参考
https://www.palantir.com/docs/zh/foundry/transforms-sql/spark-reference/
日常用法
Spark 中用于读取文本文件并创建 RDD 的核心操作:
py
dump_rdd = sc.textFile(dump_path) textFile(dump_path) 是 SparkContext 提供的方法,用于从指定路径 dump_path 读取文本文件(或目录),并返回一个 RDD String(每个元素是文件中的一行文本)
最终 dump_rdd 是一个存储了文件内容的 RDD,后续可通过 map、filter 等算子进行分布式处理
dump_path 的支持类型
- 本地文件路径:如 file:///home/user/data.txt(需集群所有节点均可访问)
- 分布式文件系统路径:如 HDFS 路径(hdfs://namenode:9000/path/file)、S3 路径(s3a://bucket/path)等,Spark 会自动并行读取
- 目录路径:若 dump_path 指向目录,会读取目录下所有文件(可通过通配符
*过滤,如hdfs:///path/*.log)
RDD 的特性
textFile 生成的 RDD 是惰性加载的:仅当执行行动算子(如 count、collect)时才会实际读取文件
自动分区:Spark 会根据文件大小和集群资源自动划分分区(每个分区由一个 executor 处理),也可通过第二个参数指定分区数,如 sc.textFile(dump_path, 10)(指定 10 个分区)
每行作为元素:文件中的每一行文本会被作为 RDD 的一个元素(换行符 \n 或 \r\n 作为行分隔符)
示例
假设 dump_path 是 HDFS 上的一个日志目录 hdfs://haruna/path/*.zstd,执行该命令后:
- dump_rdd 会包含该目录下所有
.zstd文件的内容,每行日志作为一个字符串元素 - 后续可通过 dump_rdd.map(parse_log) 对每行日志进行解析(如你代码中的 dump_transform 函数),实现分布式数据处理
py
HDFS_PATH_PREFIX = "hdfs://haruna/home/demo/data/platform_collect_raw"
business_date = "20251030"
# 匹配所有的 zstd 文件,如果数据流是按照小时分区,则这里可以打包当日所有小时分区的zstd
dump_path = f"{HDFS_PATH_PREFIX}/{business_date}/*.zstd"
dump_rdd = sc.textFile(dump_path)
# 打印rdd中的前20条数据,用于调试
# print(dump_rdd.take(20))
# 也可以用这种方式让 sc 并行执行test_text_list中的数据
# test_text_list = ['json串1','json串2']
# dump_rdd = sc.parallelize(test_text_list)
# dump_transform 是个转换函数,用于将一行str元素转为特定的格式
# filter 是为了仅保留转换后的数据
dump_df = spark.createDataFrame(
dump_rdd.map(dump_transform).filter(lambda x: x is not None), schema=DUMP_LOG_SCHEMA
)
# 计算行数
row_count = dump_df.count()
print(f"Number of rows in dump_df: {row_count}")sc, SparkContext
sc 是 SparkContext 类的缩写
是 Spark 程序的核心入口对象,负责与 Spark 集群通信、申请资源、创建分布式数据结构(如 RDD),以及协调任务执行
核心作用:
- 连接集群:与 Spark 集群的资源管理器(如 YARN、K8s 或本地模式)通信,申请计算资源(CPU、内存)
- 创建 RDD:通过 sc.textFile()、sc.parallelize() 等方法创建 RDD(分布式数据集),是处理数据的起点
- 配置任务:设置 Spark 任务的参数(如并行度、序列化方式等),例如 sc.setLogLevel("WARN") 调整日志级别
示例:
python
from pyspark import SparkContext
# 初始化 SparkContext(通常在 Spark 应用启动时自动创建,无需手动实例化)
sc = SparkContext("local", "MyApp") # "local" 表示本地模式,"MyApp" 是应用名称sc 是 Spark 程序的 "入口钥匙",RDD 是分布式计算的 "数据容器",两者共同构成了 Spark 分布式处理的基础
RDD:弹性分布式数据集(Resilient Distributed Dataset)
RDD 是 Spark 中最基础的分布式数据结构,代表一个不可变、可并行计算的数据集,数据会被自动分发到集群的多个节点上存储和处理
核心特性:
- 分布式:数据被拆分为多个 "分区(Partition)",分散存储在集群的不同节点上,可并行处理
- 弹性(容错性):如果某个节点的分区数据丢失,Spark 可通过 "血统(Lineage)" 信息重新计算恢复,无需冗余存储
- 不可变:一旦创建,RDD 的内容不能修改,只能通过转换算子(如 map、filter)生成新的 RDD
- 惰性计算:RDD 的转换操作(如 map)不会立即执行,直到遇到行动算子(如 collect、count)时才会触发实际计算,优化效率
示例:
python
# 从本地列表创建 RDD(并行化本地数据)
data = [1, 2, 3, 4, 5]
rdd = sc.parallelize(data) # 将本地列表转换为 RDD
# 从文件创建 RDD(分布式读取文件)
file_rdd = sc.textFile("hdfs://path/to/file.txt") # 每行文本作为 RDD 的一个元素RDD 是 "数据载体":存储分布式数据,通过 sc 提供的方法创建,后续所有数据处理(清洗、转换、分析)都基于 RDD 进行
和sql取join
py
demo_data_df = sql(f"""SELECT *,
row_number() OVER (
PARTITION BY
task_id, task_version
ORDER BY
demo_id
) AS demo_index
FROM {DEMO_INFO_TABLE}
WHERE date={demo_tbl_date}
AND is_deleted=0""")
join_df = (
dump_df.alias("ans")
.join(
demo_data_df.alias("demo"),
(col("ans.demo_id") == col("demo.task_id"))
& (col("ans.demo_version") == col("demo.task_version")),
"left",
)
.select(
[col("ans." + c) for c in dump_df.columns]
+ [col("demo." + c) for c in demo_data_df.columns]
)
)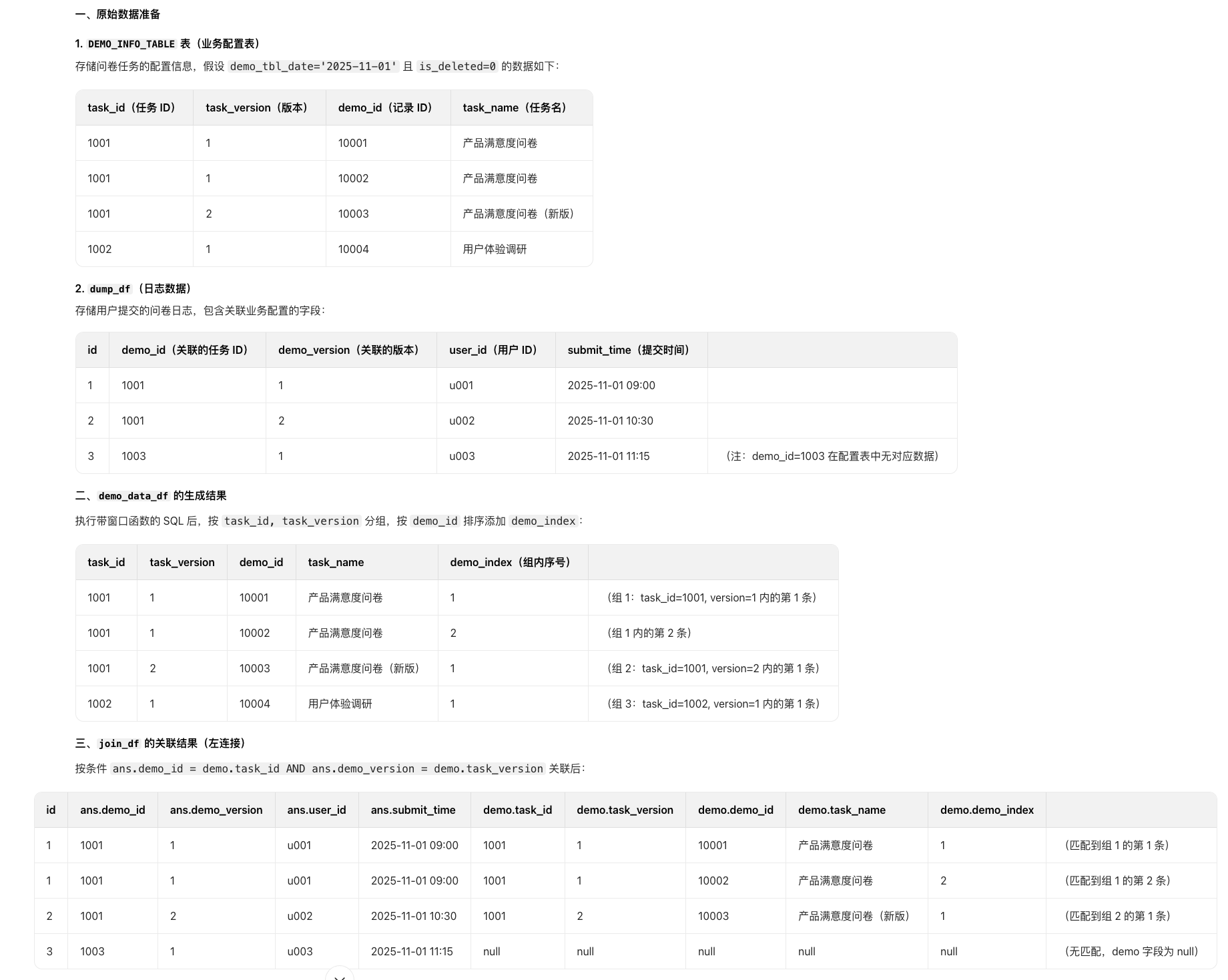
左连接(left join)时,如果左边的一行与右边的两行匹配,最终会产出两行结果
这是因为连接的本质是 "将匹配的记录两两组合",左边的一条记录会与右边所有匹配的记录分别组合成新行
- 左连接中,左边的每行记录会与右边所有匹配的行形成新行
- 若左边一行匹配右边 N 行,则最终会生成 N 行结果
- 若左边一行无匹配(右边 0 行),则保留 1 行(右边字段为 null)
这也是连接操作中 "行数可能增加" 的原因
继续
对已有 DataFrame(join_df)进行数据转换、过滤后,重新创建一个新的 DataFrame
目的是通过分布式计算(RDD 算子)处理数据,最终生成符合目标表结构(HIVE_TABLE_SCHEMA)的结果
py
join_df = spark.createDataFrame(
join_df.rdd.flatMap(join_data_transform).filter(lambda x: x is not None), schema=HIVE_TABLE_SCHEMA
)join_df.rdd:DataFrame 转 RDD
join_df 是一个已有的 DataFrame(结构化数据集)
.rdd 将 DataFrame 转换为 RDD(弹性分布式数据集),此时 RDD 的每个元素是 Row 对象(对应 DataFrame 中的一行数据)
目的:
- DataFrame 适合结构化查询(如 select、join)
- 复杂数据转换(如一行拆多行、嵌套结构处理)更适合用 RDD 的算子(如 flatMap)实现
flatMap(join_data_transform):转换并 "摊平" 数据
flatMap 是 RDD 的转换算子,作用是:
对 RDD 中的每个元素应用函数 join_data_transform,然后将函数返回的 "可迭代对象"(如列表、集合)"摊平" 为单个元素
举例:
- 若 join_data_transform 对一行数据返回 a, b, c,则 flatMap 会将这一行拆分为 a、b、c 三个独立元素
- 而普通 map 会保留列表 a,b,c 作为一个元素
join_data_transform 是自定义的转换函数,功能通常包括:
- 解析原始数据(如处理嵌套字段、格式转换)
- 一行拆多行(如将一个包含多个子项的列表拆分为多条记录)
- 生成符合目标 schema 的中间数据(如 Row 对象或字典)
filter(lambda x: x is not None):过滤无效数据
对 flatMap 处理后的 RDD 进行过滤,只保留非 None 的元素
原因:
join_data_transform 可能在处理异常数据(如格式错误、缺失关键字段)时返回 None
过滤后可确保后续生成的 DataFrame 只包含有效数据
spark.createDataFrame(..., schema=HIVE_TABLE_SCHEMA):重建 DataFrame
将处理后的 RDD 重新转换为 DataFrame,并指定目标表结构 HIVE_TABLE_SCHEMA
通常是一个 StructType 对象,定义了字段名、类型、是否可为空等
作用:
确保输出的 join_df 字段与目标表(如 Hive 表)完全匹配,避免因字段类型不兼容或缺失导致写入失败
典型业务场景
假设 join_df 存储的是 "用户提交的问卷答案",其中 answers 字段是一个嵌套列表(如 {"question_id": 1, "answer": "A"}, {"question_id": 2, "answer": "B"}),而目标是将每个问题的答案拆分为单独一行,存入 Hive 表
sc.textFile的RDD和 join_df.rdd区别
sc.textFile() 直接返回 RDD,而 join_df.rdd 需要显式转换,本质是因为 sc.textFile() 是 "创建 RDD 的入口方法"
而 join_df 是 DataFrame,需要显式转换才能使用 RDD 的算子:
sc.textFile()的本质:直接创建 RDD
sc.textFile(dump_path)是 SparkContext 提供的 RDD 创建方法,目的就是从文件读取数据并返回 RDD(RDDString,每行文本作为元素)
它是 Spark 中 "从外部数据源初始化分布式数据集" 的底层接口,返回是最基础的 RDD 类型,因此可以直接使用 map、filter 等 RDD 算子- join_df 是 DataFrame,需显式转换为 RDD
join_df 是一个 DataFrame(Spark 的结构化数据抽象),它本身不是 RDD,而是基于 RDD 构建的更高层 API
DataFrame 提供了更简洁的结构化操作(如 select、join、groupBy 等 SQL 风格的 API),但这些操作更适合处理规则的结构化数据
当需要使用 RDD 特有的算子(如 flatMap、mapPartitions 等更灵活的转换)时,必须先通过 .rdd 显式将 DataFrame 转换为 RDD
(此时 RDD 的元素是 Row 对象,对应 DataFrame 中的一行数据)

sc.textFile() 直接返回 RDD,是因为它是 "创建 RDD 的原始 API"
join_df 是 DataFrame(更高层的结构化 API),设计目标是简化结构化数据处理,需要显式通过 .rdd 转换才能使用底层 RDD 的灵活算子
这种分层设计让 Spark 既能高效处理结构化数据(DataFrame),又能支持复杂的分布式计算(RDD)
dump
py
join_df.show(vertical=True)写入HIVE
py
join_df.createOrReplaceTempView("inc_table")
spark.sql(f"""
INSERT OVERWRITE TABLE { save_table } PARTITION(p_date = { business_date })
SELECT `demo_id`,
`response_id`,
`demo_uuid`,
FROM inc_table
""")join_df.createOrReplaceTempView("inc_table") 是 Spark 中用于将 DataFrame 注册为临时视图的核心操作
方便后续通过 Spark SQL 语句直接查询该 DataFrame
join_df 是一个 DataFrame(结构化数据集,包含行列结构)
createOrReplaceTempView("inc_table") 将这个 DataFrame 注册为名为 inc_table 的 "临时视图"
使得后续可以通过 SQL 语句(如 SELECT * FROM inc_table)查询该 DataFrame 中的数据,就像操作数据库表一样
"临时视图" 的特性
- 生命周期:临时视图仅在当前 SparkSession 中有效,当 SparkSession 关闭后,视图会自动消失(不会持久化到磁盘)
- 作用范围:默认仅当前 SparkSession 可见,其他 SparkSession 无法访问
(若需要跨会话共享,可使用 createOrReplaceGlobalTempView,但需通过global_temp.前缀访问)
createOrReplace 的含义
若名为 inc_table 的临时视图已存在,则替换原视图(更新为当前 join_df 的数据和结构)
若不存在,则创建一个新的临时视图 inc_table
典型使用场景
注册临时视图后,可直接用 SQL 语句操作 join_df 中的数据,无需再使用 DataFrame 算子(如 select、filter)
尤其适合熟悉 SQL 的开发者
py
# 将 join_df 注册为临时视图 inc_table
join_df.createOrReplaceTempView("inc_table")
# 通过 Spark SQL 查询临时视图
result_df = spark.sql("""
SELECT user_id, COUNT(*) as submit_count
FROM inc_table
WHERE demo_index = 1
GROUP BY user_id
""")
# 查看结果
result_df.show()上述代码中,spark.sql 直接查询 inc_table,等价于对 join_df 执行相同的分组统计操作,但用 SQL 表达更直观
临时视图是 DataFrame 与 SQL 之间的 "桥梁":
- 对于简单操作,DataFrame 算子(如
join_df.filter(...))更简洁 - 对于复杂逻辑(如多表关联、嵌套子查询),SQL 往往更易读,此时通过临时视图用 SQL 处理更高效
join_df.createOrReplaceTempView("inc_table") 的作用是将 DataFrame 转换为 SQL 可识别的临时表
允许开发者用熟悉的 SQL 语法操作数据,提升复杂查询的可读性和开发效率
临时视图是 Spark 中 "DataFrame API" 与 "SQL API" 协同工作的重要机制