✨ 谁说浏览器不能自动化?
大家好,我是花姐!
前几天加班到半夜,困得不行,但手上还有个网页表单要填,填完才能下班。于是我突然灵光一闪:
"Python 不是万能的吗?干嘛不用它自动填表?" 🤔
于是,我打开 VsCode,摸索了一会儿 Playwright,五分钟后,代码敲好,表单一键填写完毕,我合上电脑,拎包走人。
这感觉,简直爽爆了!😆
所以今天就来聊聊 Playwright ------ 这个比 Selenium 还要快的自动化测试库,让你的浏览器变成听话的小猫咪!
🔍 Playwright 是啥?比 Selenium 强在哪?
Playwright 是微软开源的一款浏览器自动化测试工具,支持 Chrome、Firefox、WebKit(Safari)、Edge ,还能在 无头模式(Headless)运行。
它比 Selenium 更快的原因:
- 原生支持多浏览器(Selenium 需要 WebDriver)
- 默认无头模式(Selenium 需要手动设置)
- 自动等待元素加载 (Selenium 需要
time.sleep()) - 支持 API 测试、手机模拟、下载/上传文件等高级功能
总之,Playwright 适用于 自动化爬取网页、填表、截图、数据抓取、自动化测试 等等。
🛠️ 安装 Playwright(3 秒搞定!)
bash
pip install playwright
playwright install第一个命令装 Playwright,第二个命令下载浏览器内核(不然它没法控制浏览器)。
执行完毕,你的 Python 已经具备让浏览器乖乖听话的能力了!🎉
💻 Hello Playwright!让浏览器跑起来
来看一个最简单的示例,我们用 Playwright 打开百度,然后截图。
python
from playwright.sync_api import sync_playwright
def run():
with sync_playwright() as p:
browser = p.chromium.launch()
page = browser.new_page()
page.goto("https://www.baidu.com")
page.screenshot(path="baidu.png")
browser.close()
run()代码解析:
sync_playwright():启动 Playwright,支持with语法,确保程序结束后资源释放。p.chromium.launch():启动 Chrome(你也可以用p.firefox.launch())。page.goto("https://www.baidu.com"):访问百度。page.screenshot(path="baidu.png"):截图。browser.close():关闭浏览器。
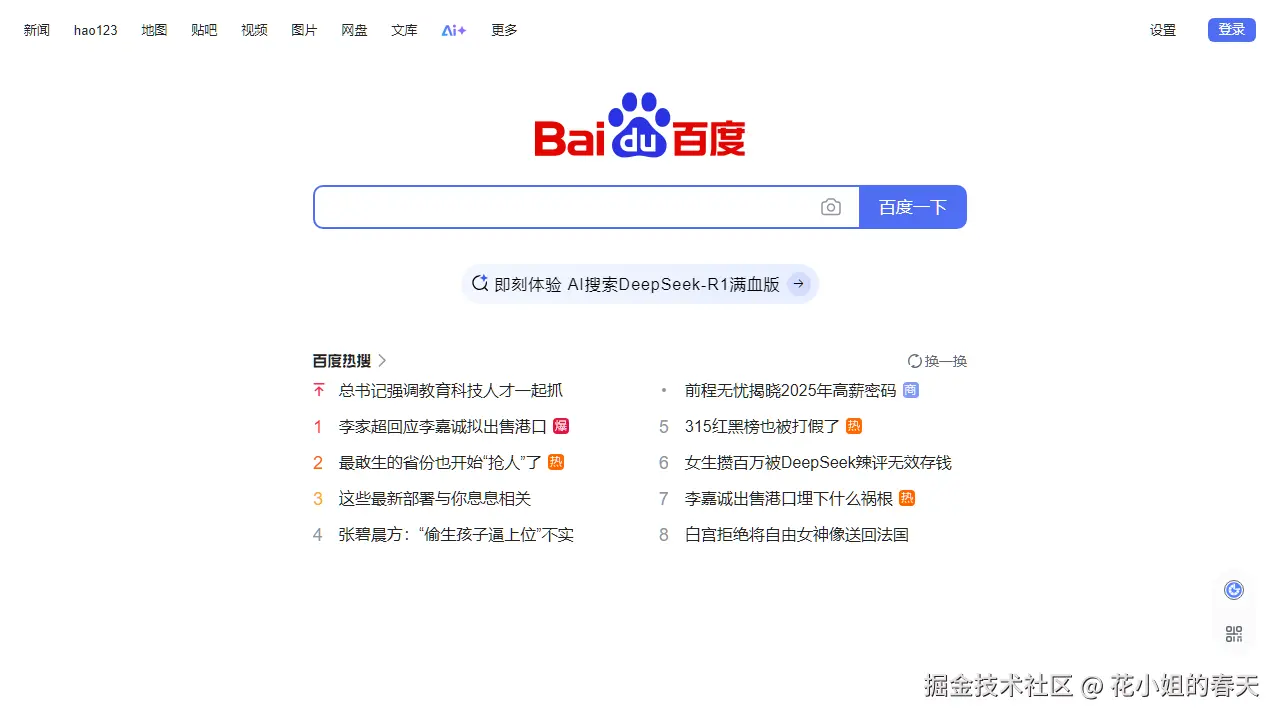
执行完代码,你的项目目录下就会多出一张 baidu.png,打开看看,百度首页是不是静静地躺在那里?
🛏️ 自动化填表(比你手速快 100 倍!)
很多网站的登录页、搜索框、表单都能用 Playwright 轻松搞定,比如打开百度然后输入Python搜索相关内容:
python
from playwright.sync_api import sync_playwright
import time
def run():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto("https://www.baidu.com")
page.fill(".s_ipt", "Python") # 输入Python
page.click("input[type='submit']") # 点击登录按钮
page.screenshot(path="baidu_search.png")
time.sleep(10) # 方便大家查看效果 这里等待10秒
browser.close()
run()代码解析:
page.fill(selector, value):模拟输入框输入,s_ipt是百度网页输入框对应的class名称。page.click(selector):点击按钮。headless=False:让浏览器可见(默认是无头模式)。
执行后,你会看到浏览器自动打开百度,输入Python,然后搜索,整个过程行云流水,堪比黑客电影里的场景!😎
🔄 模拟用户操作(滑动、点击、拖拽)
让 Playwright 模拟用户操作简直太简单了,比如 滚动页面、点击按钮、拖拽元素:
python
page.click("button.submit") # 点击按钮
page.hover("#menu") # 鼠标悬停
page.mouse.wheel(0, 500) # 模拟滚动鼠标(向下滚 500 像素)
page.drag_and_drop("#source", "#target") # 拖拽元素你可以用这个方法自动化 点击广告、滚动页面、拖拽文件,甚至抢购秒杀商品(手动狗头🐶)!
🤔 网页元素如何定位
1. 打开谷歌浏览器
输入目标网站,比如https://www.baidu.com,然后按F12打开开发者工具
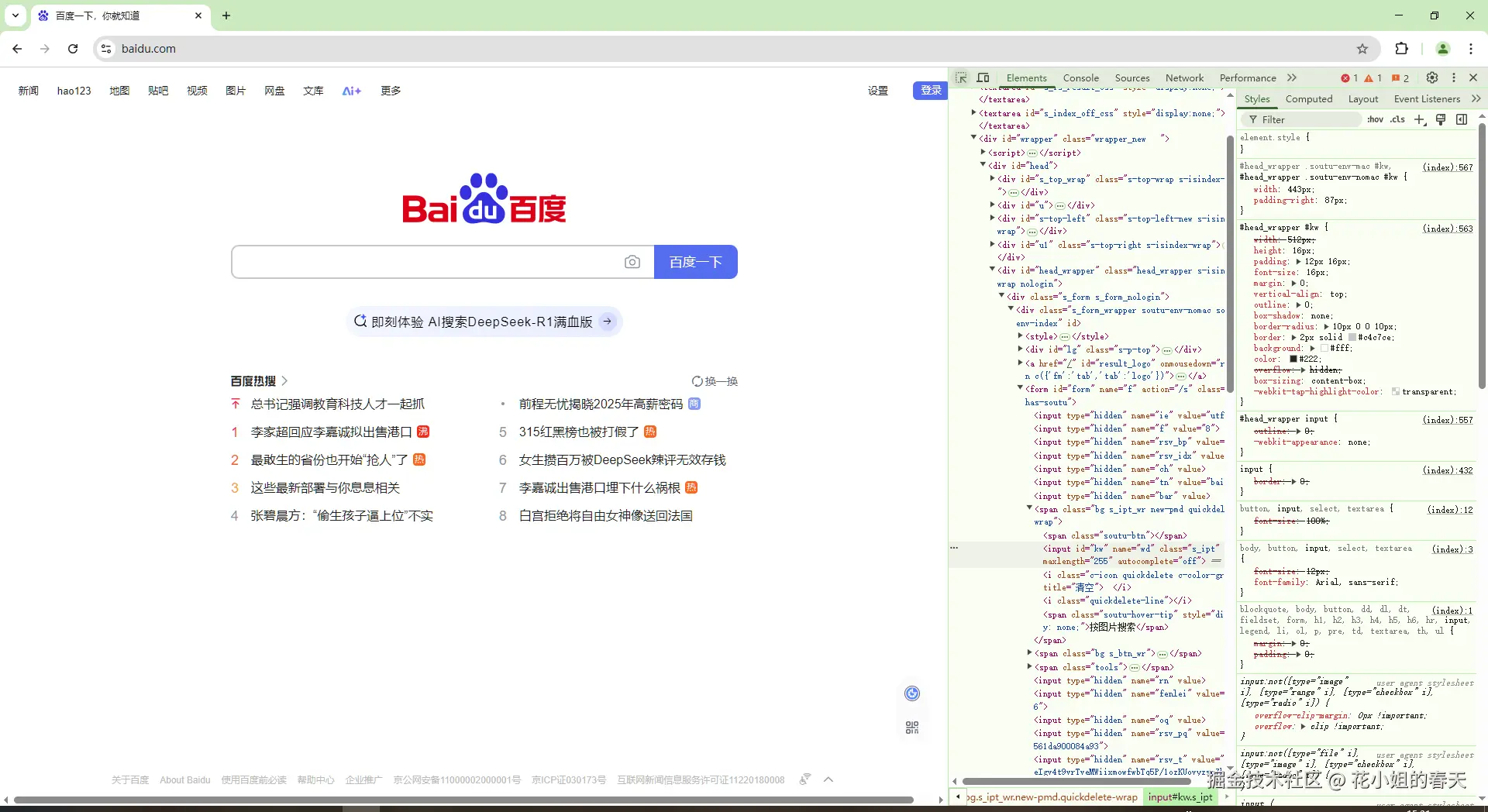
点击红框里的按钮
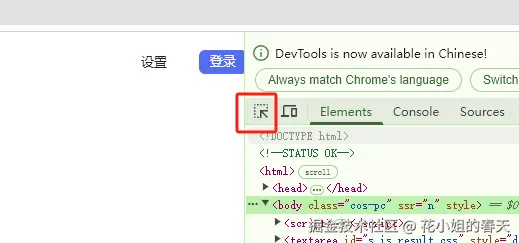
把鼠标放到想查看对应控件的地方,就可以看到控件对应的id、class、类型了。比如我想查看百度输入框控件对应的内容
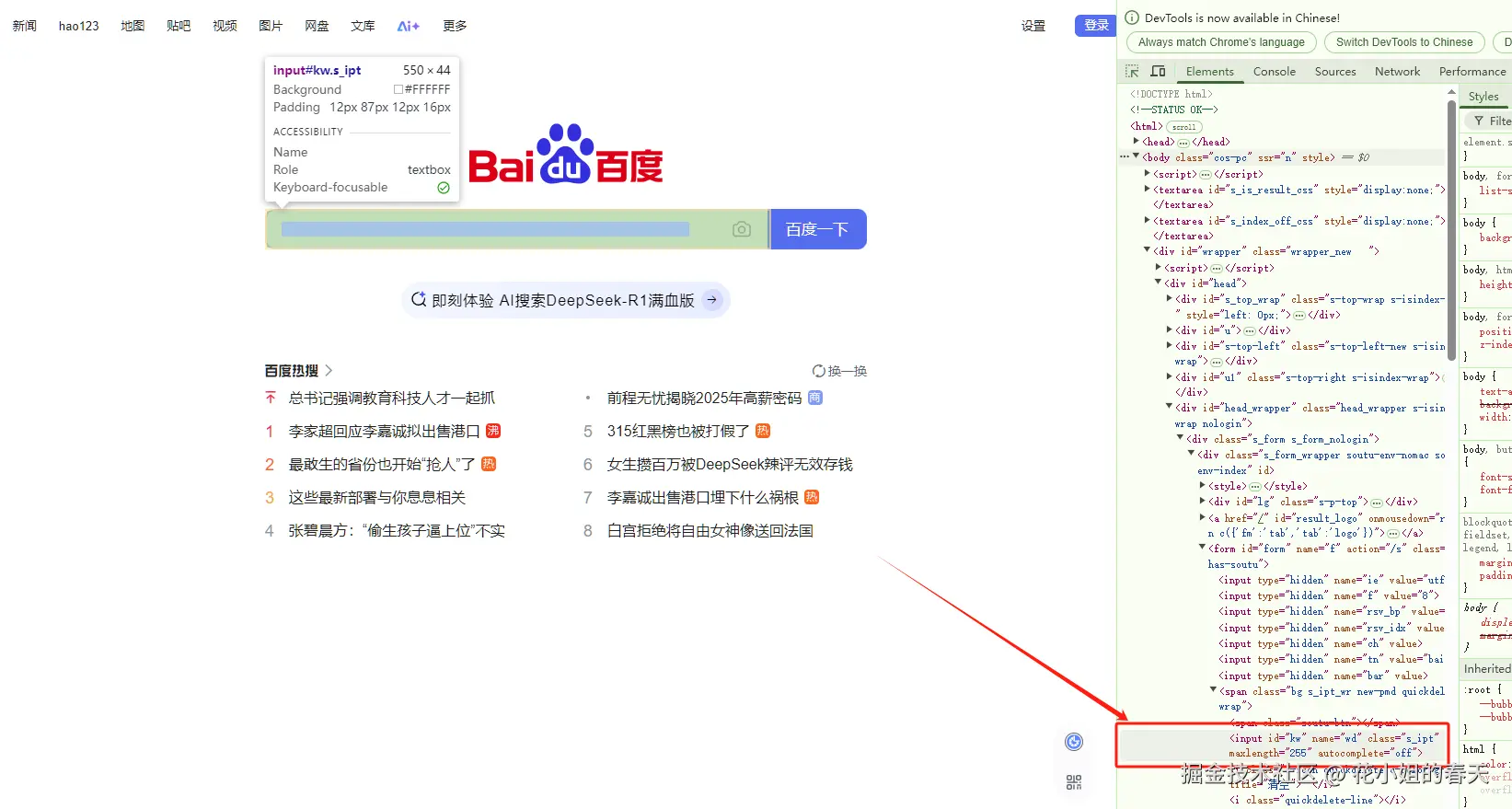
我们可以看到百度输入框对应的类型是input、id是kw,class是s_ipt

2. 撰写规则代码掌控指定控件 ------ 基础定位方法
Playwright 定位元素的核心思想
Playwright 的定位器(Locators)是其自动等待和重试能力的核心,通过智能等待元素加载、重试机制避免因网络延迟或动态渲染导致的定位失败。推荐优先使用语义化定位器(如角色、文本),而非传统 CSS/XPath,以提高代码可读性和稳定性。
2.1. CSS 选择器
通过 HTML 标签、类名、ID 等 CSS 语法定位:
python
# 定位 ID 为 "username" 的输入框
page.locator("#username").fill("admin")
# 定位类名为 "submit-btn" 的按钮
page.locator("button.submit-btn").click()适用场景 :元素有固定 ID/类名,或需层级嵌套选择(如 div > input)。
2.2. XPath 表达式
通过 XML 路径语法定位复杂结构:
python
# 定位 name 属性为 "email" 的输入框
page.locator("//input[@name='email']").fill("test@example.com")
# 定位包含特定文本的按钮
page.locator("//button[contains(text(), '提交')]").click()适用场景:元素属性动态变化、需复杂条件筛选时。
2.3. 按角色定位(Role)
基于 ARIA 角色和可访问性属性,最接近用户感知:
python
# 定位名称为 "登录" 的按钮
page.get_by_role("button", name="登录").click()
# 定位角色为输入框且名称为 "用户名"
page.get_by_role("textbox", name="用户名").fill("user123")支持角色 :button、link、checkbox、heading 等。
2.4. 按文本内容定位
python
# 精确匹配文本
page.get_by_text("欢迎回来").click()
# 正则表达式模糊匹配
page.get_by_text(re.compile(r"订单编号\d+")).hover()适用场景:元素无固定属性,但文本内容稳定。
2.5. 按标签关联定位
python
# 通过关联的 <label> 文本定位输入框
page.get_by_label("密码:").fill("secret")
# 通过占位符定位
page.get_by_placeholder("请输入手机号").type("13800138000")优势:与表单控件天然绑定,避免层级依赖。
2.6. 按测试 ID 定位
专为测试设计的属性,需页面添加 data-testid:
python
# 定位 data-testid="submit-button" 的元素
page.get_by_test_id("submit-button").click()最佳实践:与开发约定唯一测试 ID,提升定位稳定性。
✈️ 动态元素处理技巧
1. 显式等待元素加载
python
# 等待元素可见后再操作
page.locator(".loading").wait_for(state="visible")
# 等待元素消失
page.wait_for_selector(".spinner", state="hidden")2. 处理 iframe 嵌套
python
# 定位到 iframe 内的元素
iframe = page.frame(name="payment-iframe")
iframe.get_by_text("确认支付").click()3. Shadow DOM 穿透
通过 >> 符号穿透 Shadow DOM 层级:
python
page.locator("div#shadow-host >> input.custom-input").fill("data")⛳️ 复杂场景定位策略
1. 多重条件筛选
python
# 定位类名为 "item" 且包含文本 "特价" 的元素
page.locator(".item", has_text="特价").click()
# 组合角色和文本过滤
page.get_by_role("listitem").filter(has_text="待付款").nth(0).click()2. 相对定位
python
# 父子关系定位
parent = page.locator("div.parent")
child = parent.locator("span.child")
# 兄弟元素定位
second_item = page.locator("ul > li").nth(1)3. 动态列表处理
python
# 遍历商品列表并点击第三个商品
items = page.locator(".product-list > li")
await items.nth(2).click()
# 根据文本动态定位最新添加的条目
new_item = page.locator("tr:has-text('2024-03-18')").last🔺 Playwright vs Selenium,选哪个?
| 功能 | Playwright | Selenium |
|---|---|---|
| 速度 | 更快 | 较慢 |
| 多浏览器支持 | 内置 | 需驱动 |
| 无头模式 | 默认支持 | 需手动设置 |
| 等待元素加载 | 自动等待 | 需手动 sleep |
| API 自动化 | 支持 | 不支持 |
| 移动端模拟 | 支持 | 需插件 |
如果你要做 自动化测试、爬虫、网页填表 ,Playwright 绝对是 优选!但如果你的项目已经基于 Selenium,那也没必要急着换。
💪 结语:用 Playwright 解放双手!
学会 Playwright 之后,你会发现世界都不一样了:
- 想自动化登录网站?没问题!
- 想批量爬取网页数据?小意思!
- 想定时打开某个网站?安排!
反正,只要是你手工操作的网页任务,基本都可以用 Playwright 自动化完成。
下期我们将会介绍基于Playwright 的实战项目,爬取https://www.pexels.com/zh-cn/免费素材网站某个用户的图片并保存本地。
顺手点赞 + 在看,就是对花姐最大的支持!❤️