RAG挑战赛是什么?
任务是基于企业年报构建问答系统。比赛日的流程简而言之:
- 解析阶段:获得100份随机企业的年报(PDF格式,每份最多1000页),限时2.5小时完成解析并构建数据库。
- 问答阶段:系统需在最短时间内回答100道根据模板生成的随机问题。
所有问题必须有明确答案类型,例如:
- 是/非题;
- 公司名称(或多选情况);
- 管理层职位、新产品名称;
- 数值指标:营收、门店数量等。
每个答案必须附带证据页码,确保系统真实检索而非杜撰。
冠军系统架构:
伊利亚·莱斯揭秘了他构建最佳RAG系统并在企业RAG挑战赛中夺冠的独门秘籍。他包揽了所有奖项类别和SotA排行榜的双料冠军。源代码。
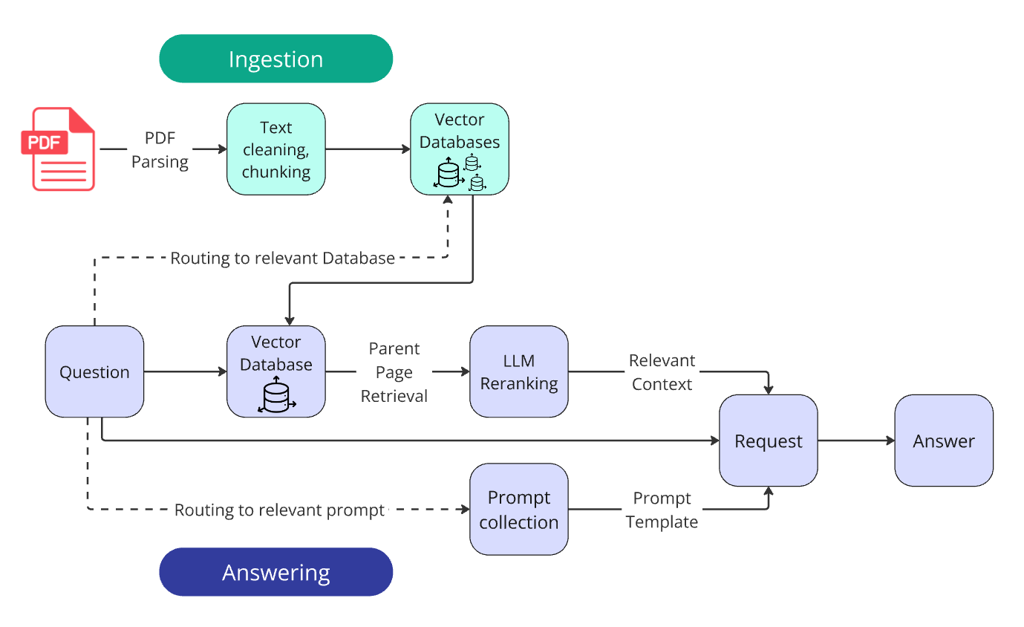
除了基础流程,获胜方案还包含两个路由器和LLM重排序模块
完整问答示例可查看这里。
接下来将详细拆解系统构建的每一步,包括踩过的坑和发现的最佳实践。
RAG极速入门
RAG(检索增强生成)通过将大语言模型(LLM)与任意规模的知识库结合,扩展了LLM的能力边界。
基础RAG系统开发流程:
- 解析:将原始文档转换为文本并清洗噪声。
- 入库:构建并填充知识库。
- 检索:根据查询定位相关数据,通常采用向量数据库的语义搜索。
- 生成:用检索结果增强用户提问,通过LLM生成最终答案。
1. 解析:与PDF的搏斗
将PDF转为纯文本是个充满陷阱的战场:
- 保留表格结构
- 维护标题/列表等关键格式
- 识别多栏文本
- 处理图表/图像/公式/页眉页脚等
遇到的奇葩PDF问题(未解决版):
- 90度旋转的表格 :解析后变成天书
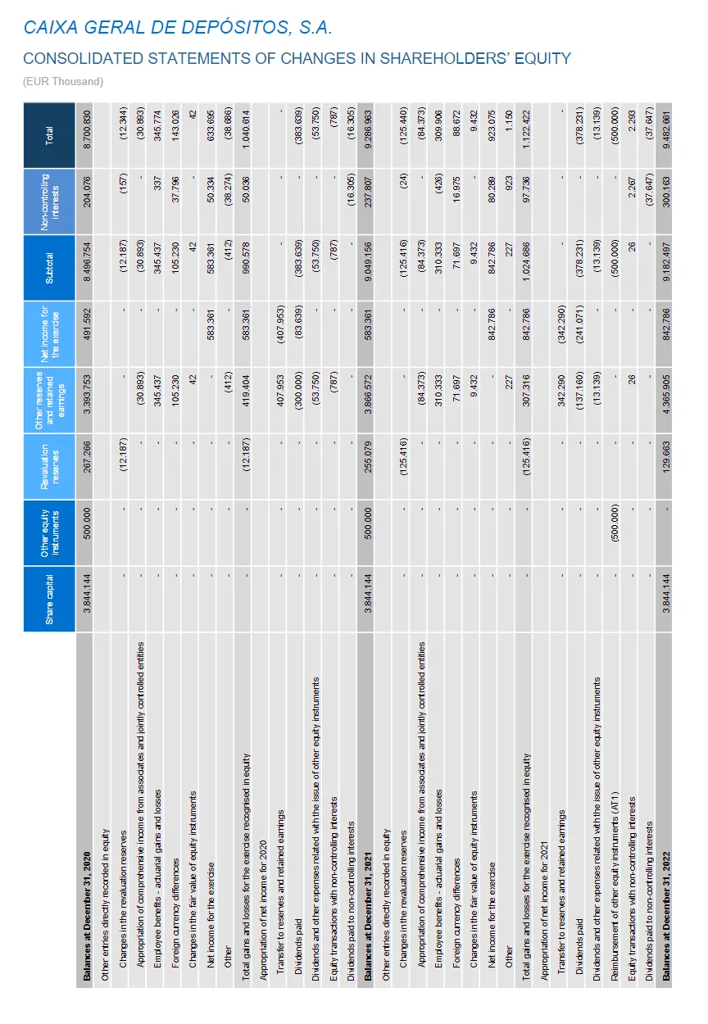
- 图文混合的图表:文字层和图片层打架
- 字体编码陷阱 :肉眼可见但复制即乱码
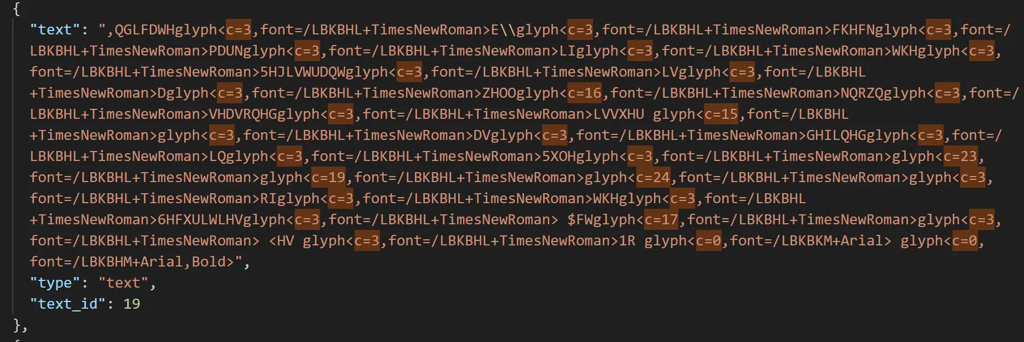
趣味发现:部分乱码实为凯撒密码,每个单词的ASCII位移量不同。这是防抄袭还是转换事故?至今成谜。
解析器选型
测试了二十余种解析器后,IBM开发的Docling脱颖而出。但仍需魔改源码:
- 新增JSON元数据输出
- 支持MD/HTML格式表格转换
- 通过GPU加速(租用4090显卡云服务器,每小时0.7美元)
最终40分钟解析15万页,速度碾压其他选手。
2. 入库:知识库的诞生
分块策略
- 原始方案:整页作为块(约2000词)
- 优化方案:300词分块+50词重叠(语义相关性提升30%)
- 每个块记录元数据:ID+父页码
向量化
- 数据库:100个独立FAISS库(每企业对应一个)
- 索引类型:
IndexFlatIP(暴力搜索保证精度) - 嵌入模型:
text-embedding-3-large
3. 检索:寻找圣杯的旅程
混合搜索(弃用)
向量搜索+BM25关键词搜索的合体技,但效果不如预期。
重排序三选一
- 交叉编码器:精度高但速度慢(Jina Reranker表现佳)
- LLM重排序 :GPT-4o-mini打分,性价比之王
- 提示词模板:点击查看
- 父页面检索:先定位相关块,再返回整页内容
最终方案组合拳:
- 向量搜索Top30块
- LLM重排序(权重0.7)
- 返回Top10完整页面
4. 生成:提示词的艺术
路由策略
- 企业路由:用正则匹配问题中的公司名,秒级定位对应数据库
- 问题类型路由:根据答案类型(数值/布尔/列表等)动态选择提示词模板
复合问题处理
示例问题:"苹果和微软谁的营收更高?"
- 拆解为:"苹果的营收?"+"微软的营收?"
- 分别检索后比较
思维链(CoT)的精髓
通过结构化输出强制LLM分步推理:
javascript
class AnswerSchema(BaseModel):
step_by_step_analysis: str # 详细推理过程
reasoning_summary: str # 结论摘要
relevant_pages: List[int] # 证据页码
final_answer: Union[str, int, float] # 严格格式化答案提示词打磨心法
- 为每种问题类型定制指令(例如数值必须去除货币符号)
- 包含单样本示例(示范完美回答格式)
- 通过200+次迭代优化措辞
5. 性能与意外发现
速度
- 全量100问仅需2分钟(利用OpenAI的TPM限速阈值)
- 批处理25问/请求
反直觉结论
- 表格序列化:虽酷炫但降低效果(干净表格无需额外处理)
- 小模型潜力:Llama 8B击败80%参赛者
6. 终极秘籍
冠军系统的魔法不在某个"银弹",而在于:
- 深度理解问题:手动标注验证集200+问题
- 模块化设计:每个组件可单独调参测试
- 细节偏执:从PDF解析到提示词标点皆有规范
伊利亚开放了完整源码