
♥♥♥~~~~~~欢迎光临知星小度博客空间~~~~~~♥♥♥
♥♥♥零星地变得优秀~也能拼凑出星河~♥♥♥
♥♥♥我们一起努力成为更好的自己~♥♥♥
♥♥♥如果这一篇博客对你有帮助~别忘了点赞分享哦~♥♥♥
♥♥♥如果有什么问题可以评论区留言或者私信我哦~♥♥♥
✨✨✨✨✨✨ 个人主页✨✨✨✨✨✨
在前面的博客中,我们已经学习了部分算法思路,可以解决一些问题了,这一篇博客我们来展开一个新的算法思想------贪心,准备好了吗~我们发车去探索奥秘啦~🚗🚗🚗🚗🚗🚗
目录
前置知识
在真正开始贪心算法题目练习之前,我们首先要了解什么是贪心算法?贪心算法有什么特点?
什么是贪心算法?
我们可以用一句话来概括:贪婪+鼠目寸光
贪心策略: 解决问题的策略,由局部最优------>全局最优
具体步骤:1.把解决问题的过程分为若干步;
2.解决每一步的时候,都选择当前看起来"最优的"解法;(鼠目寸光)
3."希望"得到全局最优解。(不一定就是最优解)
光光看这些步骤会有一点抽象,我们来结合具体例子来看~
举例
找零钱问题

将要解决的问题分为几步,从最大的面值开始计算,找当前花的最少张数,显然答案是正确的,后续我们会进行证明~
最小路径和问题
在前面动态规划我们提到过这个问题,这一次我们试一下使用贪心算法可不可以解决~
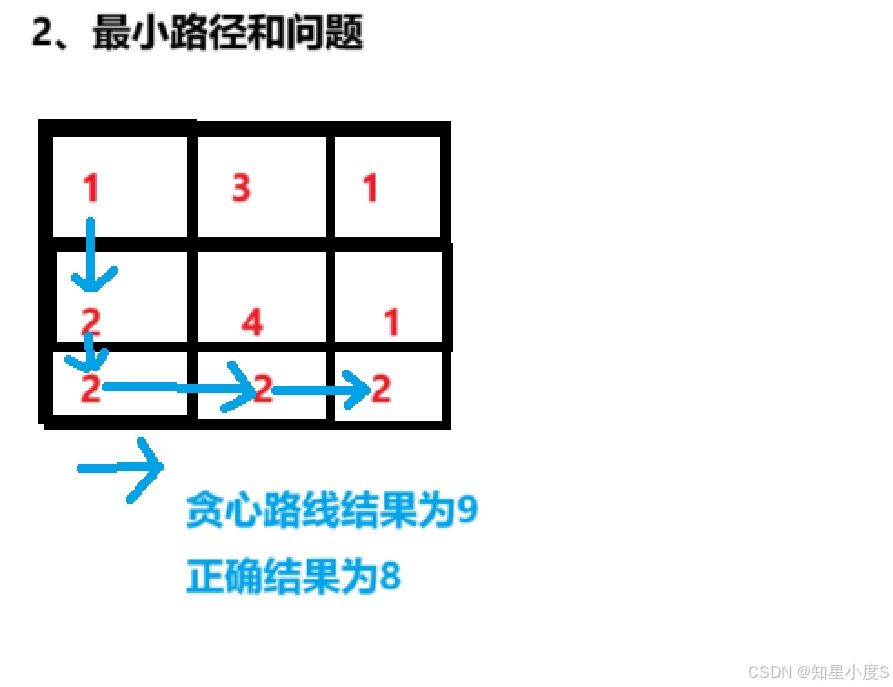
从左上角开始,我们每一步都按当前位置的最优选择(局部最优解)进行,但是不难发现结果是错误的~所以我们是"希望"得到全局最优解,但是结果不一定近人意,我们就需要更改我们的贪心策略~
贪心算法的特点
结合前面的例子,我们可以发现贪心算法有下面的特点:
一、贪心策略的提出
1.贪心策略的提出是没有标准以及模板的
2.可能每一道题的贪心策略都是不同的
二、贪心策略的正确性"贪心策略"可能是一个错误的方法;正确的贪心策略,我们是需要"证明的"。
常用的证明的方法:数学中见过的所有证明方法
接下来,我们就来证明找零钱问题贪心策略的正确性:
我们首先假设最优解得到的面值为20、10、5、1的张数分别为A、B、C、D,我们首先来看看它们的特点/性质:
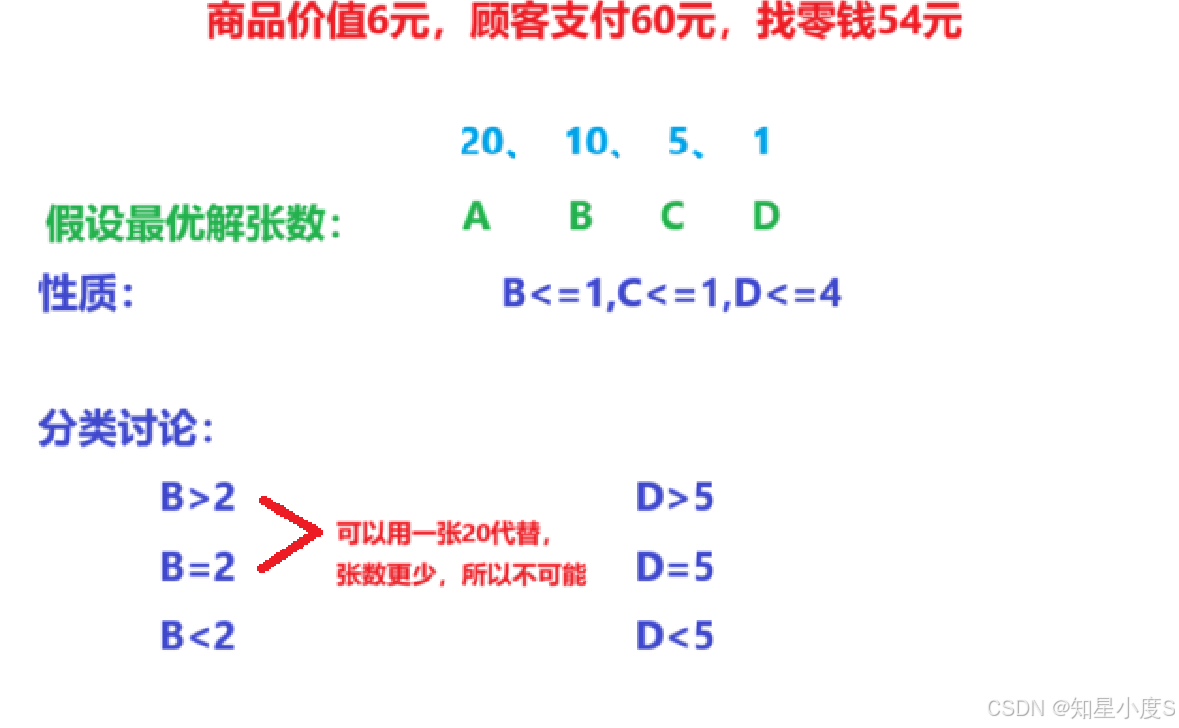
相同的分析可以得到B、C、D满足B<=1,C<=1,D<=4
我们继续来看,假设贪心算法得到的面值为20、10、5、1的张数分别为a、b、c、d~

既然最优解是最少的张数的话,那么我们显然a>=A的,那么我们来分析一下a>A的情况,a大于A说明还有20需要其他面值凑出来,但是B、C、D满足B<=1,C<=1,D<=4,所以最多就是19,不能凑出来20,那么就说明a==A,同理可以得到b==B,c==C,d==D,所以最优解的答案和贪心得到的答案是一样的,那么也就说明是正确的~
因此,正确的贪心策略,我们是需要"证明的",证明结果正确才代表贪心策略正确,证明贪心策略不正确,只需要举一个反例,那么这个时候就需要我们对贪心策略进行调整了~
有了前面的这些小知识点,接下来,我们就来在题目中进行实际应用贪心算法~
柠檬水找零
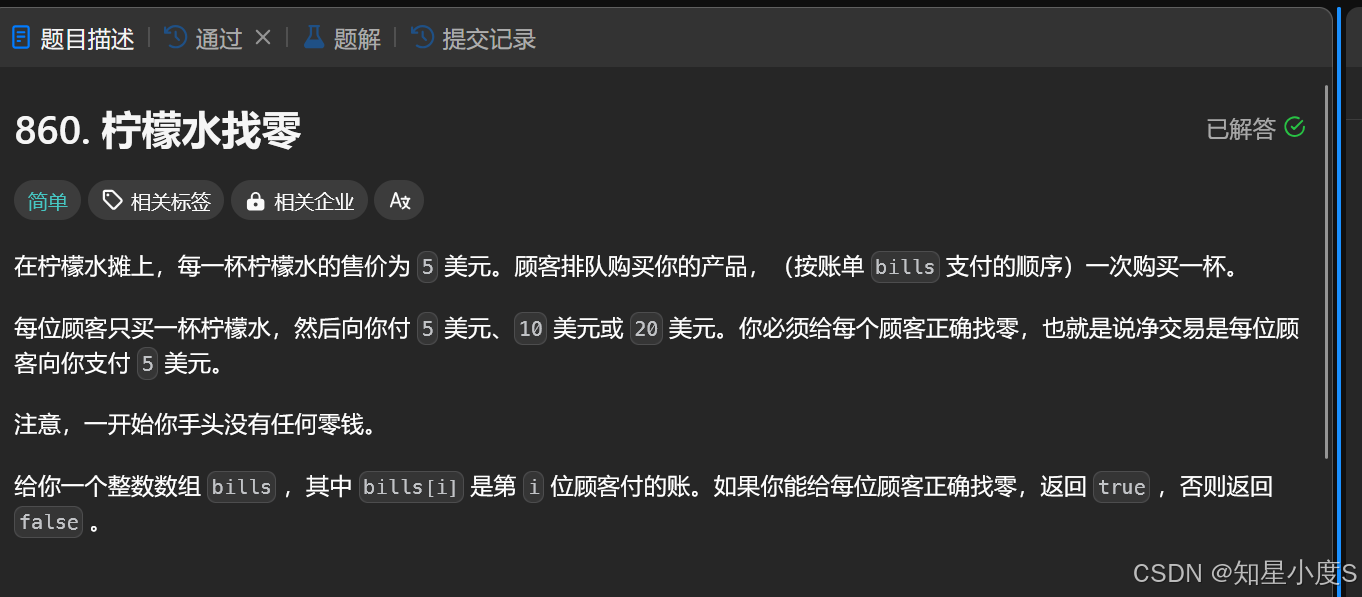

这个题目告诉了我们一杯柠檬水5美元,顾客可能给5美元/10美元/20美元,最开始我们手上没有任何的美元,这也就说明我们只能利用顾客给我们的钱进行找零~并且顾客是排队购买的,必须成功找了零钱才能继续收下一个顾客的钱~
我们来进行分类讨论:
1、如果顾客给的钱是5美元------直接收下
2、如果顾客给的钱是10美元------需要找5美元
3、如果顾客给的钱是20美元------需要找15美元(这里的十五美元就有两种选择了)
①10 + 5 ②5 + 5 + 5
我们主要来分析一下第三种情况,我们优先选择第一种还是第二种呢?
答案是第一种,我们不难发现5美元是有很大用处的,10美元可以找,20美元也可以找,结合我们的生活经验,我们应该尽可能的保留5美元~这里就体现了我们贪心思想,优先选择当前情况下的最优解,最终得到全局的最优解~
有了前面的分析,这道题目的代码实现就比较简单了~
代码实现:
cpp
//柠檬水找零
class Solution
{
public:
bool lemonadeChange(vector<int>& bills)
{
int n = bills.size();
int five = 0, ten = 0;//统计可以找的钱
for (auto x : bills)
{
if (x == 5)//是5元直接收下
{
five++;
}
else if (x == 10)//10元需要找5元
{
//判断是否有五元
if (five)
{
five--;
ten++;
}
else
return false;
}
else//20元需要找15元
{
//贪心思想
//优先10+5
if (five && ten)
{
five--;
ten--;
}
//其次5+5+5
else if (five >= 3)
{
five -= 3;
}
//找不了就return false
else
return false;
}
}
return true;
}
};
顺利通过~
将数组和减半的最小操作数
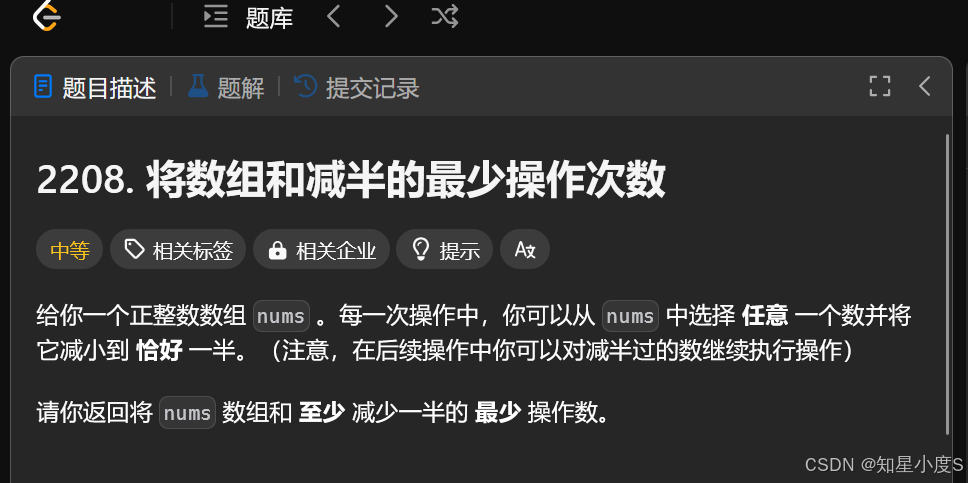


题目要求是比较简单的,我们这里就直接来说一下我们的贪心策略:
贪心策略:
每一次找到数组中最大的数(我们可以使用大根堆)进行减半操作,再把减半的数重新放入数组中,重复操作,找到整个数组和减少一半为止~
贪心策略知道了,代码实现也就更加简单了~
代码实现:
cpp
class Solution
{
public:
int halveArray(vector<int>& nums)
{
//使用大根堆------每次找到最大值减少一半
int n = nums.size();
//减半之后可能是小数,使用double存储
priority_queue<double> heap;
//插入数据+统计数组和
double sum = 0;
for (auto e : nums)
{
heap.push(e);
sum += e;
}
sum /= 2.0;//和先除2
int count = 0;//计数
while (sum > 0)//当减半和>0,进入循环
{
//找到堆顶元素减少一半重新插入
double tmp = heap.top() / 2;
heap.pop();
sum -= tmp;
heap.push(tmp);
count++;
}
return count;
}
};
顺利通过~接下来对我们的贪心策略进行简单的证明~
交换论证法证明:
贪心解选择的数据:A 、B 、C 、D 、E.....x....
最优解选择的数据:a 、 b 、c 、 d、 e......y...
贪心解每一次都是选择最大的数进行减半操作,那么说明贪心解选择的数据 >= 最优解选择的数据,数据相同的情况,我们就不需要处理了,如果说贪心解选择的数据(x)>最优解选择的数据(y)------分情况讨论
1、如果这个数据没有使用过,因为x > y,那么把最优解里面的数据y替换成x,肯定是可以达到数组和减少一半的操作的
2、如果这个数据使用过了,我们也可以把最优解里面的数据y替换成x,只不过更改一下顺序就可以了
最终进行不断地替换完成之后,我们不难发现贪心解和最优解选择的数据个数是相等的,也就是我们想要的结果~
证明结束~
此外,这一篇文章提到的priority_queue也在这里进行简单介绍
priority_queue
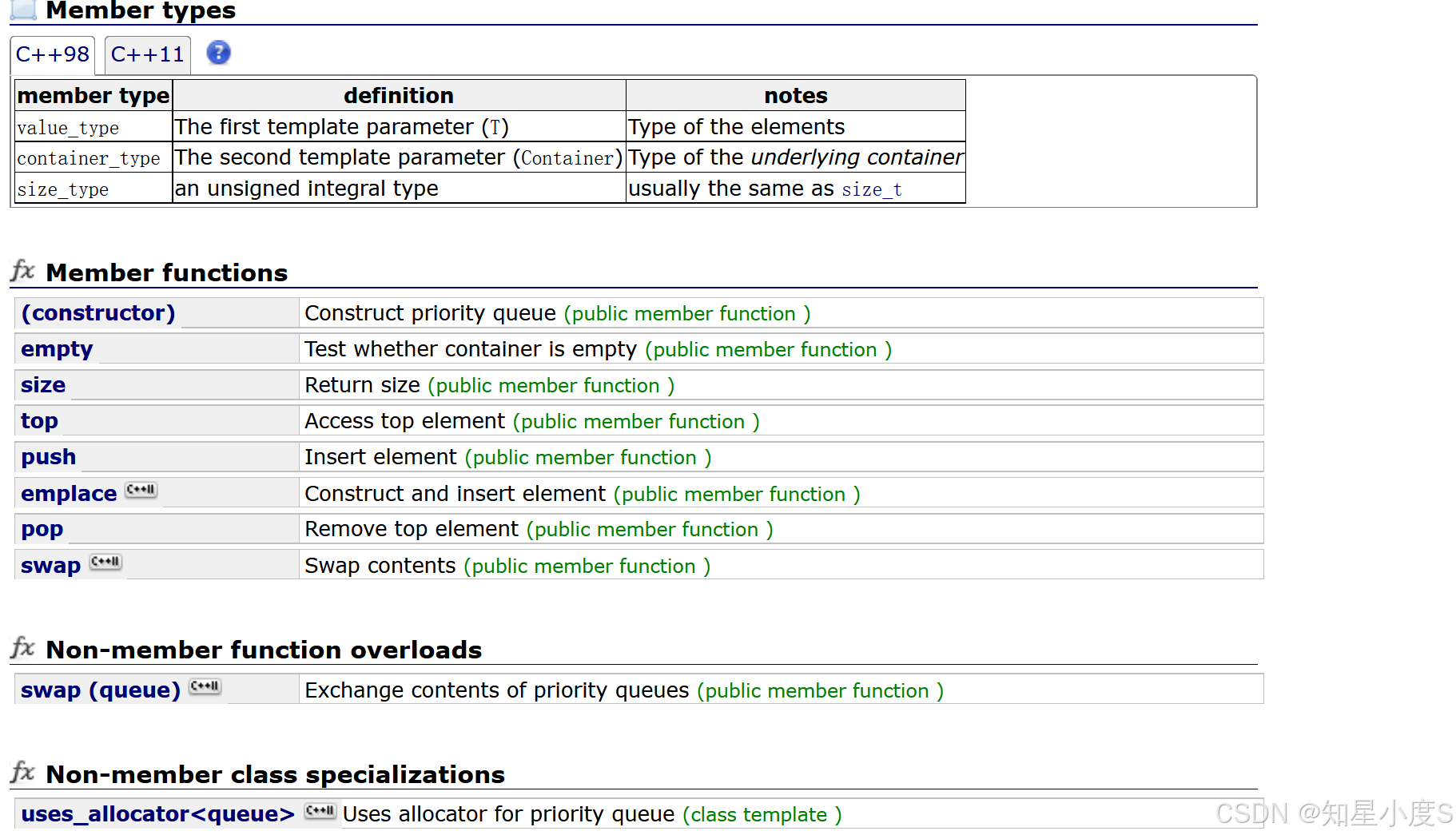
priority_queue(优先队列)是一个基于堆(Heap)结构的容器适配器,用于高效管理元素的优先级。以下是关键点介绍:
核心特性
- 默认最大堆:默认使用大顶堆(最大元素在队首),可通过比较函数改为小顶堆。
- 默认大顶堆:
priority_queue<int> pqmax;- 小顶堆:
priority_queue<int, vector<int>, greater<int>> pqmin;
- 高效操作 :插入(
push)和删除(pop)的时间复杂度为 O(log n) ,访问队首元素(top)为 O(1) - 不支持遍历:内部通过堆实现,直接遍历无法得到有序序列。
常用操作
- 插入元素 :
pq.push(value); - 删除队首 :
pq.pop(); - 访问队首 :
int top = pq.top(); - 判空 :
pq.empty() - 大小 :
pq.size()
如果想了解更加具体的可以访问cplusplus------priority_queue
♥♥♥本篇博客内容结束,期待与各位优秀程序员交流,有什么问题请私信♥♥♥
♥♥♥如果这一篇博客对你有帮助~别忘了点赞分享哦~♥♥♥
✨✨✨✨✨✨个人主页✨✨✨✨✨✨