一、数据加载与保存
通用方式:使用spark.read.load和df.write.save,通过format指定数据格式(如csv、jdbc、json等),option设置特定参数(jdbc格式下的url、user等),load和save指定路径。保存时可通过mode设置SaveMode,如ErrorIfExists(默认,文件存在则抛异常)、Append(追加)、Overwrite(覆盖)、Ignore(忽略)。
Parquet:Spark SQL 默认数据源,是嵌套数据的列式存储格式。加载和保存无需format指定,可通过修改spark.sql.sources.default变更默认格式。
JSON:Spark SQL 能自动推测结构并加载为DatasetRow,读取的 JSON 文件每行应为 JSON 串,可通过SparkSession.read.json加载。
CSV:可配置列表信息,如设置分隔符sep、推断模式inferSchema、指定表头header等。
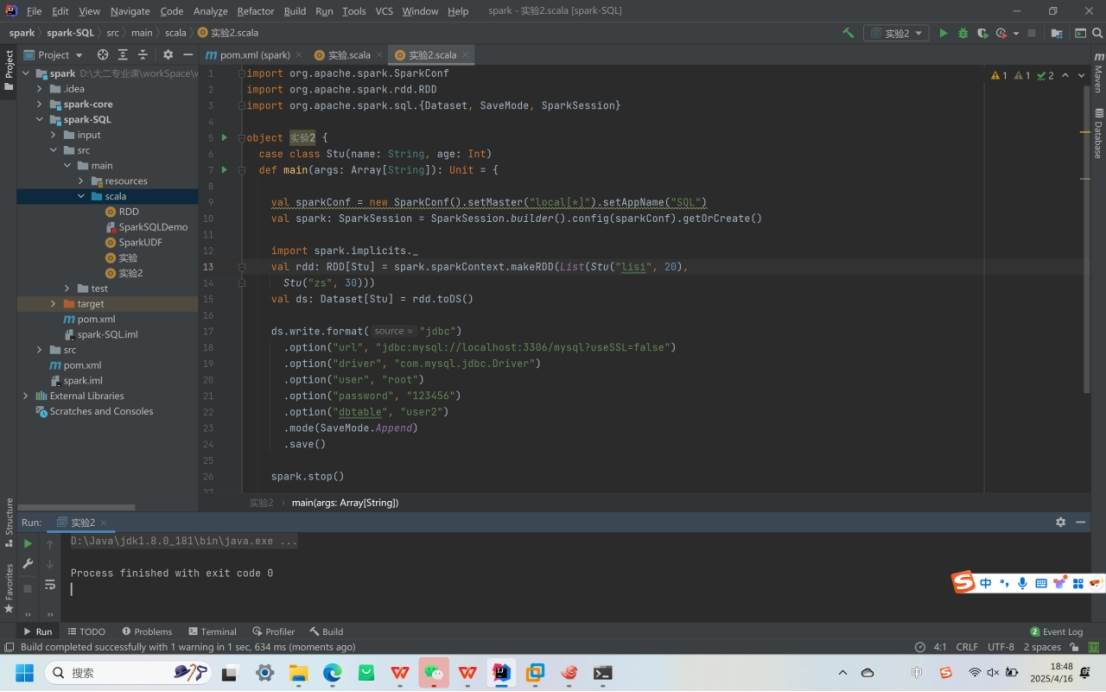
MySQL:借助 JDBC 读取和写入数据。
1.读取数据
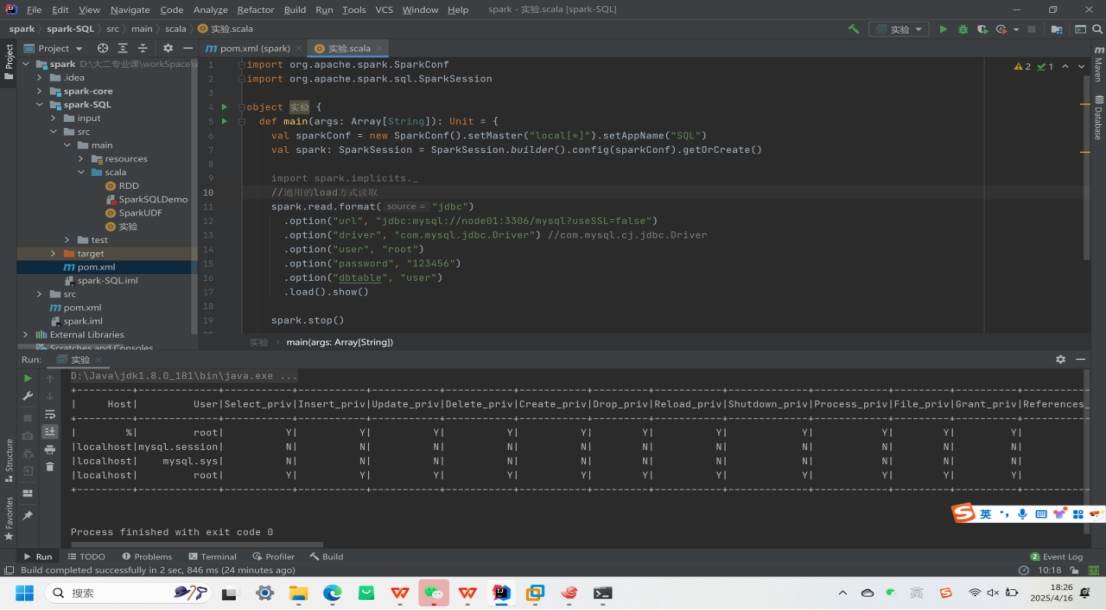
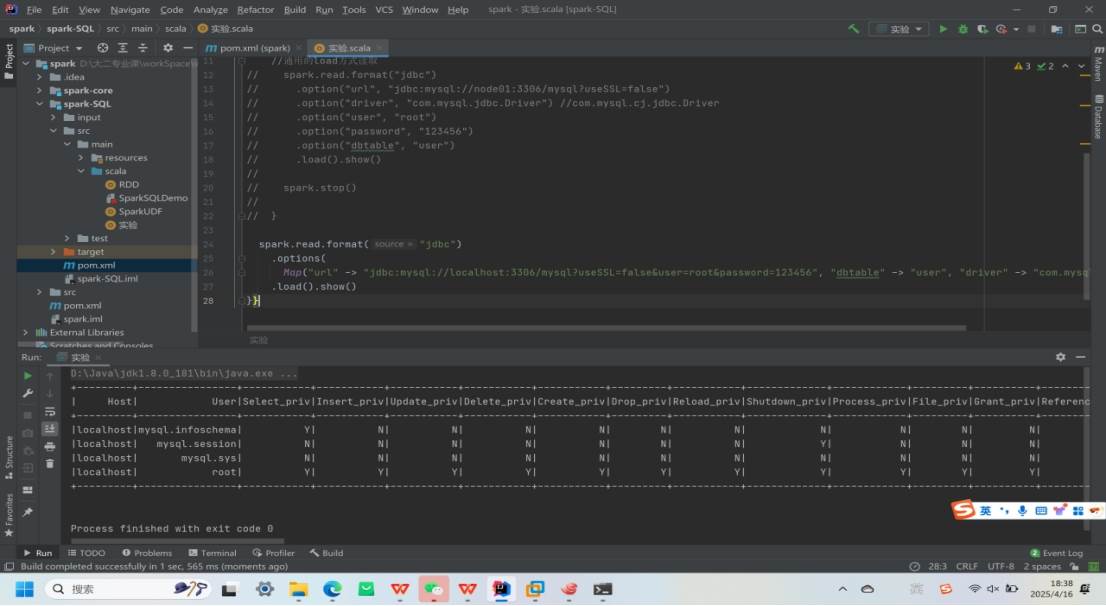
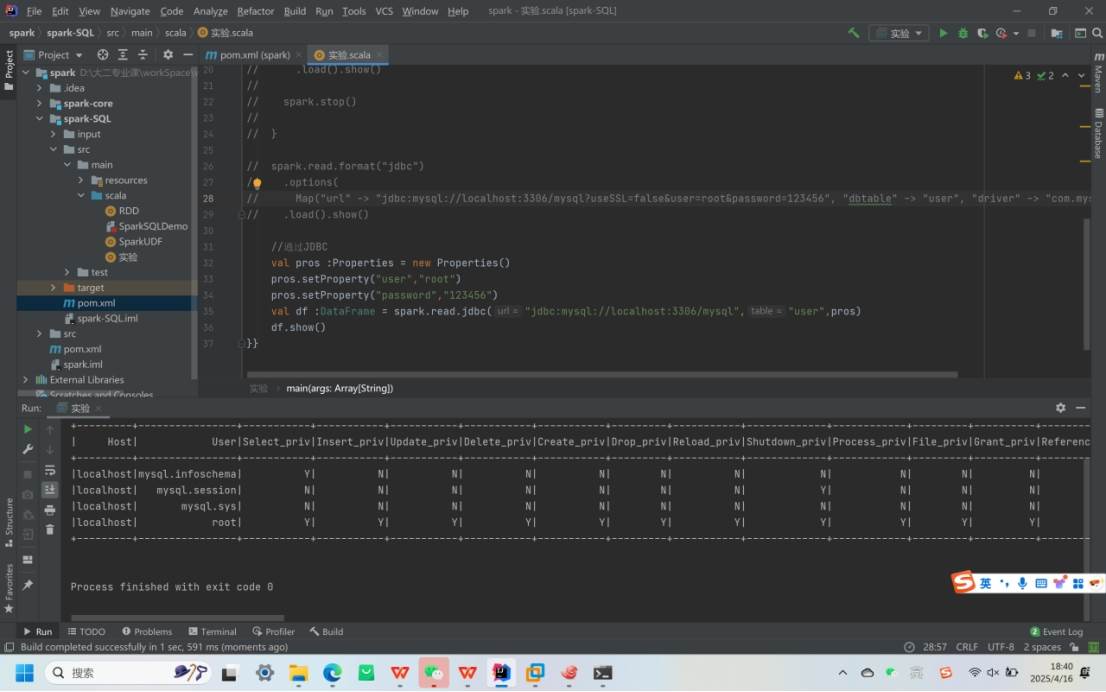
写入数据
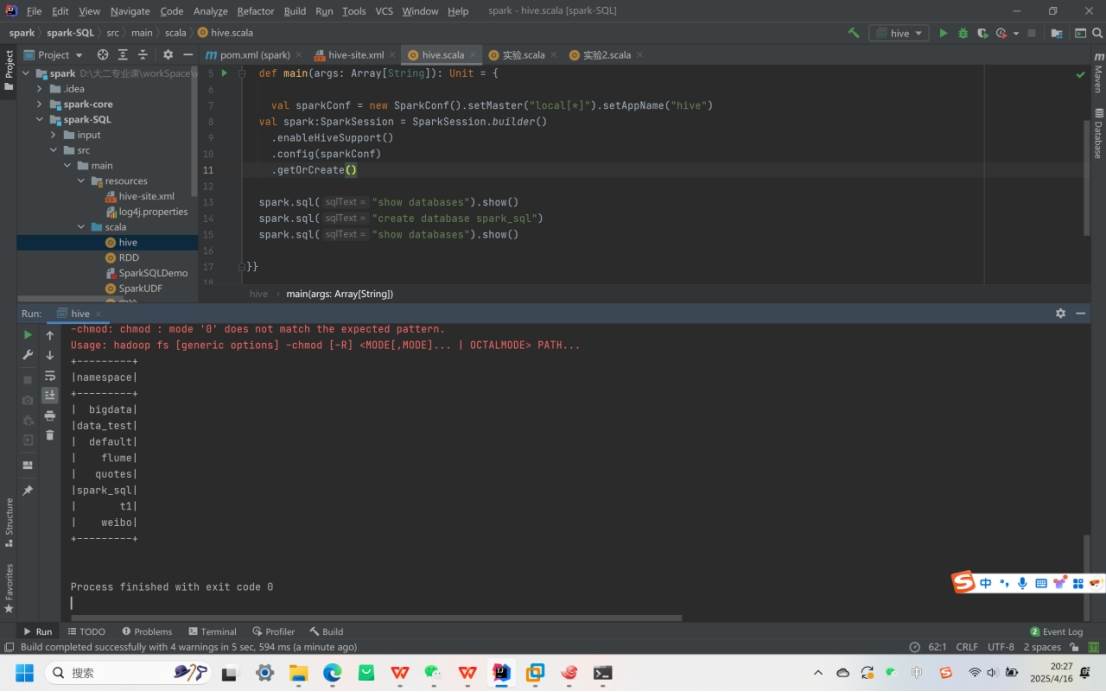
二、Spark-SQL连接Hive
内嵌 Hive:可直接使用,但实际生产中很少用。
外部 Hive:
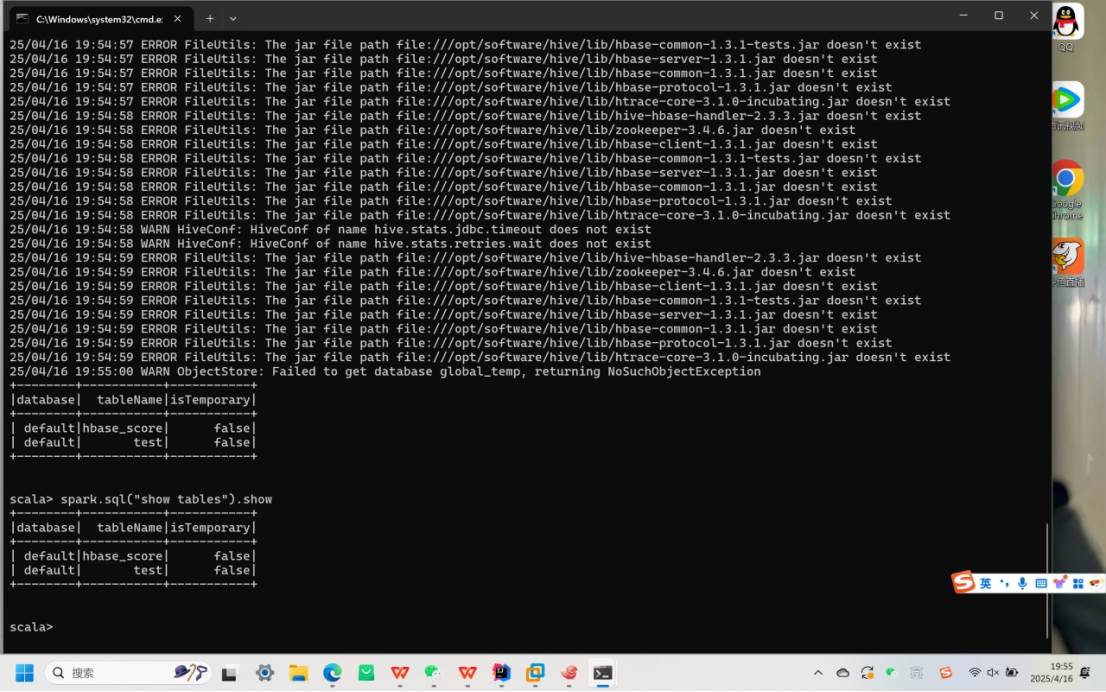
代码操作Hive