字节 Seed 团队视频生成基础模型,来了。
Seaweed 海藻,"Seed-Video" 的缩写_(真是好一个谐音梗!)_。

首发仅 70 亿参数,却能实现超越同类 140 亿参数视频模型的效果------
它能根据文本描述创建各种分辨率_(原生支持 1280x720 分辨率)_、任意宽高比和时长的视频。

比如直接来个 20 秒的 Driving 长镜头。
与其他模型对比情况。
图像到视频任务。

文本到视频的任务。

在单个 H100 GPU 运行中,Seaweed 响应速度是 Wan-2.1(参数量是前者两倍)的 62 分之一。

技术报告:三大技术创新
不过更详细的技术细节,还是集中在技术报告里。
整篇技术报告核心讨论的就是一个问题:在视频生成基础模型的训练上,如何实现低成本高效益。
他们选择训练一个中等规模的模型------约 70 亿个参数的 DiT 模型,使用 665000 个 H100 GPU Hours 从头开始训练该模型,相当于在 1000 个 H100 GPU 上训练 27.7 天。
具体在数据处理、模型架构设计、以及训练策略和优化方面三个方面的技术创新。
首先是数据这块。
他们有一套全面的数据处理管道,其中包括但不限于时间分割、空间裁剪、质量过滤、多视角数据平衡、重复数据删除和视频字幕。

每一个步骤都有他们详细的处理细节。
以字幕任务为例,他们发现使用更大的 72B LLM 可以减少幻觉。但是,使用 72B 模型为数百万个视频生成视频字幕的计算成本要高得多。
于是他们选择将 72B 作为教师模型然后蒸馏出 7B 的学生模型,节约成本的同时还提高了准确率。此外他们还将详细字幕「推导」成简短字幕,类似于思维链过程,结果进一步提高简短字幕的准确率------从 84.81% 到 90.84%。

利用这一基础设施,他们每天可以处理超过 500000 小时的视频数据。
然后再是模型架构设计上面,由 64x 压缩比 VAE 与 Diffusion Transformer 结合组成 Seaweed 。
VAE 这边,由一个编码器和一个解码器组成,编码器将原始像素数据压缩到一个紧凑的潜在空间,解码器则根据这些潜在特征重建原始输入像素。理想的 VAE 应在保持较高重建质量的同时实现较高的压缩比。

这种设计为视频生成提供了两个优势,首先,它统一了图像和视频编码,使第一帧条件图像视频生成任务变得自然。其次,它消除了两个推断片段之间边界的闪烁,并允许编码和解码任意长的视频,而无需人工拼接。
而在 Diffusion Transformer 这边,他们用图像和视频的原始分辨率和持续时间对它们进行混合训练。为了平衡运行时间的计算,较短的序列被打包在一起。

最后就是多阶段多任务学习训练策略。
他们采用了从低分辨率到高分辨率的多阶段渐进式的训练策略。这一设计侧重于在训练过程中战略性地分配 GPU 资源,以提高整体质量。
Pre-Training 阶段,他们只通过低分辨率图像对模型进行预训练,这样就能建立文本摘要与常见视觉概念之间的对齐关系。

Post-training 阶段。我们会应用监督微调(SFT),然后是人类反馈强化学习(RLHF),以进一步提高输出结果的美学质量、动作一致性和结构连贯性。
Just Like This~

这一阶段分别针对文本到视频和图像到视频任务进行。
而在更具体 Infra 层面的优化,他们还做了这些方面的措施。
比如采用并行策略在长语境视频中训练 7B 模型;引入了运行时平衡(Runtime Balance)策略,以减轻图像和视频联合训练过程中的负载不平衡;还设计了多级激活检查点(MLAC),以减少 GPU 内存使用量和重新计算开销。
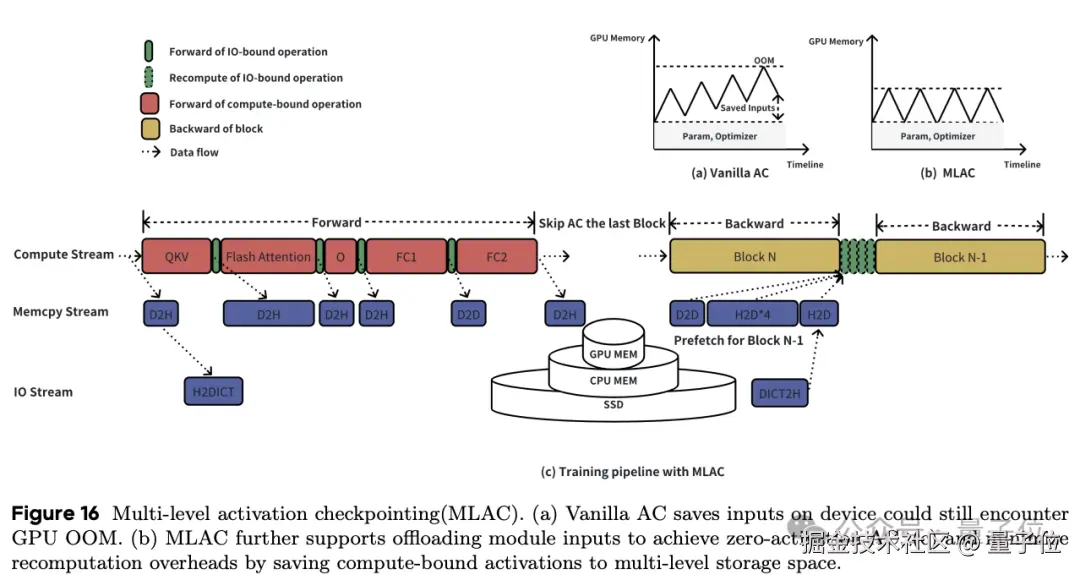
最后,还通过实施融合的 CUDA 内核来简化零散的 I/O 操作,从而优化 GPU 利用率。
因此,在大规模分布式训练中,Seaweed-7B 的模型 FLOPs 利用率(MFU)达到了 38%。

Seed 研究团队大曝光
而在官网最后,背后研究团队也都全部曝光。
由蒋路、冯佳时、杨振恒、杨建超带领的研究团队。

其中蒋路正是去年加盟字节的前谷歌高级科学家,曾负责谷歌视频生成工作,在多个谷歌产品(如 YouTube、云服务、AutoML、广告、Waymo 和翻译)中做出了重要贡献,同时也是 CMU 兼职教授。
冯佳时则是首次曝光的「关键 8 人」之一,大模型视觉基础研究团队负责人,专注于计算机视觉、机器学习领域的相关研究及其在多媒体中的应用。
具体研究团队成员如下:

基础设施以及贡献者还有这些:

参考链接:
1seaweed.video/
2arxiv.org/abs/2504.08...
3x.com/CeyuanY/sta...
欢迎在评论区留下你的想法!