partitionBy
对键值对RDD进行自定义分区,使相同键的数据尽可能分布在同一个分区中(或按指定规则分布)。
示例
join
使用join操作将两个RDD中相同键的值连接在一起,形成嵌套形式的结果。
join示例

转换算子和行动算子
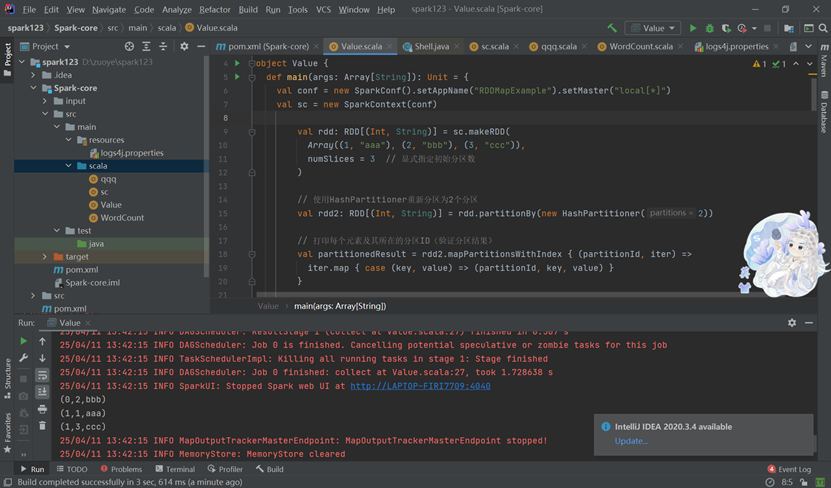
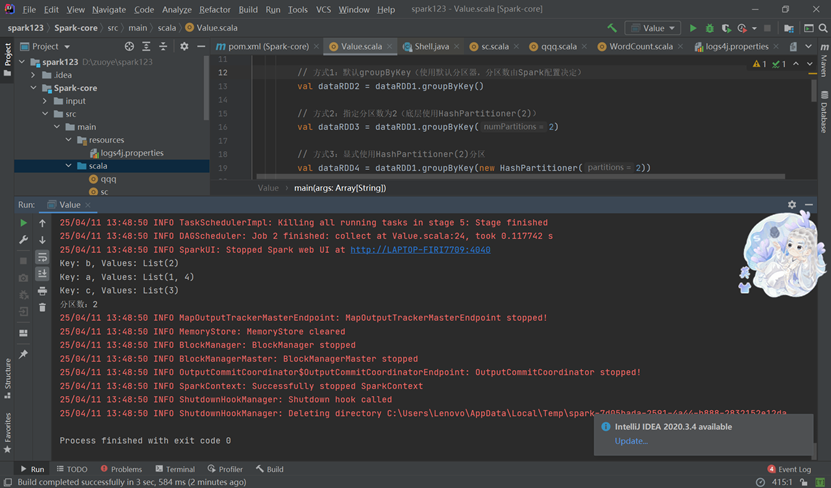
转换算子:各种转换算子(如groupByKey)的作用和用法,这些算子不会立即执行,只有在遇到行动算子时才会触发执行。
groupByKey
示例
代码
运行结果
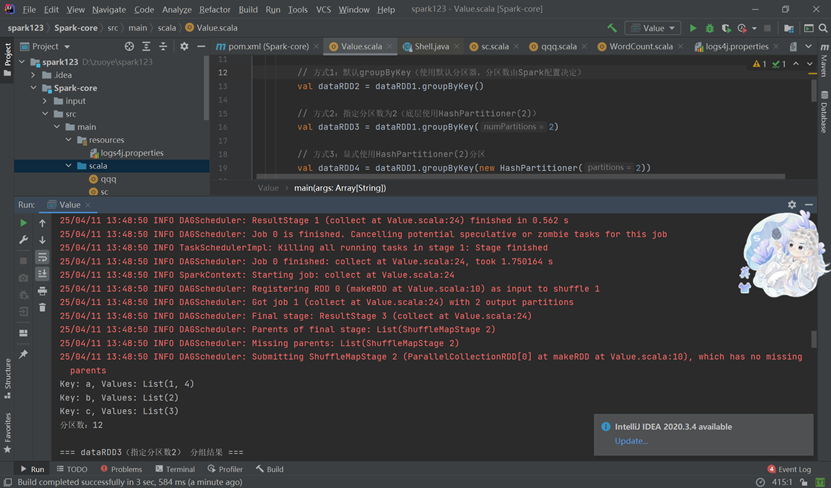
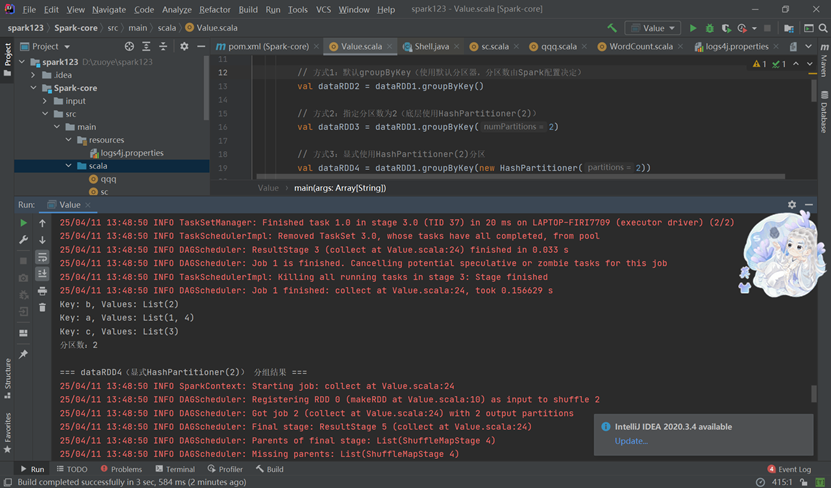
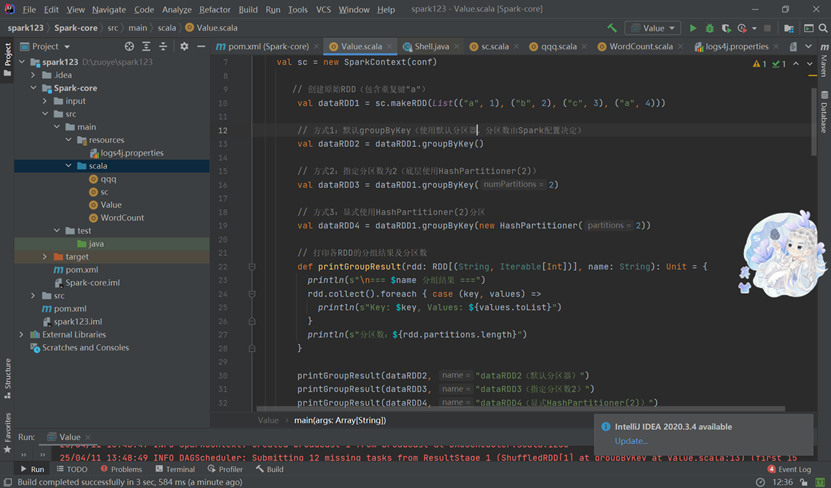
行动算子:行动算子(如collect、reduce、count、first、take等)的作用和用法,这些算子会触发实际的计算并返回结果。
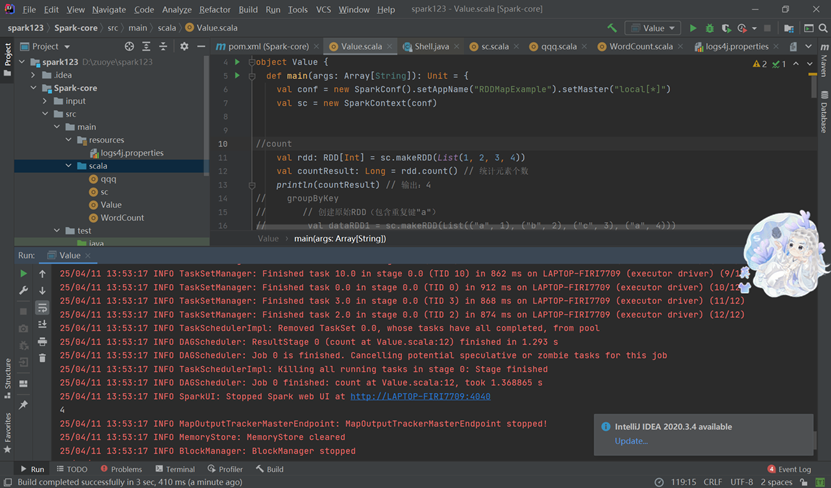
Count
是一个常用的基础算子,用于统计数据集中的元素数量
示例
分布式计算和分区
分布式计算:RDD是分布式数据结构,数据分布在不同的节点上,行动算子在executor端执行,而结果需要在driver端收集。
分区操作:
输出结果:在使用行动算子时,特别是collect操作时需要注意数据量的大小,避免driver内存溢出。
数据结构与变量
Spark 中的三大数据结构:弹性分布式数据集(RDD)、累加器和广播变量。
广播变量在处理较大只读变量时的高效性。