
Transformers 提供了数以千计的预训练模型,支持 100 多种语言的文本分类、信息抽取、问答、摘要、翻译、文本生成。它的宗旨是让NLP 技术人易用。
Transformers 提供了便于快速下载和使用的API,可以把预训练模型用在给定文本、在自己的数据集上微调然后,通过 model hub 与社区共享。同时,每个定义的 Python 模块都是完全独立的,便于修改和快速进行研究实验。
Transformers支持三个最热门的深度学习库: Jax, PyTorch 以及 TensorFlow ,并与之无缝整合。可以直接使用一个框架训练模型,然后用另一个加载和推理。
目录
[为什么要用 transformers?](#为什么要用 transformers?)
[什么情况下我不该用 transformers?](#什么情况下我不该用 transformers?)
在线演示
可以直接在模型页面上测试大多数 model hub 上的模型。
提供了 私有模型托管、模型版本管理以及推理API。
这里是一些例子:
Write With Transformer,由Hugging Face团队打造,是一个文本生成的官方 demo。
快速上手
为快速使用模型提供了 pipeline (流水线)API。流水线聚合了预训练模型和对应的文本预处理。下面是一个快速使用流水线去判断正负面情绪的例子:
python
>>> from transformers import pipeline
# 使用情绪分析流水线
>>> classifier = pipeline('sentiment-analysis')
>>> classifier('We are very happy to introduce pipeline to the transformers repository.')
[{'label': 'POSITIVE', 'score': 0.9996980428695679}]第二行代码下载并缓存了流水线使用的预训练模型 ,而第三行代码则在给定的文本上进行了评估。这里的答案"正面" (positive) 具有 99 的置信度。
许多的 NLP 任务都有开箱即用的预训练流水线。比如说,可以轻松的从给定文本中抽取问题答案:
python
>>> from transformers import pipeline
# 使用问答流水线
>>> question_answerer = pipeline('question-answering')
>>> question_answerer({
... 'question': 'What is the name of the repository ?',
... 'context': 'Pipeline has been included in the huggingface/transformers repository'
... })
{'score': 0.30970096588134766, 'start': 34, 'end': 58, 'answer': 'huggingface/transformers'}除了给出答案,预训练模型还给出了对应的置信度分数、答案在词符化 (tokenized) 后的文本中开始和结束的位置。可以从这个教程了解更多流水线API支持的任务。
要在自己的任务上下载和使用任意预训练模型也很简单,只需三行代码。这里是 PyTorch 版的示例:
python
>>> from transformers import AutoTokenizer, AutoModel
>>> tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-uncased")
>>> model = AutoModel.from_pretrained("google-bert/bert-base-uncased")
>>> inputs = tokenizer("Hello world!", return_tensors="pt")
>>> outputs = model(**inputs)这里是等效的 TensorFlow 代码:
python
>>> from transformers import AutoTokenizer, TFAutoModel
>>> tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-uncased")
>>> model = TFAutoModel.from_pretrained("google-bert/bert-base-uncased")
>>> inputs = tokenizer("Hello world!", return_tensors="tf")
>>> outputs = model(**inputs)词符化器 (tokenizer) 为所有的预训练模型提供了预处理,并可以直接对单个字符串进行调用(比如上面的例子)或对列表 (list) 调用。它会输出一个可以在下游代码里使用或直接通过 ** 解包表达式传给模型的词典 (dict)。
模型本身是一个常规的 ++++Pytorch++++ ++++nn.Module++++ 或 TensorFlow tf.keras.Model,可以常规方式使用。 这个教程解释了如何将这样的模型整合到经典的 PyTorch 或 TensorFlow 训练循环中,或是如何使用 Trainer 训练器API 来在一个新的数据集上快速微调。
为什么要用 transformers?
1便于使用的先进模型:
NLU 和 NLG 上表现优越
对教学和实践友好且低门槛
高级抽象,只需了解三个类
对所有模型统一的API
2 更低计算开销:
研究人员可以分享已训练的模型而非每次从头开始训练
工程师可以减少计算用时和生产环境开销
数十种模型架构、两千多个预训练模型、100多种语言支持
3 对于模型生命周期的每一个部分都面面俱到:
训练先进的模型,只需 3 行代码
模型在不同深度学习框架间任意转移,随你心意
为训练、评估和生产选择最适合的框架,衔接无缝
4 为你的需求轻松定制专属模型和用例:
为每种模型架构提供了多个用例来复现原论文结果
模型内部结构保持透明一致
模型文件可单独使用,方便魔改和快速实验
什么情况下我不该用 transformers?
本库并不是模块化的神经网络工具箱。模型文件中的代码特意呈若璞玉,未经额外抽象封装,以便研究人员快速迭代魔改而不致溺于抽象和文件跳转之中。
Trainer API 并非兼容任何模型,只为本库之模型优化。若是在寻找适用于通用机器学习的训练循环实现,请另觅他库。
尽管已尽力而为,examples 目录中的脚本也仅为用例而已。对于特定问题,它们并不一定开箱即用,可能需要改几行代码以适之。
安装
使用 pip
这个仓库已在 Python 3.9+、Flax 0.4.1+、PyTorch 2.0+ 和 TensorFlow 2.6+ 下经过测试。
可以在虚拟环境中安装Transformers, 如果还不熟悉 Python 的虚拟环境,请阅此用户说明。
首先,用打算使用的版本的 Python 创建一个虚拟环境并激活。
然后,需要安装 Flax、PyTorch 或 TensorFlow 其中之一。关于在使用的平台上安装这些框架,请参阅 TensorFlow 安装页, [++++PyTorch 安装页++++](#PyTorch 安装页) 或 [++++Flax 安装页++++](#Flax 安装页)。
当这些后端之一安装成功后, Transformers 可依此安装:
python
pip install transformers如果想要试试用例或者想在正式发布前使用最新的开发中代码,++++从源代码安装++++。
使用 conda
python
conda install conda-forge::transformers笔记: 从 huggingface 渠道安装 transformers 已被废弃。
要通过 conda 安装 Flax、PyTorch 或 TensorFlow 其中之一,请参阅它们各自安装页的说明。
模型架构
所有的模型检查点由用户和组织上传,均与 huggingface.co model hub 无缝整合。目前的数量: 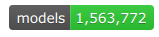
Transformers 目前支持如下的架构: 模型概述请阅这里.
要检查某个模型是否已有 Flax、PyTorch 或 TensorFlow 的实现,或其是否在Tokenizers 库中有对应词符化器(tokenizer),参阅++++此表++++。
这些实现均已于多个数据集测试(请参看用例脚本)并应于原版实现表现相当。可以在用例文档的此节中了解表现的细节。
更多
| 章节 | 描述 |
|---|---|
| 文档 | 完整的 API 文档和教程 |
| 任务总结 | 🤗 Transformers 支持的任务 |
| 预处理教程 | 使用 Tokenizer 来为模型准备数据 |
| 训练和微调 | 在 PyTorch/TensorFlow 的训练循环或 Trainer API 中使用 🤗 Transformers 提供的模型 |
| 快速上手:微调和用例脚本 | 为各种任务提供的用例脚本 |
| 模型分享和上传 | 和社区上传和分享你微调的模型 |
| 迁移 | 从 pytorch-transformers 或 pytorch-pretrained-bert 迁移到 🤗 Transformers |
论文:论文
至此,本文的内容就结束啦。