1 数据库概述
1.1 数据库本身的瓶颈
① 连接数
MySQL默认最大连接数为100,允许的最大连接数为16384
② 单表海量数据查询性能
单表最好500w左右,最大警戒线800w
③ 单数据库并发压力问题
MySQL QPS:1500左右/秒
④ 系统磁盘IO、CPU瓶颈
1.2 数据库架构演变升级
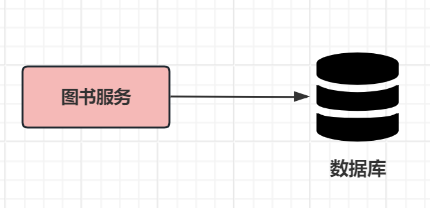
(1)单机
请求量大查询就会变慢;单机不可用
(2)主从
主从同步,读写分离。从库可以水平扩展。满足更大读请求
但单服务器TPS、内存、IO等都有限

(3)双主(使用场景较少)
用户量上来了,写请求越来越多,一个master节点不能解决问题,添加多个主节点
多个主节点数据要保持一致性,写操作需要两个master之间同步,流程更加复杂 
(4)分库分表
分库分表是通过垂直拆分或水平拆分对数据库进行物理或逻辑层面的分割,以解决单库单表的性能瓶颈(如连接数限制、数据量过大、硬件资源不足)和数据管理复杂度问题。 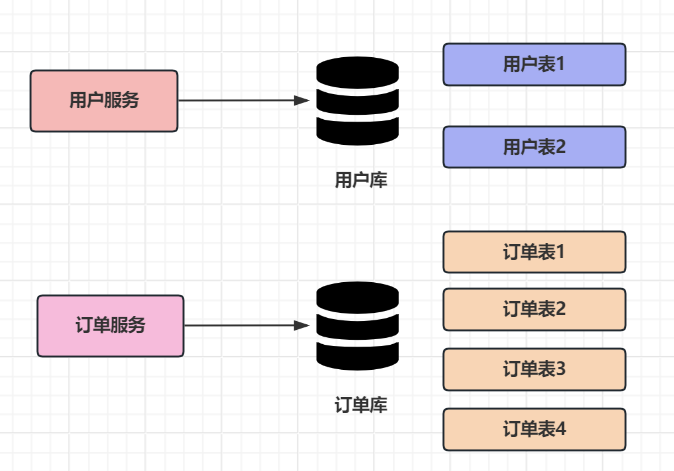
面试题:开发的项目业务增长,数据库优化思路
思路:① 先问清楚业务增长量,平均大概增长多少
② 千万不要一上来就说分库分表,要根据实际情况分析
(1)数据库优化
1)硬优化:如果资金充裕,可以先优化硬件条件
提升系统硬件,更快的IO,更多的内存,带宽、CPU、磁盘等
2)软优化
① 数据库参数优化
② 分析慢查询SQL语句,分析执行计划,进行SQL改写或程序改下
③ 优化索引结构
④ 优化数据表结构
⑤ 引入NoSQL和程序架构调整
(2)分库分表(如果单表数据量超过1000w或者并发量特别大,还是建议分库分表)
① 根据业务情况而定,选择合适的分库分表策略
② 先看只分表是否满足需求和未来增长
③ 如果单分表不能满足需求,再分库分表一起
总结:
① 在数据量和访问压力不是特别大的情况下,首先考虑数据库优化
② 如果数据量极大,且业务增长块,在考虑分库分表方案
2 分库分表的问题
① 跨节点数据库 join 关联查询
② 分库操作带来的分布式事务问题
③ 执行的SQL排序、翻页、函数计算问题
④ 数据库全局主键重复问题(以前使用的自增ID就会出现问题)
⑤ 容量规划,分库分表二次扩容问题
⑥ 分库分表技术选型问题
3 常见分库分表方案
项目、技术负责人需要有前瞻性思维
① 需要提前考虑1到2年的业务增长情况
② 对数据库服务器(QPS、连接数、容量等)做合理评估和规划
3.1 垂直分表
大表拆小表:基于列字段进行,分离热点字段和非热点字段,避免大字段IO
① 把不常用的字段放在一张表
② 把text、blob等大字段拆分出来一张表
③ 业务经常组合查询的列放在一张表中
3.2 垂直分库
微服务架构,就做了垂直分库,每个服务使用自己的库
问题:垂直分库分表可以提高并发,但是依然没有解决单表数据量过大的问题。
3.3 水平分表
数据拆分:把一个大表分割成N个小表,表结构一样,数据不一样
主要解决单表数据量过大的问题,减少锁表时间
3.4 水平分库
把同一个表数据按照一定规则分到不同的数据库中,数据库在不同的服务器上
水平分库的粒度,比水平分表大
多个数据库,降低系统的IO和CPU压力
注意:水平分库分表,选择合适的分片键和分片策略,和业务场景相配合
4 分库分表常见策略
4.1 range范围(更多适用于水平分表)
(1)数字范围
自增ID,根据ID范围进行分表(左闭右开)
优点:ID自增长,可以无限;扩容不用迁移数据,容易理解和维护
缺点:数据倾斜严重,热点数据过于集中,部分节点有瓶颈,整体利用率低
(2)时间范围
年、月、日范围
使用场景:流水数据、日志信息
(3)空间范围
地理位置:省份、区域划分(华东、华中、华南...)
使用场景:外卖、物流等 
4.2 Hash取模
库ID = hashcode % 库数量
表ID = hashcode / 库数量 % 表数量
优点:保证数据较均匀的分散在不同的库、表中,可以有效的避免热点数据集中问题
缺点:扩容不是很方便,需要数据迁移
5 分库分表技术选型
① TDDL(Taobao Distributed Data Layer)
淘宝根据自己业务特点开发的
基于JDBC规范,没有server,以client-jar形式存在,引入项目即可使用
开源功能比较少,阿里内部使用为主
② Mycat
网址:| MYCAT官方网站---中国开源分布式数据库中间件
遵守MySQL原生协议,跨语言、跨平台、跨数据库的通用中间件代理
基于proxy,复写了MySQL协议,将Mycat server伪装成一个MySQL数据库 
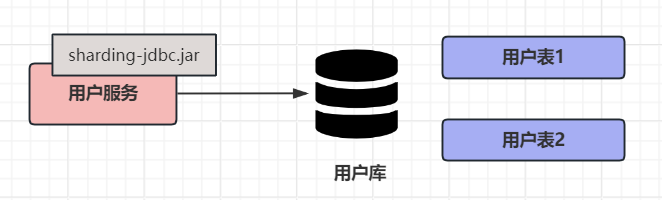
③ ShardingJDBC
Apache ShardingSphere 是一款分布式的数据库生态系统,包括Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar
基于JDBC驱动,不用额外proxy,支持任意实现JDBC规范的数据库
以jar包形式提供服务,无需额外部署和依赖
面试题:Mycat 和 ShardingJDBC 的区别
两者设计理念相同,主流程都是 SQL解析 -> SQL路由 -> SQL改写 -> 结果归并
ShardingJDBC
① 基于JDBC驱动,不用额外proxy,在本地应用重写JDBC原生的方法,实现数据库分片形式
② 是基于JDBC接口的扩展,是以jar包的形式提供轻量级服务,性能高
③ 代码有侵入性
Mycat
① 是基于proxy,复写了MySQL协议,将Mycat server 伪装成一个MySQL数据库
② 客户端所有的JDBC请求都必须要先交给Mycat,再由Mycat转发到具体的真实服务器
③ 缺点是效率偏低,中间包装了一层
④ 代码无侵入性