Spark-SQL 核心编程
数据加载与保存
加载数据
spark.read.load 是加载数据的通用方法。如果读取不同格式的数据,可以对不同的数据格式进行设定
保存数据
df.write.save 是保存数据的通用方法。如果保存不同格式的数据,可以对不同的数据格式进行设定
Parquet
Spark SQL 的默认数据源为 Parquet 格式。Parquet 是一种能够有效存储嵌套数据的列式
JSON
加载json文件
val path = "/opt/module/spark-local/people.json"
val peopleDF = spark.read.json(path)
创建临时表
peopleDF.createOrReplaceTempView("people")
数据查询
val resDF = spark.sql("SELECT name FROM people WHERE age BETWEEN 13 AND 19")
CSV
Spark SQL 可以配置 CSV 文件的列表信息,读取 CSV 文件,CSV 文件的第一行设置为
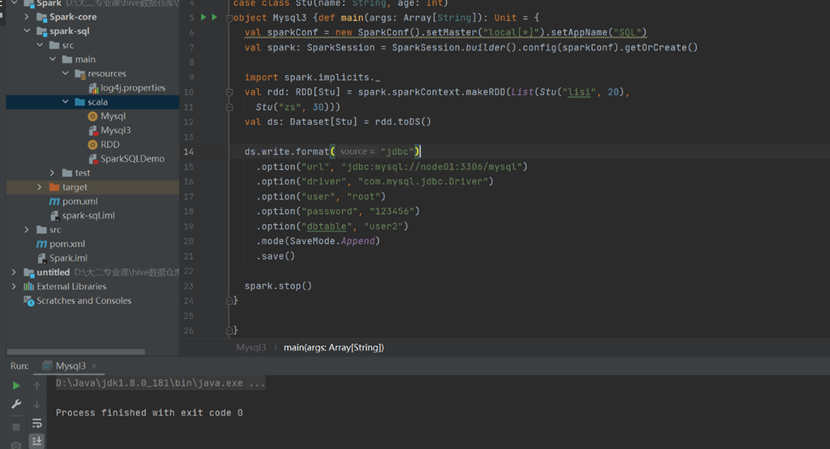
MySQL
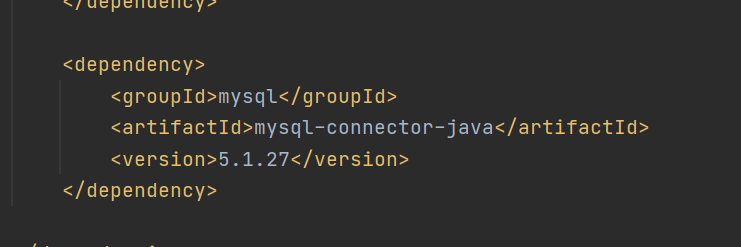
导入依赖
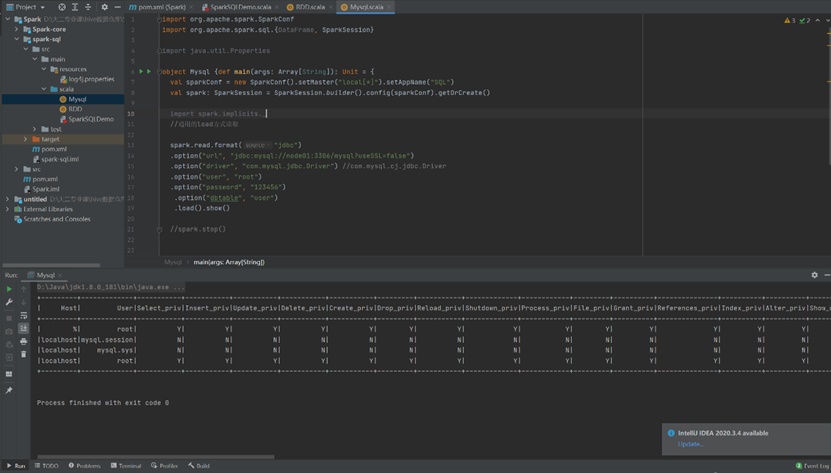
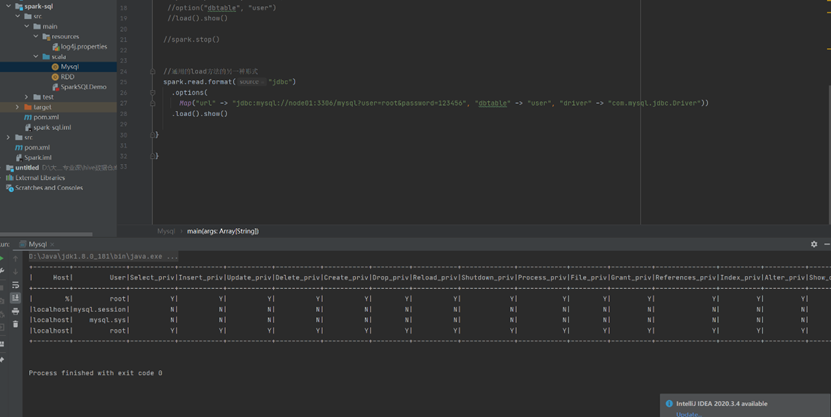
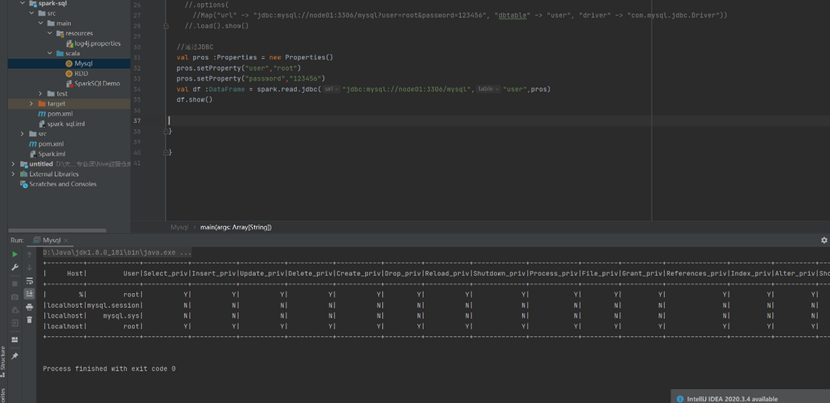
读取数据
写入数据
Spark-SQL连接Hive
内嵌的 HIVE
外部的 HIVE
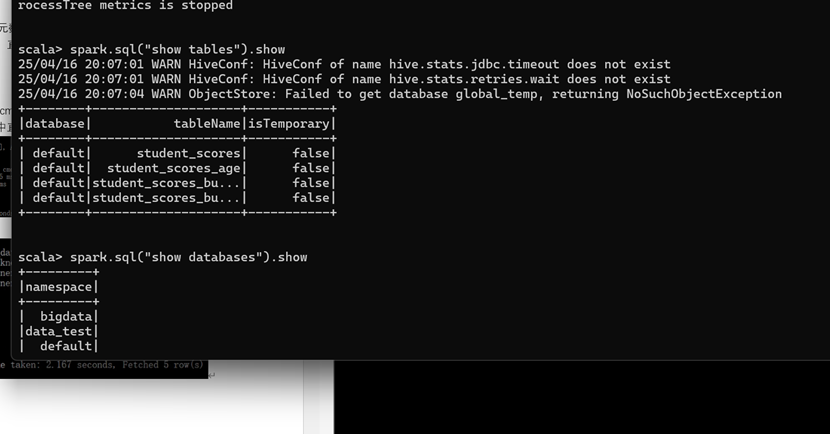
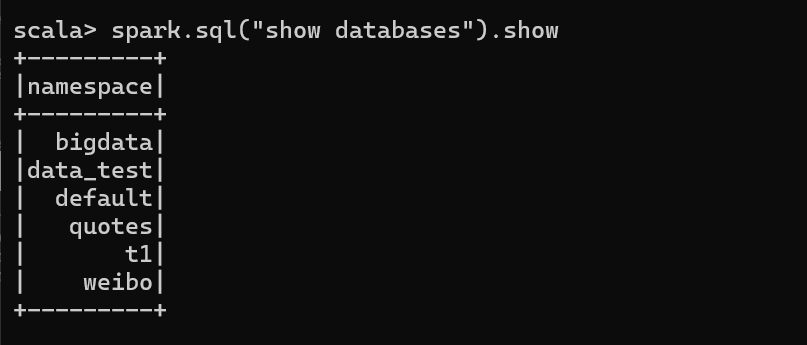
运行 Spark beeline(了解)
Spark Thrift Server 是 Spark 社区基于 HiveServer2 实现的一个 Thrift 服务。旨在无缝兼容HiveServer2。
运行Spark-SQL CLI
Spark SQL CLI 可以很方便的在本地运行 Hive 元数据服务以及从命令行执行查询任务。在 Spark 目录下执行如下命令启动 Spark SQL CLI,直接执行 SQL 语句,类似于 Hive 窗口。
