 、
、
Sklearn全称:Scipy-toolkit Learn是 一个基于scipy实现的的开源机器学习库。它提供了大量的算法和工具,用于数据挖掘和数据分析,包括分类、回归、聚类等多种任务。本文我将带你了解并入门Sklearn下的datasets在机器学习中的基本用法。
获取方式
pip install scikit-learn模块结构
在Python中,要想熟练地使用一个库来完成各种任务,那么我们必须得对这个库内各个模块的结构比较熟悉才可以,观察Scikit-learn源代码中的第一级模块,我们不难画出这样的一个树状图用来描述其结构:
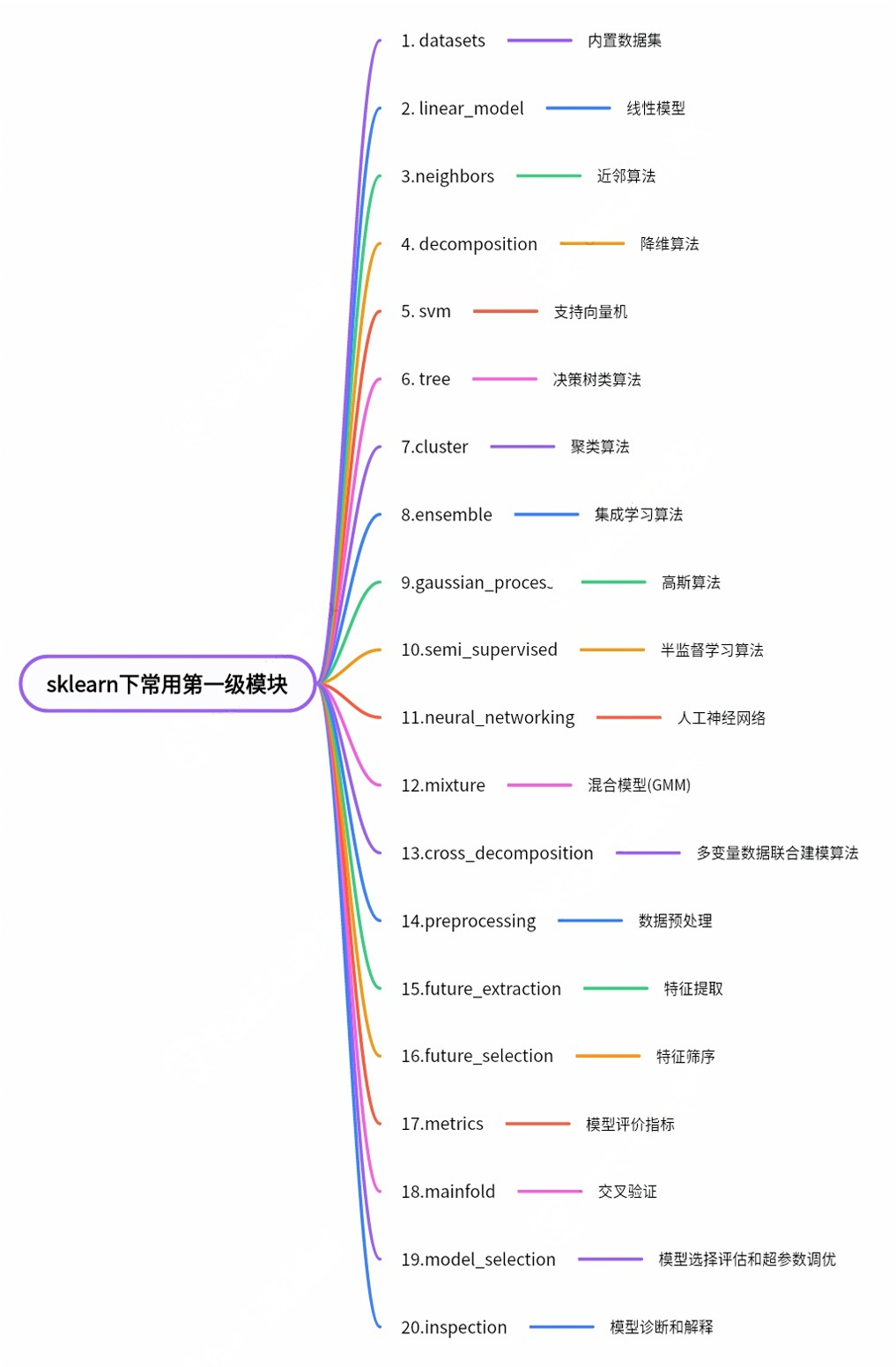
在这其中,datasets为内置数据集,剩下的2-13基本包含了整个机器学习中所有比较经典的算法,后边七个模块是我们在进行机器学习任务时常用的工具。
后续,我将分别为大家介绍这20个模块的基本用法,本文我们着重来了解datasets这个模块的基本用法。
datasets
datasets是sklearn中用来加载预置数据集的模块,其内部主要有以下数据集:
所有数据集
| 数据集名称 | 导入方式 | 样本数×特征数 | 描述 |
|---|---|---|---|
| load_iris | from sklearn.datasets import load_iris |
150×4 | 鸢尾花数据集,包含3类鸢尾花的4个特征(花萼/花瓣长宽) |
| load_digits | from sklearn.datasets import load_digits |
1797×64 | 手写数字(0-9)的8x8像素图像,共10类 |
| load_wine | from sklearn.datasets import load_wine |
178×13 | 葡萄酒化学分析数据,3类意大利不同品种葡萄酒 |
| load_breast_cancer | from sklearn.datasets import load_breast_cancer |
569×30 | 乳腺癌诊断数据,2类(恶性/良性),特征为细胞核的30项测量值 |
| load_diabetes | from sklearn.datasets import load_diabetes |
442×10 | 糖尿病进展指标,10个生理特征(年龄、BMI等),目标为定量病情进展 |
| fetch_california_housing | from sklearn.datasets import fetch_california_housing |
20640×8 | 加州房价数据,包含收入、房龄等特征,目标为房屋中位数价格(回归问题) |
| fetch_olivetti_faces | from sklearn.datasets import fetch_olivetti_faces |
400×4096 | 40人的人脸图像(每人10张),64x64像素,用于人脸识别 |
| fetch_20newsgroups | from sklearn.datasets import fetch_20newsgroups |
文本数据(约18k篇) | 20个新闻组的文本分类数据,需文本向量化处理 |
| make_classification | from sklearn.datasets import make_classification |
可自定义(默认100×20) | 生成合成分类数据,可控制样本数、特征数、类别数等 |
| make_regression | from sklearn.datasets import make_regression |
可自定义(默认100×100) | 生成合成回归数据,可控制噪声、特征重要性等 |
| make_blobs | from sklearn.datasets import make_blobs |
可自定义(默认100×2) | 生成各向同性高斯分布的聚类数据,适用于聚类算法测试 |
| make_moons | from sklearn.datasets import make_moons |
可自定义(默认100×2) | 生成半月形非线性可分数据,用于测试分类算法 |
| make_circles | from sklearn.datasets import make_circles |
可自定义(默认100×2) | 生成同心圆非线性可分数据,用于测试分类算法 |
示例
python
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
#加载iris数据集
iris=load_iris()
X=iris.data#特征 (150, 4)
y=iris.target#三种花的类别(0,1,2)
feature_names=iris.feature_names
target_names=iris.target_names
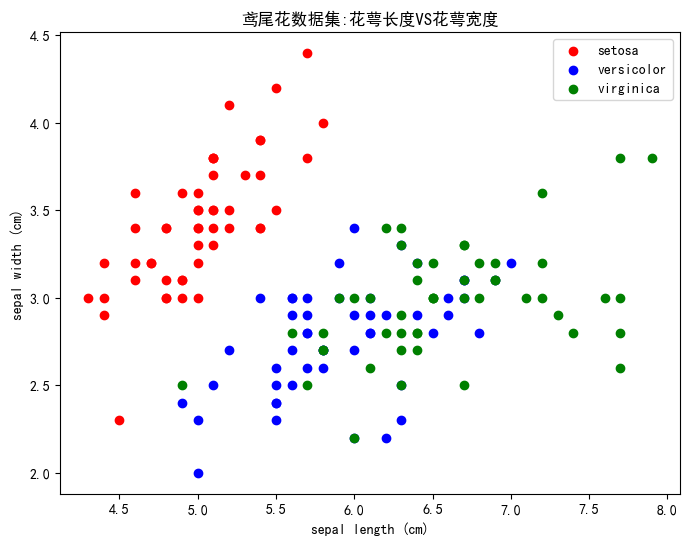
#绘制花萼长度与宽度,其为data下的第0与第1特征
#y==0,y==1,y==2分别表示三中不同类别的花
plt.figure(figsize=(8, 6))
plt.scatter(X[y==0,0], X[y==0,1], color='red', label=target_names[0])
plt.scatter(X[y==1,0], X[y==1,1], color='blue',label=target_names[1])
plt.scatter(X[y==2,0], X[y==2,1], color='green',label=target_names[2])
plt.xlabel(feature_names[0]) #花萼长度
plt.ylabel(feature_names[1]) # 花萼宽度
plt.title("鸢尾花数据集:花萼长度VS花萼宽度")
plt.legend()
plt.show()结果
数据集加载方法
sklearn所有的load_数据集名称 函数的返回值为一个字典**(不指定return_Xy=True时)**,这个字典内部包含的所有属性为:
python
['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module']以load_iris()函数的返回值为例, 其中data是大小为指定形状的ndarray类型数据, feature_names是data中的所有特征名称构成 的列表,feature_names的长度即为data.shape1的值也就是data对应的列数,target为数据集的目标变量( 监督学习中的标签或输出值,在iris数据集中为三种类型的花的名称**)** 也是ndarray的类型
| 键(Key) | 数据类型 | 含义 |
| data | numpy.ndarray (150×4) | 特征数据矩阵,每行代表一个样本,每列代表一个特征(花萼/花瓣的长度和宽度)。 |
| target | numpy.ndarray (150,) | 目标标签(类别),整数编码: 0=setosa, 1=versicolor, 2=virginica。 |
| frame | pandas.DataFrame | 包含 data 和 target 的DataFrame(需 as_frame=True 时返回)。 |
| target_names | numpy.ndarray (3,) | 目标类别名称,对应 target 的标签: ['setosa', 'versicolor', 'virginica']。 |
| feature_names | list (4,) | 特征名称列表: ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']。 |
| DESCR | str | 数据集的完整描述(字符串),包含来源、特征解释等信息。 |
filename |
str |
数据文件的路径(通常用于本地存储的数据集)。 |
|---|
我们在使用时可以通过以下几种方式来获取
通过索引获取
python
from sklearn.datasets import load_iris
'''iris为包含['data', 'target','target_names', 'feature_names]等健的一个字典'''
iris=load_iris()
data=iris['data']
print(data)通过属性获取
python
from sklearn.datasets import load_iris
'''iris为包含['data', 'target','target_names', 'feature_names]等健的一个字典'''
iris=load_iris()
print(iris.data)二者得到的结果是一致的。当然,为了方便我们还可以只返回data与target,需要指定return_Xy=True,此时返回值为tuple类型包含data与target
只获取data与target
当我们将return_X_y指定为True时,函数返回值为data与target构成的tuple
python
from sklearn.datasets import load_iris
X,y=load_iris(return_X_y=True)#X为data,y为target
print(X)获取Dataframe格式数据
当我们将as_frame指定为True时,函数的返回值仍然为字典,要想获取dataframe格式的数据需要通过索引的方式来获取,即'frame'。
python
from sklearn.datasets import load_iris
import pandas as pd
iris=load_iris(as_frame=True)
df=iris['frame']总结

以上便是Sklearn入门之datasets的基本用法的所有内容,如果本文对你有用,免费的三连来一波,感谢各位大佬支持。后续,我还将继续介绍sklearn中其他模块的使用方法。