文献信息 :Pre-Training With Whole Word Masking for Chinese BERT | IEEE Journals & Magazine | IEEE Xplore
哈工大和科大讯飞联合发表的用于中文NLP任务的基于BERT的改进模型,在中文NLP任务取得了最先进的性能。
摘要
原本的BERT使用随机掩蔽的方式进行MLM(masked language model)训练,但这并不一定能很好的训练中文语言场景下的模型。
本文提出了适用于中文BERT的全词掩蔽(wwm)策略,并训练了一系列中文预训练模型。
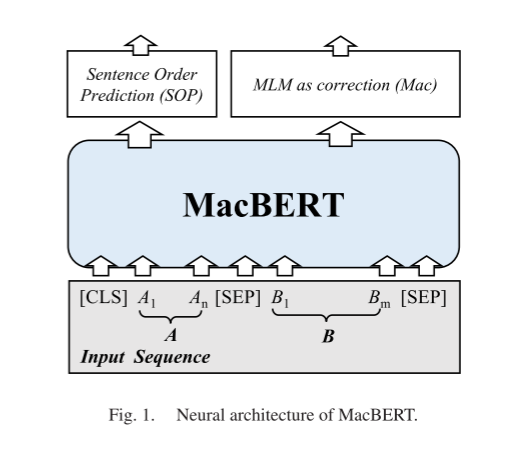
除此之外,还提出了一种新的掩蔽策略,称为 MLM as correction Masking (Mac Masking),引入了MLM as correction任务,这类似于实际的语法或拼写错误修正任务,这种新的预训练任务缓解了预训练和微调阶段的差异。以此从RoBERTa模型中改进而来,提出了MacBERT。
RoBRTa
RoBERTa 模型是BERT 的改进版(A Robustly Optimized BERT,鲁棒优化BERT预训练方法)。
在模型规模、算力和数据上,与BERT相比主要有以下几点改进:
- 更大的模型参数量
- 更大bacth size。RoBERTa 在训练过程中使用了更大的bacth size。尝试过从 256 到 8000 不等的bacth size。
- 更多的训练数据(包括:CC-NEWS 等在内的 160GB 纯文本。而最初的BERT使用16GB BookCorpus数据集和英语维基百科进行训练)
另外,RoBERTa在训练方法上有以下改进:
- 去掉下一句预测(NSP)任务
- 动态掩码。BERT 依赖随机掩码和预测 token。原版的 BERT 实现在数据预处理期间执行一次掩码,得到一个静态掩码。 而 RoBERTa 使用了动态掩码:每次向模型输入一个序列时都会生成新的掩码模式。这样,在大量数据不断输入的过程中,模型会逐渐适应不同的掩码策略,学习不同的语言表征。
- 文本编码。Byte-Pair Encoding(BPE)是字符级和词级别表征的混合,支持处理自然语言语料库中的众多常见词汇。原版的 BERT 实现使用字符级别的 BPE 词汇,大小为 30K,是在利用启发式分词规则对输入进行预处理之后学得的。Facebook 研究者没有采用这种方式,而是考虑用更大的 byte 级别 BPE 词汇表来训练 BERT,这一词汇表包含 50K 的 subword 单元,且没有对输入作任何额外的预处理或分词。
RoBERTa建立在BERT的语言掩蔽策略的基础上,修改BERT中的关键超参数,包括删除BERT的下一个句子训练前目标,以及使用更大的bacth size和学习率进行训练。RoBERTa也接受了比BERT多一个数量级的训练,时间更长。这使得RoBERTa表示能够比BERT更好地推广到下游任务。
全词掩码
在最初的BERT中,使用WordPiece标记器将文本拆分为WordPiece标记,其中一些单词被拆分为几个小片段。全词掩蔽(wwm)减轻了只对整个词的一部分进行掩蔽的缺点,使模型更容易预测。在汉语条件下,WordPiece标记器不再将单词分割成小片段,因为汉字不是由类似字母的符号组成的。
使用传统的中文分词(CWS)工具将文本分割成几个单词。这样,我们就可以采用中文的整词掩码来掩码单词,而不是单个的汉字。在实现上,我们严格遵循原有的整字掩码,不改变其他组成部分,比如字掩码的百分比等。我们使用LTP进行中文分词,识别词的边界。注意,整个词屏蔽只影响预训练阶段屏蔽token的选择。我们仍然使用WordPiece标记器来分割文本,这与原始BERT相同。
WWM全词掩码顾名思义就是,把这一段词隶属的原词,整个都mask掉,那显然模型的预测难度就会增加了英文这样的方法提升可能不够直观或者不够明显,但是对于中文来说,全词遮罩的处理会好很多。
因为中文词语通常由多个单字组成,对于中文全词掩码来说,就是要把整个词语全mask掉,这样预测难度就比mask单字的难度更高,从而逼迫模型学会理解上下文的信息。比如下图中的"语言M型"和"语言MM"。

Mac
(mask Language Model, MLM)是BERT及其变体中最重要的预训练任务,它对双向上下文推理能
力进行建模。然而,其中预训练阶段的人工token,如MASK,从未出现在真正的下游微调任务中。
为了解决这个问题,我们提出了一种新的预训练任务,称为MLM as correction(Mac)。
在这个预训练任务中,我们不采用任何预定义的令牌来进行屏蔽。相反,我们将原始的MLM转换为文本更正任务,模型应该将错误的单词更正为正确的单词,这比MLM要自然得多。具体来说,在
Mac任务中,本文对原来的MLM进行了以下修改。
- 我们使用wwm全词掩蔽以及N-gram masking策略来选择用于掩蔽的候选标记,对于单词级的unigram到4-gram,百分比为40%,30%,20%,10%。
- 使用类似的单词来进行掩码,而不是使用MASK标记进行掩码,因为MASK标记在微调阶段从未出现过。通过使用Synonyms toolkit3获得相似的单词,该工具基于word2vec相似性计算。在极少数情况下,当没有相似的单词时,我们降级为使用随机单词替换。
- 使用15%的输入单词进行掩蔽,其中80%的标记被相似的单词替换,10%的标记被随机单词替换,其余10%保留原始单词。
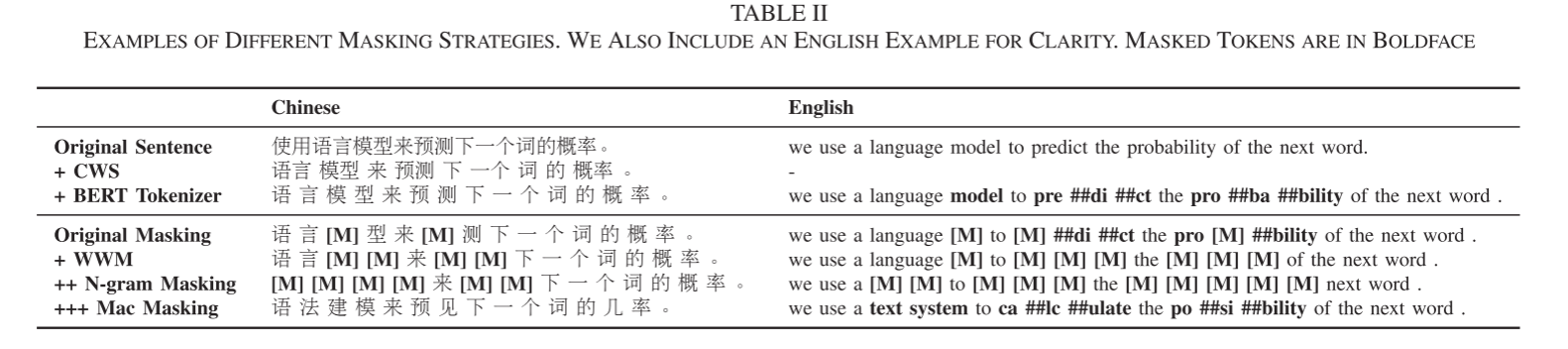
Mac Masking将相似词作为MASK标记,使得填空任务变成文本更正任务,使得微调时的输入与预训练时的输入一致性更高。
结果
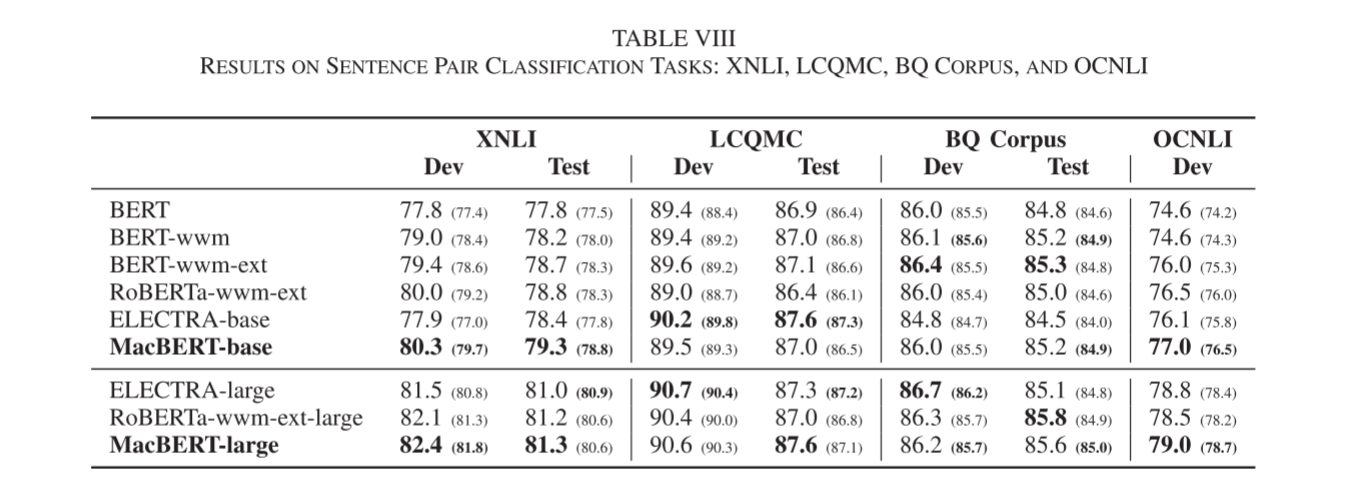
该模型在不同的自然语言处理任务中进行了验证,从句子到文档,包括机器阅读理解(CMRC2018,DRCD,CJRC)、自然语言推理(XNLI)、情感分类(ChnSentiCorp)、句子对匹配(LCQMC, BQ语料库)和文档分类(THUCNews),均取得了更有效的结果。
实验
使用chinese-roberta-wwm-ext预训练模型进行微调,用于中文的情感分析任务。具体模型名称是chinese-roberta-wwm-ext-large。
数据集使用lansinuote/ChnSentiCorp · Datasets at Hugging Face。是一个中文数据集,来自互联网的酒店评价,一共12k条数据,标签为0(negtive)或1(postive)。
加载数据集
python
from datasets import load_dataset, load_from_disk
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
# # 下载并保存数据集
# dataset = load_dataset('lansinuote/ChnSentiCorp')
# dataset.save_to_disk('datasets/ChnSentiCorp')
# 加载数据集
dataset = load_from_disk('datasets/ChnSentiCorp')
print(dataset)将文本向量化
python
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('hfl/chinese-roberta-wwm-ext')
def tokenize_func(data):
return tokenizer(data['text'], padding='max_length', max_length=128, truncation=True)
dataset_tokenized = dataset.map(tokenize_func, batched=True)这里我们只取1.2k数据,缩短训练时间
python
train_dataset_tokenized = dataset_tokenized['train'].shuffle(seed=0).select(range(1000))
print(train_dataset_tokenized)
test_dataset_tokenized = dataset_tokenized['test'].shuffle(seed=0).select(range(200))
print(test_dataset_tokenized)加载模型
python
from transformers import AutoModelForSequenceClassification
# # 下载和保存模型
# model = AutoModelForSequenceClassification.from_pretrained(r'E:\xiao_yu\Program\GPT-SoVITS-20240821v2\GPT_SoVITS\pretrained_models\chinese-roberta-wwm-ext-large', num_labels=2,)
# model.save_pretrained('models/chinese-roberta-wwm-ext')
# 加载模型
model = AutoModelForSequenceClassification.from_pretrained('models/chinese-roberta-wwm-ext', num_labels=2)设置参数,训练模型
python
from transformers import Trainer, TrainingArguments
training_args = TrainingArguments(
output_dir='output',
eval_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
num_train_epochs=3,
weight_decay=0.01,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset_tokenized,
eval_dataset=test_dataset_tokenized
)
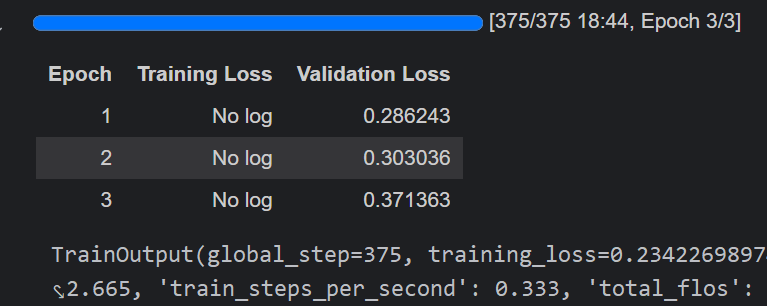
trainer.train()3个epoch要训练15分钟(RTX 4060)。因为使用的模型chinese-roberta-wwm-ext-large参数量比较大。
计算准确率
python
import numpy as np
# 预测结果
prediction_output = trainer.predict(test_dataset_tokenized)
pred_labels = np.argmax(prediction_output.predictions, -1)
true_labels = prediction_output.label_ids
acc = (pred_labels == true_labels).mean()
print(f"Accuracy on test_dataset: {acc:.4f}")虽然训练时间较久但是准确率很高,92%
