由于参数众多,测量困难,很多参数想要及时调整并不容易,而且有很多参数之间互相关联,想要确定应当如何调控也是一个不容易解决的问题。所以在化工厂的运营过程中,人们很重视使用数学模型来对生产流程的情况进行推算和预测。理想的状态是我们只测量少数容易测量的变量,如最终产物的成分;只控制少数几个容易控制的参数,如某些原料的输入速率,通过数学模型推知反应链的整体情况并予以适当的控制。
问题分析:
(1)根据已有输入数据,建立数学模型预测输出数据(二氧化硫 SO₂ 和硫化氢 H₂S 的浓度)。
(2)基于已有的数据,预测未来(t+10 到 t+70)的输出数据是否超出阈值(SO₂ > k₁ 或 H₂S > k₂)。
(3)在预测第二问的基础上,进一步准确预测不合格事件的发生时间。
可明确使用回归分析(或机器学习预测模型)和时间序列预测的方法完成上述的三个任务。
问题解答:
数据预处理:
1)数据清洗:检查数据是否存在缺失值、异常值。
2)数据标准化/归一化:消除各变量之间量纲的影响,便于后续模型建立。
3)特征分析:观察数据中各输入变量与输出变量之间的关系,确定变量间的相关性。
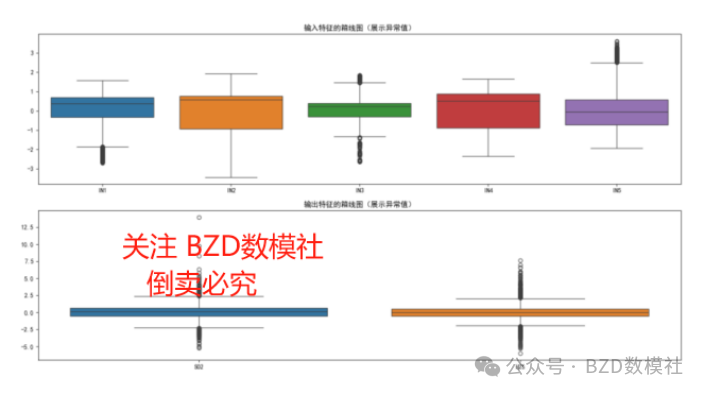
数据清洗是数据预处理的关键步骤,旨在确保数据的完整性和准确性。首先,对数据集进行缺失值检查,统计结果显示所有变量(IN1、IN2、IN3、IN4、IN5、SO2、H2S)的缺失值均为0,表明数据完整,无需填充或删除操作。其次,通过箱线图分析输入和输出特征的异常值分布情况。从图中可见,部分输入特征(如IN1至IN5)和输出特征存在明显的异常值(如数值超出箱体范围或偏离中位数较远)。这些异常值可能由测量误差或数据录入错误导致,若不处理可能影响模型性能。因此,采用IQR(四分位距)法识别并剔除超出1.5倍IQR的异常值,或根据业务需求进行修正。
由于输入变量(IN1至IN5)和输出变量(SO2、H2S)的量纲和数值范围可能存在差异(如箱线图中IN1的数值范围明显大于IN3),直接建模会导致模型对量纲较大的变量过度敏感。因此,采用Z-score标准化方法,将各特征转换为均值为0、标准差为1的分布。公式为:
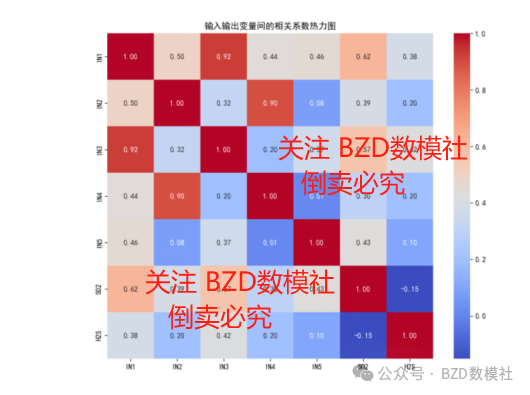
通过相关系数热力图分析输入与输出变量间的相关性。结果显示输入变量中,IN1与IN3的相关系数较高(0.92),可能存在多重共线性,输出变量SO2与IN1、IN3、IN5的相关系数分别为0.62、0.57、0.43,呈现中度正相关,而H2S与IN5的相关系数为-0.15,相关性较弱。通过量化分析特征间的相关性,为后续模型构建中的特征筛选奠定基础。
通过数据清洗、标准化和特征分析,原始数据被转化为高质量、无量纲且相关性明确的建模数据集。这一过程不仅提升了数据的可靠性,还为模型选择与优化提供了科学依据,最终确保预测结果的准确性和可解释性。
问题1分析:建立输入输出预测模型
问题1:假设不考虑反应过程造成的延时,请你建立合理的数学模型,根据从开始直至时刻 t 的输入数据,预测时刻 t 的输出数据。
****问题分析:****问题1关注某化工厂脱硫工艺流程中的污染控制问题。输入端有 5 种原料气体(IN1~IN5),输出端检测二氧化硫(SO₂)和硫化氢(H₂S)浓度。建立回归预测模型,根据原料输入特征,精准预测 SO₂和 H₂S 浓度值,辅助企业调控气流输入,降低污染物浓度。
1、使用输入数据(IN1~IN5)作为特征,输出数据(SO₂, H₂S)作为标签。
2、通过交叉验证(如k-fold cross-validation)选择最佳模型及其参数。
3、评估指标可选择MSE、RMSE、R²等衡量预测准确性。
1、模型构建与优化:
为对比模型性能,我们选择以下三类回归模型:
1)线性回归(Linear Regression):基础线性模型,用于基准对照;
2)随机森林回归(Random Forest Regressor):集成树模型,具备强大的非线性拟合能力;
3)XGBoost 回归(XGBRegressor):基于梯度提升树的增强模型,适合处理复杂结构数据。
超参数优化方面,对于树模型,采用 5 折交叉验证与 GridSearchCV 搜索最优参数。
均方误差(MSE):
|------|---------|--------|--------|------------------------------------------|
| 目标变量 | 模型名称 | MSE | R² | 最优参数 |
| SO2 | 随机森林 | 0.1772 | 0.7880 | {'max_depth': None, 'n_estimators': 150} |
| SO2 | XGBoost | 0.2176 | 0.7396 | {'max_depth': 5, 'n_estimators': 150} |
| SO2 | 线性回归 | 0.4082 | 0.5115 | N/A |
| H2S | 随机森林 | 0.3206 | 0.6085 | {'max_depth': None, 'n_estimators': 150} |
| H2S | XGBoost | 0.3531 | 0.5687 | {'max_depth': 5, 'n_estimators': 150} |
| H2S | 线性回归 | 0.6243 | 0.2375 | N/A |
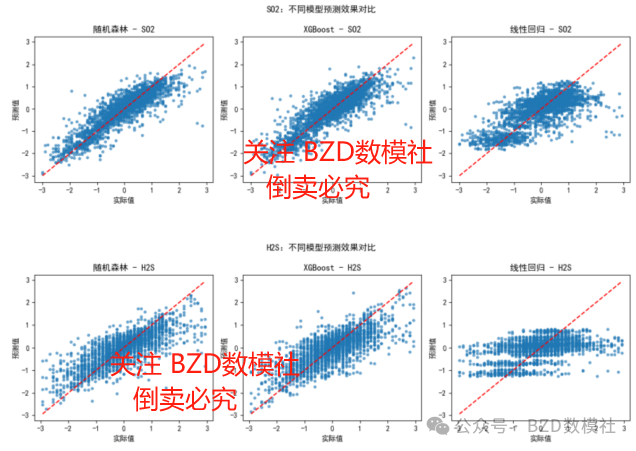
对比每种模型的预测值与实际值之间的拟合效果,随机森林在两个输出变量上拟合度最高;线性模型拟合效果最差,受非线性影响明显;XGBoost 拟合度适中但存在过拟合倾向。
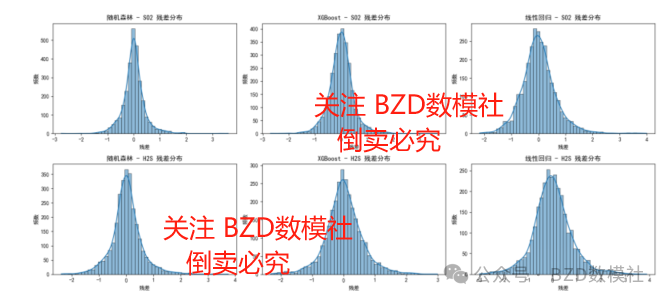
从模型的残差分布图可以看出,随机森林与 XGBoost 的残差接近正态分布,说明模型拟合较稳定,无明显偏差;而线性回归在 SO2 和 H2S 的预测上残差较分散,性能较弱。
预测-实际散点图显示:随机森林与 XGBoost 均能较好地拟合 SO2 和 H2S 的分布趋势,特别是 SO2 的拟合度明显高于 H2S,表明 H2S 的建模难度更大。
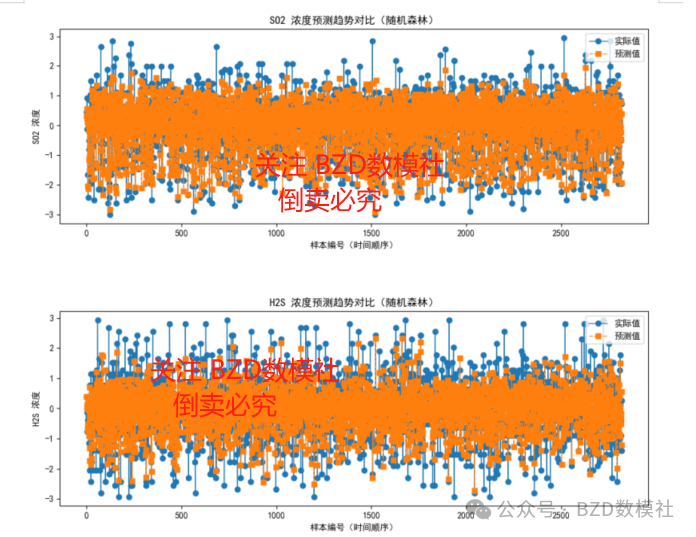
预测趋势图中可以看出,随机森林能够较好地跟踪污染物浓度的变化趋势。
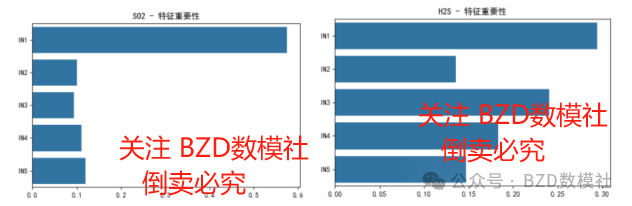
特征重要性图显示:IN1 对 SO2 的影响最为显著,是工艺调控的重要指标。
问题2分析:阈值预测模型构建
问题2:如果输出的二氧化硫的量大于某个阈值k₁或硫化氢的量大于某个阈值k₂,那么输出产物就被视为不合格的。我们希望根据从开始直至时刻t的输入数据和输出数据,预测在t + 10到 t + 70个时间单位之间的输出数据是否会出现不合格的问题。请你建立合理的数学模型完成这项工作,阈值k₁和k₂可以根据模型的性能自行设定,而我们希望在保证预测正确率的前提下,阈值尽可能小。
1、确定阈值k₁与k₂:结合预测模型的性能,迭代寻找能保证准确性且最小的k₁和k₂(可以初始设定为历史数据的某一分位数或最大最小值)。
2、数据构建方法:以t时刻为基准,利用之前的数据特征预测(t+10)到(t+70)的数据。
每条样本特征维度: 70(来自过去 10 个时间步的 IN1~IN5 和 SO2、H2S,共 10×(5+2)),标签定义: 若在未来 t+10 到 t+70 中 SO2 > 0.7 或 H2S > 0.7,则视为"不合格",标签为 1。数据存在明显不平衡(正负样本比例 ≈ 8:1),适合使用支持不平衡分类的模型(如 XGBoost、LightGBM);
