1 什么是Yarn?
Yarn(Yet Another Resource Negotiator) 是Hadoop生态系统中的资源管理和调度框架,负责为上层应用提供统一的资源管理和调度服务。 是Hadoop 2.0引入的重要架构改进,成为Hadoop集群的资源管理层,使得Hadoop能够支持更多样化的计算框架,而不仅仅是MapReduce。
2 Yarn的核心组件
YARN (Yet Another Resource Negotiator) 作为Hadoop 2.0引入的资源管理系统,其架构由几个关键组件组成,共同协作完成集群资源管理和任务调度功能。
2.1 ResourceManager (RM) - 资源总管
核心职责:
- 全局资源管理和调度
- 处理客户端请求
- 监控集群资源使用情况
主要子组件:- Scheduler(调度器)
- ApplicationsManager(应用管理器)
关键特性:- 支持高可用(Active/Standby架构)
- 通过ZooKeeper实现故障转移
- 处理所有NodeManager的心跳信息
2.2 NodeManager (NM) - 节点代理
核心职责:
- 单节点资源管理和任务执行代理
- 向RM注册并定期发送心跳
- 管理本节点的Container生命周期
主要功能:- 资源隔离:使用Linux cgroups或Docker实现CPU隔离;内存隔离通过监控和强制kill实现
- 本地化服务:管理分布式缓存,确保任务所需文件本地化
- 健康监控:磁盘健康检查、节点健康状况报告
2.3 ApplicationMaster (AM) - 应用管家
核心特点:
- 每个应用一个独立实例(MapReduce/Spark等各有实现)
- 运行在Container中
- 与具体计算框架紧密相关
主要职责:- 资源协商
- 任务调度
- 容错处理
- 进度报告
2.4 Container - 资源容器
核心概念:
- YARN的资源抽象单元
- 由RM调度器分配
- 由NM监控和执行
资源维度:- 内存:
- 最小分配单位可配置(默认1GB)
- 超过限制会被NM强制终止
- CPU:
- 使用虚拟核(vCore)概念
- 支持分数核分配(如0.5个vCore)
- 其他资源:
- 磁盘I/O带宽
- 网络带宽
- GPU等异构资源
生命周期:- 由AM通过RPC向RM申请
- RM分配后返回Container令牌
- AM与目标NM通信启动Container
- 任务完成后由AM或NM释放
3 Yarn的工作流程
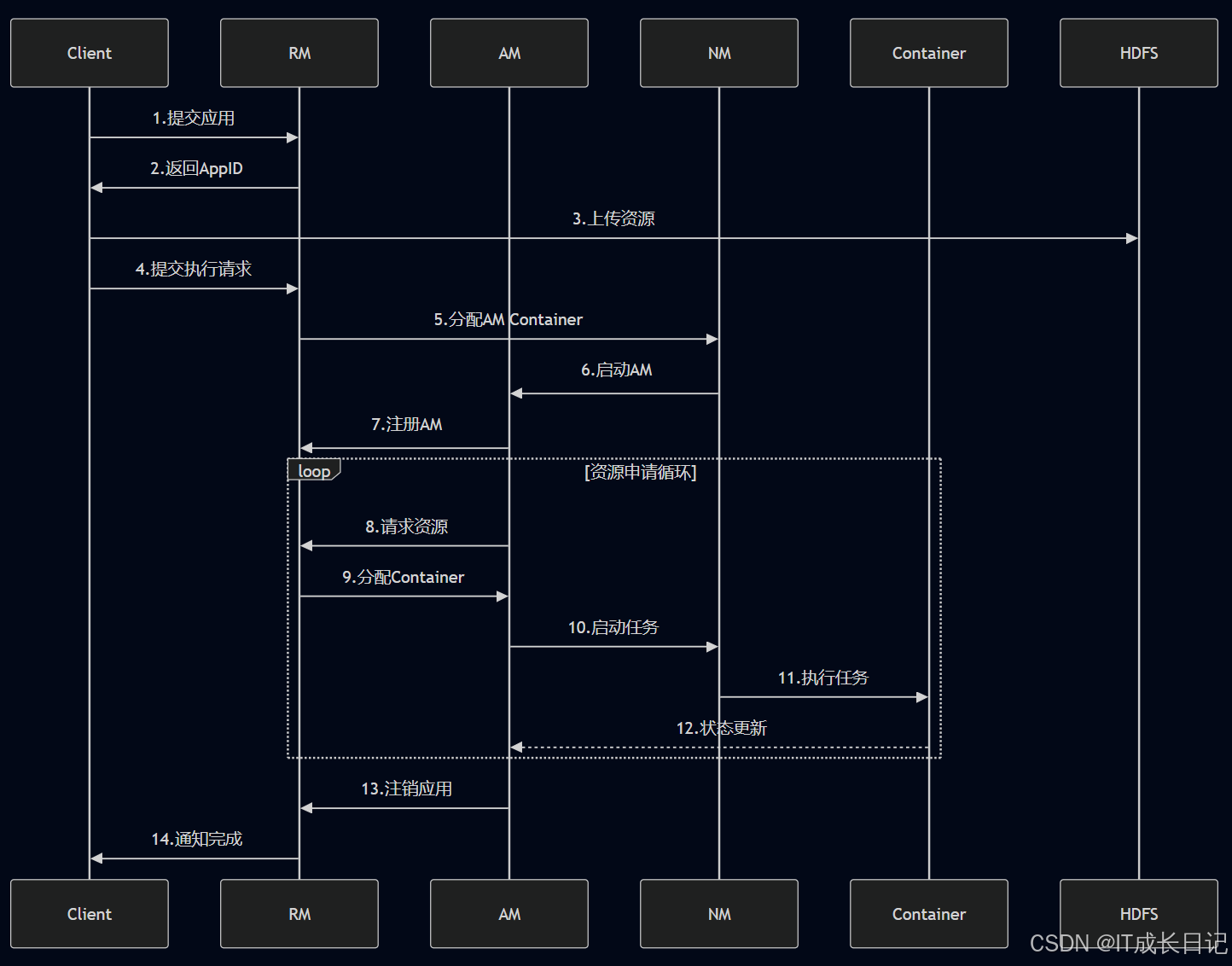
3.1 作业提交阶
1. 客户端提交应用
- 用户通过yarn jar命令或API提交应用程序
- ResourceManager(RM) 的ApplicationsManager接收提交请求
- RM 返回一个Application ID和资源提交路径
2. 资源拷贝- 客户端将应用所需资源(JAR 文件、配置文件等)上传到HDFS
- 包括:应用JAR包、依赖库、配置文件、分布式缓存文件
3. 应用注册- 客户端向RM提交应用执行请求
- RM将应用加入调度队列
3.2 ApplicationMaster启动阶段
1. 调度首个Container
- RM的调度器(Scheduler)为该应用分配第一个Container
- 这个Container专门用于运行ApplicationMaster(AM)
- 分配考虑因素:队列资源配额、用户资源限制、节点资源可用性
2. NodeManager启动AM- RM与目标 NodeManager(NM)通信
- NM在分配的Container中启动AM进程
3. AM向RM注册- AM启动后向RM注册
- 建立RPC通信通道
- 报告AM的跟踪URL和RPC端口
3.3 资源申请与分配阶段
1. AM资源请求
- AM根据应用需求计算所需资源
- 向RM发送 **资源请求(ResourceRequest),**请求包含:优先级(Priority)、资源量(内存/CPU)、数据本地化偏好
2. RM资源分配- RM的调度器处理资源请求
- 根据调度策略(Capacity/Fair/FIFO)分配资源
- 返回Container分配列表给AM
3. AM二次调度- AM收到分配的Container列表
- 根据数据本地化优化任务分配
- 可能拆分大任务为多个小任务
3.4 任务执行阶段
1. AM启动任务Container
- AM与对应NM通信
- 在每个分配的Container中启动任务
2. 任务执行与监控- NM监控Container的资源使用
- AM通过心跳机制监控任务状态
- 关键监控指标:任务进度(Progress)、资源使用量、任务健康状态
3. 状态报告- AM定期向RM报告应用状态
- 客户端可以通过RM或直接向AM查询状态
3.5 作业完成阶段
1. AM注销
- 所有任务完成后,AM向RM发送完成信号
- 释放所有占用的资源
- 记录最终应用状态(SUCCEEDED/FAILED/KILLED)
2. 清理工作- RM清理应用记录
- NM清理工作目录
- 可选保留中间结果
4 Yarn的特点与优势
4.1 核心特点
资源管理与作业调度分离:
- 将传统的 JobTracker 功能拆分为:
- ResourceManager:全局资源管理
- ApplicationMaster:应用级任务调度
- 架构解耦带来更好的扩展性和灵活性
多租户支持:- 通过队列(Queue)实现资源隔离
- 支持容量保证(Capacity Guarantees)
- 提供公平资源分配(Fair Sharing)
多框架支持:- 不仅支持 MapReduce
- 可运行 Spark、Flink、Tez 等计算框架
- 通过 ApplicationMaster 接口实现框架可插拔
层级化调度:- 支持多级资源分配策略
- 典型层次:队列 → 应用 → 容器
4.2 技术优势
高可扩展性:
- 支持10000+节点集群
- 可管理10000+并发容器
- 每日处理百万级作业
高资源利用率:- 细粒度资源分配(CPU/Memory/GPU等)
- 动态资源分配(运行时调整)
- 资源共享(避免资源孤岛)
高可用性:- ResourceManager HA 机制
- 应用失败自动恢复
- 支持应用保存点(Savepoint)
灵活的调度策略:- 内置调度器:CapacityScheduler(生产环境首选)、FairScheduler(研发环境常用)
- 支持自定义调度器插件
5 Yarn的应用场景
- 批处理作业:支持MapReduce等批处理框架,处理大规模的历史数据
- 实时计算:支持Spark Streaming、Flink等实时计算框架,处理实时数据流
- 交互式查询:支持Hive on Tez、Impala等交互式查询框架,提供低延迟的查询服务
- 图计算:支持Giraph等图计算框架,处理大规模的图数据
6 总结
Yarn作为Hadoop生态系统中的资源管理和调度框架,为上层应用提供了统一的资源管理和调度服务。通过ResourceManager、NodeManager、ApplicationMaster和Container等核心组件的协同工作,Yarn实现了资源的高效利用和任务的灵活调度。其资源隔离、高扩展性、高可用性和灵活性等特点,使得Yarn在批处理作业、实时计算、交互式查询和图计算等场景中发挥着重要作用。通过学习和使用Yarn,用户可以更加高效地管理和调度Hadoop集群的资源,提升数据处理和分析的效率。