- Spark-SQL 开发:
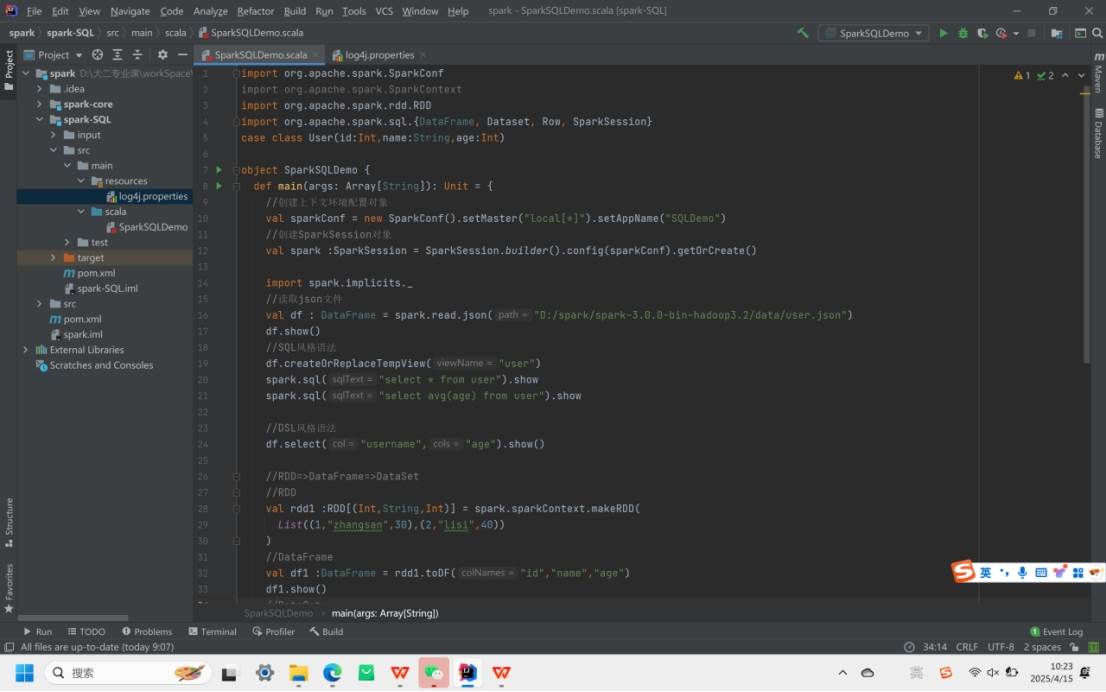
借助 IDEA 开发 Spark-SQL,创建子模块并添加org.apache.spark:spark-sql_2.12:3.0.0依赖。创建SparkConf(设置运行模式和应用名)和SparkSessio(作为 Spark 入口,可读取数据、执行 SQL 查询)配置上下文环境。
RDD、DataFrame、DataSet 转换:三者可相互转换。RDD 可通过toDF转为DataFrame,指定字段名;DataFrame用as转为DataSet,需有对应的样例类。反向转换时,DataSet用toDF转回DataFrame,DataFrame通过rdd获取 RDD,转换过程能发挥不同数据结构优势。
自定义函数
运行代码:
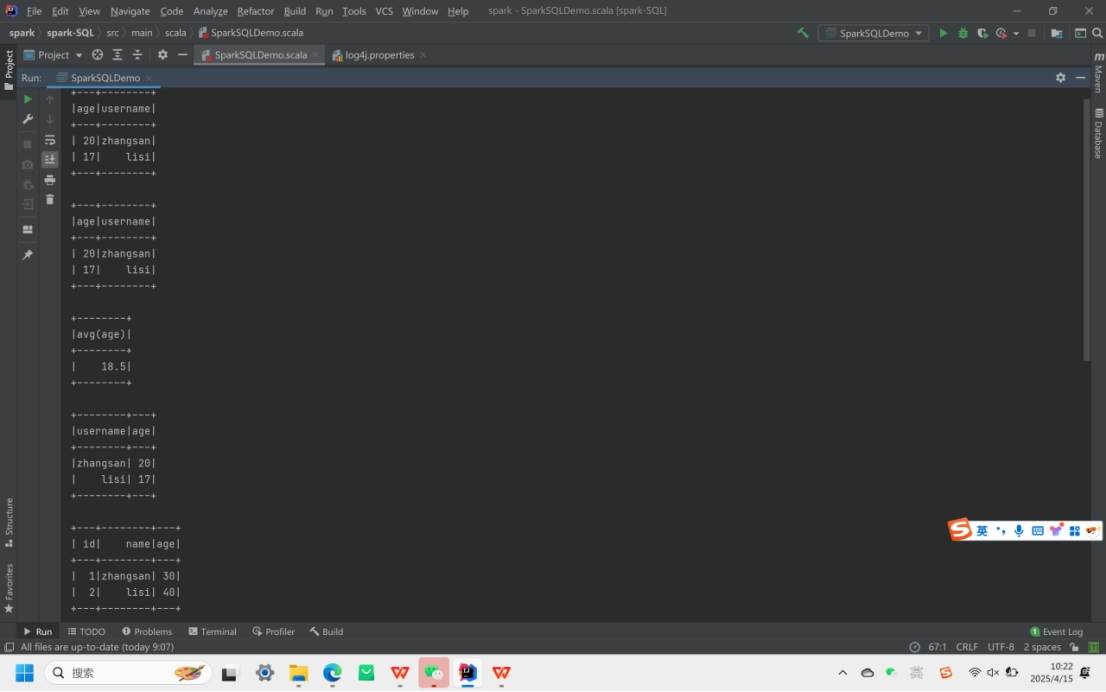
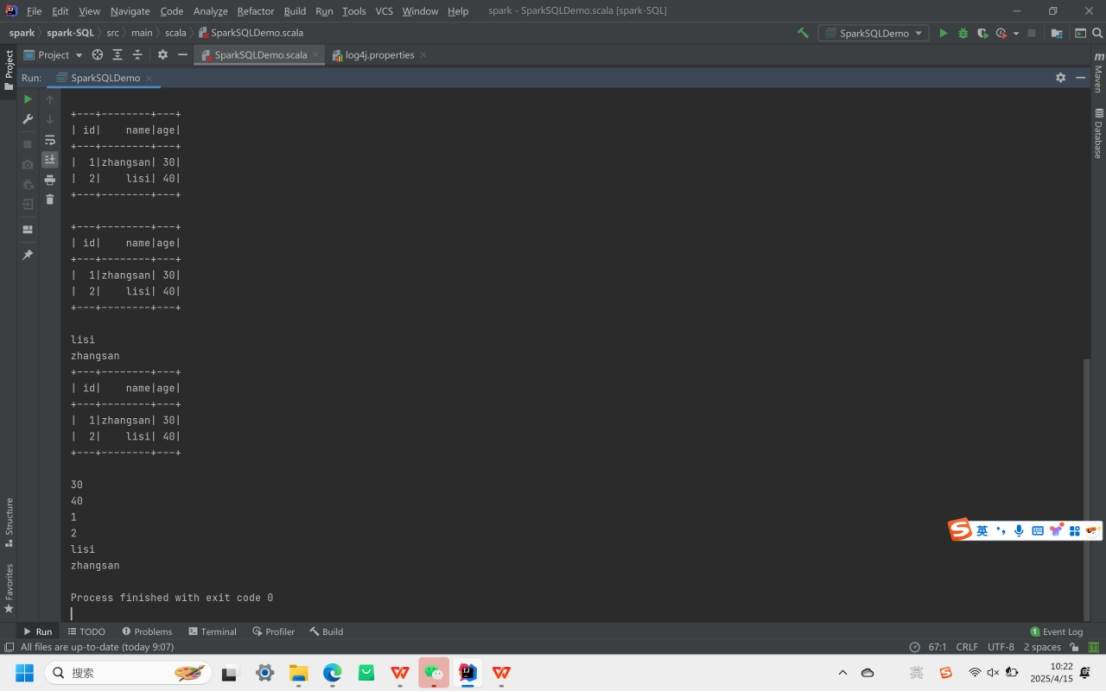
运行结果如下:
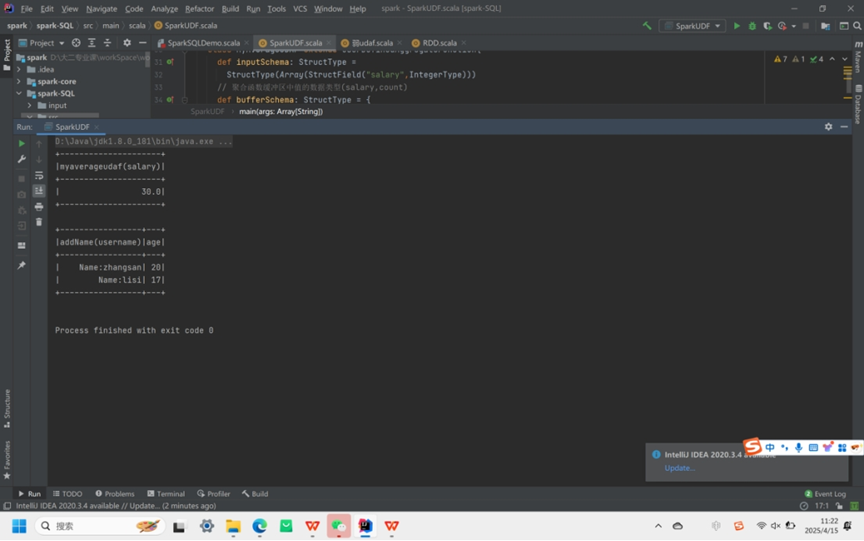
- UDF(用户自定义函数):
可注册自定义函数处理数据。在 Spark 环境中,注册函数如addName后,可在 SQL 查询中调用,对指定字段按自定义逻辑处理。
- UDAF(用户自定义聚合函数):
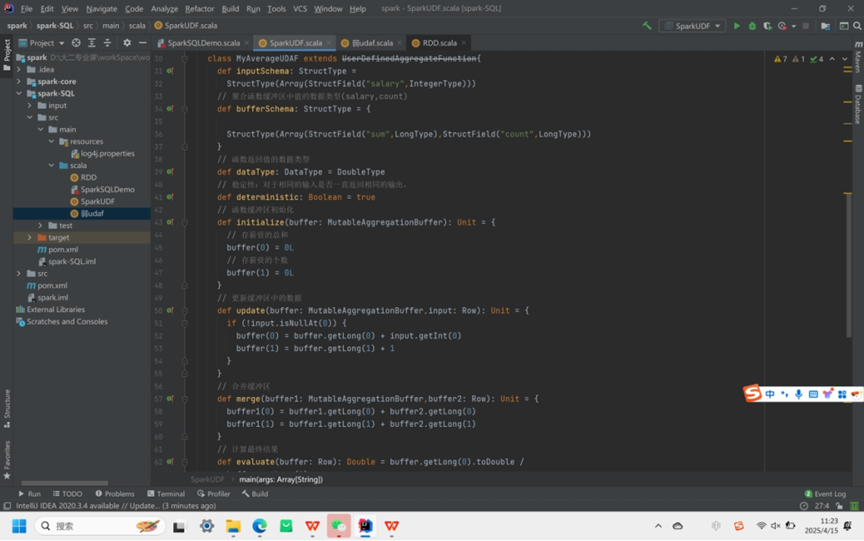
用于数据聚合计算,有多种实现方式(RDD与强弱UDAF)。RDD 方式通过映射和规约操作计算;弱类型 UDAF 继承UserDefinedAggregateFunction,自定义输入、缓冲区和返回值的 Schema 及相关操作方法;强类型 UDAF 继承Aggregator,利用样例类和类型系统,实现更简洁安全 。
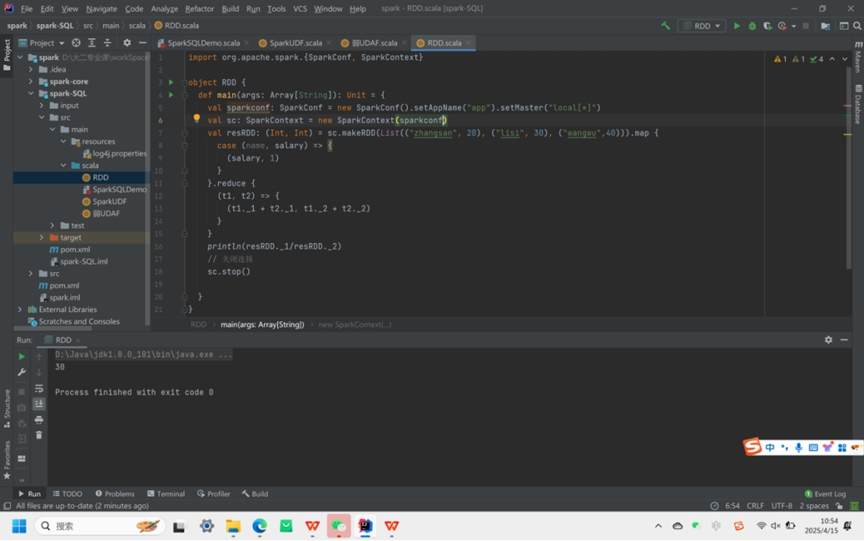
实验需求:计算平均工资
- 实现方式一:RDD
- 实现方式二:弱类型UDAF
代码:
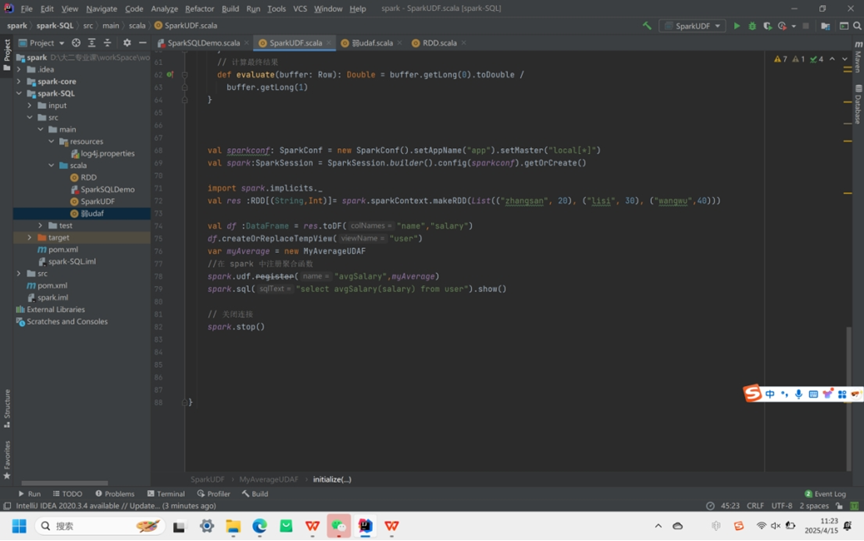
运行结果: