**全文链接:**https://tecdat.cn/?p=41501
**分析师:**Rui Liu
在当今数字化浪潮席卷的时代,电商市场的蓬勃发展犹如一部波澜壮阔的史诗,蕴藏着无尽的商业价值与潜力。电商平台积累的海量数据,宛如一座等待挖掘的宝藏,其中蕴含着消费者行为、市场趋势等宝贵信息。如何运用先进的数据分析技术从这些数据中提取有价值的见解,成为电商从业者和数据科学家们共同关注的焦点**(** 点击文末"阅读原文"获取完整代码、数据、文档******** )。
本专题合集围绕电商数据展开了深入而全面的分析,综合运用了 Python 和 R 语言,结合多种数据分析方法和模型,涵盖了销售预测、评论主题分类、用户行为建模以及虚假评论识别等多个关键领域。在销售预测方面,我们采用 XGBOOST 算法,结合随机森林进行数据预处理,精准预测电商平台的月销售额,为商家的运营决策提供有力支持。评论主题分类则借助 NLTK、决策树、KNN 算法和多项式朴素贝叶斯等,对用户评论进行细致分类,洞察消费者的喜好与反馈。用户行为建模部分,创新性地引入时间感知注意力网络模型,充分考虑用户行为的时间动态变化,实现更精准的用户推荐。而在虚假评论识别中,运用改进的 K - means 聚类算法,结合层次聚类和文本挖掘技术,有效识别出虚假电商评论,维护市场的公平与健康。
本专题合集不仅提供了详细的算法原理和实现步骤,还附有丰富的代码示例(注明:附数据代码),具有很强的实践指导意义。无论是数据科学初学者,还是经验丰富的专业人士,都能从中获得新的启发和思路。专题合集已分享在交流社群,阅读原文进群和 500 + 行业人士共同交流和成长,一起探索电商数据背后的奥秘,为电商行业的发展贡献智慧与力量。
Python用XGBOOST、NLTK、对电商平台数据分析:销售预测、评论主题分类及时间感知注意力网络创新推荐模型
在当今时代,电商市场的发展可谓日新月异。想象一下,电商就像一片广阔的海洋,其中蕴含着无数的商机和奥秘。商家们就像勇敢的航海者,渴望探索这片海洋的基本规律,预测未来的风向,找到潜在的宝藏------也就是潜在的客户群体。那么,如何高效地发掘电商市场的基本规律,如年月销售量、增长率、季度与失业率之间的关系呢?又如何通过多种机器学习算法,像朴素贝叶斯、神经网络等,预测各商店未来一年的销售量呢?同时,怎样对用户根据潜在特征进行分类,探索长短期消费记录与用户个性的关联性,实现效果较优的个性推荐算法功能,这些都是电商领域亟待解决的技术难题。
解决方案
任务/目标
本次项目主要聚焦于三个方面:XGBOOST电商平台月销售预测、销售评论主题分类以及用户推荐算法。这就像是一个电商运营的"组合拳",通过这三个方面的分析和预测,帮助商家更好地了解市场和用户。
数据源准备
我们从电商平台获取了相关的数据源。在拿到数据后,就像拿到了一堆杂乱的拼图,我们需要对其进行整理。首先,剔除了其中的负值和缺失值,因为这些数据就像是拼图中的残片,会影响我们最终的画面。然后,使用随机森林算法填补缺失值,让数据更加完整。同时,考察了数据的极大极小值,进行异常值处理,根据平均值和方差考虑值的异常情况,就像把拼图中不符合整体画面的部分调整好。
AI提示词:请提供一个Python脚本,从电商平台获取数据源,剔除负值和缺失值,使用随机森林填补缺失值,并处理异常值。
go
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
# 读取数据
data = pd.read\_csv('ecommerce\_data.csv')
# 剔除负值和缺失值
data = data\[(data >= 0).all(1)\].dropna()
# 划分特征和目标变量
X = data.drop('target_column', axis=1)
y = data\['target_column'\]
# 使用随机森林填补缺失值
rf = RandomForestRegressor()
rf.fit(X, y)
data = data.fillna(rf.predict(X))
# 异常值处理
mean = data.mean()
std = data.std()
data = data\[(data - mean).abs() <= 3 * std\]特征转换
接下来,我们把数据按照时间序列进行组织,就像把拼图按照一定的顺序排列起来。构造了周交易数据、月交易数据、季度交易数据和年交易数据,然后绘制图像观察各因子的时间序列图。通过这些图像,我们可以直观地看到数据随时间的变化趋势,就像看到了拼图逐渐呈现出的画面。
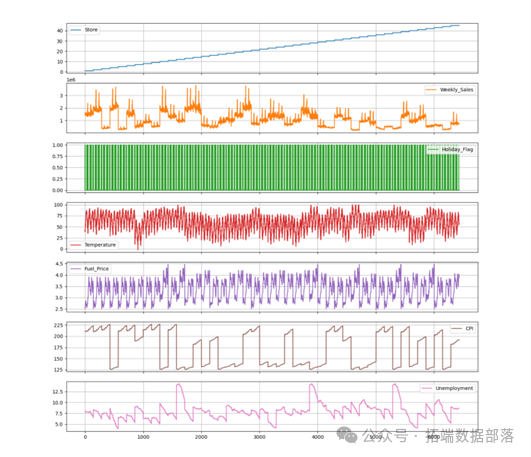
AI提示词:请提供一个Python脚本,将电商数据按照时间序列组织,构造周、月、季度和年交易数据,并绘制时间序列图。
go
import pandas as pd
import matplotlib.pyplot as plt
# 假设数据已经读取为data
data\['date'\] = pd.to_datetime(data\['date'\])
data.set_index('date', inplace=True)
# 构造周、月、季度和年交易数据
weekly_data = data.resample('W').sum()
monthly_data = data.resample('M').sum()
quarterly_data = data.resample('Q').sum()
yearly_data = data.resample('Y').sum()
# 绘制时间序列图
plt.figure(figsize=(12, 8))
plt.subplot(2, 2, 1)
plt.show()构造
在抽取相关特征后,我们得到了一些训练样本。这些样本就像是拼图中的关键部分,包含了我们需要的重要信息。
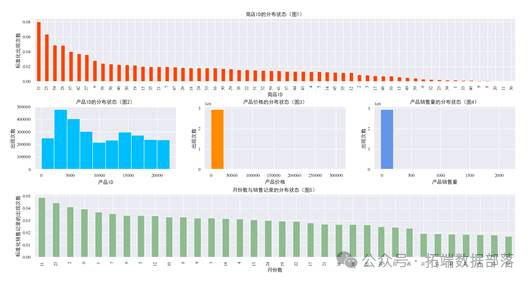
我们还绘制了直方图来观察各因子的分布状态,这有助于我们了解数据的特征,就像更仔细地观察拼图的每一块。
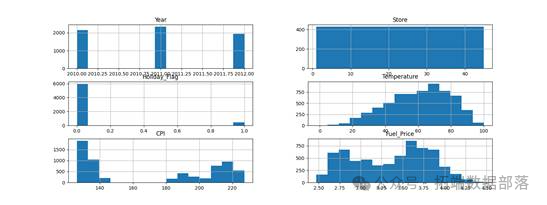
AI提示词:请提供一个Python脚本,绘制电商数据各因子的直方图。
go
import pandas as pd
import matplotlib.pyplot as plt
# 假设数据已经读取为data
data.hist(figsize=(12, 8))
plt.show()划分训练集和测试集
对数据按照月份统计销售额,我们共有33个月的销售额数据。我们以小于33周的数据集作为训练数据,第33周数据作为验证数据,第34周数据作为预测数据,也就是测试集,并提取对应特征。这就像是把拼图分成了不同的部分,一部分用来学习如何拼,一部分用来检查拼得对不对,还有一部分用来预测未来的拼图样子。
AI提示词:请提供一个Python脚本,将电商销售额数据按照月份统计,划分训练集、验证集和测试集,并提取对应特征。
go
import pandas as pd
from sklearn.model\_selection import train\_test_split
# 假设数据已经读取为data
data\['month'\] = data\['date'\].dt.to_period('M')
monthly_sales = data.groupby('month')\['sales'\].sum()
# 划分训练集、验证集和测试集
train\_data = monthly\_sales\[:-2\]
val\_data = monthly\_sales\[-2:-1\]
test\_data = monthly\_sales\[-1:\]
# 提取特征
train\_features = train\_data.index.astype(str).tolist()
train\_labels = train\_data.values.tolist()
val\_features = val\_data.index.astype(str).tolist()
val\_labels = val\_data.values.tolist()
test\_features = test\_data.index.astype(str).tolist()建模:使用XGBOOST进行销售预测
我们使用XGBOOST算法进行销售预测。XGBOOST就像是一个聪明的助手,能够帮助我们根据历史数据预测未来的销售额。
AI提示词:请提供一个Python脚本,使用XGBOOST算法进行电商销售预测,设置模型参数并进行训练。
go
from xgboost import XGBRegressor
# 设定模型参数
model = XGBRegressor(
n_estimators=3000,
max_depth=10,
colsample_bytree=0.5,
subsample=0.5,
learning_rate=0.01
)
# 进行模型训练,并设置早停函数
model.fit(train\_features, train\_labels,
eval_metric="rmse",
eval\_set=\[(train\_features, train\_labels), (val\_features, val_labels)\],
verbose=True,
early\_stopping\_rounds=50)最后,我们导出了预测结果。
模型二、评论数据的主题分类
在电商平台上,用户的评论就像是一面镜子,反映了产品的优缺点和用户的喜好。我们考虑了电商产品评论语料库中的6000个文本文档,其中75%(4500)的文档用于培训目的,其余的25%(1500)个数据用于测试系统的性能。每一篇评论都被注释为六个主题类型类别(书籍、相机、DVD、健康状况、音乐、软件)中的一个。
评论数据处理
首先,我们使用NLTK词干提取器接口提取评论文本词干,这就像是把评论中的单词还原到最基本的形式。然后,使用NLTK词形还原器进行正则化处理,删除终止词、停用词等,让评论更加简洁明了。最后,使用sklearn中的CountVectorizer和TfidfVectorizer类提取评论文本特征(矢量化),把文本数据转化为可以被机器学习算法处理的形式。
AI提示词:请提供一个Python脚本,使用NLTK词干提取器和词形还原器处理电商评论文本,并使用sklearn提取文本特征。
go
import nltk
from nltk.stem import PorterStemmer, WordNetLemmatizer
from nltk.tokenize import word_tokenize
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
nltk.download('punkt')
nltk.download('wordnet')
# 词干提取
stemmer = PorterStemmer()
roots = \[stemmer.stem(plural) for plural in doc\]
# 词形还原
wnl = WordNetLemmatizer()
lemmatized\_text = \[wnl.lemmatize(t) for t in word\_tokenize(doc)\]
# 提取文本特征
count_vectorizer = CountVectorizer()
tfidf_vectorizer = TfidfVectorizer()
count\_features = count\_vectorizer.fit\_transform(lemmatized\_text)
tfidf\_features = tfidf\_vectorizer.fit\_transform(lemmatized\_text)不同算法的应用
我们使用了决策树、KNN算法和多项式朴素贝叶斯等不同的算法对评论数据进行分类。
AI提示词:请提供一个Python脚本,使用决策树、KNN算法和多项式朴素贝叶斯对电商评论数据进行分类。
go
from sklearn.pipeline import Pipeline
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import MultinomialNB
# 决策树
classifier\_dt = Pipeline(\[('vec', count\_vectorizer), ('cls', DecisionTreeClassifier())\])
classifier\_dt.fit(train\_features, train_labels)
# 单值的KNN分类
classifier\_knn\_single = Pipeline(\[('vec', count\_vectorizer), ('cls', KNeighborsClassifier(n\_neighbors=15))\])
classifier\_knn\_single.fit(train\_features, train\_labels)
# 不同k值的KNN分类
for k in range(1, 20):
classifier\_knn = Pipeline(\[('vec', count\_vectorizer), ('cls', KNeighborsClassifier(n_neighbors=k))\])
classifier\_knn.fit(train\_features, train_labels)
# 多项式朴素贝叶斯
classifier\_nb = Pipeline(\[('vec', count\_vectorizer), ('cls', MultinomialNB())\])
classifier\_nb.fit(train\_features, train_labels)不同K值下准确率和召回率的曲线可以帮助我们选择最合适的K值。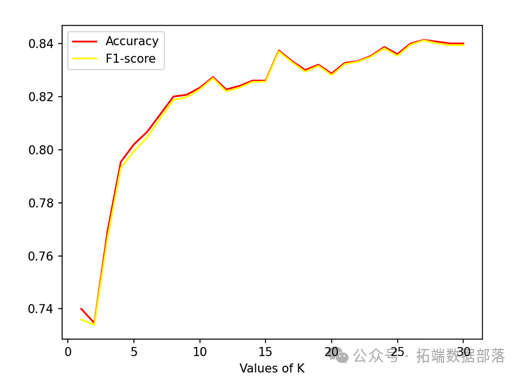
算法比较
我们对这三种算法的耗时和分类结果进行了比较。
| NB | DT | KNN | |
|---|---|---|---|
| TRAINING(S) | 0.906 | 3.914 | 0.789 |
| TESTING(S) | 0.215 | 0.208 | 1.015 |
| Model | Accuracy | Precision | Recall |
| --- | --- | --- | --- |
| DT | 0.788 | 0.794 | 0.788 |
| NB | 0.918 | 0.920 | 0.918 |
从这些结果中我们可以看出,不同算法在不同方面有不同的表现。多项式朴素贝叶斯在准确率和召回率方面表现较好,而KNN算法在训练速度方面相对较快。
模型三:时间感知注意力网络模型
现有的推荐模型一般使用贝叶斯、协同过滤、深度神经网络等算法。这些算法虽然可以进行用户类别划分,但用户类别往往随着时间动态变化。长期的时间类别可以表征用户的性格、习惯、消费水平等特质,短期的时间类别则可以表征用户的短期喜好和效用,而且短期特征对预测下期结果可能比潜在的长期特征更有时效性。因此,我们构造了具有时间感知注意力的网络模型。
模型假设
不同时间位置的行为记录对预测/推荐任务有不同的贡献。这就像是在不同的时间点,用户的行为对我们了解他们的喜好有着不同的重要性。
模型核心
特征注意层使用长期层来捕捉用户的长期偏好,采用短期层来强调用户的短期兴趣。就像我们既要了解用户的长期喜好,也要关注他们当前的兴趣。
算法步骤
-
针对同一用户id,按照时间序列处理用户的交易数据。
-
根据时间长短,将时间序列划分为长期和短期行为记录。
-
长期和短期特征注意层:构建长期特征注意层来捕获用户的长期偏好,构建短期特征注意层,结合长期偏好和短期利益获得当前的偏好。
网络训练
用训练集中所有用户的行为记录来训练模型,然后预测测试集中的标签。我们选用交叉熵损失函数进行优化。
损失函数:−∑_u,j((log(σ(f(u,s)))+(1−y)log(1−σ(f(u,s)))+λ||θ||^2
输入:L:长期行为参数,S:短期行为参数,α:学习率,df:特征数,λ:L2正则化参数
输出:最优模型参数
控制台返回结果图示如下:
代码实践
-
构造网络参数

-
训练模型参数
-
运行模型

算法比较
我们对该模型的召回率、正确率和训练速度进行了比较。
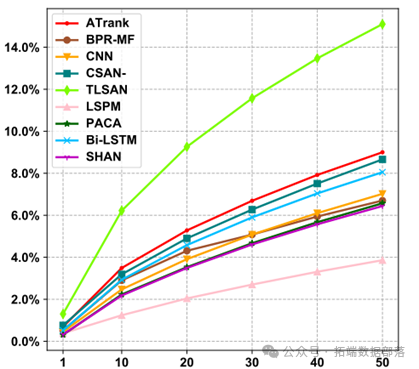
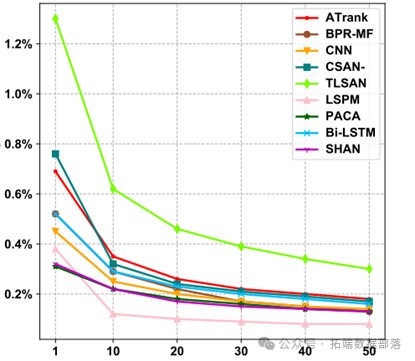
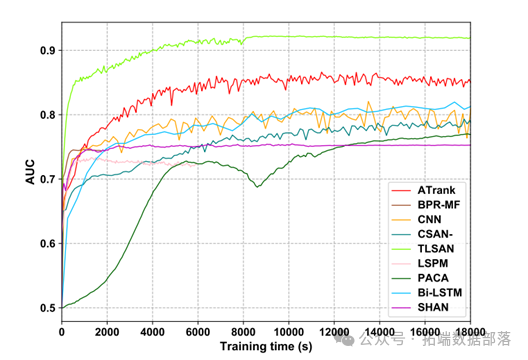
通过这些比较,我们可以评估该模型在不同方面的性能,为电商平台的推荐系统提供更好的支持。
综上所述,通过对电商市场数据的分析和预测,以及对评论数据的主题分类和时间感知注意力网络模型的应用,我们可以更好地了解电商市场的规律,预测销售情况,对用户进行分类,实现更精准的个性推荐,为电商商家的决策提供有力的支持。在这个电商的海洋中,我们就像拥有了一张精准的地图,能够更准确地驶向成功的彼岸。
R语言LASSO特征选择、决策树CART算法和CHAID算法电商网站购物行为预测分析|附数据代码
本文通过分析电子商务平台的用户购物行为,帮助客户构建了一个基于决策树模型的用户购物行为预测分析模型**(** 点击文末"阅读原文"获取完整代码数据******** )。
该模型可以帮助企业预测用户的购物意愿、购物频率及购买金额等重要指标,为企业制定更有针对性的营销策略提供参考。
数据来源和处理
本研究所使用的数据来自某电子商务平台的用户购物历史记录。
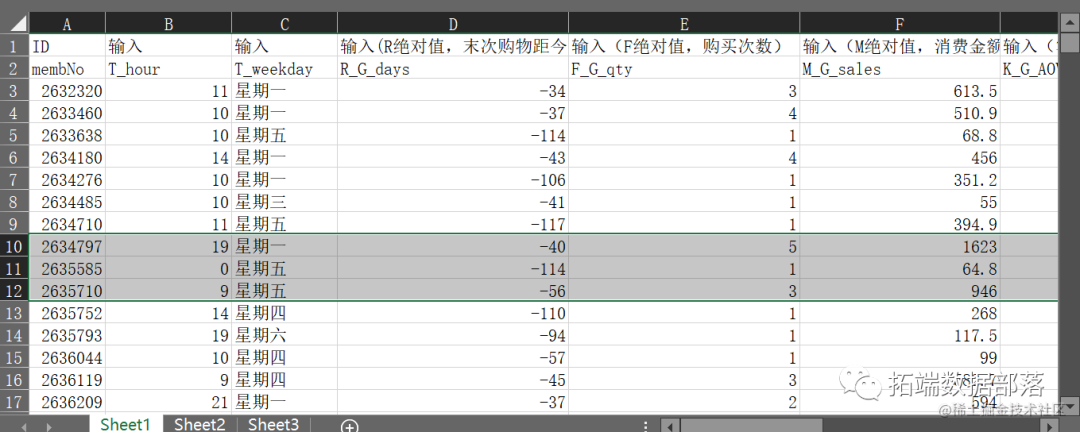
读取数据
go
head(data)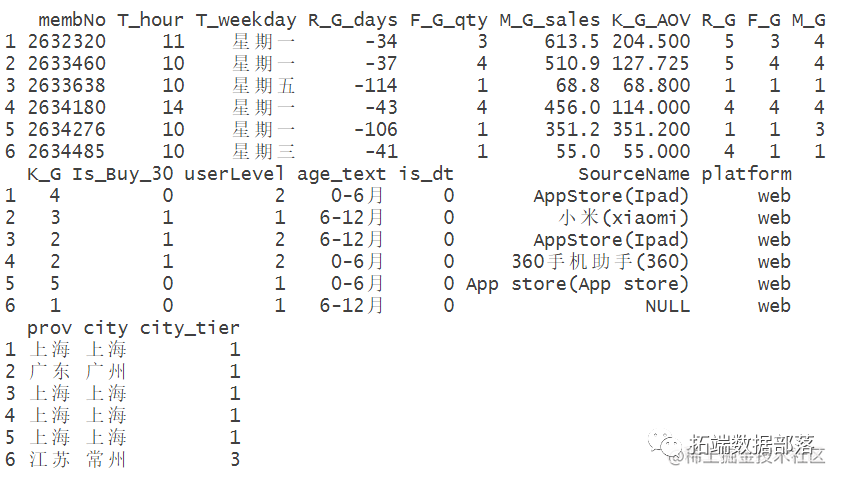
模型构建
在本文中,我们选择了决策树和LASSO模型作为分析工具。决策树是一种常见的机器学习算法,它能够根据数据的特征变量将数据分成不同的类别,并找到最佳的划分方式。LASSO模型通过构造一个惩罚函数得到一个较为精炼的模型,使得它压缩一些回归系数,即强制系数绝对值之和小于某个固定值;同时设定一些回归系数为零。因此保留了子集收缩的优点,是一种处理具有复共线性数据的有偏估计。
决策树
go
df2$Is_Buy_30
变量类型设置
go
df2$Is_Buy_30 =as.factor(df2$Is_Buy_30 )
df2$T_weekday =as.factor(df2$T_weekday)
df2$T_hour=as.numeric(df2$T_hour)
df2$city_tier=as.numeric(df2$city_tier)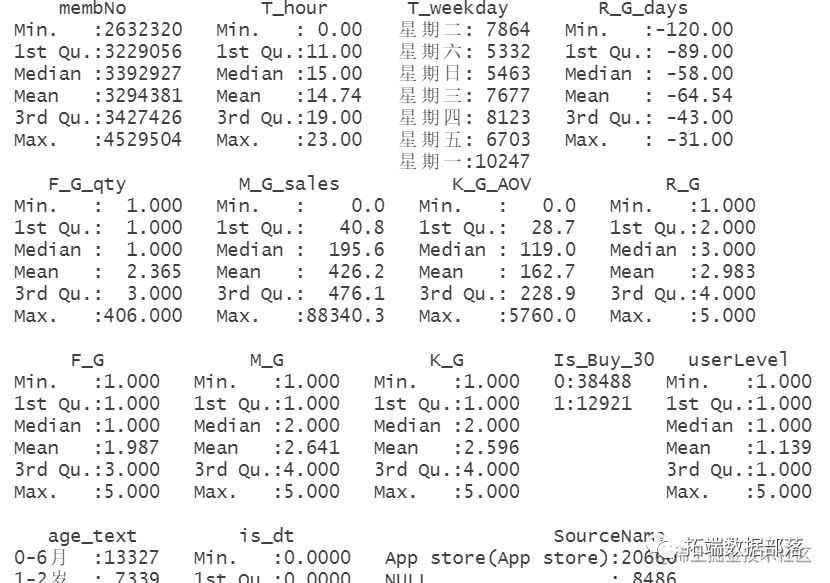
设置权重
go
df2$weight[df2$Is_Buy_30==1]=7
df2$weight[df2$Is_Buy_30==0]=4建立决策树:是否购买
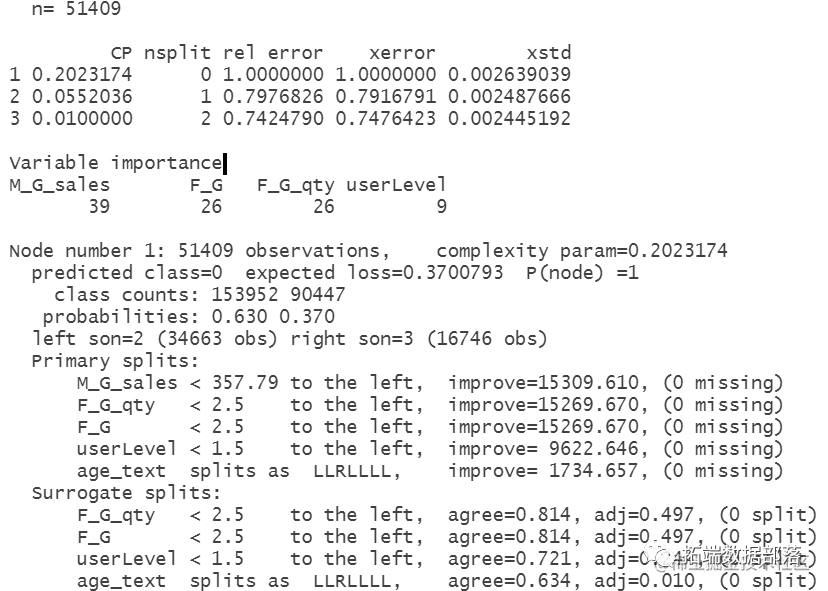
go
result=list(0) CARTmodelfunc=function(model){ CARTmodel = rpart(model, data=df2 , method="class",weights = df2$weig## 绘制决策树 ## 输出决策树cp值 prune(CARTmodel, cp= CARTmodel$cptable[which.min(CARTmodel$cptable[,"xerror"]),"CP"]) #剪枝 CARTmodel2 <- prune(CARTmodel, cp=cp); #对树进行剪枝#对数据进行预测 set.seed(1) #获得训练集 df2.train <- df2[train, ] #测试集 df2.test <- df2[-train, ] #预测数据 tree.pred= (predict(CARTmodel2,df2.test ,type = "class")) confusionmatrix=table(tree.pred,df2.test$Is_Buy_30),#得到训练集混淆矩阵 MSE=mean((as.numeric(tree.pred) - as.numeric(df2.test$Is_Buy_30))^使用lasso算法进行筛选变量
go
#获得训练集
train <- sample(1:nrow(df2), nrow(df2)*0.8)
t)]), alpha = 1)
plot(cv.lasso)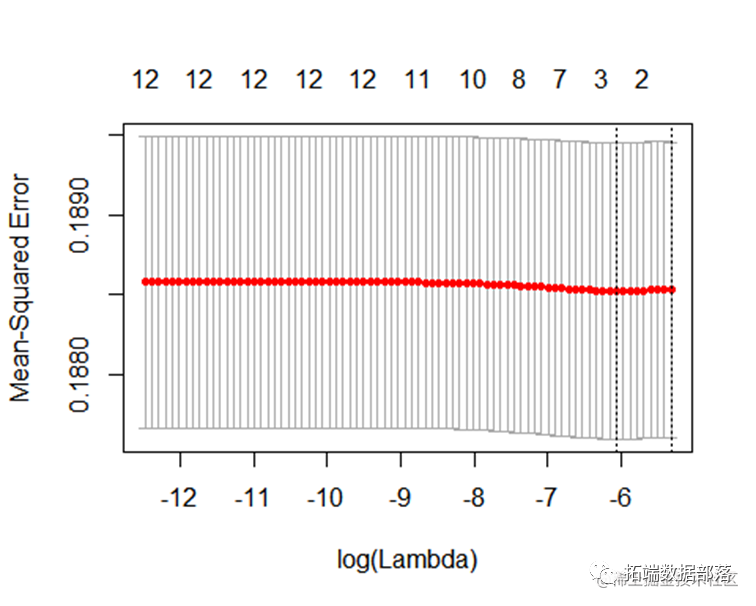
点击标题查阅往期内容

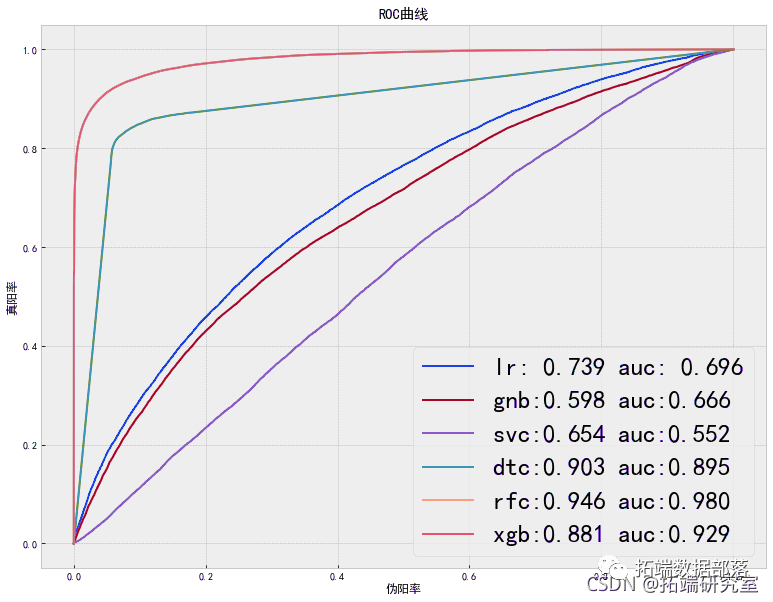
PYTHON用户流失数据挖掘:建立逻辑回归、XGBOOST、随机森林、决策树、支持向量机、朴素贝叶斯和KMEANS聚类用户画像

左右滑动查看更多
01
02
03
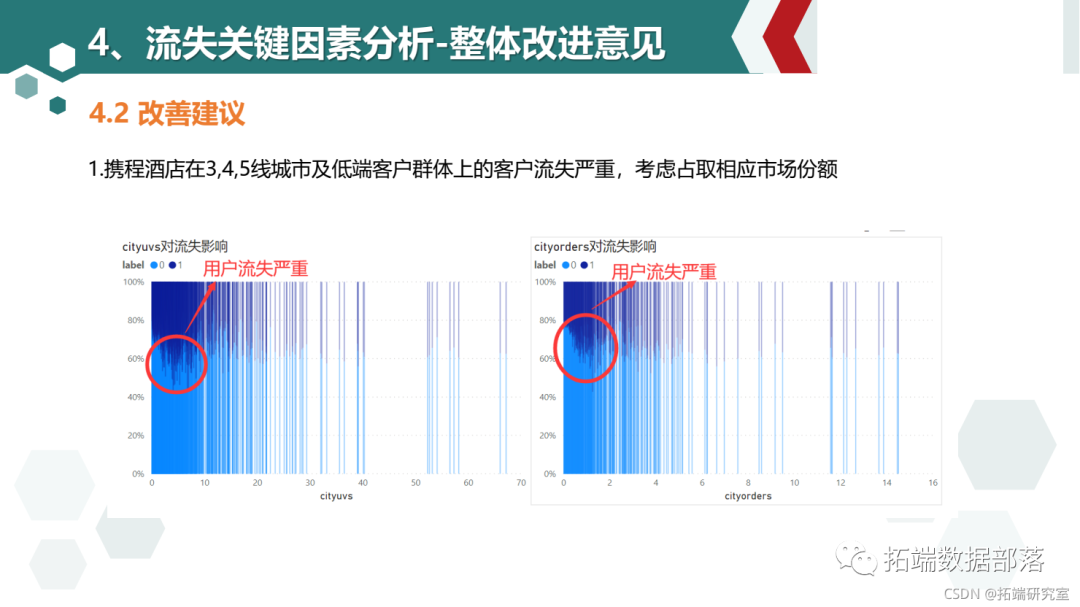
04
go
coef(cv.lasso,s="lambda.1se")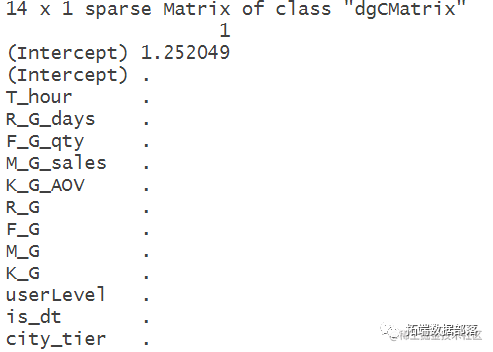
根据lasso筛选出最优的变量

chaid 树
go
ctreemodelfucntion=function(modelformula){
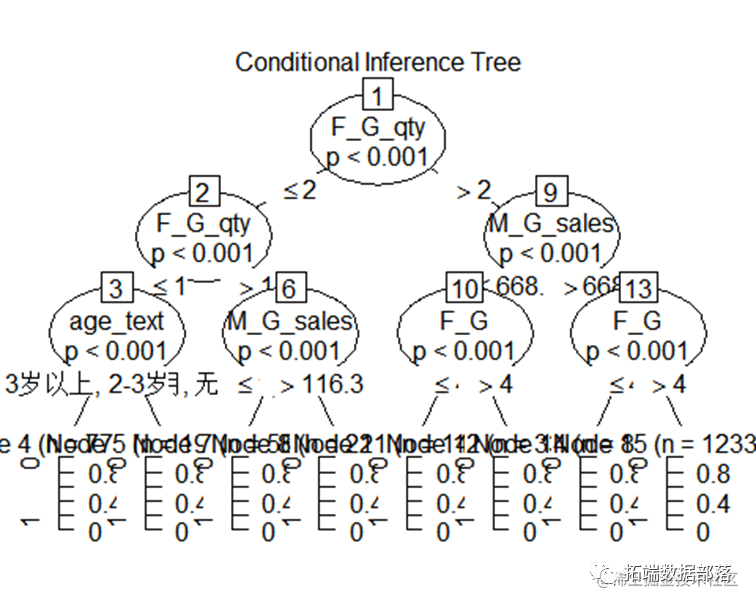
index=sample(1:nrow(df2),nrow(df2)*0.6) df2.train=df2[index,] df2.test=df2[index,] confusionmatrix=table(tree.pred2,df2.test$Is_Buy_30)#得到训练集混淆矩阵#预测为1类的正确率 presicion=tab[2,2]/sum(tab[,2]), # [1] 0.3993589 #预测为1类的召回率 recall=tab[2,2]/sum(tab[2,]), # [1] 0.6826484 #mse MSE=mean((as.numeric(tree.pred2) - as.numeric(df2.test$Is_Buy_30))^2),chaid tree LASSO 算法
可视化树状图:
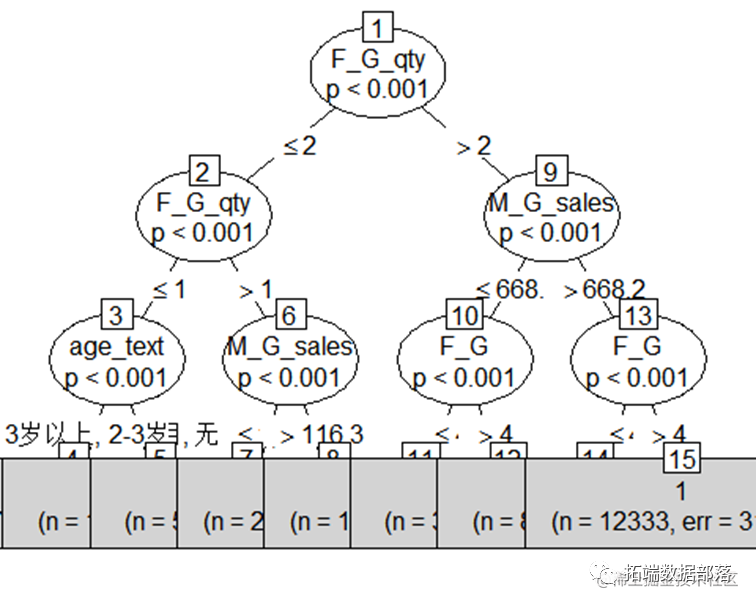
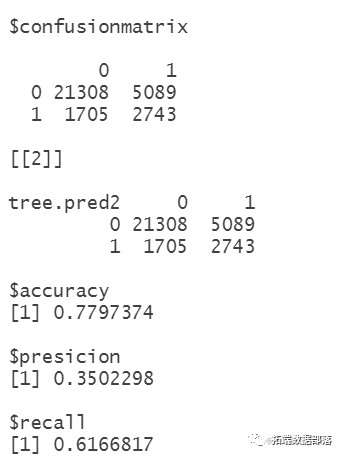
混淆矩阵
混淆矩阵也称误差矩阵,是表示精度评价的一种标准格式,用n行n列的矩阵形式来表示。具体评价指标有总体精度、制图精度、用户精度等,这些精度指标从不同的侧面反映了图像分类的精度。

将x表写进数据库里
go
sqlSave(channel,result2_loss22,rownames = "result2_loss22",addPK = TRUE)CART tree LASSO 算法
绘制决策树
go
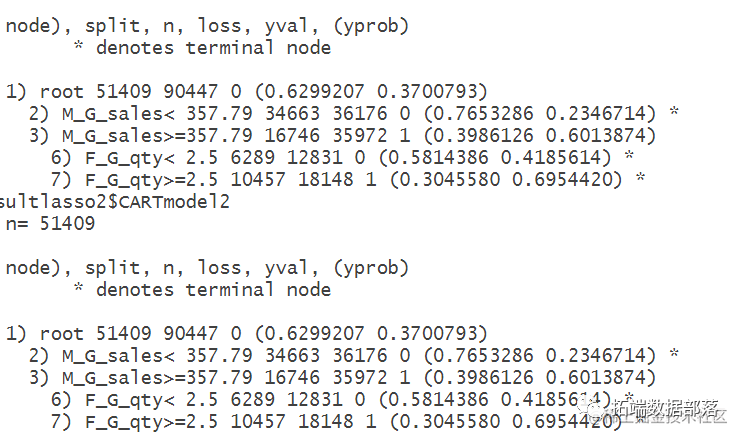
resultlasso2=CARTmodelfunc(modelformulalasso)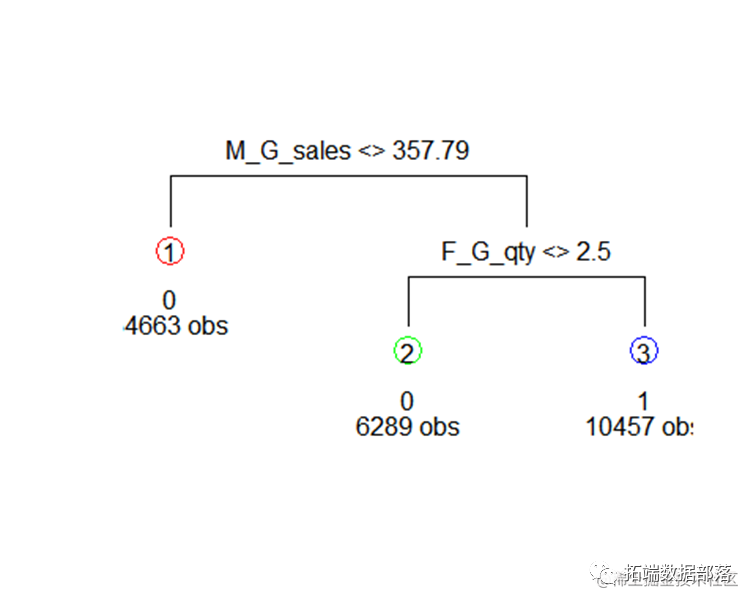
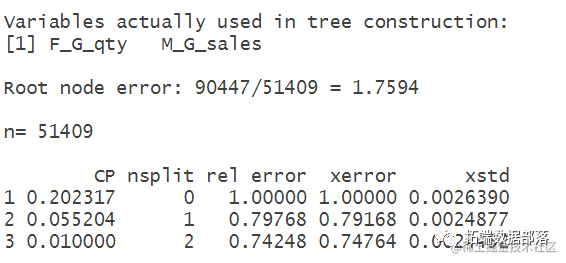
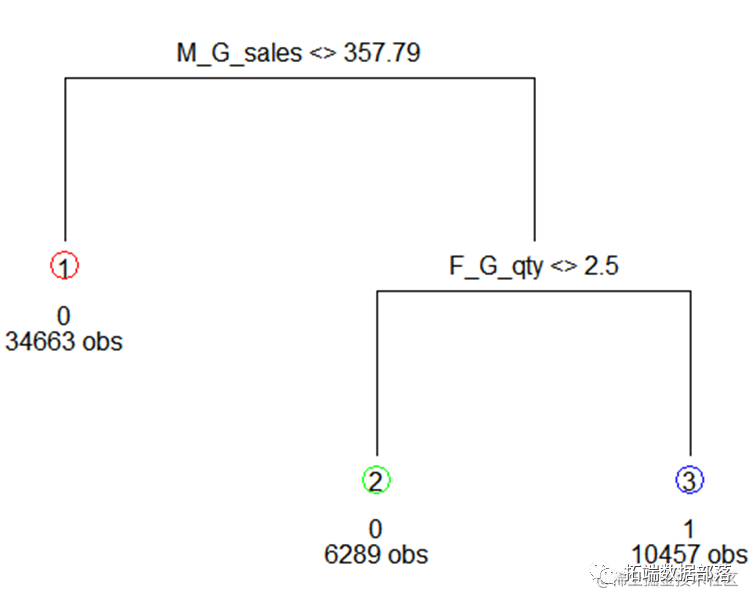
模型结果:
混淆矩阵
混淆矩阵也称误差矩阵,是表示精度评价的一种标准格式,用n行n列的矩阵形式来表示。具体评价指标有总体精度、制图精度、用户精度等,这些精度指标从不同的侧面反映了图像分类的精度。
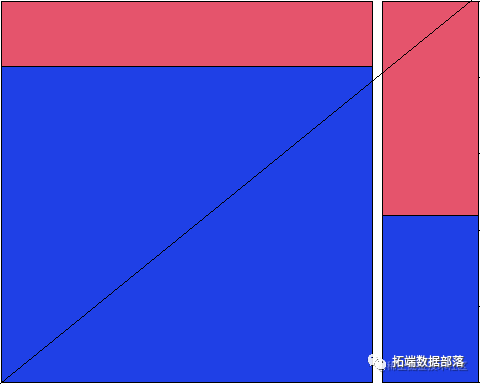
go
resultlasso2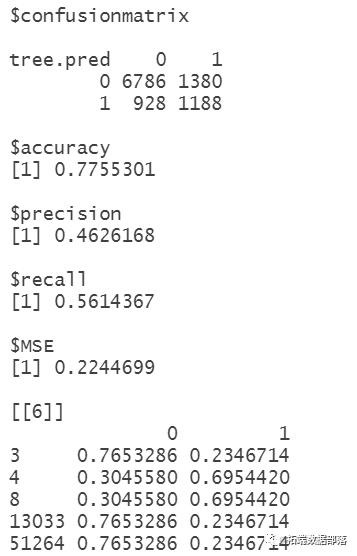
go
# 将x表写进数据库里
sqlSave(channel,result_rfm,rownames = "result_rfm",addPK = TRUE)数据分享|R语言聚类、文本挖掘分析虚假电商评论数据:K-MEANS(K-均值)、层次聚类、词云可视化|附数据代码
聚类分析是一种常见的数据挖掘方法,已经广泛地应用在模式识别、图像处理分析、地理研究以及市场需求分析。本文主要研究聚类分析算法K-means在电商评论数据中的应用,挖掘出虚假的评论数据**(** 点击文末"阅读原文"获取完整代码数据******** )。
本文主要帮助客户研究聚类分析在虚假电商评论中的应用,因此需要从目的出发,搜集相应的以电商为交易途径的评论信息。对调查或搜集得到的信息进行量化录入处理,以及对缺失值过多的分析对象进行删除。之后进行多维度的数据描述。由于地图最多只能显示三维空间,而顾客指标属性很可能不止三个,因此在数据描述中可以进行单一指标与某个确定指标的二维展示,这样大致先了解客户分布。
最终,通过应用改进的K-means算法对数据进行挖掘,得出了直观有用的形象化结论,对之后公司管理层做销售决策提供了必要的依据。本次改进,也可以作为今后其他数据的参考,来进行其他数据的可靠挖掘,可以说提供了可靠的参照。
研究内容
本项目主要是针对现实中的市场营销与统计分析方法的结合,来挖掘潜在的客户需求。随着电子商务的发展和用户消费习惯改变,电商在销售渠道的比重将大大增强,2014年电商销售已经超过了店面销售的数量。因此,这为通过数据挖掘算法来分析客户的交易选择行为,将客户的喜好通过分类来组别,这样进一步能挖掘潜在客户和已交易客户的下一步潜在需求。
本文在基础的K-means聚类算法的基础上,结合该算法固有的一些缺陷,提出了一些改进措施,即通过改进的K-means聚类算法来对"B2C电商评论信息数据集"数据进行处理,在最终得到结果之后依据形象化的结论提出相应的公司决策,以满足市场的要求。
K-means的改进
文献7是Huang为克服K-means算法仅适合于数值属性数据聚类的局限性,提出的一种适合于分类属性数据聚类的K-modes算法"该算法对K-means进行了3点扩展:引入了处理分类对象的新的相异性度量方法(简单的相异性度量匹配模式),使用mode:代替means,并在聚类过程中使用基于频度的方法修正modes,以使聚类代价函数值最小化"这些扩展允许人们能直接使用K-means范例聚类有分类属性的数据,无须对数据进行变换"K-modes算法的另一个优点是modes,能给出类的特性描述,这对聚类结果的解释是非常重要的"事实上,K-modes算法比K-means算法能更快收敛,与K-means算法一样,K-modes算法也会产生局部最优解,依赖于初始化modes的选择和数据集中数据对象的次序。初始化modes的选择策略尚需进一步研究。
1999年,Huang等人8证明了经过有限次迭代K-modes算法仅能收敛于局部最小值。
K-medoids聚类算法的基本策略就是通过首先任意为每个聚类找到一个代表对象(medoid)而首先确定n个数据对象的k个聚类;(也需要循环进行)其它对象则根据它们与这些聚类代表的距离分别将它们归属到各相应聚类中(仍然是最小距离原则)。
综合考虑以上因素,本文考虑了孤立点。传统的聚类分析将全部点进行聚类,而不考虑可能存在的孤立点对聚类结果的干扰,这使得聚类结果缺乏可靠性和稳定性。对于聚类结果,需要进行判别分析,包括内分析和外分析。内分析主要是在聚类之后,点到类中心的阈值来寻找孤立点,从而剔除孤立点,保证样本和聚类中心的可靠性,在剔除了孤立点后需要重新计算类中心,如果出现极端情况,甚至有可能进行再一次聚类分析;外分析是指在确定好最终的聚类结果后,进行外样本预测,使聚类结果更加稳定。
分析
数据集与环境
本文的实验环境为Windows操作系统,R编程环境。同时选取了"B2C电商评论信息数据集"作为实验对象。这个数据集中包含了2370条B2C电商评论信息**(** 查看文末了解数据免费获取方式 )。
数据文件:

设计
在这里,为了提高算法效率,降低数据的稀疏性,本文首先导入文本数据,对该数据进行文本挖掘。筛选出所有评论中词频最高的前30个词汇,用作实验的聚类属性。
go
# == 分词+频数统计
words=unlist(lapply(X=data, FUN=segmentCN));每个高频词汇和其词频数据如下表所示:
| word | freq |
|---|---|
| 漂亮 | 547 |
| 喜欢 | 519 |
| 颜色 | 477 |
| 质量 | 474 |
| 丝巾 | 452 |
| 不错 | 435 |
| 好评 | 425 |
| 谢谢 | 277 |
| 非常 | 273 |
| 解释 | 263 |
| 愉快 | 237 |
| 生活 | 229 |
| 满意 | 226 |
| 继续 | 225 |
| 宝贝 | 222 |
| 美丽 | 217 |
| 一天 | 214 |
| 提供 | 214 |
| 努力 | 213 |
| 祝愿 | 212 |
| 衷心 | 212 |
| 赏赐 | 212 |
| 感恩 | 212 |
| 收到 | 211 |
| 没有 | 187 |
| 色差 | 141 |
| 好看 | 126 |
| 图片 | 120 |
| 可以 | 110 |
通过中文分词Rwordseg词频云软件包可以根据不同的词汇的词频高低来显示文本挖掘的高频词汇的总体结果。通过将词频用字体的大小和颜色的区分,我们可以明显地看到哪些词汇是高频的,哪些词汇的频率是差不多的,从而进行下一步研究。
实验采用上述数据集得到的高频词汇得到每个用户和高频词汇的频率矩阵。
| 记录 | 漂亮 | 喜欢 | 颜色 | 质量 | 丝巾 | 满意 |
|---|---|---|---|---|---|---|
| 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 1 | 0 | 0 | 0 | 0 |
| 3 | 1 | 1 | 0 | 0 | 0 | 0 |
| 4 | 1 | 1 | 0 | 0 | 0 | 0 |
| 5 | 0 | 0 | 0 | 0 | 1 | 0 |
| 6 | 1 | 0 | 0 | 0 | 0 | 0 |
| 7 | 1 | 0 | 0 | 0 | 0 | 0 |
| 8 | 0 | 0 | 1 | 0 | 0 | 0 |
| 9 | 0 | 2 | 0 | 0 | 0 | 0 |
| 10 | 0 | 0 | 0 | 0 | 0 | 1 |
| 11 | 0 | 1 | 1 | 0 | 1 | 0 |
| 12 | 0 | 0 | 0 | 0 | 0 | 0 |
| 13 | 1 | 0 | 0 | 2 | 1 | 1 |
| 14 | 0 | 0 | 0 | 0 | 0 | 0 |
| 15 | 1 | 1 | 0 | 1 | 0 | 0 |
| 16 | 0 | 1 | 0 | 0 | 0 | 0 |
| 17 | 1 | 0 | 1 | 1 | 1 | 0 |
| 18 | 0 | 0 | 0 | 0 | 0 | 0 |
用户词汇频率矩阵表格的一行代表用户的一条评论,列代表高频词汇,表中的数据代表该条评论中出现的词汇频率。
结果及分析
K-均值聚类算法的虚假评论聚类结果
用K-mean进行分析,选定初始类别中心点进行分类。
一般是随机选择数据对象作为初始聚类中心,由于kmeans聚类是无监督学习,因此需要先指定聚类数目。
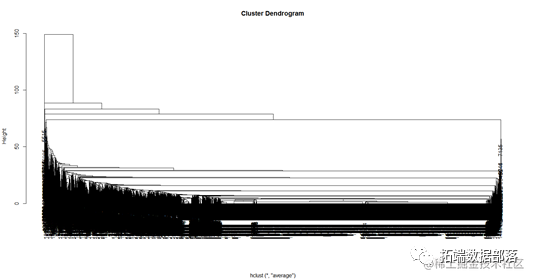
层次聚类是另一种主要的聚类方法,它具有一些十分必要的特性使得它成为广泛应用的聚类方法。它生成一系列嵌套的聚类树来完成聚类。
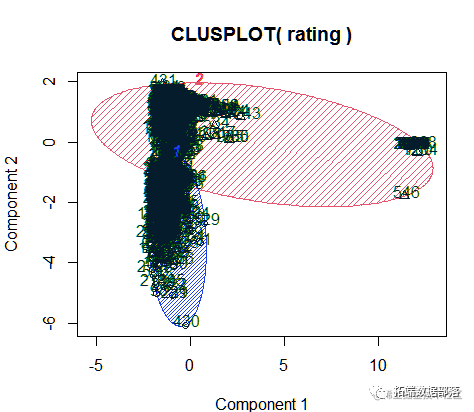
从树的直观表示来看,当height取80的时候,树的分支可以大概分成2类,分成的类别比较清楚和直观,因此我们取k等于2,分别对应虚假评论和真实评论。
点击标题查阅往期内容

R语言文本挖掘:kmeans聚类分析上海玛雅水公园景区五一假期评论词云可视化
左右滑动查看更多
01

02
03
04

K-means算法得到的聚类中心
go
#查找虚假评论
#比较典型的识别方式 # 看文字,什么非常好,卖家特别棒,我特满意,以后还会来等等,写一大堆文字,但是没有对产品有实质性描述的,一般是刷的,这一点是主要判断依据,因为刷单的人一般要写很多家的评价,所以他不会对产品本身做任何评论,全都是一些通话套话。fake1= grep(pattern="非常好" ,data); fake2= grep(pattern="卖家特 for(j in 1:length(index)){ jj=which(dd[,1]==i]) rating[i,colnames(rating)==indexj,2][[1]]#高频词汇的数量赋值到评价矩阵 } }cl=kmeans(ratin,2)#对评价矩阵进行k均值聚类
write.csv(cl$centers,"聚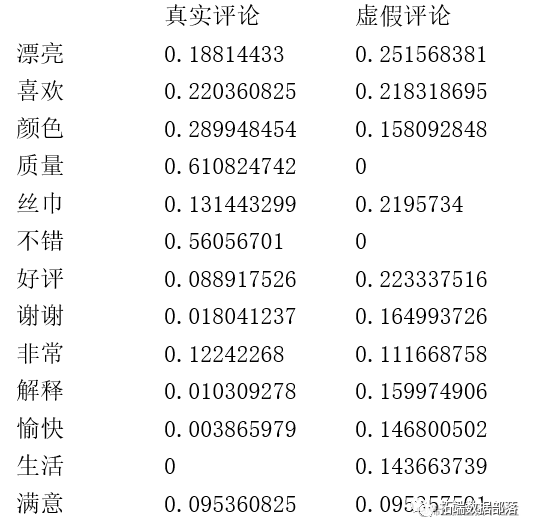
每个类所有点到类中心的距离之和与平均距离
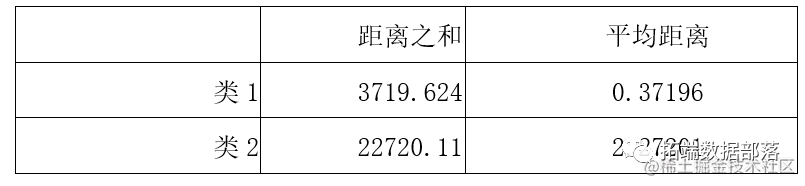
通过设定距离阈值k=2,我们找出了3356个异常值并将其剔除。
然后绘制聚类散点图,通过聚类图,我们可以看到真实评论和虚假评论明显地被分成了两个聚类簇。
最后对2个类分别做了词频统计,并用词频云表示每个类的特征。
真实评论
go
wordcloud(colnames(c
虚假评论

从词频云图可以看到,真实的评价中的主要关键词是质量,不错,色差等,从这些关键词来看,本文可以推测这类用户主要看重的是商品的功能性和质量型,并且主要集中在一些基本的特征,如质量、色差。也可以推测这些用户的商品评论没有太多华丽的词汇,而只是简单的不错,谢谢等。因此,可以认为真实的评论一般比较简单,并且会有一些对商品具体的方面的不足进行描述如色差,而不是一味的非常好、喜欢、愉快等。
虚假评论类别中主要的关键词是好评!,感恩!,美丽!,赏赐!、努力!祝愿!等词汇。从这些关键词我们大致可以推测这类用户主要使用的是一些华丽的词藻。他们比较看重评论的夸张度和给人的好感度,更在乎评论给别的买家造成的美好体验。这些用户往往使用很"完美"的评价,大多使用好评、美丽、感恩等评价很高的词汇,而没有很关注商品的质量和具体的细节,一般套用了相近的评论模板,因此可以认为是虚假评论。
参考文献
1T Zhang.R.Ramakrishnan and M.ogihara.An efficient data clustering method for very largedatabases.In Pror.1996 ACM-SlGMOD hat.Conf.Management of Data,Montreal.Canada,June 1996:103.114.
2邵峰晶,于忠清,王金龙,孙仁城 数据挖掘原理与算法(第二版) 北京:科学出版社 ,2011, ISBN 978-7-03-025440-5.
3张建辉.K-meaIlS聚类算法研究及应用:武汉理工大学硕士学位论文.武汉:武汉理工大学,2012.
4冯超.K-means 类算法的研究:大连理工大学硕士学位论文.大连:大连理工大学,2007.
5曾志雄.一种有效的基于划分和层次的混合聚类算法.计算机应用,2007,27(7):1692.1695.
6范光平.一种基于变长编码的遗传K-均值算法研究:浙江大学硕士学位论文.杭州:浙江大学,2011.
7孙士保,秦克云.改进的K-平均聚类算法研究.计算机工程,2007,33(13):200.202.
8孙可,刘杰,王学颖.K均值聚类算法初始质心选择的改进.沈阳师范大学学报,2009,27(4):448-450.
9Jain AK,Duin Robert PW,Mao JC.Statistical paaern recognition:A review.IEEE Trans.Actions on Paaem Analysis and Machine Intelligence,2000,22(1):4-37.
10Sambasivam S,Theodosopoulos N.Advanced data clustering methods ofmining web documents.Issues in Informing Science and Information Technology,2006,8(3):563.579.

本文中分析的完整数据、代码、文档**** 分享到会员群,扫描下面二维码即可加群!


点击文末**"阅读原文"**
获取全文完整代码数据资料。
本文选自《Python与R语言用XGBOOST、NLTK、LASSO、决策树、聚类分析电商平台评论信息数据集》。


点击标题查阅往期内容
Python对商店数据进行lstm和xgboost销售量时间序列建模预测分析
PYTHON集成机器学习:用ADABOOST、决策树、逻辑回归集成模型分类和回归和网格搜索超参数优化
R语言集成模型:提升树boosting、随机森林、约束最小二乘法加权平均模型融合分析时间序列数据
Python对商店数据进行lstm和xgboost销售量时间序列建模预测分析
R语言用主成分PCA、 逻辑回归、决策树、随机森林分析心脏病数据并高维可视化
R语言基于树的方法:决策树,随机森林,Bagging,增强树
python在Scikit-learn中用决策树和随机森林预测NBA获胜者
python中使用scikit-learn和pandas决策树进行iris鸢尾花数据分类建模和交叉验证
R语言里的非线性模型:多项式回归、局部样条、平滑样条、 广义相加模型GAM分析
R语言用标准最小二乘OLS,广义相加模型GAM ,样条函数进行逻辑回归LOGISTIC分类
R语言用泊松Poisson回归、GAM样条曲线模型预测骑自行车者的数量
R语言分位数回归、GAM样条曲线、指数平滑和SARIMA对电力负荷时间序列预测
R语言样条曲线、决策树、Adaboost、梯度提升(GBM)算法进行回归、分类和动态可视化
R语言ARMA-EGARCH模型、集成预测算法对SPX实际波动率进行预测
R语言基于Bagging分类的逻辑回归(Logistic Regression)、决策树、森林分析心脏病患者
R语言基于树的方法:决策树,随机森林,Bagging,增强树
R语言使用bootstrap和增量法计算广义线性模型(GLM)预测置信区间
R语言样条曲线、决策树、Adaboost、梯度提升(GBM)算法进行回归、分类和动态可视化
Python对商店数据进行lstm和xgboost销售量时间序列建模预测分析
R语言随机森林RandomForest、逻辑回归Logisitc预测心脏病数据和可视化分析
R语言用主成分PCA、 逻辑回归、决策树、随机森林分析心脏病数据并高维可视化
Matlab建立SVM,KNN和朴素贝叶斯模型分类绘制ROC曲线


