目录
[1.1 布隆过滤器是什么?](#1.1 布隆过滤器是什么?)
[1.2 工作原理](#1.2 工作原理)
[1.3 优点](#1.3 优点)
[1.4 缺点](#1.4 缺点)
[1.5 适用场景](#1.5 适用场景)
[2.1 布谷鸟过滤器是什么?](#2.1 布谷鸟过滤器是什么?)
[2.2 工作原理](#2.2 工作原理)
[2.3 优点](#2.3 优点)
[2.4 缺点](#2.4 缺点)
[2.5 适用场景](#2.5 适用场景)
[三、布隆过滤器 vs 布谷鸟过滤器:谁更适合你?](#三、布隆过滤器 vs 布谷鸟过滤器:谁更适合你?)
在数据结构的世界里,布隆过滤器和布谷鸟过滤器是两种高效且独特的解决方案。它们在处理海量数据时表现出色,但各有优缺点。本文将带你深入了解这两种过滤器的工作原理、适用场景以及它们的优缺点,帮助你选择最适合的工具。
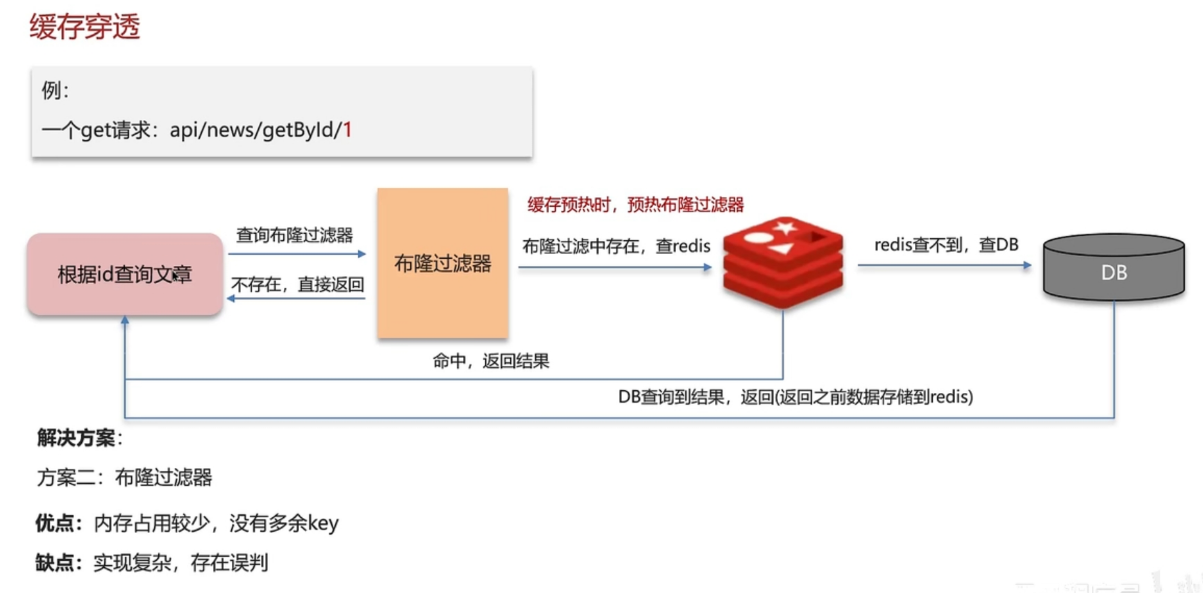
为什么使用过滤器:用于解决缓存穿透,缓存穿透是指查询一个一定不存在的数据,由于存储层查不到数据因此不写入缓存,这将导致这个不存在的数据每次请求都要到 DB 去查询,可能导致 DB 挂掉。这种情况大概率是遭到了攻击。解决方案的话,我们通常都会用布隆过滤器来解决它。如图所示:
一、布隆过滤器:高效的空间节省者
1.1 布隆过滤器是什么?
布隆过滤器是一种基于概率的紧凑型数据结构,由 Burton Howard Bloom 在 1970 年提出。它的核心思想是通过多个哈希函数将数据映射到位图(bitmap)中,从而实现高效的插入和查询操作。
1.2 工作原理
-
插入数据:将数据通过多个哈希函数映射到位图的多个位置,并将这些位置的比特位设置为 1。
-
查询数据:通过相同的哈希函数计算数据的映射位置。如果所有位置的比特位都是 1,则认为数据可能存在;如果有一个位置的比特位是 0,则数据一定不存在。

1.3 优点
-
高效性:插入和查询的时间复杂度均为 O(k),其中 k 是哈希函数的数量。
-
空间节省:相比哈希表或红黑树,布隆过滤器占用的空间更少。
-
支持高并发:哈希函数之间相互独立,适合硬件并行运算。
1.4 缺点
-
误判率:布隆过滤器允许误判,即可能将不存在的数据误判为存在。误判率随着插入数据量的增加而上升。
-
无法删除数据:由于多个数据可能共享同一个比特位,删除一个数据可能会影响其他数据的查询结果。

1.5 适用场景
-
去重:如新闻推荐系统中过滤已阅读的内容。
-
快速判断数据是否存在:如用户名注册时的昵称检查。
-
缓存系统:快速判断数据是否在缓存中。
二、布谷鸟过滤器:解决删除难题的创新者
2.1 布谷鸟过滤器是什么?
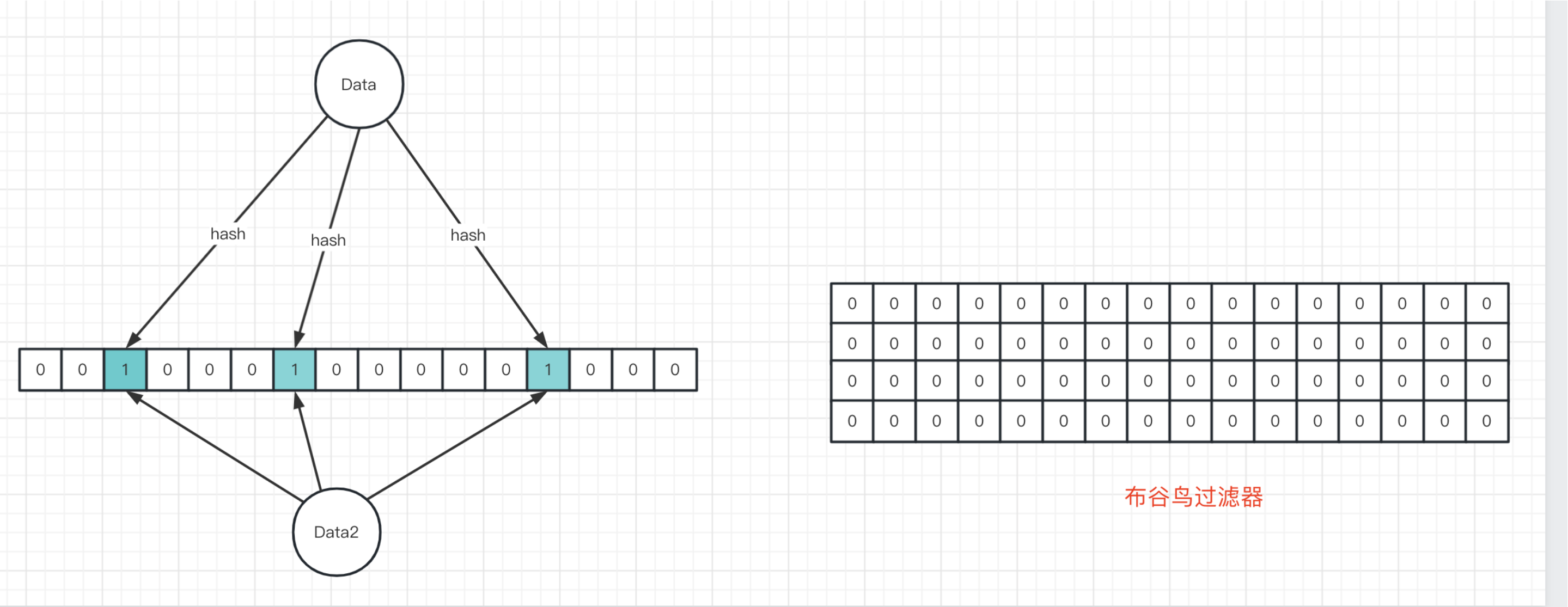
布谷鸟过滤器是布隆过滤器的增强版,由论文《Cuckoo Filter:Better Than Bloom》提出。它通过存储元素的指纹信息(而不是完整的元素)来节省空间,同时支持删除操作。
2.2 工作原理
-
插入数据:使用两个哈希函数计算元素的两个可能位置。如果位置为空,直接插入;如果位置已满,则"鸠占鹊巢",将现有元素挤出并重新计算其位置。
-
查询数据:检查两个哈希位置是否存储了匹配的指纹信息。
-
删除数据:通过指纹信息找到对应的存储位置并移除。
2.3 优点
-
支持删除:解决了布隆过滤器无法删除数据的问题。
-
更高的空间利用率:在相同误判率下,布谷鸟过滤器的空间利用率比布隆过滤器高约 40%。
-
查询性能强:通过优化哈希函数和存储结构,查询性能优于布隆过滤器。
2.4 缺点
-
复杂性:实现比布隆过滤器更复杂,需要处理"鸠占鹊巢"导致的循环挤兑问题。
-
固定长度要求:布谷鸟过滤器要求数组长度必须是 2 的幂次,灵活性稍差。
2.5 适用场景
-
动态系统:如需要频繁插入和删除数据的系统。
-
高空间利用率需求:在内存有限的环境中,布谷鸟过滤器表现更优。
三、布隆过滤器 vs 布谷鸟过滤器:谁更适合你?
| 特性 | 布隆过滤器 | 布谷鸟过滤器 |
|---|---|---|
| 插入和查询效率 | 高效(O(k)) | 高效(O(1)) |
| 空间利用率 | 较低 | 更高(节省约 40%) |
| 支持删除 | 不支持 | 支持 |
| 误判率 | 存在误判 | 存在误判,但通过优化可以降低 |
| 实现复杂度 | 简单 | 较复杂 |
| 适用场景 | 静态数据、去重、缓存 | 动态数据、频繁删除、高空间利用率需求 |
四、总结
布隆过滤器和布谷鸟过滤器各有千秋。如果你的应用场景对删除操作没有需求,且追求简单高效的实现,布隆过滤器是不错的选择。而如果你需要支持删除操作,并且对空间利用率有较高要求,布谷鸟过滤器则更具优势。
在选择时,可以根据实际需求权衡两者的优缺点,找到最适合你的解决方案。希望本文能为你在数据结构的选择上提供一些启发!
如果文章对您有帮助,还请您点赞支持
感谢您的阅读,欢迎您在评论区留言指正分享