- 序:上一个章节,我从硬件出发,由宏观到微观,由具体到抽象,围绕研究对象未被打开的文件来讲解,操作系统是如何对一个大块的磁盘进行管理的,从而引进inode的概念,加深了对文件的理解,本章,我将带领大家更加深入的学习,了解软硬链接的概念,知道软连接和硬链接所处理的场景,以及动静态库的概念!!!
1. 软硬链接
1.1 什么是软硬连接
想要知道什么是软硬链接,我们先看软硬链接是如何创建的!
建立硬链接:ln + 文件名
建立软连接: ln -s + 文件名
创建软连接后,我们发现他具有独立的inode,与被其链接的文件的inode和软连接的inode不一样。所以,软连接是一个独立的文件,因为他具有独立的inode创建硬链接后,该硬链接的inode与被其链接的文件的inode一样。所以,硬链接不是一个独立的文件,因为他没有独立的inode。
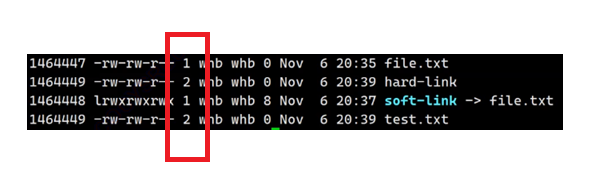
我们发现当一个文件被硬链接后,文件权限后面的那个数字变成了2,且那个硬链接的文件的那个数字也是2!!!这个数字是什么意思呢?权限后面的那个数字,其实就是硬链接数,来表示一个文件有几个硬链接的。那么问题来了,为什么硬链接的文件属性和被硬链接链接的文件的属性一模一样,而且硬链接数也一样呢?
答:这是因为这两个文件的inode是一样的,所以根据inode读出来的数据就是一模一样的。
1.2 如何理解软硬链接
问题一:该如何理解软连接?
软连接是一个独立的文件,有独立的inode,也有独立的数据块,他的数据块里面保存的是指向文件的路径(相当于windows的快捷方式)
当我们删除被软连接链接的文件时,该文件被删除,该软链接所指向的文件没了,所以该软链接就失效了!!!
问题二:该如何理解硬链接?
所谓的建立硬链接,本质其实就是在特定的目录的数据块中新增文件名和指向文件的inode编号的映射关系!!!
当我们删除被硬链接链接的文件的时候,该文件的内容仍然存在,只是硬链接数减一了,如果硬链接数减一后变成了一,这不就是给一个文件取别名吗!!!任意一个文件,无论目录,还是普通文件,都有inode
每一个inode内部,都有一个叫做引用计数的计数器(有多少个文件名指向我!)目录里面保存的是 文件名:inode编号的映射关系
文件名1:inode1234
文件名2:inode1234
文件名3:inode1234
文件名4:inode1234
(多个不同的文件名映射同一个inode)
删除这种链接文件,有两种删发,一种是直接rm +文件名,另一种就是通过:
unlink + [链接文件名]1.3 软硬链接的应用场景
软连接的应用场景
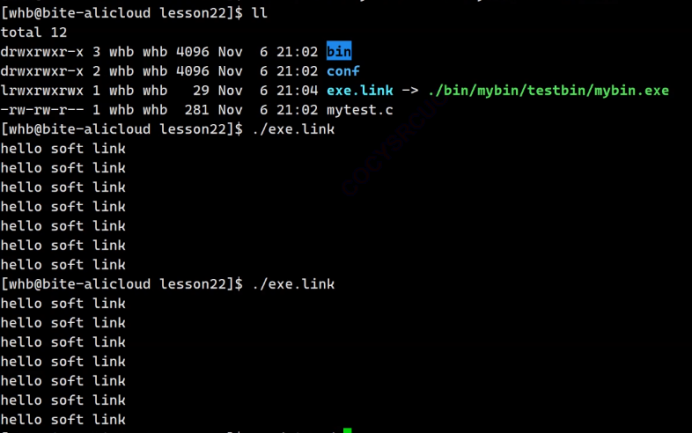
既然软连接里面是存的是被链接的文件的地址,那我们只要一个可执行程序用软链接链接,就不用去找这个文件在哪了,只需要执行软链接,不管这个文件在哪,他都会自动去找到该文件,然后执行!!!
硬连接的应用场景
软连接可以直接链接一个路径很深的可执行程序,可以链接目录。但是硬链接无法链接目录,但'.''...'这两个文件是目录的硬链接,这是因为这是操作系统自己设定的,但操作系统不让也不允许用户给目录链接硬链接,这是因为操作系统不信任用户,用户对目录使用硬链接,很容易就造成目录下的环路问题,进而让操作系统崩溃。
2. 动静态库前置知识
2.1 补充一:数据交换的基本单位
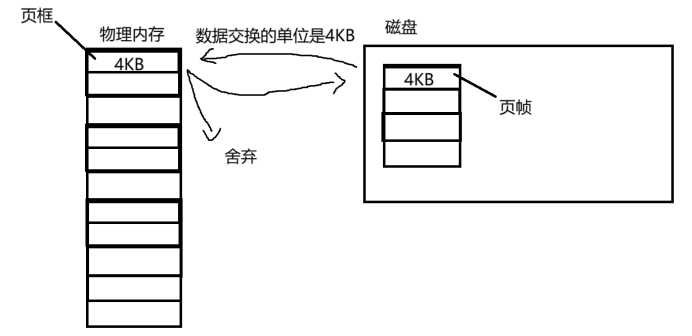
问题一:为什么数据交换的单位是4KB?为什么不是我们需要多少内存空间,就申请多少空间,而是统一的用4KB呢?
1. 减少IO的次数---减少访问外设的次数---硬件
2. 基于局部性原理!!!预加载机制---软件
2.2 补充二:操作系统如何管理内存
操作系统是能看到内存的物理地址的,但用户层只能看到虚拟地址。
问题一:那么操作系统是如何管理内存的呢?
一定是先描述,再组织!!!
struct page {
//page 页必要的属性信息
}
以4GB为例,一个4KB的页框就是一个页
struct page mem_array1048576由于数组是有下标的,数组的下标就是对应的页号,所以,我们对内存的的管理就转变为了对数组进行管理!!!
对于4GB中的一个地址 0x1122 3344,我们只要让他按位 &上0xFFFF F000就能知道他的页号,因为一个页号占4KB,所以,只要将低12位字节置零就可以得到该地址的页号,然后就可以通过该页号,得到对应的数据
所以,我们要访问一个内存,我们只需要先直接找到这个4KB对应的page,就能在系统中找到对应的物理页框。总结:所有申请内存的动作,都是在访问内存page数组!!!
内存管理:
1. 大块内存管理:伙伴系统算法
2. 小块内存管理(不足4KB):slab分派器
2.3 补充三:Linux中,我们每一个进程,打开的每一个文件都要有自己的inode属性和自己的文件页缓冲区
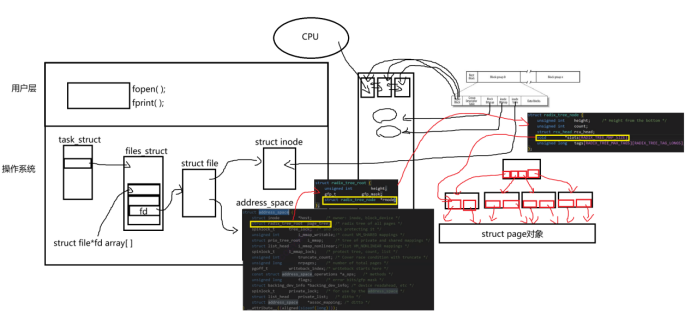
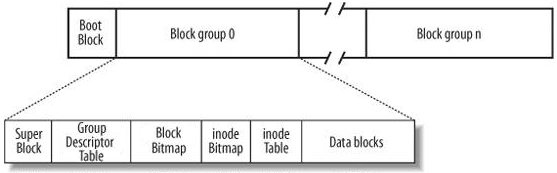
当我们电脑开机的时候,这些分组中的数据(Super Block、Group Descriptor Table、Block Bitmap、inode Bitmap等都会预加载到物理内存中),其中物理内存中会存在一个链表,每一个链表就是一个Super Block的对象,是用双向链表的形式链接起来,当操作系统访问时,就知道每一个分区大概是在什么位置,每个分区中的文件系统大概是什么样,所以很多文件系统上的数据,操作系统已经给我们预加载了。
当我们在打开一个文件时,我们首先要知道该文件的文件路径和文件名,我们打开一个文件,要直接指定该文件的直接或相对路径,我们通过该文件名和文件路径就可以知道在该目录下,该文件名所映射的该文件的inode编号。
一个被打开的文件,该进程的task_struct指向文件描述符数组,在这个数组中,该文件的文件描述符会指向他文件对应的struct file,==当一个文件被打开时,我们最关心的是两个东西,一个是文件的属性,一个是文件的内容!!!==而文件属性基本都在inode Table内的对应inode的inode结构体当中。
问题一:文件的属性怎么获取?
当我们打开一个文件时,操作系统要为我们对应文件的struct file创建一个结构体struct inode,当我们要打开这个文件时,我们就要根据他的文件名,找到对应的inode的编号,然后在我们预加载到物理内存中的inode Bitmap中判断该文件是否存在,然后通过该inode找到inode Table中的inode结构体中的文件属性,将这些文件属性填到系统给struct file创建的struct inode结构体对象中。
问题二:文件的内容怎么获取?
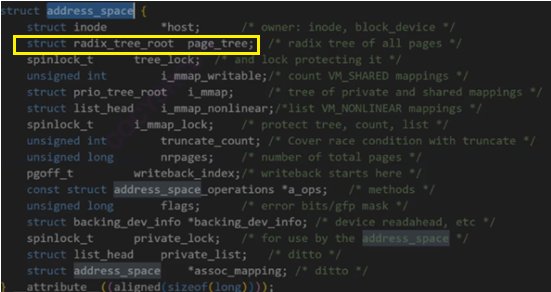
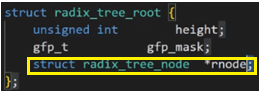
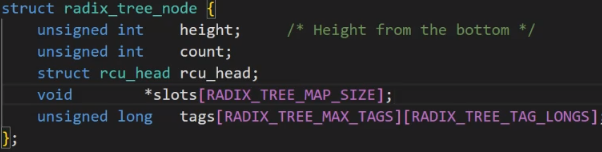
其中struct file中有一个指针指向address space,而这个address space中有一棵radix_tree_root的树(多叉树或字典树),该树的节点内有个slots的(void*)的指针,这就是说,该树的每个叶子节点中,都有很多指针,每一个指针会指向一个个的struct page结构对象,而一个struct page结构就对应一个4KB大小的页,如果我要修改文件中的数据,本质就是通过这样一系列的数据结构找到这样的叶子节点指向的struct page,然后修改其物理内存中的内容!!!而这种一个个的struct page就是文件的页缓冲区!!!
补充四:基数树or基树(本质上是字典树)
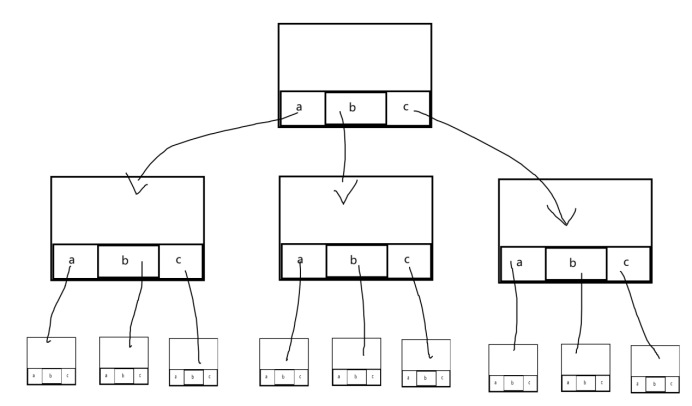
原本字典树是有26个子节点的,这里化简为3个子节点,方便理解。
总结:
本章,从认识到理解,从理解到实现场景,我们知道了什么是软硬链接,通过对四个小点的补充,我们知道了,数据交换的基本单位---页,知道了操作系统是如何管理内存的,又通过对图片的分析,深入清楚了一个被打开的文件在内核部分是如何被修改文件内容的!!!还知道了什么是字典树的一个基本概念!!!本章的补充部分的知识,是为下一篇动静态库而做的铺垫,补齐之前学习的缺口,将知识关联,串联起来!!!