一文速通 Python 并行计算:07 Python 多线程编程-线程池的使用和多线程的性能评估
摘要:
本文介绍了 Python 线程池(ThreadPoolExecutor)的使用方法,包括线程池的基本概念、Future 对象、任务提交方式(map/submit)、结果获取技巧,以及多线程性能评估工具 VizTracer 的使用。

关于我们更多介绍可以查看云文档: Freak 嵌入式工作室云文档,或者访问我们的 wiki:****https://github.com/leezisheng/Doc/wik
原文链接:
往期推荐:
全网最适合入门的面向对象编程教程:00 面向对象设计方法导论
全网最适合入门的面向对象编程教程:01 面向对象编程的基本概念
全网最适合入门的面向对象编程教程:02 类和对象的 Python 实现-使用 Python 创建类
全网最适合入门的面向对象编程教程:03 类和对象的 Python 实现-为自定义类添加属性
全网最适合入门的面向对象编程教程:04 类和对象的Python实现-为自定义类添加方法
全网最适合入门的面向对象编程教程:05 类和对象的Python实现-PyCharm代码标签
全网最适合入门的面向对象编程教程:06 类和对象的Python实现-自定义类的数据封装
全网最适合入门的面向对象编程教程:07 类和对象的Python实现-类型注解
全网最适合入门的面向对象编程教程:08 类和对象的Python实现-@property装饰器
全网最适合入门的面向对象编程教程:09 类和对象的Python实现-类之间的关系
全网最适合入门的面向对象编程教程:10 类和对象的Python实现-类的继承和里氏替换原则
全网最适合入门的面向对象编程教程:11 类和对象的Python实现-子类调用父类方法
全网最适合入门的面向对象编程教程:12 类和对象的Python实现-Python使用logging模块输出程序运行日志
全网最适合入门的面向对象编程教程:13 类和对象的Python实现-可视化阅读代码神器Sourcetrail的安装使用
全网最适合入门的面向对象编程教程:全网最适合入门的面向对象编程教程:14 类和对象的Python实现-类的静态方法和类方法
全网最适合入门的面向对象编程教程:15 类和对象的 Python 实现-__slots__魔法方法
全网最适合入门的面向对象编程教程:16 类和对象的Python实现-多态、方法重写与开闭原则
全网最适合入门的面向对象编程教程:17 类和对象的Python实现-鸭子类型与"file-like object"
全网最适合入门的面向对象编程教程:18 类和对象的Python实现-多重继承与PyQtGraph串口数据绘制曲线图
全网最适合入门的面向对象编程教程:19 类和对象的 Python 实现-使用 PyCharm 自动生成文件注释和函数注释
全网最适合入门的面向对象编程教程:20 类和对象的Python实现-组合关系的实现与CSV文件保存
全网最适合入门的面向对象编程教程:21 类和对象的Python实现-多文件的组织:模块module和包package
全网最适合入门的面向对象编程教程:22 类和对象的Python实现-异常和语法错误
全网最适合入门的面向对象编程教程:23 类和对象的Python实现-抛出异常
全网最适合入门的面向对象编程教程:24 类和对象的Python实现-异常的捕获与处理
全网最适合入门的面向对象编程教程:25 类和对象的Python实现-Python判断输入数据类型
全网最适合入门的面向对象编程教程:26 类和对象的Python实现-上下文管理器和with语句
全网最适合入门的面向对象编程教程:27 类和对象的Python实现-Python中异常层级与自定义异常类的实现
全网最适合入门的面向对象编程教程:28 类和对象的Python实现-Python编程原则、哲学和规范大汇总
全网最适合入门的面向对象编程教程:29 类和对象的Python实现-断言与防御性编程和help函数的使用
全网最适合入门的面向对象编程教程:30 Python的内置数据类型-object根类
全网最适合入门的面向对象编程教程:31 Python的内置数据类型-对象Object和类型Type
全网最适合入门的面向对象编程教程:32 Python的内置数据类型-类Class和实例Instance
全网最适合入门的面向对象编程教程:33 Python的内置数据类型-对象Object和类型Type的关系
全网最适合入门的面向对象编程教程:34 Python的内置数据类型-Python常用复合数据类型:元组和命名元组
全网最适合入门的面向对象编程教程:35 Python的内置数据类型-文档字符串和__doc__属性
全网最适合入门的面向对象编程教程:36 Python的内置数据类型-字典
全网最适合入门的面向对象编程教程:37 Python常用复合数据类型-列表和列表推导式
全网最适合入门的面向对象编程教程:38 Python常用复合数据类型-使用列表实现堆栈、队列和双端队列
全网最适合入门的面向对象编程教程:39 Python常用复合数据类型-集合
全网最适合入门的面向对象编程教程:40 Python常用复合数据类型-枚举和enum模块的使用
全网最适合入门的面向对象编程教程:41 Python常用复合数据类型-队列(FIFO、LIFO、优先级队列、双端队列和环形队列)
全网最适合入门的面向对象编程教程:42 Python常用复合数据类型-collections容器数据类型
全网最适合入门的面向对象编程教程:43 Python常用复合数据类型-扩展内置数据类型
全网最适合入门的面向对象编程教程:44 Python内置函数与魔法方法-重写内置类型的魔法方法
全网最适合入门的面向对象编程教程:45 Python实现常见数据结构-链表、树、哈希表、图和堆
全网最适合入门的面向对象编程教程:46 Python函数方法与接口-函数与事件驱动框架
全网最适合入门的面向对象编程教程:47 Python函数方法与接口-回调函数Callback
全网最适合入门的面向对象编程教程:48 Python函数方法与接口-位置参数、默认参数、可变参数和关键字参数
全网最适合入门的面向对象编程教程:49 Python函数方法与接口-函数与方法的区别和lamda匿名函数
全网最适合入门的面向对象编程教程:50 Python函数方法与接口-接口和抽象基类
全网最适合入门的面向对象编程教程:51 Python函数方法与接口-使用Zope实现接口
全网最适合入门的面向对象编程教程:52 Python函数方法与接口-Protocol协议与接口
全网最适合入门的面向对象编程教程:53 Python字符串与序列化-字符串与字符编码
全网最适合入门的面向对象编程教程:54 Python字符串与序列化-字符串格式化与format方法
全网最适合入门的面向对象编程教程:55 Python字符串与序列化-字节序列类型和可变字节字符串
全网最适合入门的面向对象编程教程:56 Python字符串与序列化-正则表达式和re模块应用
全网最适合入门的面向对象编程教程:57 Python字符串与序列化-序列化与反序列化
全网最适合入门的面向对象编程教程:58 Python字符串与序列化-序列化Web对象的定义与实现
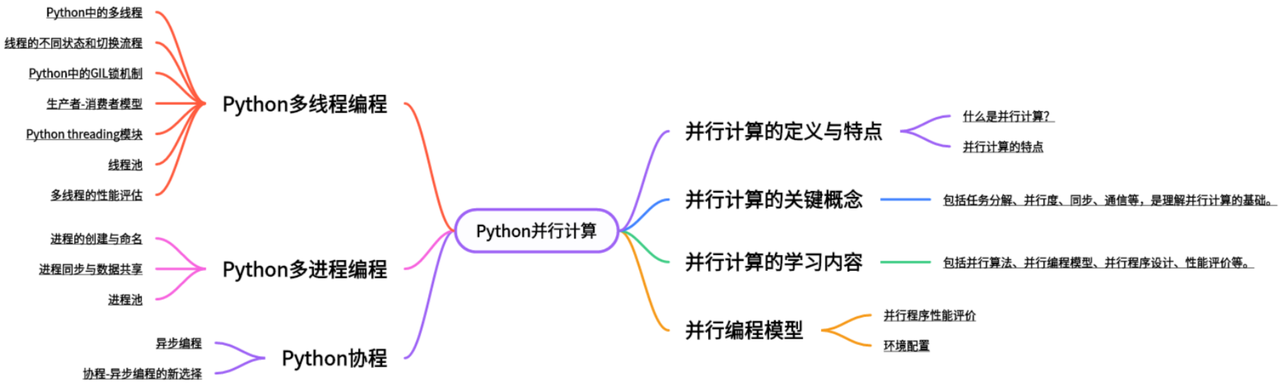
全网最适合入门的面向对象编程教程:59 Python并行与并发-并行与并发和线程与进程
一文速通Python并行计算:01 Python多线程编程-基本概念、切换流程、GIL锁机制和生产者与消费者模型
一文速通Python并行计算:02 Python多线程编程-threading模块、线程的创建和查询与守护线程
一文速通Python并行计算:03 Python多线程编程-多线程同步(上)---基于互斥锁、递归锁和信号量
一文速通Python并行计算:04 Python多线程编程-多线程同步(下)---基于条件变量、事件和屏障
一文速通Python并行计算:05 Python多线程编程-线程的定时运行
一文速通Python并行计算:06 Python多线程编程-基于队列进行通信
更多精彩内容可看:
给你的 Python 加加速:一文速通 Python 并行计算
一个MicroPython的开源项目集锦:awesome-micropython,包含各个方面的Micropython工具库
Avnet ZUBoard 1CG开发板---深度学习新选择
万字长文手把手教你实现MicroPython/Python发布第三方库
文档获取:
可访问如下链接进行对文档下载:
https://github.com/leezisheng/Doc
该文档是一份关于 并行计算 和 Python 并发编程 的学习指南,内容涵盖了并行计算的基本概念、Python 多线程编程、多进程编程以及协程编程的核心知识点:
正文
1.线程池的基本概念和使用方法
系统启动一个新线程的成本是比较高的,因为它涉及与操作系统的交互。在这种情形下,使用线程池可以很好地提升性能,尤其是当程序中需要创建大量生存期很短暂的线程时,更应该考虑使用线程池。
线程池在系统启动时即创建大量空闲的线程 ,程序只要将一个函数提交给线程池,线程池就会启动一个空闲的线程来执行它。当该函数执行结束后,该线程并不会死亡,而是再次返回到线程池中变成空闲状态,等待执行下一个函数。
此外,**使用线程池可以有效地控制系统中并发线程的数量。**当系统中包含有大量的并发线程时,会导致系统性能急剧下降,甚至导致 Python 解释器崩溃,而线程池的最大线程数参数可以控制系统中并发线程的数量不超过此数。
1.1 ThreadPoolExecutor 类
线程池的基类是 concurrent.futures 模块中的 Executor,Executor 提供了两个子类,即 ThreadPoolExecutor 和 ProcessPoolExecutor,其中 ThreadPoolExecutor 用于创建线程池,而 ProcessPoolExecutor 用于创建进程池。
如果使用线程池来管理并发编程,那么只要将相应的 task 函数提交给线程池,剩下的事情就由线程池来搞定。
Exectuor 提供了如下常用方法:
submit(fn, *args, **kwargs):将fn函数提交给线程池,*args代表传给 fn 函数的参数,*kwargs代表以关键字参数的形式为fn函数传入参数。map(func, *iterables, timeout=None, chunksize=1):该函数类似于全局函数map(func, *iterables),只是该函数将会启动多个线程,以异步方式立即对 iterables 执行 map 处理。shutdown(wait=True):关闭线程池。
1.2 Future 对象
程序将 task 函数提交(submit)给线程池后,submit 方法会返回一个 Future 对象,Future 类主要用于获取线程任务函数的返回值。 由于线程任务会在新线程中以异步方式执行,因此,线程执行的函数相当于一个"将来完成"的任务,所以 Python 使用 Future 来代表。
Future 提供了如下方法:
cancel():取消该Future代表的线程任务。如果该任务正在执行,不可取消,则该方法返回False;否则,程序会取消该任务,并返回True。cancelled():返回Future代表的线程任务是否被成功取消。running():如果该Future代表的线程任务正在执行、不可被取消,该方法返回True。done():如果该Future代表的线程任务被成功取消或执行完成,则该方法返回True。result(timeout=None):获取该Future代表的线程任务最后返回的结果。如果 Future 代表的线程任务还未完成,该方法将会阻塞当前线程,其中timeout参数指定最多阻塞多少秒。exception(timeout=None):获取该Future代表的线程任务所引发的异常。如果该任务成功完成,没有异常,则该方法返回None。add_done_callback(fn):为该Future代表的线程任务注册一个"回调函数",当该任务成功完成时,程序会自动触发该fn函数。
在用完一个线程池后,应该调用该线程池的 shutdown() 方法,该方法将启动线程池的关闭序列。调用 shutdown() 方法后的线程池不再接收新任务,但会将以前所有的已提交任务执行完成。当线程池中的所有任务都执行完成后,该线程池中的所有线程都会死亡。
1.3 线程池使用步骤
使用线程池来执行线程任务的步骤如下:
- 调用
ThreadPoolExecutor类的构造器创建一个线程池; - 定义一个普通函数作为线程任务;
- 调用
ThreadPoolExecutor对象的submit()方法来提交线程任务; - 当不想提交任何任务时,调用
ThreadPoolExecutor对象的shutdown()方法来关闭线程池。
1.3.1 提交任务到线程池
在下例中我们定义了任务函数 task_function,该函数接受一个任务作为参数,并打印出任务的信息。并创建了一个线程池,用 submit() 方法将每个任务提交到线程池中执行。 通过使用线程池,我们可以并发地处理队列中的多个任务,提高程序的执行效率。请注意,线程池的大小默认为系统的 CPU 核心数,但也可以通过传递 max_workers 参数来指定线程池的大小。
import concurrent.futures
_# 模拟的任务函数_
def task_function(task):
print(f"Processing task: {task}")
_# 创建线程池_
with concurrent.futures.ThreadPoolExecutor() as executor:
_# 创建一个任务队列_
task_queue = ["Task 1", "Task 2", "Task 3", "Task 4", "Task 5"]
_# 提交任务到线程池_
for task in task_queue:
executor.submit(task_function, task)
_# 等待所有任务完成_
executor.shutdown()
1.3.2 获取线程执行结果
下面代码调用了 Future 的 result() 方法来获取线程任务的返回值:
from concurrent.futures import ThreadPoolExecutor
import threading,time
def test(value1, value2=None):
print("%s threading is printed %s, %s"%(threading.current_thread().name, value1, value2))
time.sleep(2)
return 'finished'
def test_result(future):
print(future.result())
if __name__ == "__main__":
threadPool = ThreadPoolExecutor(max_workers=4, thread_name_prefix="test_")
for i in range(0,10):
future = threadPool.submit(test, i,i+1)
print(future.result())
threadPool.shutdown(wait=True)
print('main finished')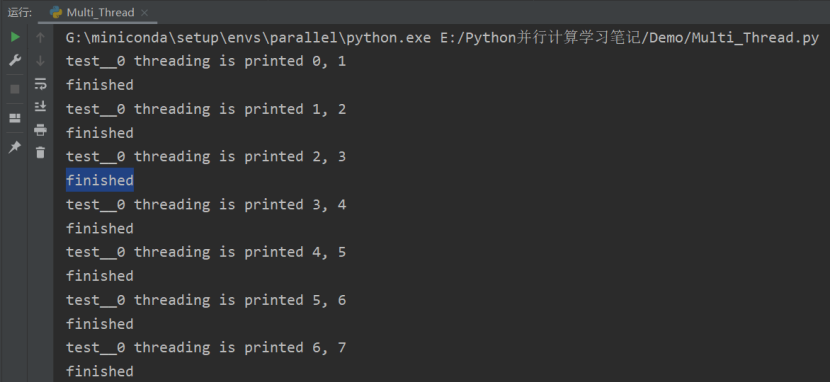
但该方法会阻塞当前主线程,只有等到子线程任务完成后,result() 方法的阻塞才会被解除。如果程序不希望直接调用 result() 方法阻塞线程,则可通过 Future 的 add_done_callback() 方法来添加回调函数,该回调函数形如 fn(future)。当线程任务完成后,程序会自动触发该回调函数,并将对应的 Future 对象作为参数传给该回调函数。
from concurrent.futures import ThreadPoolExecutor
import threading,time
def test(value1, value2=None):
print("%s threading is printed %s, %s"%(threading.current_thread().name, value1, value2))
time.sleep(2)
return 'finished'
def test_result(future):
future.add_done_callback(test_result)
if __name__ == "__main__":
threadPool = ThreadPoolExecutor(max_workers=4, thread_name_prefix="test_")
for i in range(0,10):
future = threadPool.submit(test, i,i+1)
print(future.result())
threadPool.shutdown(wait=True)
print('main finished')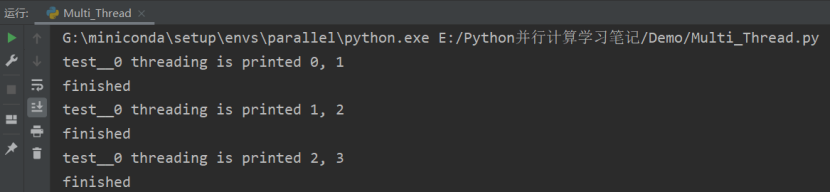
另外,由于线程池实现了上下文管理协议(Context Manage Protocol),因此,程序可以使用 with 语句来管理线程池,这样即可避免手动关闭线程池。
1.3.3 使用 ThreadPoolExecutor 的 map 方法
Exectuor 还提供了一个 map(func, *iterables, timeout=None, chunksize=1) 方法,该方法的功能类似于全局函数 map(),区别在于线程池的 map() 方法会为 iterables 的每个元素启动一个线程,以并发方式来执行 func 函数。这种方式相当于启动 len(iterables) 个线程,井收集每个线程的执行结果。
以下是一个示例,展示如何使用 ThreadPoolExecutor 的 map 方法处理队列中的多个任务:
import concurrent.futures
_# 模拟的任务函数_
def task_function(task):
print(f"Processing task: {task}")
return task.upper()
_# 创建线程池_
with concurrent.futures.ThreadPoolExecutor() as executor:
_# 创建一个任务队列_
task_queue = ["Task 1", "Task 2", "Task 3", "Task 4", "Task 5"]
_# 使用map方法处理任务队列_
results = executor.map(task_function, task_queue)
_# 获取任务的执行结果_
for result in results:
print(f"Task result: {result}")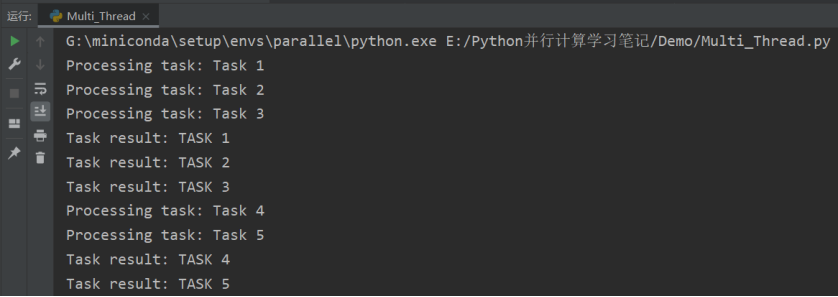
在上面的示例中,我们定义了一个模拟的任务函数 task_function,该函数接受一个任务作为参数,并打印出任务的信息。在任务函数中,我们将任务转换为大写并返回。
然后,我们使用 ThreadPoolExecutor 创建了一个线程池。接下来,我们创建了一个任务队列 task_queue,其中包含了多个任务。
然后,我们使用 executor.map() 方法将任务函数和任务队列作为参数传递给 map 方法,map 方法会自动将任务分配给线程池中的线程进行并发执行,并返回结果的迭代器 results。
最后,我们使用 for 循环遍历 results 迭代器,获取每个任务的执行结果,并打印出来。
通过使用 map 方法,可以更简洁地处理队列中的多个任务,并且可以方便地获取任务的执行结果。请注意,map****方法会按照任务在任务队列中的顺序返回结果,即使任务的执行顺序可能不同。
2.多线程的性能评估
前文已经介绍过,GIL 是 CPython 解释器引入的锁,GIL 在解释器层面阻止了真正的并行运行。 解释器在执行任何线程之前,必须等待当前正在运行的线程释放 GIL。事实上,解释器会强迫想要运行的线程必须拿到 GIL 才能访问解释器的任何资源,例如栈或 Python 对象等。这也正是 GIL 的目的------**阻止不同的线程并发访问 Python 对象。**这样 GIL 可以保护解释器的内存,让垃圾回收工作正常。但事实上,这却造成了程序员无法通过并行执行多线程来提高程序的性能。如果我们去掉 CPython 的 GIL,就可以让多线程真正并行执行。GIL 并没有影响多处理器并行的线程,只是限制了一个解释器只能有一个线程在运行。
这里,我们使用 VizTracer 对多线程进行性能评估。
首先进行安装:pip install viztracer
这里,我们使用 LIFO 队列的代码进行测试:
viztracer Multi_Thread.py
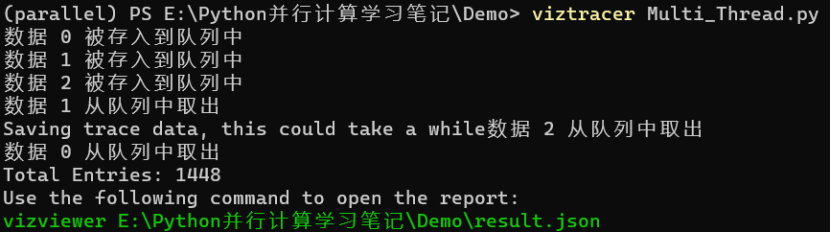
按照提示,输入指令:vizviewer E:\Python 并行计算学习笔记\Demo\result.json
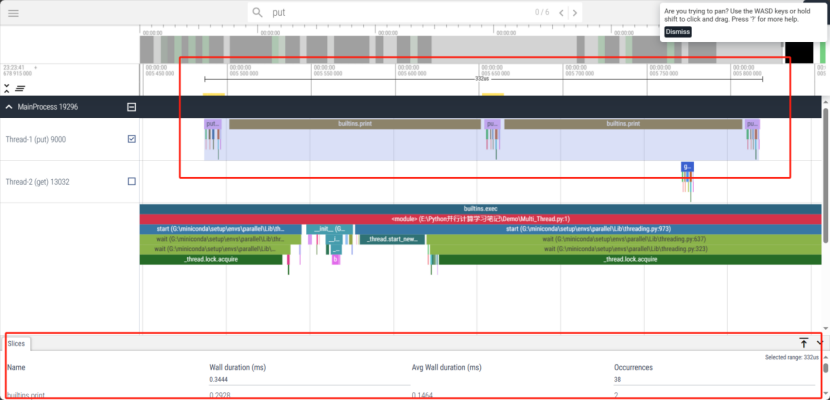
打开分析结果页面,可以看到两个线程的函数调用情况和运行时间:
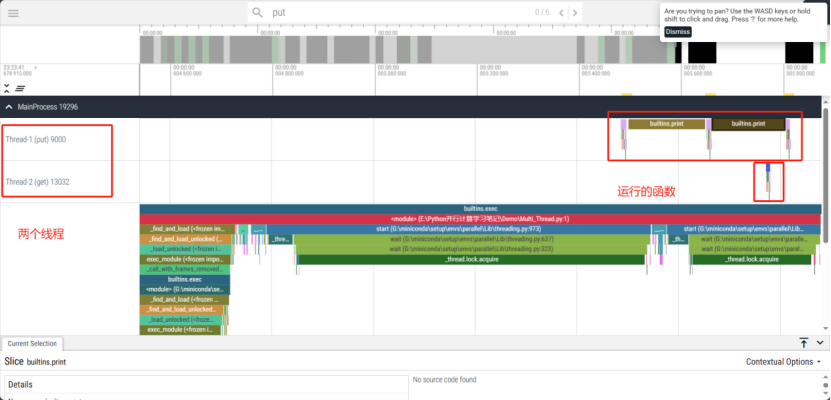
调节光标,我们可以看到更多的细节:
详细使用方法可以进入:++https://viztracer.readthedocs.io/en/latest/index.html++