作者:Shoufa Chen, Peize Sun, Yibing Song, Ping Luo
论文:https://arxiv.org/pdf/2211.09788v2
代码:https://github.com/ShoufaChen/DiffusionDet
摘要
我们提出了一个新的框架DiffusionDet, 将目标检测构建为从噪声框到目标框的去噪扩散过程。|| 在训练过程中,目标框从真实框扩散到随机分布,模型接下来学习反转这个噪声过程。在推理过程中,该模型以渐进的方式将一组随机生成的框改善为输出结果。|| 本文工作具有非常强的灵活性,可以实现目标框的动态数量和迭代评估。|| 在标准数据集上的大量实验表明,DiffusionDet相比于之前的检测器取得了良好的性能。
1. Introduction
目标检测问题:旨在预测一张图片中目标的一组边界框和关联类别标签。作为一个基础的视觉识别任务,目标检测已成为许多相关识别场景的基石,例如实例分割、姿态估计、动作识别、目标跟踪和视觉关系检测。
已有方法 :现代目标检测方法随着候选目标的发展而演进,例如,从经验对象先验(empirical object priors)到可学习的对象查询(learnable object queries)。|| 具体地,大多数检测器通过定义代理回归和分类来解决检测任务,例如滑动窗口(sliding windows)、区域建议(region proposals)、锚框(anchor boxes)和参考点(reference points)。最近,DETR提出可学习的对象查询以避免手工设计组件,并建立了一个端到端的检测管道,吸引了许多的关注在基于查询的检测范式。
动机提出 :尽管这些方法简答且有效,但他们仍依赖于一组固定的可学习查询。一个自然而言的问题是:有没有一种更简单的方法,甚至不需要可学习查询的替代品(the surrogate of learnable queries)?
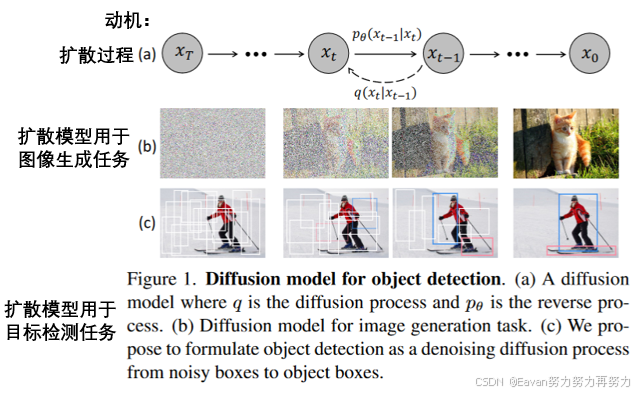
本文方法 :我们通过设计一个新颖的框架来回答该问题,该框架直接从一组随机框中检测对象。从随机框开始,它不包含在训练阶段可学习的参数需要被优化,我们希望逐步优化这些框的位置和大小,指导他们完全地囊括住目标。这种noise-to-box方法既不需要启发式目标先验也不需要可学习的查询,进一步简化目标候选并推动目标检测管道的发展。
具体过程 :DiffusionDet,通过扩散模型处理目标检测任务,将目标检测作为生成式任务投射到图像中边界框的位置和尺寸的空间上。在训练阶段,由方差表(variance shcedule)控制的高斯噪声被添加到GT框中以获得噪声框------>使用这些噪声框从backbone编码器(例如ResNet, Swin Transformer)中裁剪ROI(Region of Interest)区域的特征------>将这些ROI特征送入检测解码器中,该解码器经过训练后可以在没有噪声的情况下预测GT框------>在推理阶段,通过反转学习到的扩散过程生成边界框,该过程将噪声先验分布调整为边界框上学习到的分布。
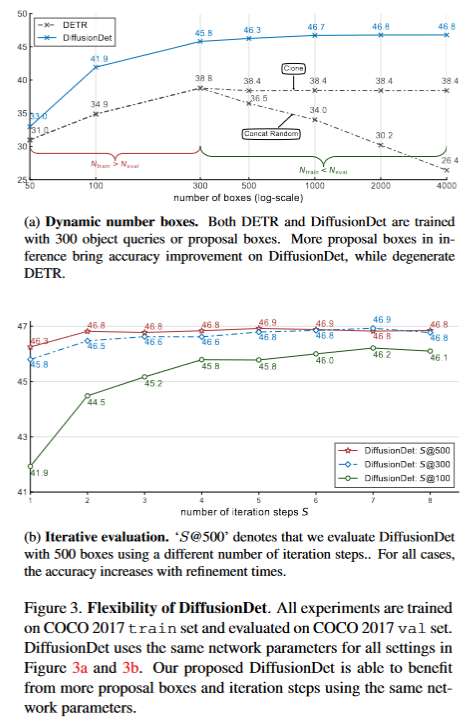
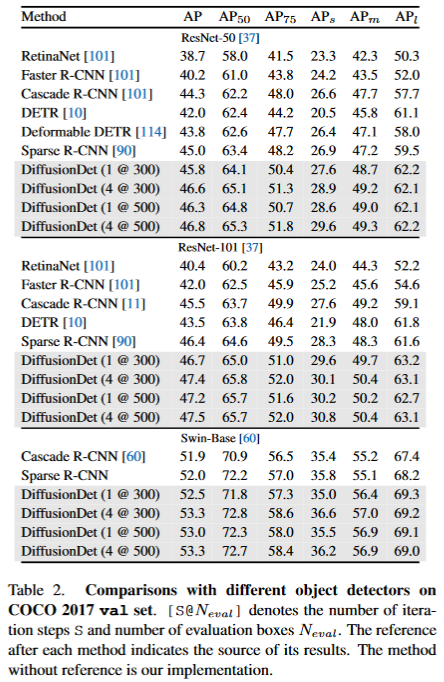
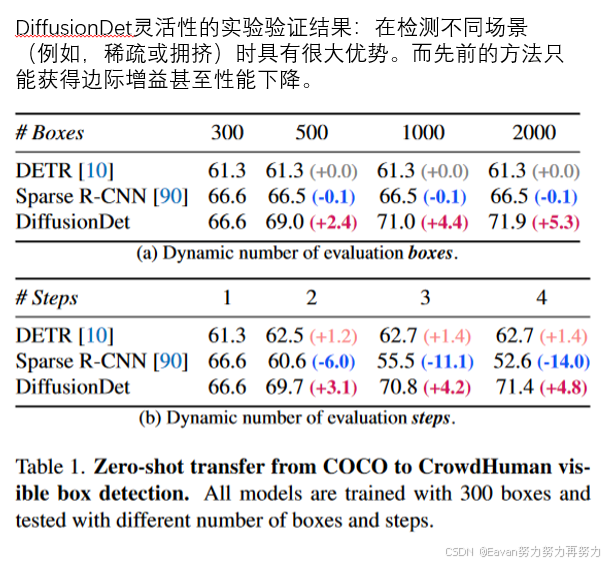
DiffusionDet灵活性说明:作为一个概率模型,DiffusionDet具有很强的灵活性,即可以只训练网络一次,并在不同推理阶段的设置下使用相同的网络参数,主要包括:
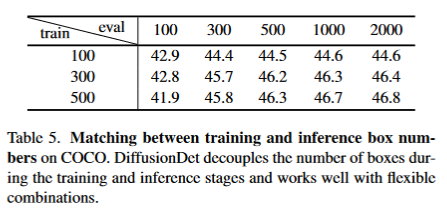
- 动态框数。DiffusionDet将训练和评估过程解耦,即可以利用N_train个随机框训练DiffusionDet,同时使用N_eval个随机框评估,其中N_eval是随机的,可以不等于N_train。
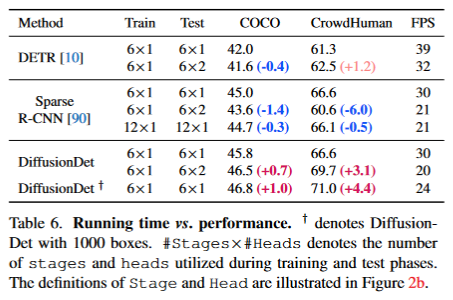
- 迭代评估。得益于扩散模型的迭代降噪特性,DiffusionDet可以以一种迭代的方式重用整个检测头,进一步提升性能。
本文贡献:
- 将目标检测建模为生成式降噪过程(generative denoising process),第一个将扩散模型应用于目标检测的研究;
- noise-to-box检测范式有几个吸引人的特性,例如解耦训练和评估过程;
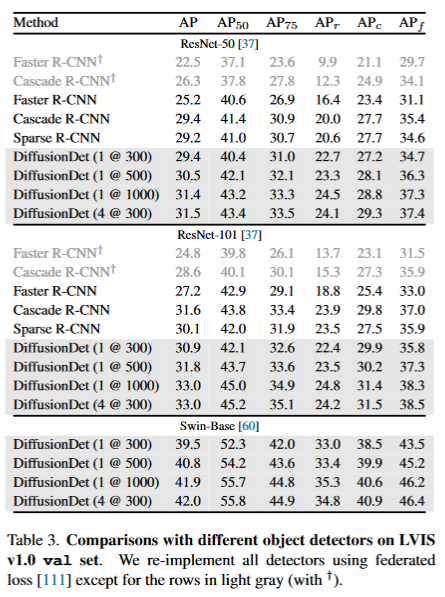
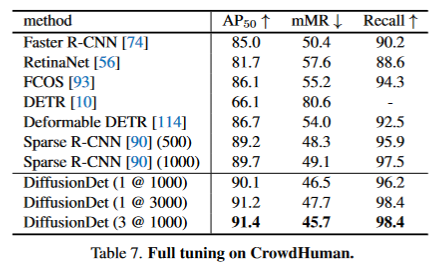
- 在COCO, Crowd-Human, LVIS数据集上,DiffusionDet实现了良好的性能,尤其是在不同场景的zero-shot transferring。
2. Related Work
目标检测.(略)
扩散模型. 作为一类深度生成式模型,扩散模型从随机分布的样本开始,通过逐渐去噪的过程恢复数据样本。扩散模型最近在计算机视觉、自然语言处理、音频处理、图相关主体、跨学科应用等领域取得了显著成果。
扩散模型用于感知任务. 虽然扩散模型在图像生成方法已取得了巨大成功,但它们在判别任务中的潜力尚未得到充分探索。一些先驱工作试图采用扩散模型进行图像分割。然而,尽管大家对这个想法有浓厚的兴趣,但之前还没有成功将生成式扩散模型应用于目标检测中,其进展明显落后于分割任务。我们认为这可能是因为分割任务是以图像-图像的 方式处理,这和图像生成任务的概念更相近,而目标检测是一个集合预测问题,其需要将目标候选分配给GT目标。本文是第一个尝试将扩散模型应用于目标检测。
3. Approach
3.1 Preliminaries

3.2 Architecture
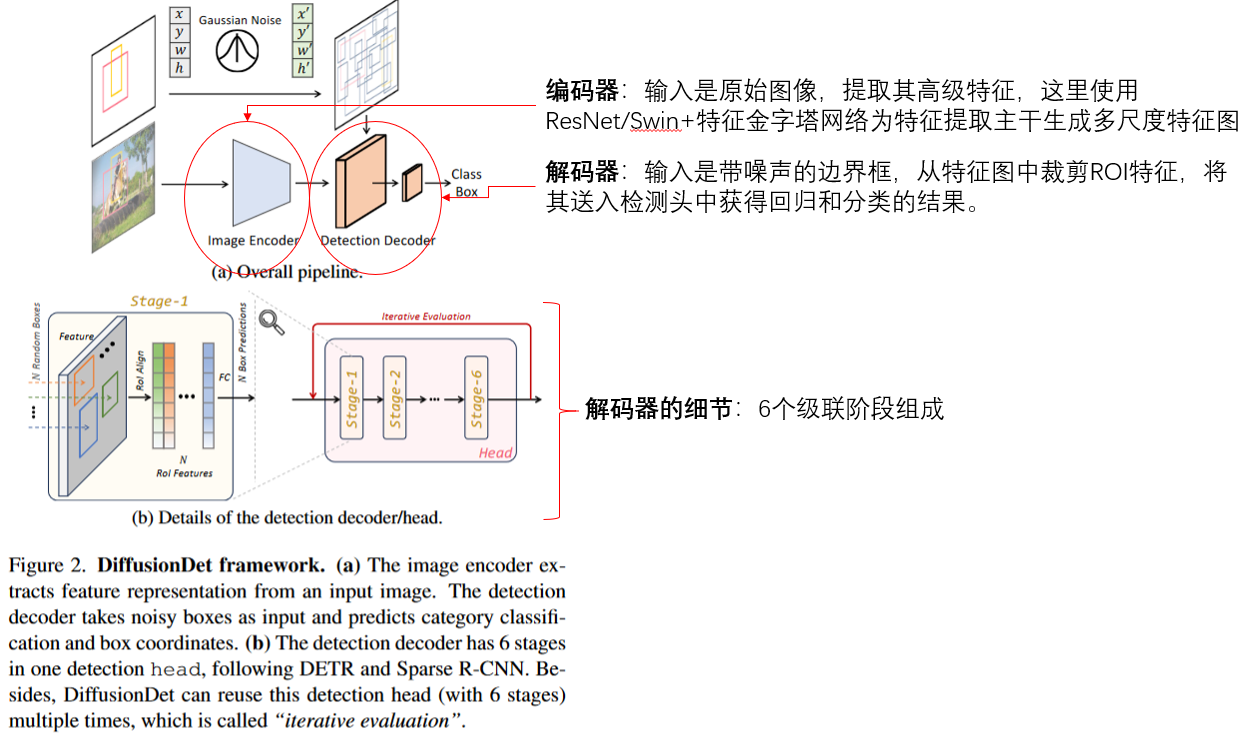
由于扩散模型迭代生成数据样本,需要在推理阶段多次运行模型f_theta(即神经网络)。但是,在每次迭代时都直接将f_theta应用于原始图像上计算会很困难。因此,本文将整个模型分为图像编码器 和检测解码器,前者只运行一次,从原始图像x中提取深度特征表示,后者将深度特征作为条件,逐步从噪声框z_t中改善得到预测框。
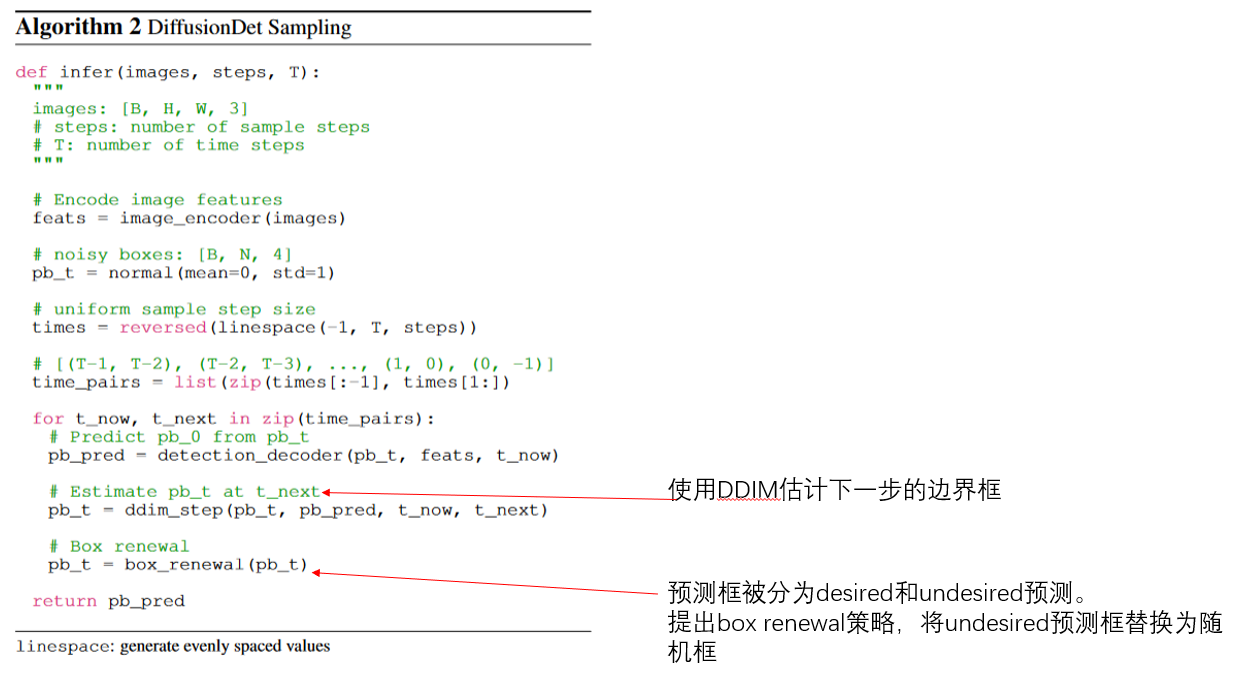
3.3 Training and 3.4 Inference

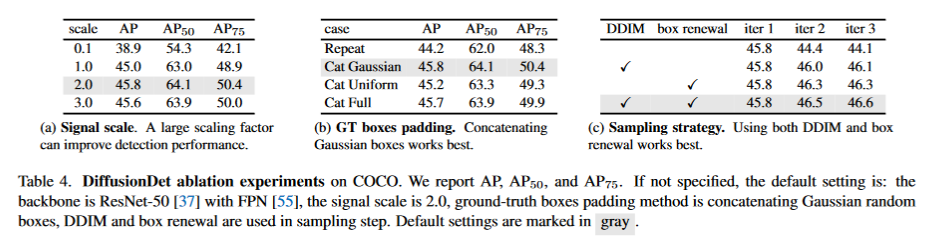
4. Experiments
数据集:COCO、LVIS v1.0、CrowdHuman
实验细节:
- ResNet和Swin主干网分别在ImageNet-1K和ImageNet-21K上使用预训练权重进行初始化;
- 解码器使用Xavier init进行初始化;
- 使用AdamW优化器进行训练,初始学习率2.5x10^-5,权重衰减为10^-4。所有模型都在8个GPUS上以mini-batch size为16进行训练。
- 默认的训练schedule为450K iterations,在350K和420K次迭代时,学习率除以10。
- 数据增强:随机水平翻转、调整输入图像大小的缩放抖动、随机裁剪增强。
- 测试阶段:每个采样步骤的预测由NMS集成在一起,以获得最终预测。