在数据分析和可视化领域,雷达图是一种适用于多维数据的可视化、综合评估和决策支持的工具。
雷达图通过将数据点沿多个轴分布,并通过多边形面积或线条连接来展示数据的多维度特征,能够直观地呈现数据在各个维度上的表现,帮助我们快速识别优势和劣势,从而做出更明智的决策。
本文主要介绍Plotly雷达图的奥秘,从绘制原理到实战应用,包括代码实现与分析方法。
1. 基础绘制
雷达图是一种多轴图表,数据点沿多个轴分布,每个轴代表一个维度。通过将数据点连接成多边形,可以直观地展示数据在各个维度上的表现。
1.1. 数据标准化
与其他图形(比如折线图,柱状图等等)不同,绘制雷达图之前,数据标准化是必不可少的步骤。
因为雷达图的各个维度可能具有不同的量纲和范围,这会直接绘制会导致图形失真。
常用的数据标准化方法有两个:
- 归一化 (
Min-Max Scaling):将数据缩放到 0, 1 区间。 Z-score标准化:将数据转换为均值为 0,标准差为 1 的分布。
绘制雷达图的数据结构要求:
- 输入数据需为二维列表或数组,每行代表一个对象在各个维度上的值。
- 维度标签(theta)与数值(r)需一一对应。
1.2. 代码示例
下面通过一组测试数据(产品性能评分数据,包含多个维度,如摄像头、电池、屏幕等),来尝试绘制雷达图。
python
import plotly.graph_objects as go
# 数据准备
categories = ["摄像头", "电池", "屏幕", "处理器", "设计"]
values = [8, 7, 9, 6, 8] # 示例评分
values += values[:1] # 闭合多边形
categories += categories[:1] # 闭合多边形
fig = go.Figure(
data=[
go.Scatterpolar(
r=values,
theta=categories,
fill="toself", # 填充闭合区域
name="产品性能评分",
)
]
)
# 设置图表标题和布局
fig.update_layout(
title="产品性能雷达图",
polar=dict(radialaxis=dict(visible=True, range=[0, 10])), # 设置径向轴范围
showlegend=True,
)
# 显示图表
fig.show()代码中的核心参数含义:
r:绑定数值数据,表示各个维度的数值theta:设置维度标签,支持字符串或数值标签fill:填充模式选择,'toself'表示闭合区域填充,'none'表示仅绘制线条line:线条样式,包括颜色、宽度、透明度等
运行结果如下:

为了提升图表的可读性,可以对标签进行优化,例如调整字体大小和角度。
python
fig.update_layout(
title='产品性能雷达图',
polar=dict(
radialaxis=dict(
visible=True,
range=[0, 10]
),
angularaxis=dict(
tickfont=dict(size=12), # 设置标签字体大小
rotation=90, # 设置标签旋转角度
direction='clockwise' # 设置标签方向
)
),
showlegend=True
)调整之后显示如下:

2. 应用场景
2.1. 多组数据对比
通过go.Scatterpolar叠加多组数据,并使用不同颜色区分,可以直观地对比多组数据的性能。
python
# 数据准备
values1 = [8, 7, 9, 6, 8]
values2 = [7, 8, 6, 7, 9]
values1 += values1[:1]
values2 += values2[:1]
fig = go.Figure(data=[
go.Scatterpolar(
r=values1,
theta=categories,
fill='toself',
name='产品A'
),
go.Scatterpolar(
r=values2,
theta=categories,
fill='toself',
name='产品B'
)
])
# 设置图表标题和布局
fig.update_layout(
title='多产品性能对比雷达图',
polar=dict(
radialaxis=dict(
visible=True,
range=[0, 10]
)
),
showlegend=True
)
# 显示图表
fig.show()
2.2. 优劣势定位
假设我们有几家供应商的综合能力评估数据,包括质量、成本、交付等维度。
我们将使用雷达图来评估这些供应商的综合能力。
python
# 数据准备
categories = ['质量', '成本', '交付', '服务', '创新']
values1 = [8, 6, 7, 8, 7] # 供应商A的评分
values2 = [7, 8, 6, 7, 8] # 供应商B的评分
values3 = [9, 7, 8, 6, 9] # 供应商C的评分
values1 += values1[:1]
values2 += values2[:1]
values3 += values3[:1]
categories += categories[:1]
# 绘制雷达图
fig = go.Figure(data=[
go.Scatterpolar(
r=values1,
theta=categories,
fill='toself',
name='供应商A'
),
go.Scatterpolar(
r=values2,
theta=categories,
fill='toself',
name='供应商B'
),
go.Scatterpolar(
r=values3,
theta=categories,
fill='toself',
name='供应商C'
)
])
# 添加参考线(行业平均值)
fig.add_trace(
go.Scatterpolar(
r=[7, 7, 7, 7, 7, 7],
theta=categories,
mode='lines',
line=dict(color='rgba(255, 0, 0, 0.5)', dash='dash'),
name='行业平均值'
)
)
# 设置图表标题和布局
fig.update_layout(
title='供应商综合能力评估雷达图',
polar=dict(
radialaxis=dict(
visible=True,
range=[0, 10]
)
),
showlegend=True
)
# 显示图表
fig.show()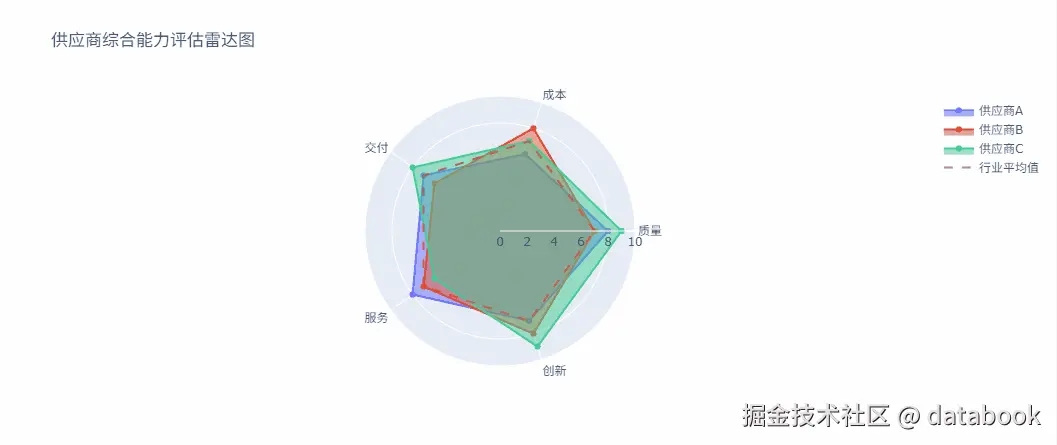
通过雷达图,我们可以直观地看到各供应商在不同维度上的表现。
例如,供应商C 在质量和创新方面表现较好,而供应商B在成本方面表现更优。
通过添加行业平均值的参考线,我们可以进一步评估各供应商的综合能力。
2.3. 权重分析
结合维度权重计算综合得分,例如加权平均。
然后在雷达图 边上用柱状图显示总分对比。
python
from plotly.subplots import make_subplots
# 权重
weights = [0.2, 0.3, 0.25, 0.15, 0.1]
# 计算综合得分
score1 = sum([v * w for v, w in zip(values1[:-1], weights)])
score2 = sum([v * w for v, w in zip(values2[:-1], weights)])
# 创建子图布局
fig = make_subplots(
rows=1,
cols=2,
specs=[[{"type": "polar"}, {"type": "bar"}]],
subplot_titles=("产品性能雷达图", "综合得分对比")
)
# 添加雷达图
fig.add_trace(
go.Scatterpolar(
r=values1,
theta=categories,
fill='toself',
name='产品A',
line=dict(color='rgba(0, 128, 0, 0.7)')
),
row=1,
col=1
)
fig.add_trace(
go.Scatterpolar(
r=values2,
theta=categories,
fill='toself',
name='产品B',
line=dict(color='rgba(255, 165, 0, 0.7)')
),
row=1,
col=1
)
# 添加柱状图
fig.add_trace(
go.Bar(
x=['产品A', '产品B'],
y=[score1, score2],
marker=dict(color=['rgba(0, 128, 0, 0.7)', 'rgba(255, 165, 0, 0.7)'])
),
row=1,
col=2
)
# 设置雷达图布局
fig.update_layout(
polar=dict(
radialaxis=dict(
visible=True,
range=[0, 10]
)
),
showlegend=True
)
# 设置柱状图布局
fig.update_layout(
barmode='group',
bargap=0.2,
bargroupgap=0.1
)
# 显示图表
fig.show()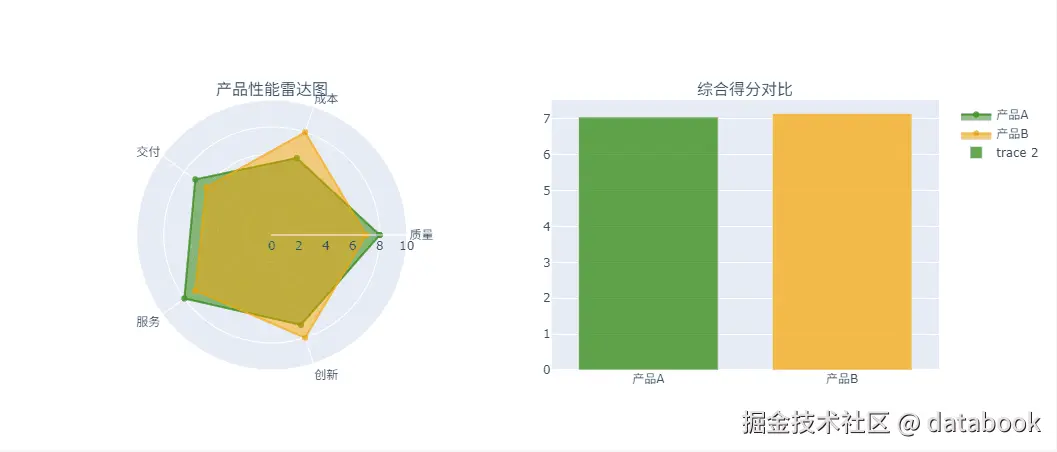
3. 总结
雷达图在多维数据评估中具有不可替代的作用,它能够直观地展示数据在各个维度上的表现,帮助我们快速识别优势和劣势,从而做出更明智的决策。
通过使用 Plotly 绘制雷达图,我们可以轻松实现多组数据的对比评估,并结合权重分析和参考线等工具,进一步提升决策的科学性和准确性。
在实际应用中,数据预处理阶段要重视标准化方法的选择,确保各维度之间的可比性。