pytorch实现逻辑回归
- 数据准备,参数初始化
- 前向计算
- 计算损失
- 计算梯度
- 更新参数
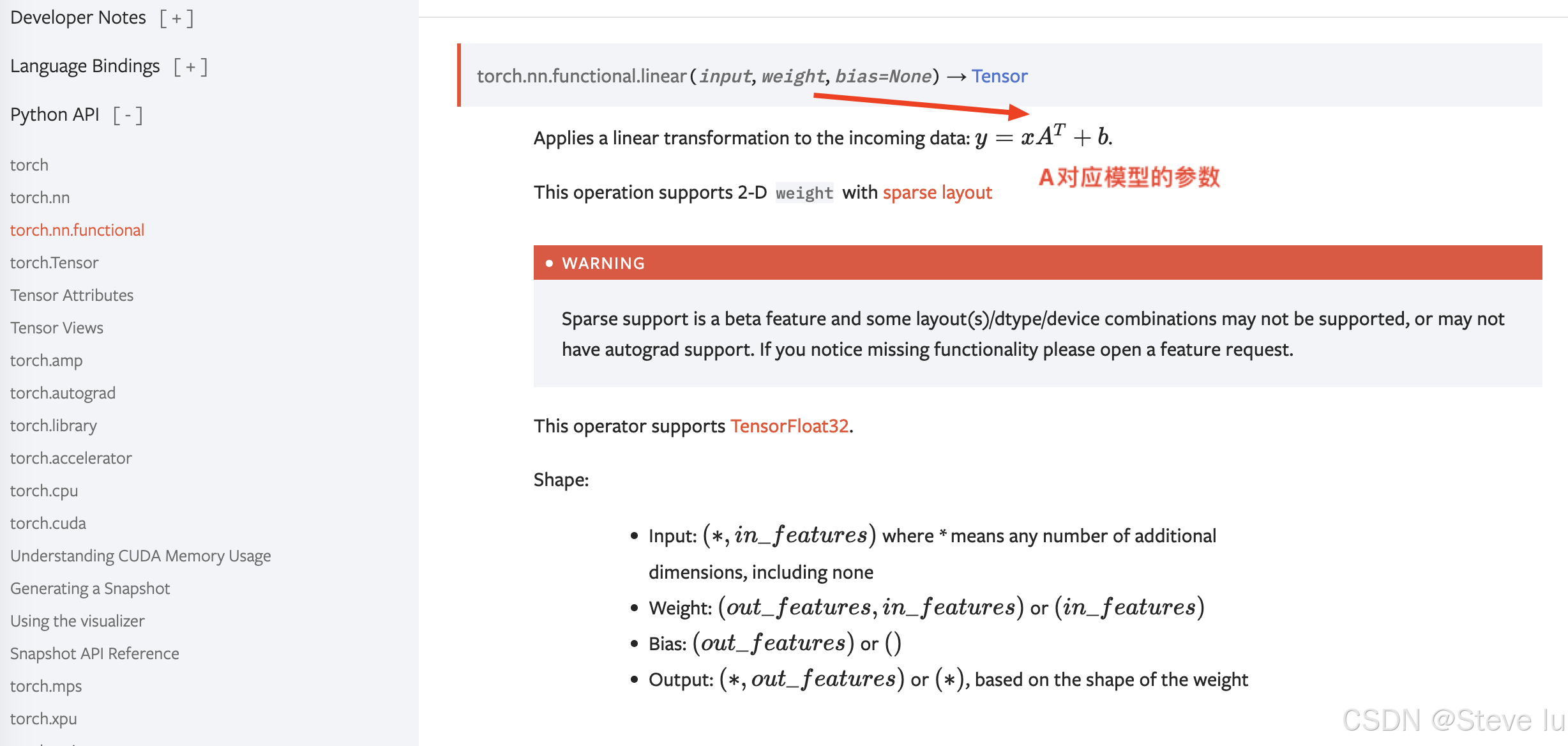
在官网上找到线性函数的公式表达式
python
import torch
from sklearn.datasets import load_iris
# from sklearn.model_selection import train_test_split #train_test_split是sklearn中的一个函数,作用是将数据集划分为训练集和测试集
python
#数据准备
X, y = load_iris(return_X_y=True) #加载数据,X,y分别为特征和标签
X = X[:100] #取前100个样本
y = y[:100] #取前100个样本
#创建张量数据集
tensor_x = torch.tensor(X, dtype=torch.float32)
tensor_y = torch.tensor(y, dtype=torch.float32)
#超参数设置
learning_rate = 0.001
epochs = 500
#模型参数
w = torch.randn(1, 4, requires_grad=True) #requires_grad=True表示w需要求导,1表示输出维度,4表示输入维度
b = torch.randn(1, requires_grad=True) #1表示输出维度【注】
- 张量是一种容器
- 张量也是一种计算的方法,或说操作
- grad属性,梯度属性,保存参数梯度值
python
for i in range(epochs):
#前向计算
z = torch.nn.functional.linear(tensor_x, w, b) #线性函数计算
#z = torch.matmul(tensor_x, w.t()) + b #线性函数计算
z = torch.sigmoid(z) #线性函数转为概率函数0-1之间
#损失函数
loss = torch.nn.functional.binary_cross_entropy(z.reshape(-1), tensor_y,reduction='mean') #二分类交叉熵损失函数
#reduction='mean'表示对每个样本的损失求均值
#计算梯度
loss.backward() #计算梯度、梯度保存在w.grad和b.grad中
#参数更新
#with torch.no_grad()表示不需要梯度跟踪,不需要计算梯度,不需要梯度更新
#with关键字是上下文管理器,用于简化资源管理,确保资源被及时释放(可以理解为作用域)
with torch.no_grad(): #梯度清零,关闭梯度计算跟踪,防止梯度累加
w -= learning_rate * w.grad
b -= learning_rate * b.grad
#梯度清零
w.grad.zero_()
b.grad.zero_()
#训练动态损失
print('train loss:' ,loss.item())train loss: 0.9154033064842224
train loss: 0.9093276262283325
train loss: 0.9033000469207764
train loss: 0.8973206877708435
train loss: 0.891389787197113
train loss: 0.8855075240135193
train loss: 0.8796738982200623
train loss: 0.873889148235321
train loss: 0.8681536912918091
......
train loss: 0.37976446747779846
train loss: 0.37959033250808716
train loss: 0.3794163167476654
train loss: 0.379242479801178
train loss: 0.3790687322616577
train loss: 0.37889519333839417
train loss: 0.378721684217453
train loss: 0.37854844331741333
train loss: 0.3783752918243408
train loss: 0.37820228934288025
python
w.grad #查看w的梯度tensor([[0., 0., 0., 0.]])二元交叉熵计算损失维度要相同,不然报错,去掉维度
z.reshape(-1).shape #将z展平
z.squeeze().shape #将z压缩(去掉维度为1的维度)
torch.Size(100)
完整代码
python
import torch
from sklearn.datasets import load_iris
#数据准备
X, y = load_iris(return_X_y=True)
X = X[:100]
y = y[:100]
#创建张量数据集
tensor_x = torch.tensor(X, dtype=torch.float32)
tensor_y = torch.tensor(y, dtype=torch.float32)
#超参数设置
learning_rate = 0.001
epochs = 500
#模型参数
w = torch.randn(1, 4, requires_grad=True)
b = torch.randn(1, requires_grad=True)
for i in range(epochs):
#前向计算
z = torch.nn.functional.linear(tensor_x, w, b)
z = torch.sigmoid(z)
#损失函数
loss = torch.nn.functional.binary_cross_entropy(z.reshape(-1), tensor_y,reduction='mean')
#计算梯度
loss.backward()
#参数更新
with torch.no_grad():
w -= learning_rate * w.grad
b -= learning_rate * b.grad
#梯度清零
w.grad.zero_()
b.grad.zero_()
#训练动态损失
print('train loss:' ,loss.item())