目录
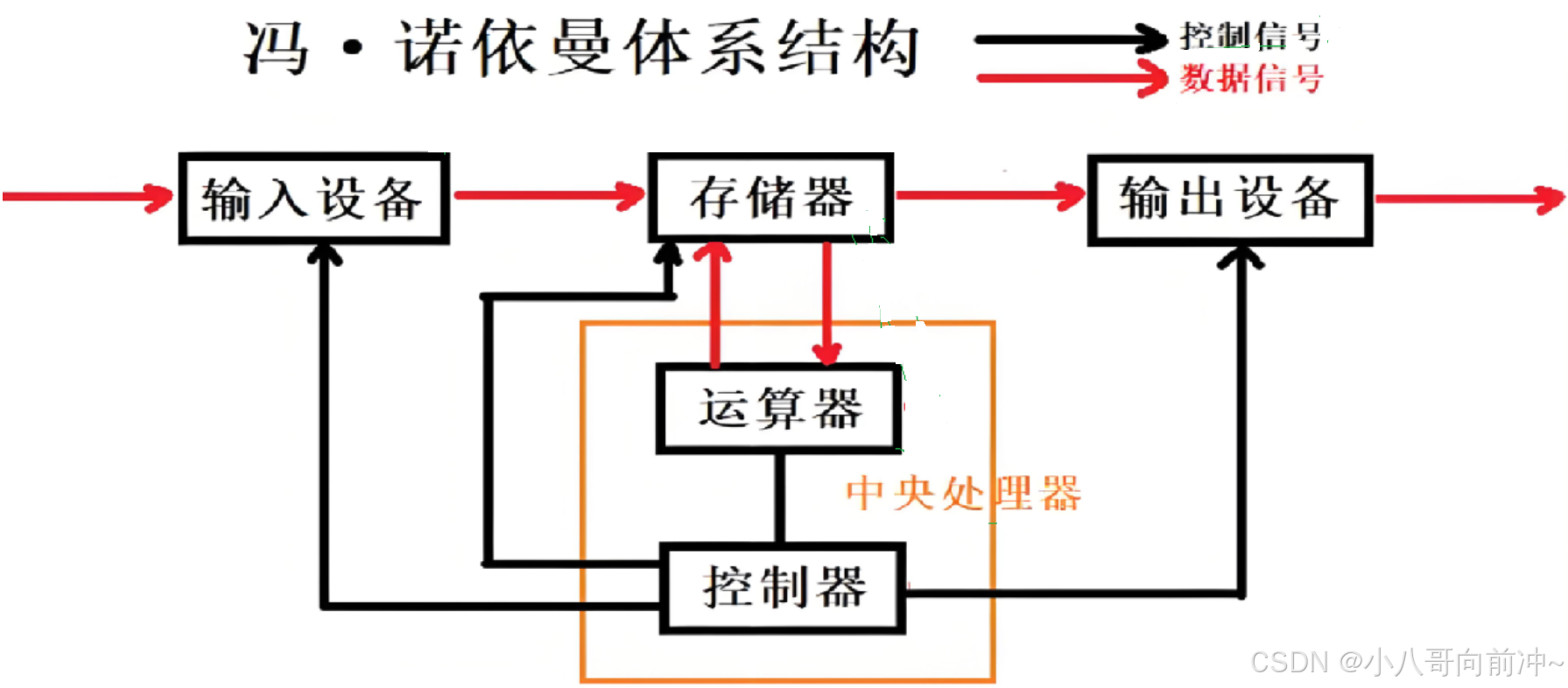
了解进程之前,我们先说说冯诺依曼体系结构,这是计算机硬件方面的知识。
冯诺依曼体系
我们常见的计算机,如笔记本,各种服务器,都是由各种硬件组成的,而这些硬件都遵循这个体系结构。
存储器理解
存储器主要分为内存和外存。
内存:直接参与CPU运算,存放当前执行的程序和数据。
外存(如硬盘,U盘,固态硬盘等):作为内存的扩展,用于长期保存大量数据,需通过内存与CPU交互。
输入设备:包括键盘,⿏标,摄像头,网卡,磁盘等。
输出设备:显示器,打印机,磁盘,网卡等。
磁盘和网卡既不是单纯的输入设备,也不是单纯的输出设备 ,而是具有双重角色的存储介质。
中央处理器(CPU):含有运算器和控制器等。
注意:
- 我们这里的存储器(图中)主要指的是内存。
- 不考虑缓存情况,这⾥的CPU能且只能对内存进⾏读写,不能访问外设(输⼊或输出设备)。
- 外设(输⼊或输出设备)要输⼊或者输出数据,也只能写⼊内存或者从内存中读取。
- ⼀句话,所有设备都只能直接和内存打交道。
数据的流动其实就是拷贝,是从一个设备拷贝到另一个设备中,所以这个体系效率是由设备数据的拷贝决定的!
深入理解:
对于这个体系不能只停留在表面,我们必须要深入到数据流的理解。
举个例子:
我们在登陆qq和朋友发消息,这个消息数据是怎么流动的?而朋友又是怎么收到消息并且能看到的呢?
软件在运行之前,是在文件里,而文件在磁盘中,软件要运行,必须先要加载到内存中,也就是说我们登陆了qq,qq这个软件(程序)就已经加载到内存中了(从输入设备(这里是磁盘)数据流动到内存中),然后我们发送一个消息,这个数据是从键盘(输入设备)流动到内存中,数据再流动到网卡(输出设备),经过网络一系列操作,数据进入朋友计算机的输入设备(网卡),数据再流动到内存(朋友登陆qq,也是将qq加载到了内存中),最后流入显示器(输出设备)中,然后朋友就看见我们的消息了!
其实本质就是两台冯诺依曼体系在"聊天"。
只要我们稳稳理解这个体系,其实很多问题都能知道一个大概,只不过当中过程,细节等需要我们去不断学习和深究!
操作系统(OperatorSystem)
任何计算机系统都包含⼀个基本的程序集合,称为操作系统(OS)。笼统的理解,操作系统包括:
- 内核(进程管理,内存管理,⽂件管理,驱动管理)
- 其他程序(例如函数库,shell程序等等)
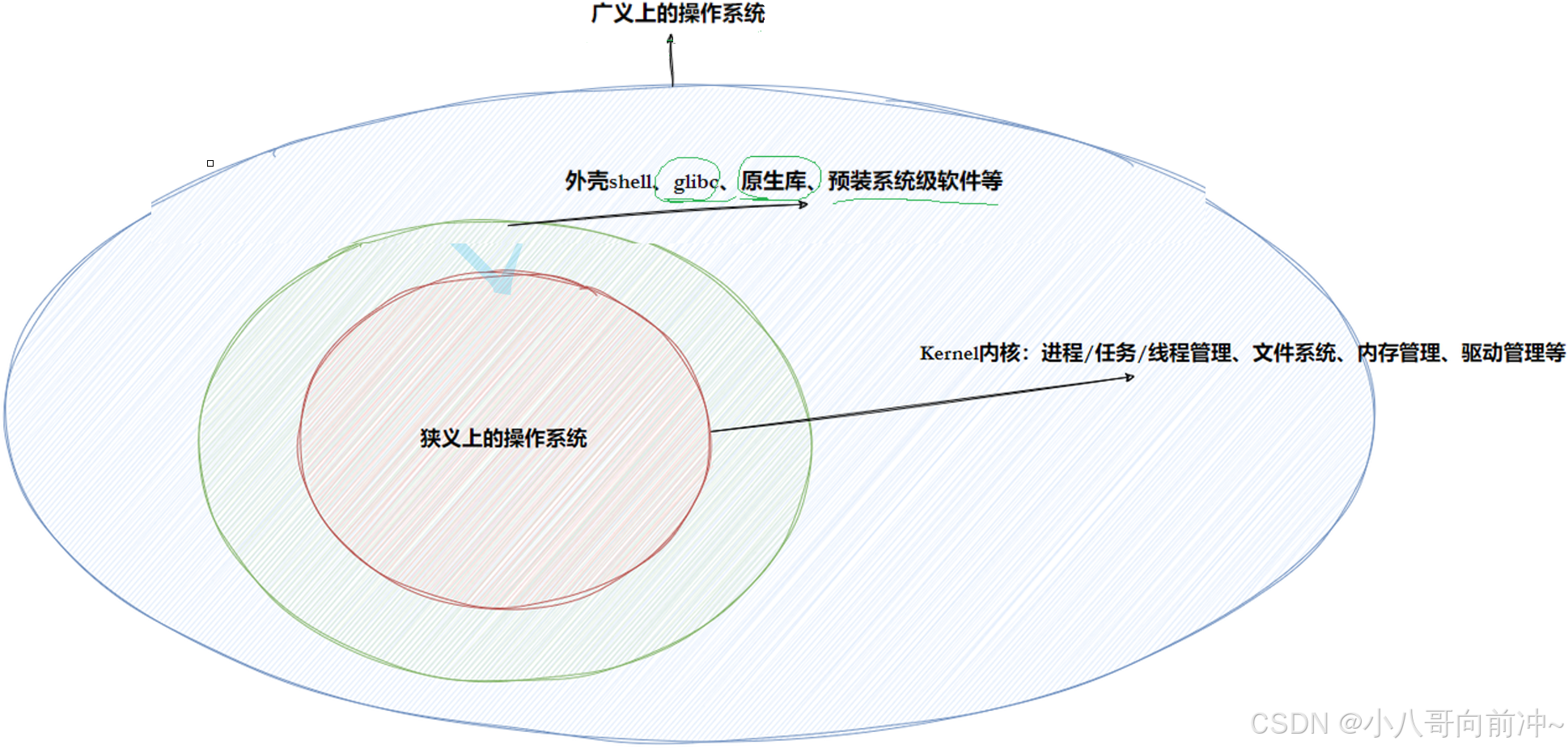
我们不需要将OS看成有多么高大上,整个计算机软硬件架构中,操作系统的定位是:⼀款纯正的"搞管理"的软件。
其实就是一个利用c语言写的一个软件!
这也就是很多人说会c语言就会操作系统的原因,但是这种说法显然是片面的。
设计OS的目的
- 对下,与硬件交互,管理所有的软硬件资源。
- 对上,为用户程序(应⽤程序)提供⼀个良好的执⾏环境
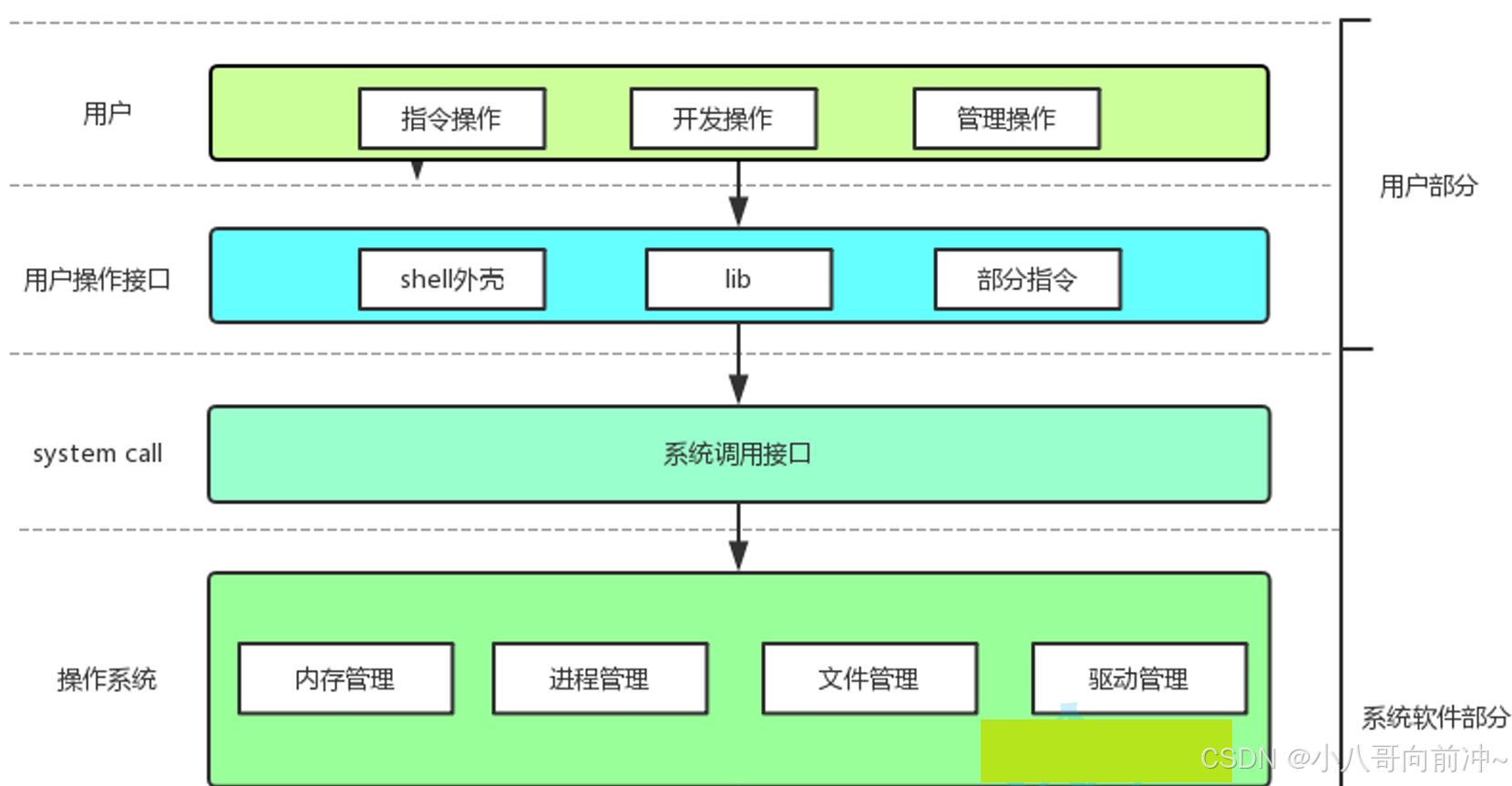
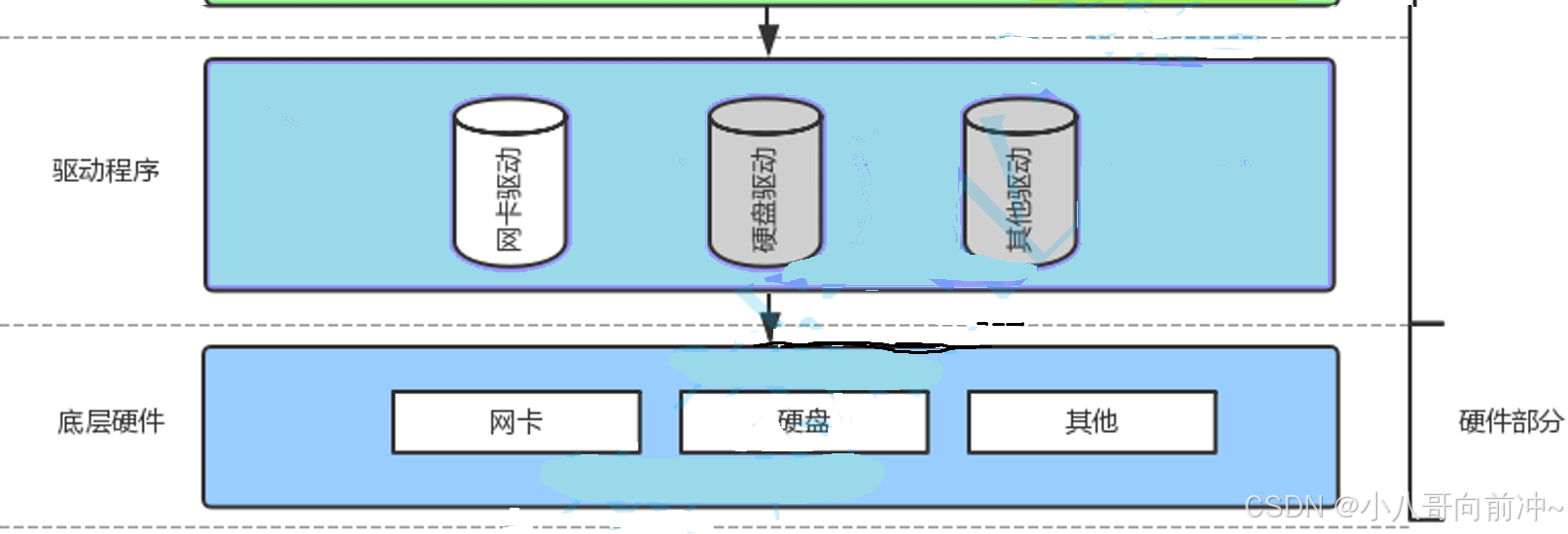
这里的硬件部分就是我们前面讲的遵循冯诺依曼体系结构。
既然我们说操作系统它是一款管理软件,那它是如何管理硬件的?
面对这一个个众多的硬件,将它们管理起来,那么必然要用到数据结构中的知识!
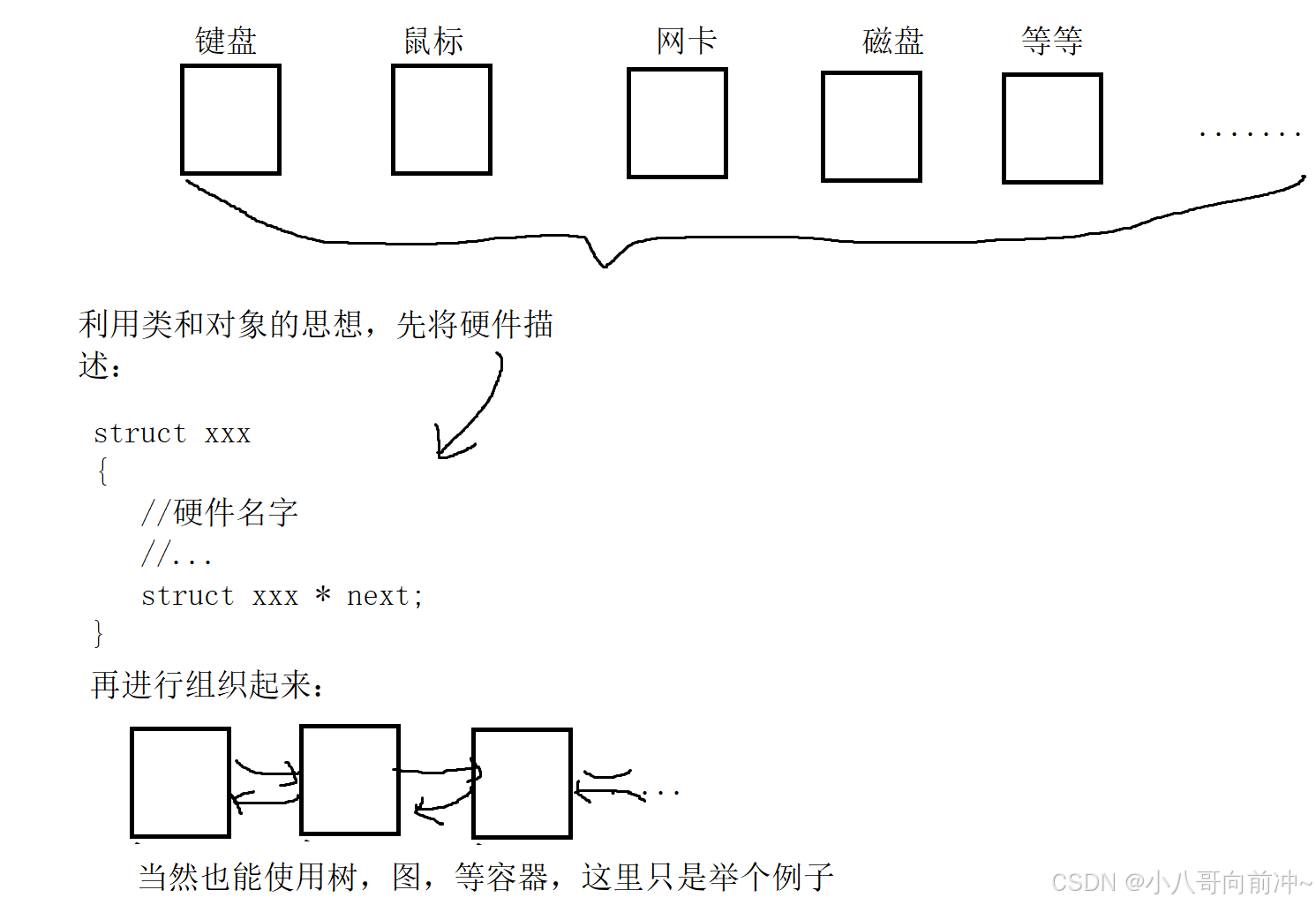
这样一来,操作系统对硬件的管理,转变成对链表的增删查改!
先描述(类和对象),再组织(数据结构)。
这6个字,也就决定了C++,java等面对对象高级计算机语言的地位!
我们要访问操作系统,必须使用系统调用,为什么?
因为操作系统不相信任何人,那我们又需要去访问操作系统,怎么办?所以就提供了一个个系统调用,而系统调用其实就是一个个接口,更准确一点就是一个个c语言函数!当然也有部分指令和外壳等!所以说,我们只能通过库函数,指令,外壳访问操作系统!
当然并不是所有的库函数或者库文件,指令都封装了系统调用,比如:系统调用封装库(如C标准库的fopen
()封装open()系统调用),字符串处理函数(strcpy)、数学函数(sqrt)等,这些不涉及系统调用。
注意:
- 软硬件体系结构是层状结构。
- 访问操作系统必须使用系统调用(其实就是c语言函数,只不过是系统提供的)。
- 只要你判断出访问了硬件,那么必定贯穿整个软硬件体系结构。
其实这种软硬件结构是符合高内聚,低耦合的特点。
高内聚体现在硬件部分只能是硬件,软件只能是软件,每一个部分是"独立"的存在,而各个部分是由一个个接口联系的!比如:我们换一个键盘,鼠标,亦或者网卡,内存条,不管换成哪种牌子,都能用,而不是只能限制一种牌子或者不能换!
再比如我们初学c语言的时候,总是喜欢把所有代码都放在main函数里面,直到我们学了函数,就可以层层调用,层次分明,这也是高内聚的特点。
低耦合的特点体现再它们各自都是用接口联系的,这就是说我们可以随便换鼠标,键盘等外设!
进程
在课本上进程的概念是比较抽象的,导致很多人都会把一个正在执行的程序看成是一个进程,但其实这种是比较片面的!
我们先抛出来:
进程==内核数据结构对象+执行的代码和数据。
解释:
我们执行一个个可执行程序或者软件,它们都要先加载到内存里面(将磁盘数据拷贝到内存里面),OS势必要将这一个个程序管理起来,所以OS会去开一个个节点指向执行的代码和数据,用于管理。一个个节点是一个双链表(也叫进程列表)联系起来!所以说对正在执行的程序的管理转换成了对这个双链表的增删查改。
在此基础上cpu是怎么调度一个一个程序呢?
很简单,有了pcb,cpu只需要拿到一个一个管理程序的pcb即可进行调度,于是这一个个节点又会组成一个调度队列,cpu只需要通过这个调度队列即可转化成了调度队列的增删查改。
注意:双链表和调度队列不冲突,后面会做出解释!
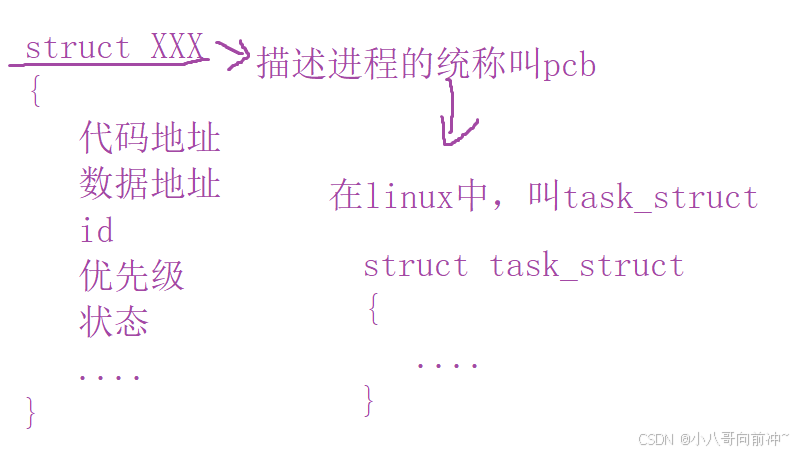
我们将这种描述执行的代码和数据的数据结构对象统称为PCB,而在Linux中叫作task_struct。
它们之间的区别就相当于shell和bash的区别!task_struct只是PCB中的一种。
也就是说:进程==PCB+执行的代码和数据。
task_struct
- 标⽰符(pid):描述本进程的唯⼀标⽰符,⽤来区别其他进程。
- 状态(运行,睡眠,僵尸状态):任务状态,退出代码,退出信号等。
- 优先级:相对于其他进程的优先级。
- 程序计数器:程序中即将被执⾏的下⼀条指令的地址。
- 内存指针:包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针。
- I∕O状态信息:包括显⽰的I/O请求,分配给进程的I∕O设备和被进程使⽤的⽂件列表。
- 记账信息:可能包括处理器时间总和,使⽤的时钟数总和,时间限制,记账号等。
图理解:
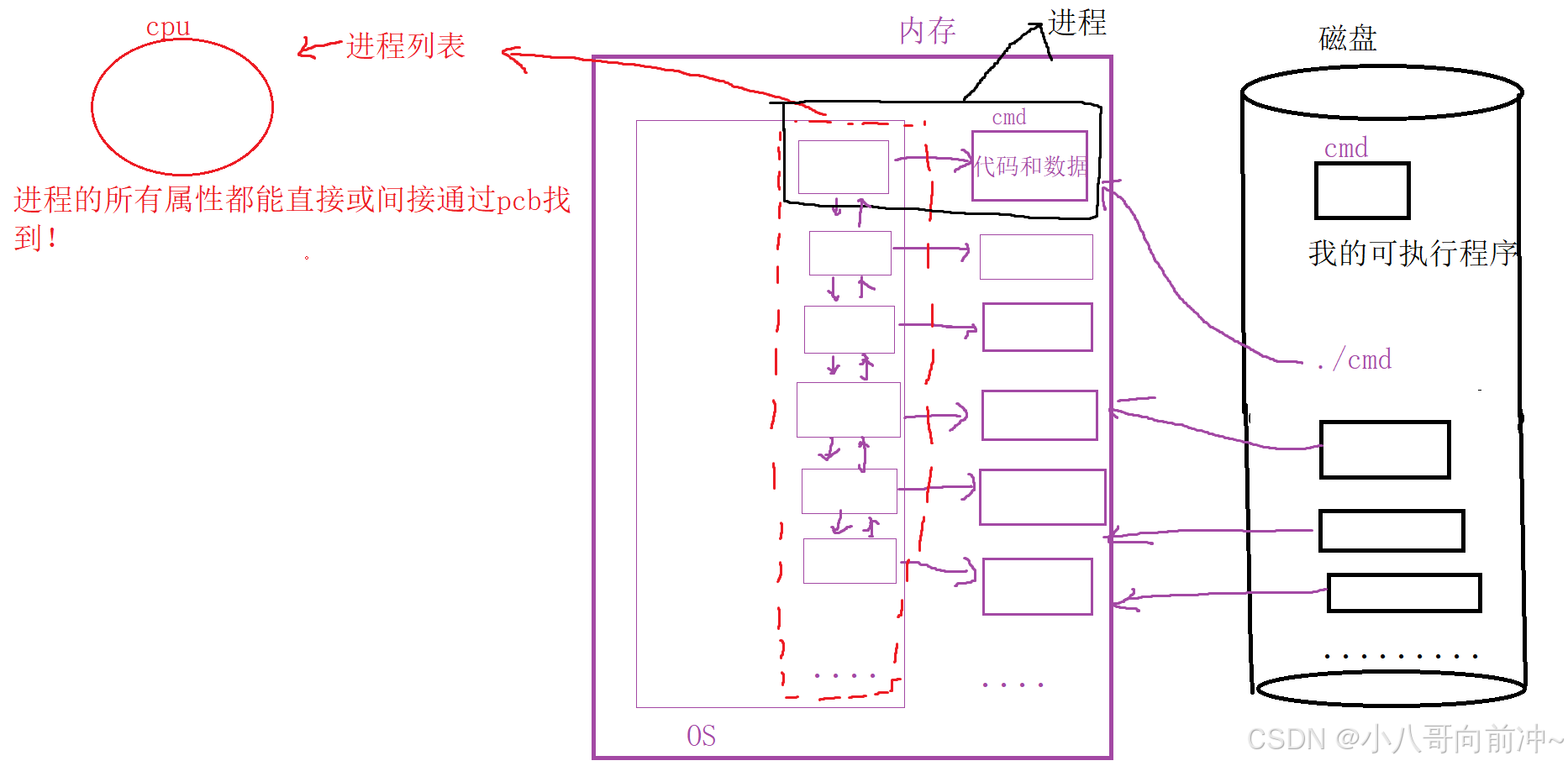
基于上述的理解,所以我们历史上执行过的所有指令,工具,自己的程序,运行起来,就是个进程!
操作
我们运行一个简单的c语言文件(myprocess.c),来逐步理解进程!
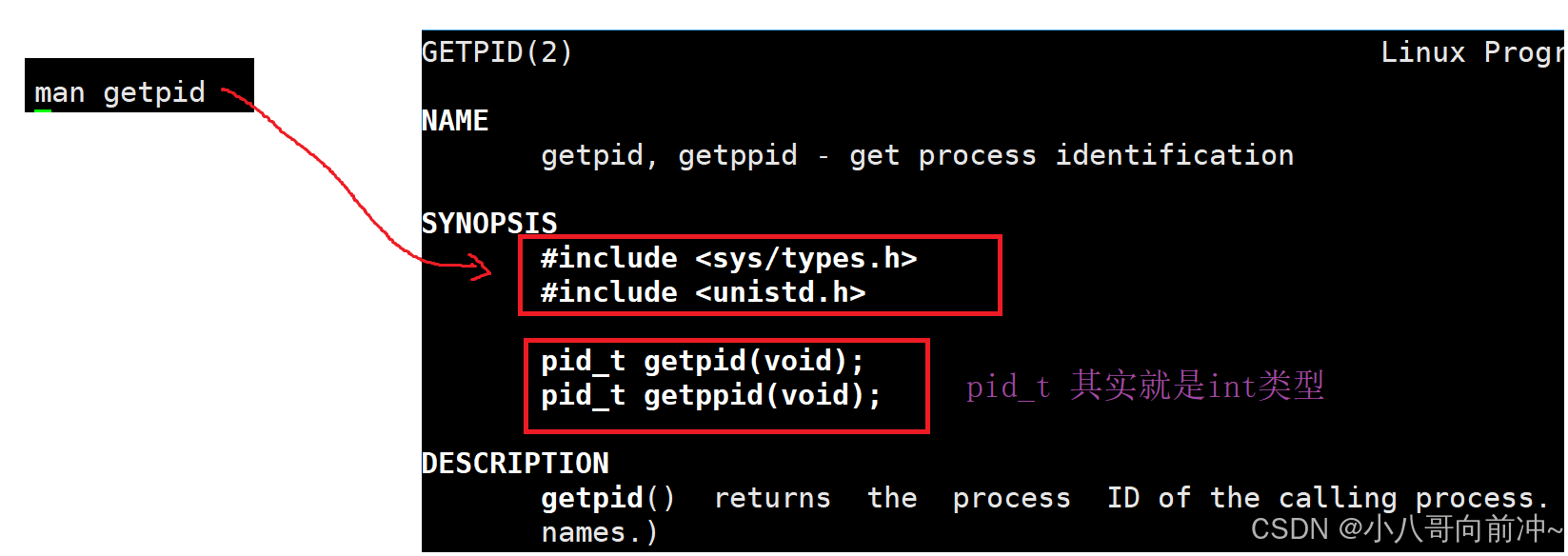
我们利用getpid函数可以获取进程ID。
我们可以查看所有进程:ps axj
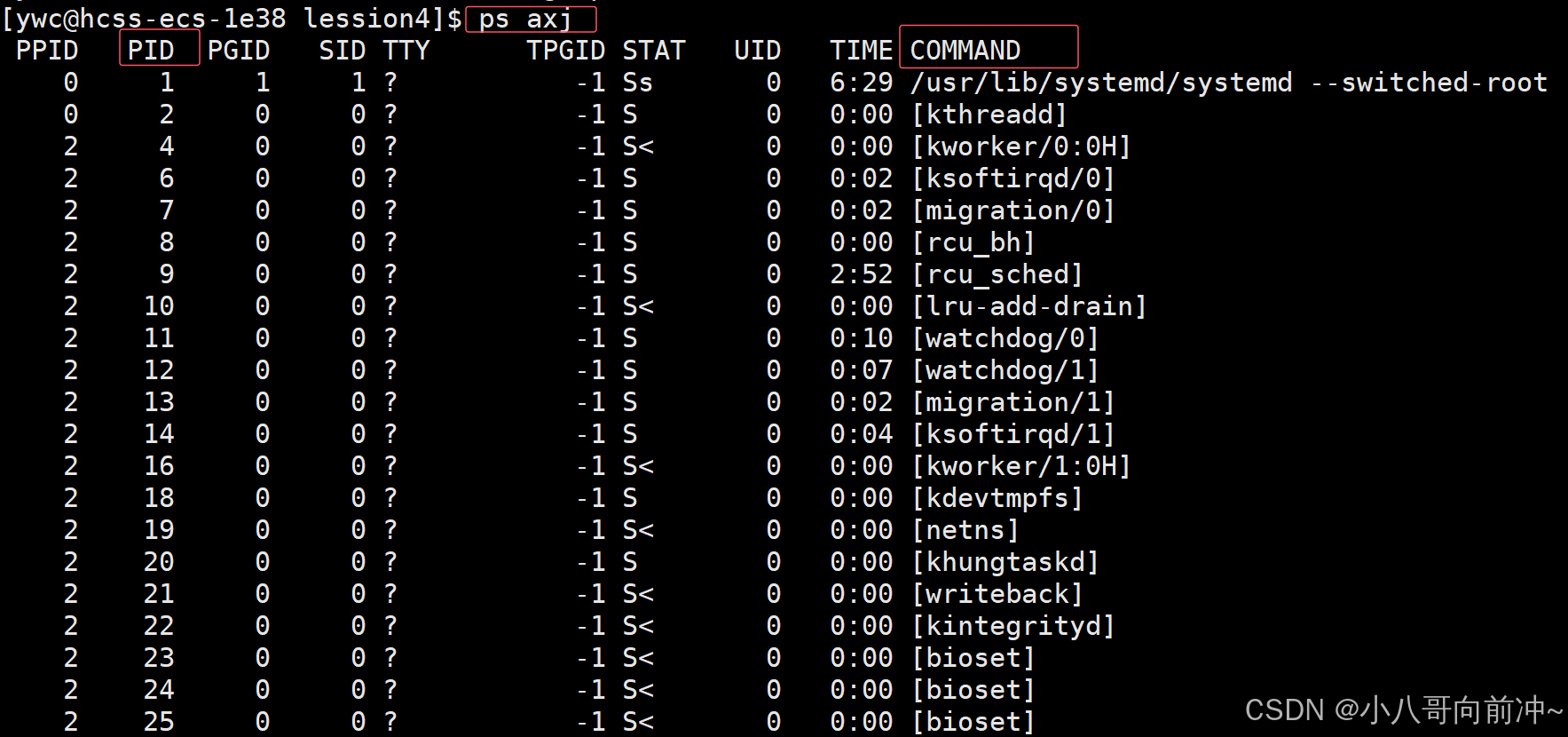
运行myprocess.c,查看:
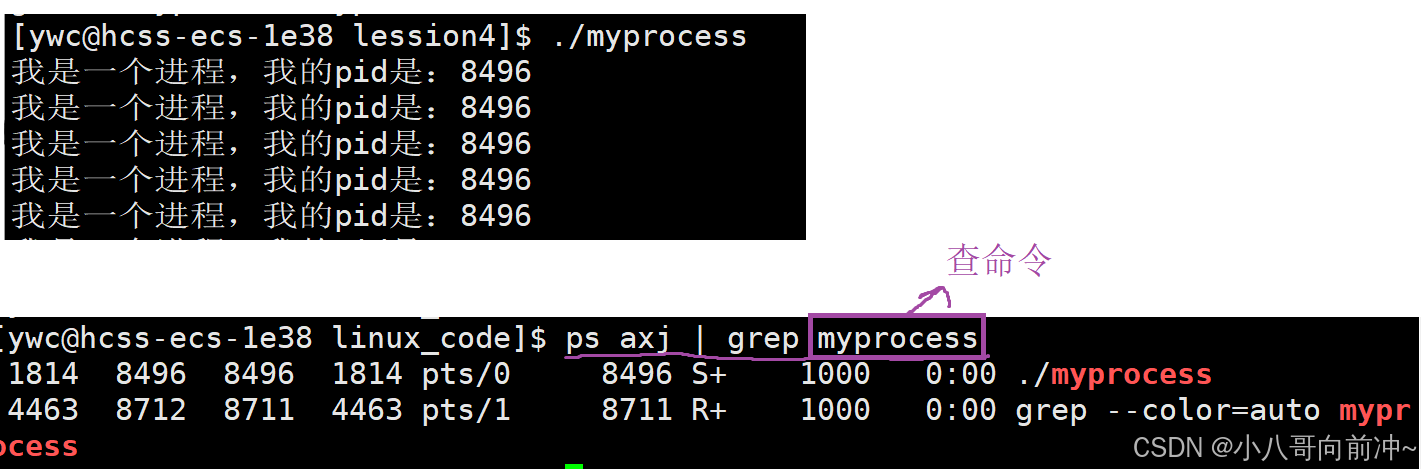
我们在查myprocess的时候,grep也是一个进程,所以grep也查进来了!
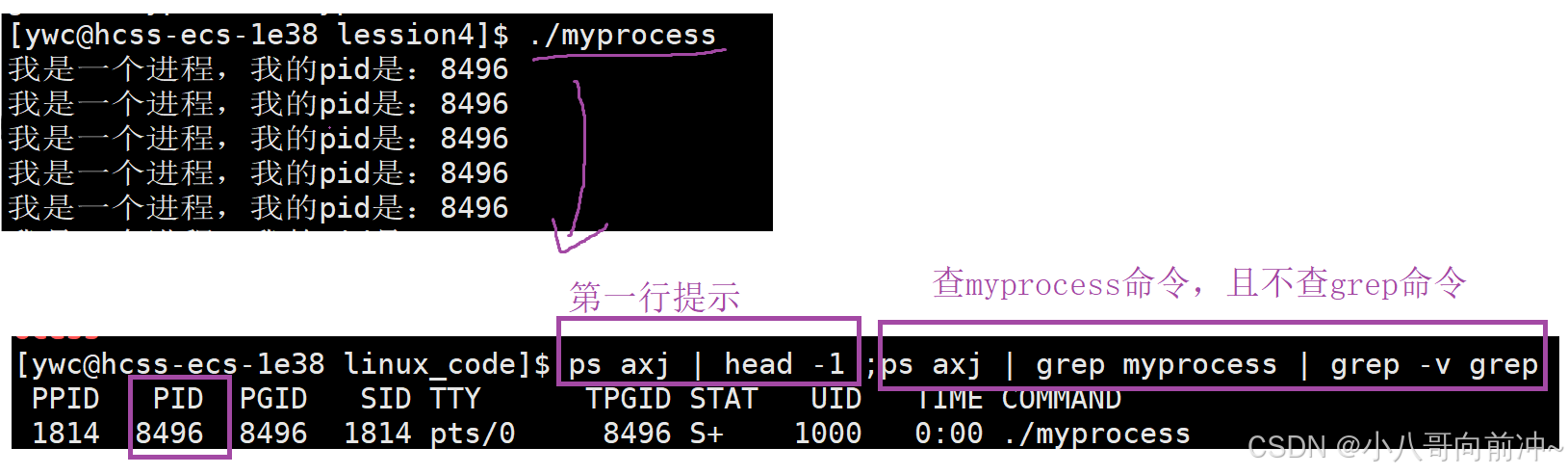
我们也可以这样查:
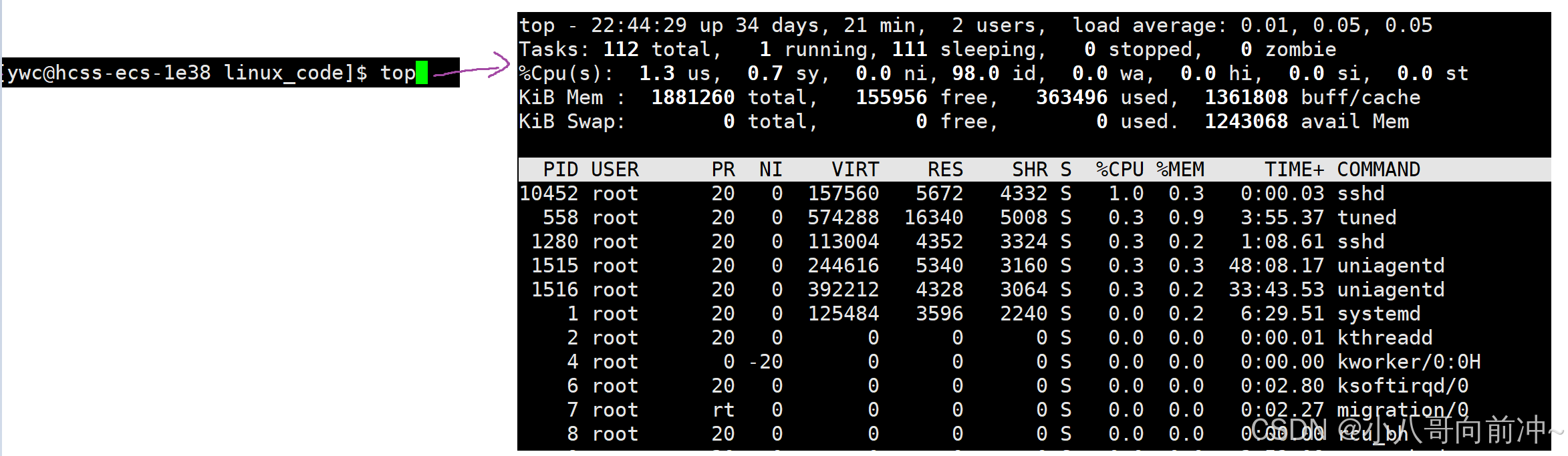
我们也可以通过top指令来查看:
杀掉进程
我们之前知道ctrl+c可以强制退出,其实这就是在杀掉进程,当然我们也可以这样杀掉进程:
kill -9 进程编号
/proc文件夹
我们的进程也可以在/proc查到,/proc文件夹是在磁盘上,而进程是动态的,所以/proc文件夹也是动态的!我们杀掉某个进程,proc文件夹中会立马体现出来。这其实也印证了linux下一切皆文件的说法!
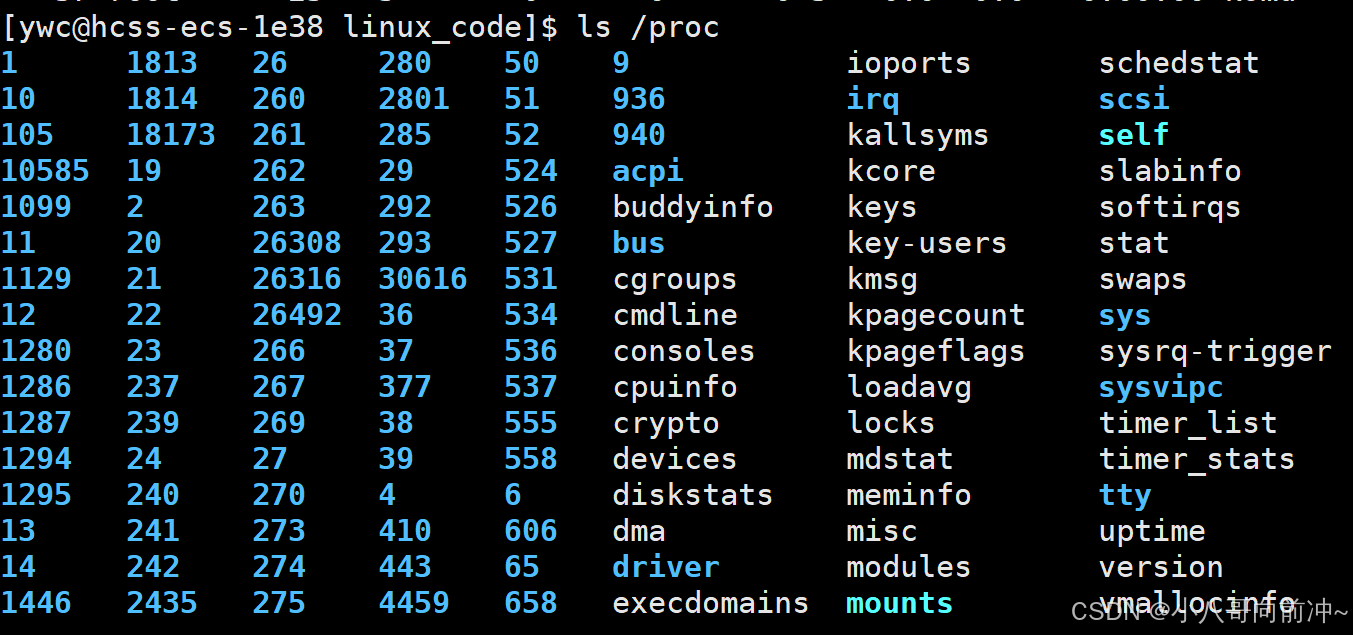
我们可以通过查看/proc文件夹来查看我们想要查看的进程!
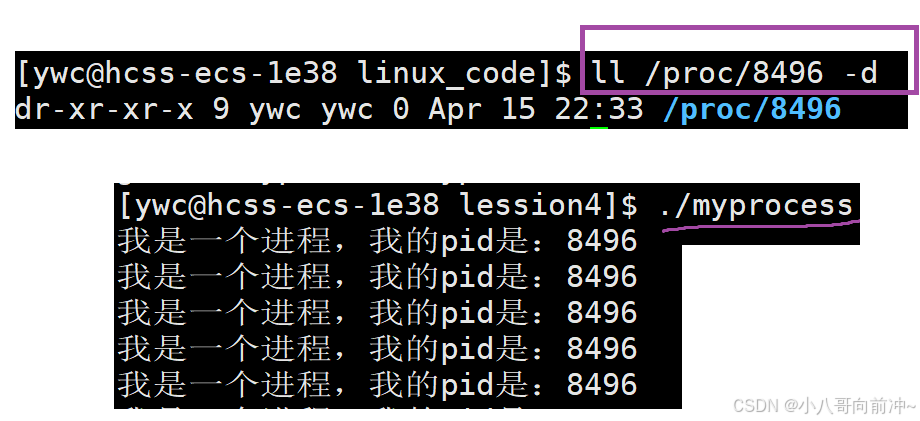
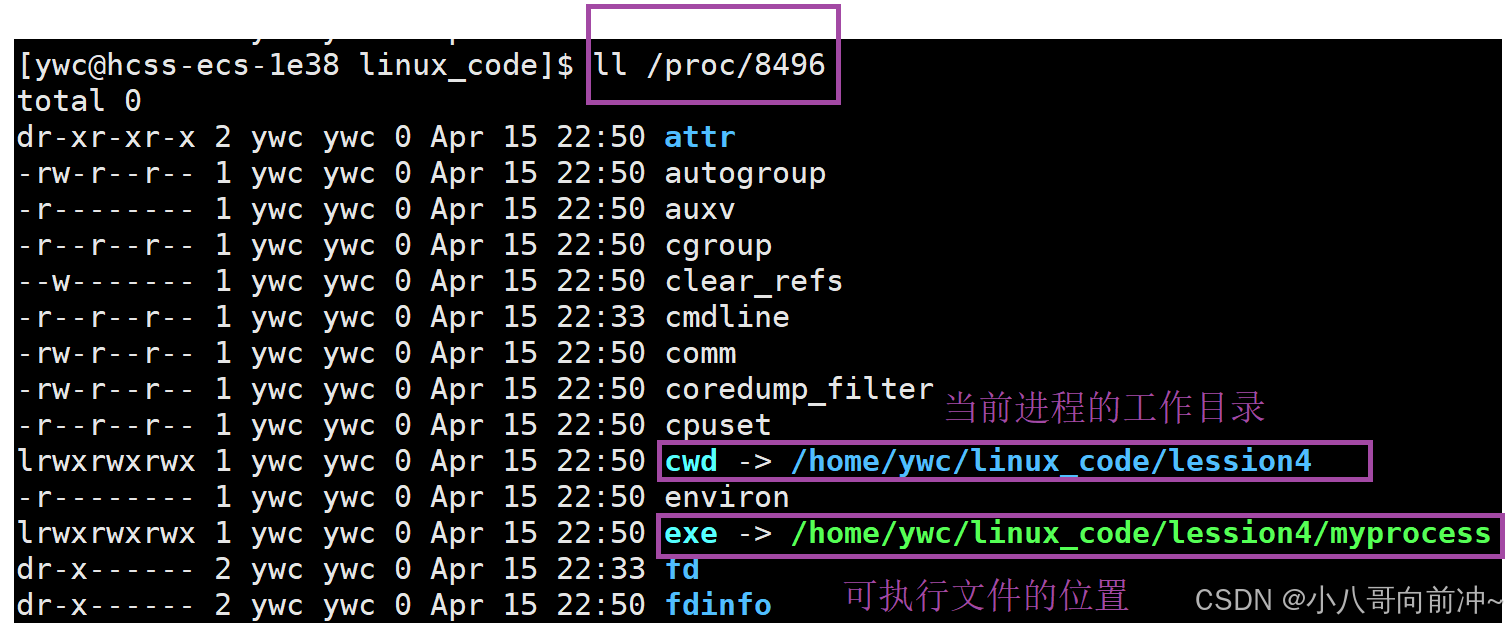
这样我们OS就能通过cwd直到某个进程的工作目录,这也就是为什么当我们写fopen函数时,不需要写当前程序的绝对路径,只需要写目标文件名即可!
当我们在运行某个程序时,我们把可执行文件删掉,此时程序还能跑,这是因为我们删掉的是磁盘中的可执行文件,而运行这个程序时,磁盘中的可执行文件早就拷贝到了内存中,所以还能跑,只是proc/XXX文件中的exe文件会标红,提示我们磁盘中的可执行文件已经没有了!
我们上图看看:

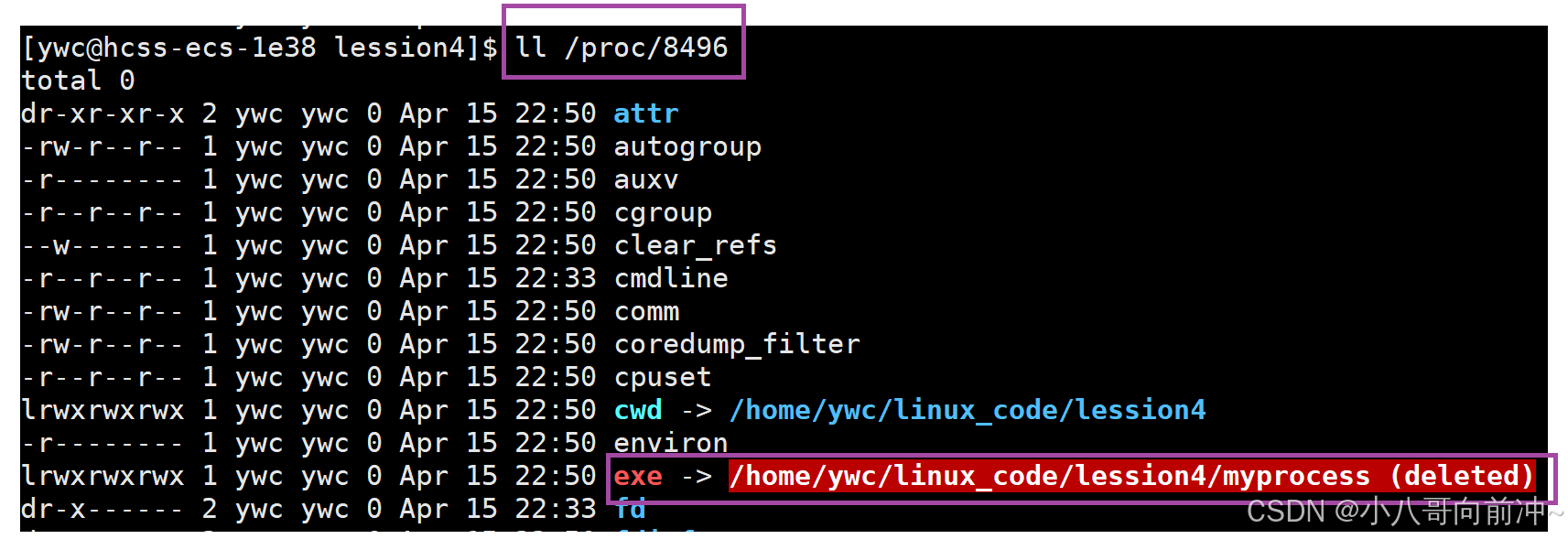
其实,我们可以更改进程的cwd,利用chdir函数可更改。
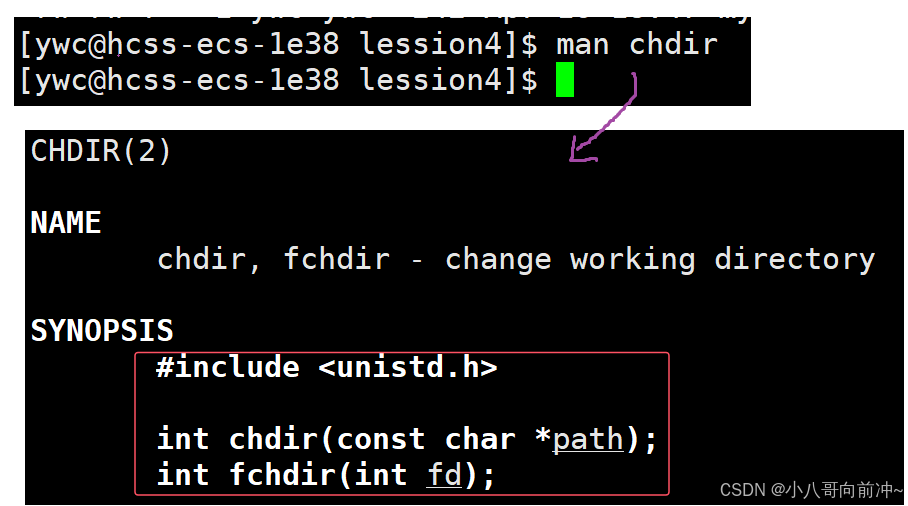
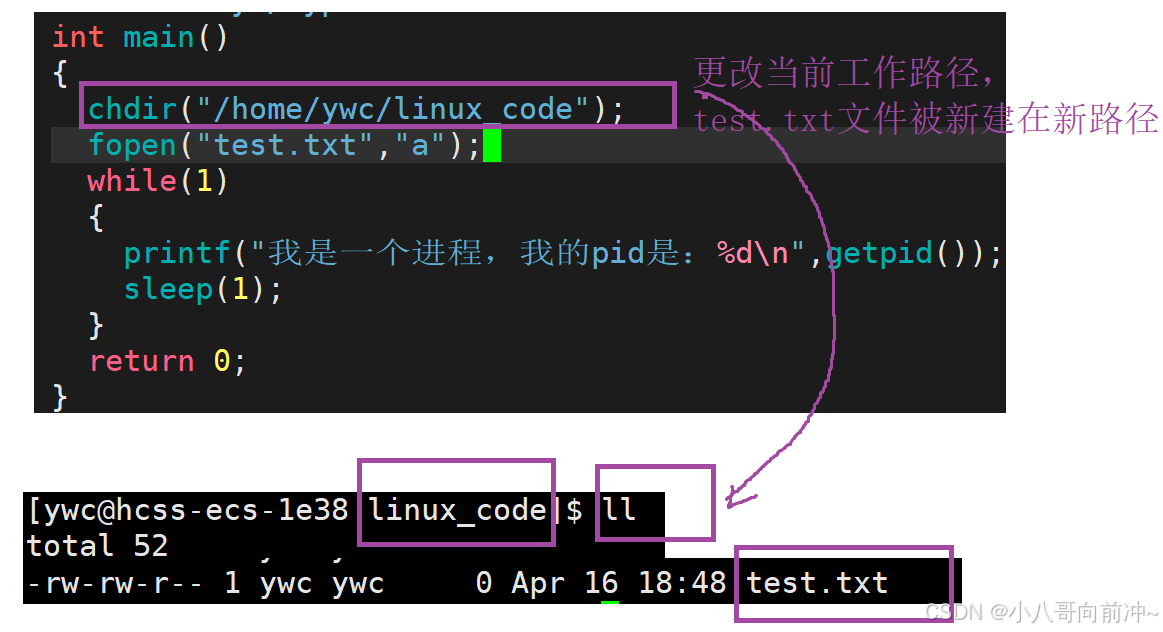
chdir函数具有修改当前工作目录的功能,其实我们常用的cd命令,它的底层就是chdir函数,我们之前说过,我们平时不断敲指令,是命令解释器(bash)来处理我们的各种指令的,所以cd指令其实就是修改bash的路径。
父子进程
我们知道getpid函数可以获取进程自己的ID,但getppid函数可以获取当前进程的父进程!
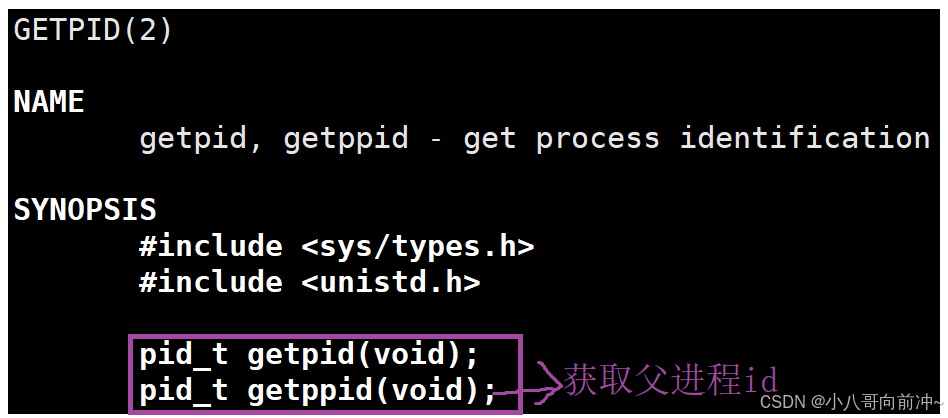
我们的命令解释器(bash)其实也是一个进程,而我们自己主动去启动一个进程,那么这个进程其实就是bash的子进程。我们当然可以同时去启动多个进程(它们都是bash的子进程),所以不难知道:
父进程:子进程==1:n 是1比多的关系!而我们自己也能去创子进程,所以最终进程之间的关系会形成一个多叉树!
至此,我们以前写的所有指令,程序,都是bash的子进程!
我们不断重复的启动/杀某一个进程,它自己的pid会变,而父进程的pid不变。
我们知道可以多个用户登陆一个机器,而OS会给每个登陆用户一个bash,为什么?
因为每个用户都需要去不断敲指令,所以OS会给每个用户分配一个bash来处理每个用户不同的指令需求!
我们不妨说的更深一点,我们知道OS是c语言写的,当然命令解释器也是如此,我们不断的敲指令,是不断的输入,bash不断的解释指令的。
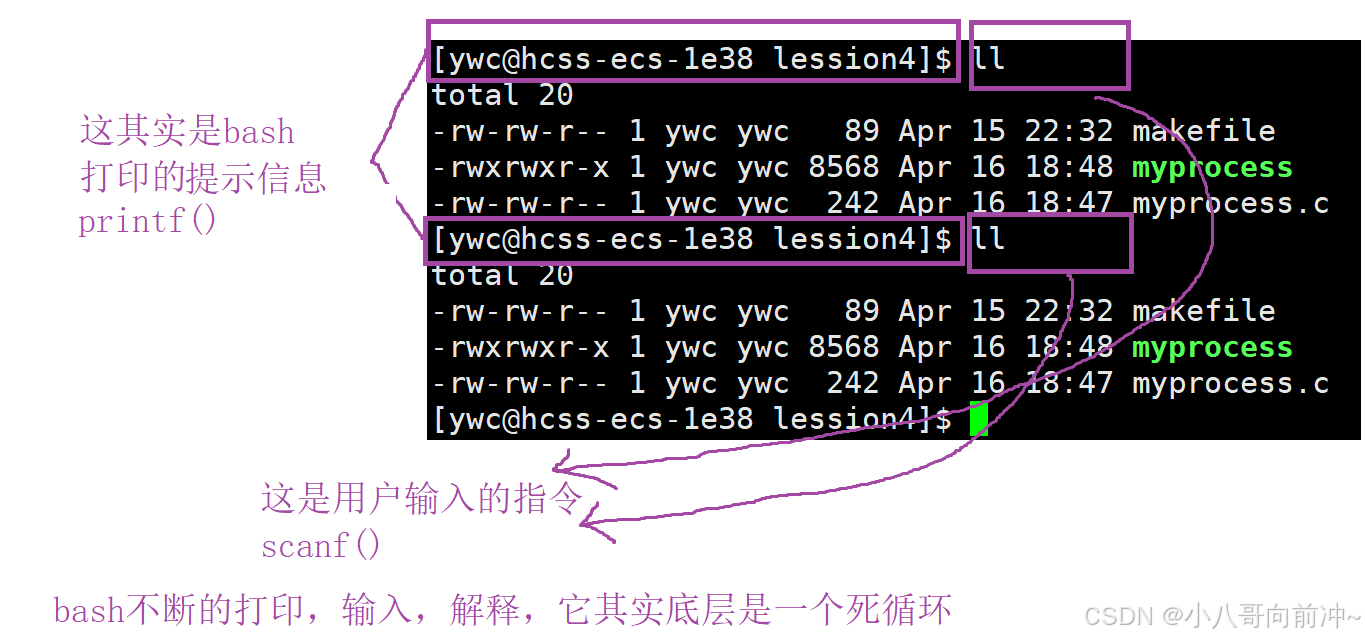
所以说如果有n个用户登陆,就能查到n个bash进程!
一个用户的bash进程的pid只要登陆了就一直不会变,除非退出重新登陆。

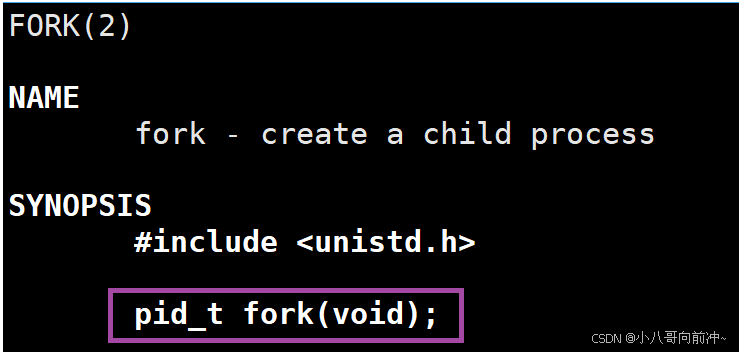
创建子进程
fork函数创建子进程,创建成功给子进程返回0,给父进程返回子进程的pid,创建失败返回-1.
看图:
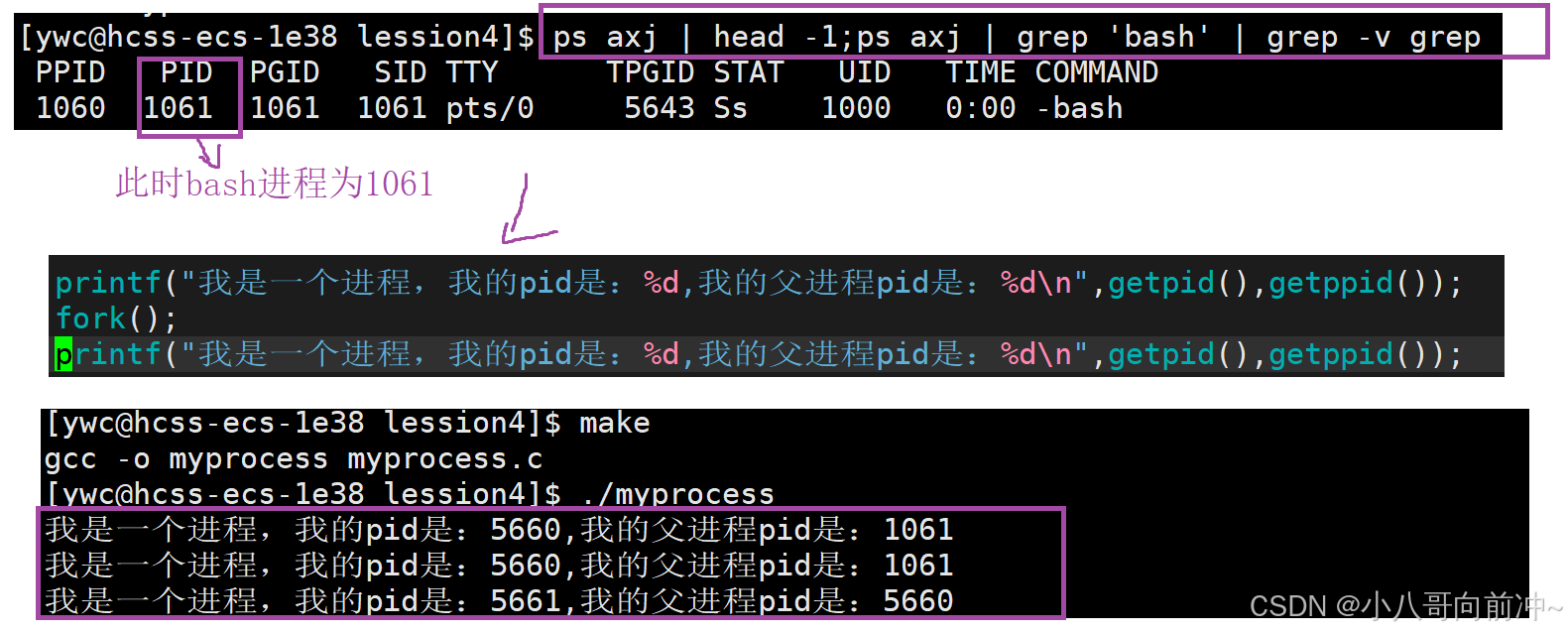
解释:
当前程序先打印,再创建子进程,再打印。
当前的程序的父进程是bash,然后创建一个子进程,这个子进程的父进程是当前执行的程序!
第一次打印只是当前程序的打印,而后两次打印是当前程序和当前程序的子进程分别打印的!
那为什么是这样呢?
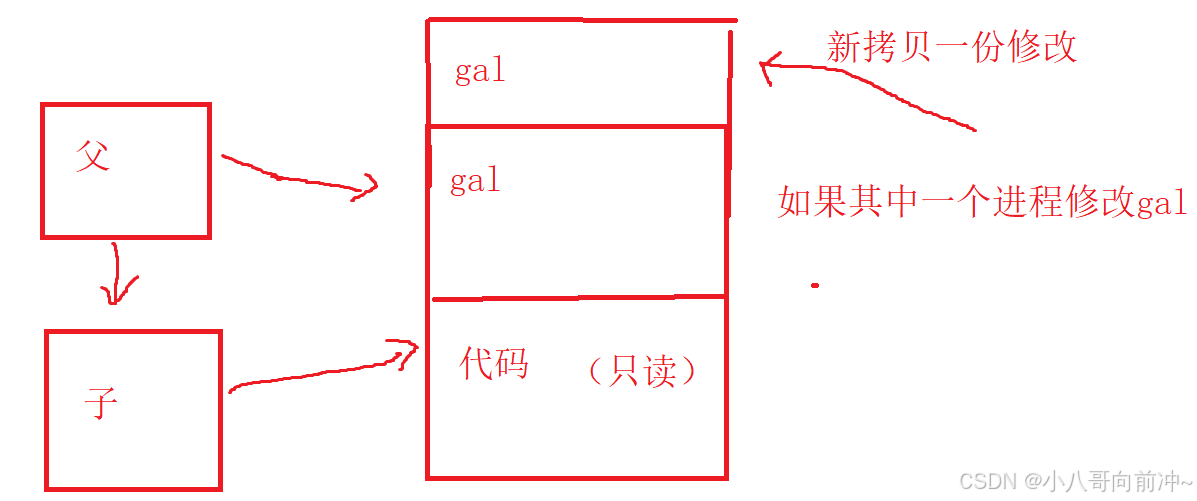
我们知道进程是由pcb+自己的代码和数据,所以说创建一个子进程也就是得有pcb和自己的代码和数据,所以会申请一个新的pcb,父进程会把自己的pcb拷贝给子进程pcb,既然pcb都是一样的,那么父进程的代码和数据都是和子进程共享的。(代码是只读,数据是写时拷贝,我们后面讲)。
我们继续看:
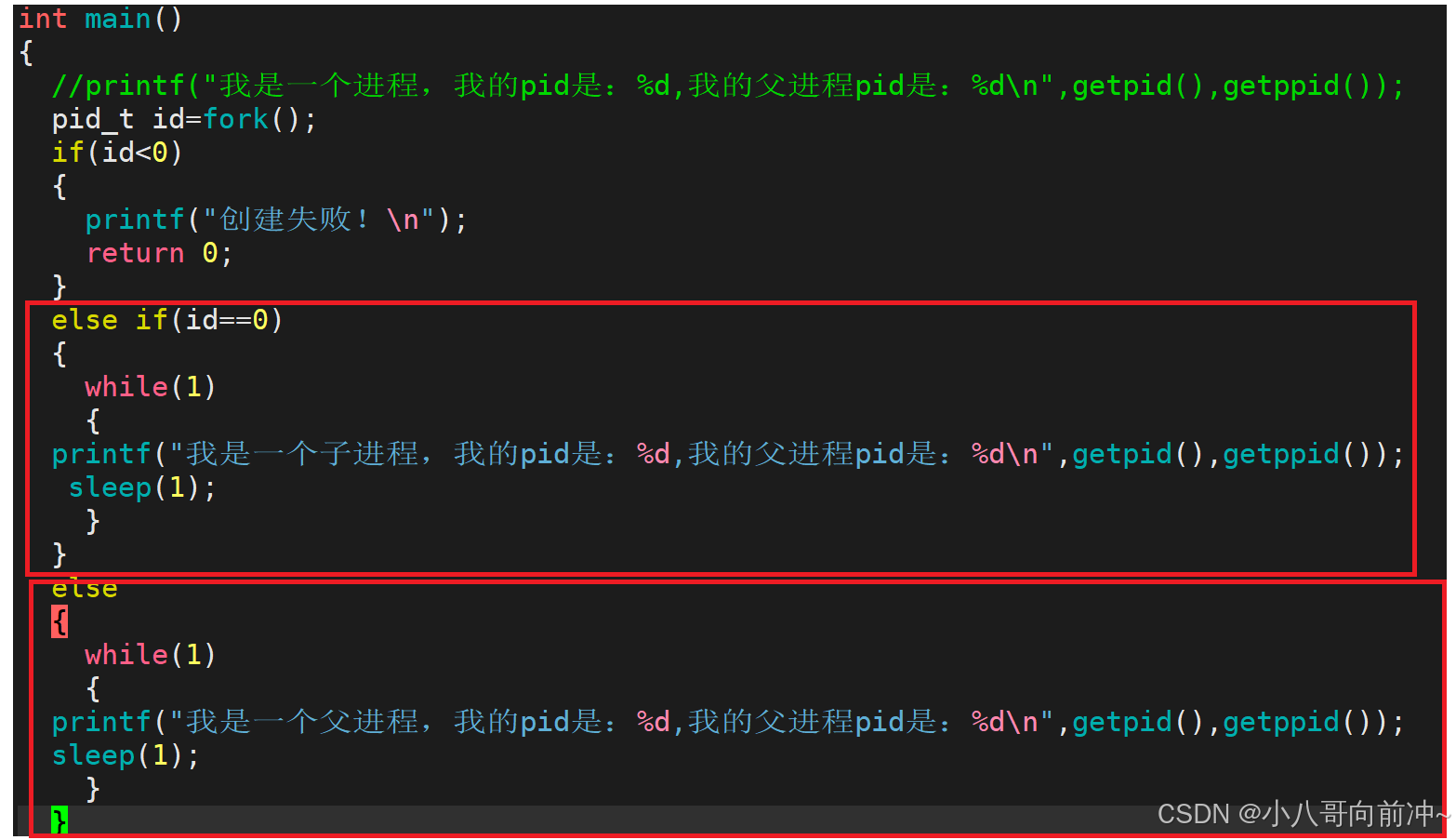
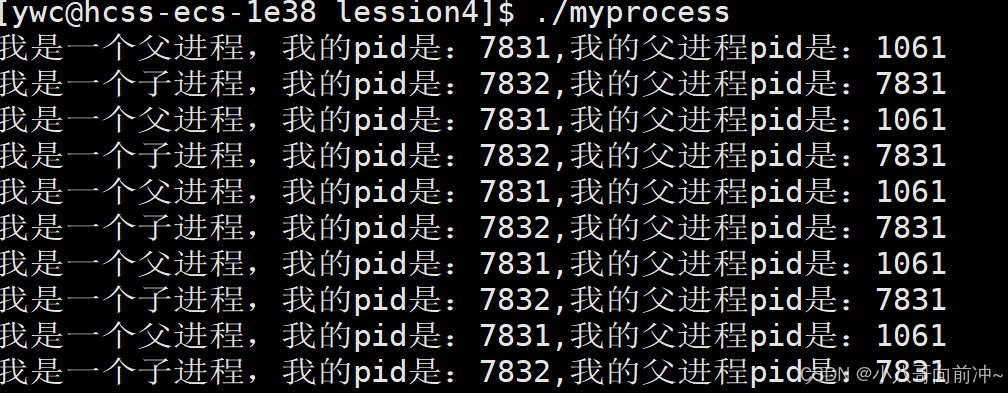
看到这里,就有一点看不懂了!
解释一下:
程序fork出来了一个进程,此时现在就有两个进程,因为fork函数是给子进程返回0,给父进程返回子进程的pid,所以子进程走id==0的if条件,而父进程走id>0的if条件。
至此我们有几个疑问:
为什么fork函数要给子进程返回0,父进程返回子进程的pid?
我们知道一个父进程可以有多个子进程,那么父进程怎么区分这么多子进程呢?所以要给父进程返回子进程的pid以便区分。
为什么fork函数能有两个返回值?怎么实现的?进入fork函数,先申请一个新的pcb,拷贝父进程的pcb拷贝给子进程pcb,将子进程pcb放入进程列表,甚至放入调度队列中,此时子进程就已将被创建,然后父进程跑一次return语句,子进程也跑一遍!
既然父子进程在fork函数执行return语句时分流,而id变量始终是一个变量,怎么能存储两个值呢?我们前面说过,父子进程的代码是只读共享的,数据是写时拷贝的共享,什么是写时拷贝呢?写时拷贝就是,父子进程任何一方需要给同一个变量修改时,OS会先将这个变量拷贝一份,然后供一方修改。
我们可以验证一下写时拷贝:
代码:
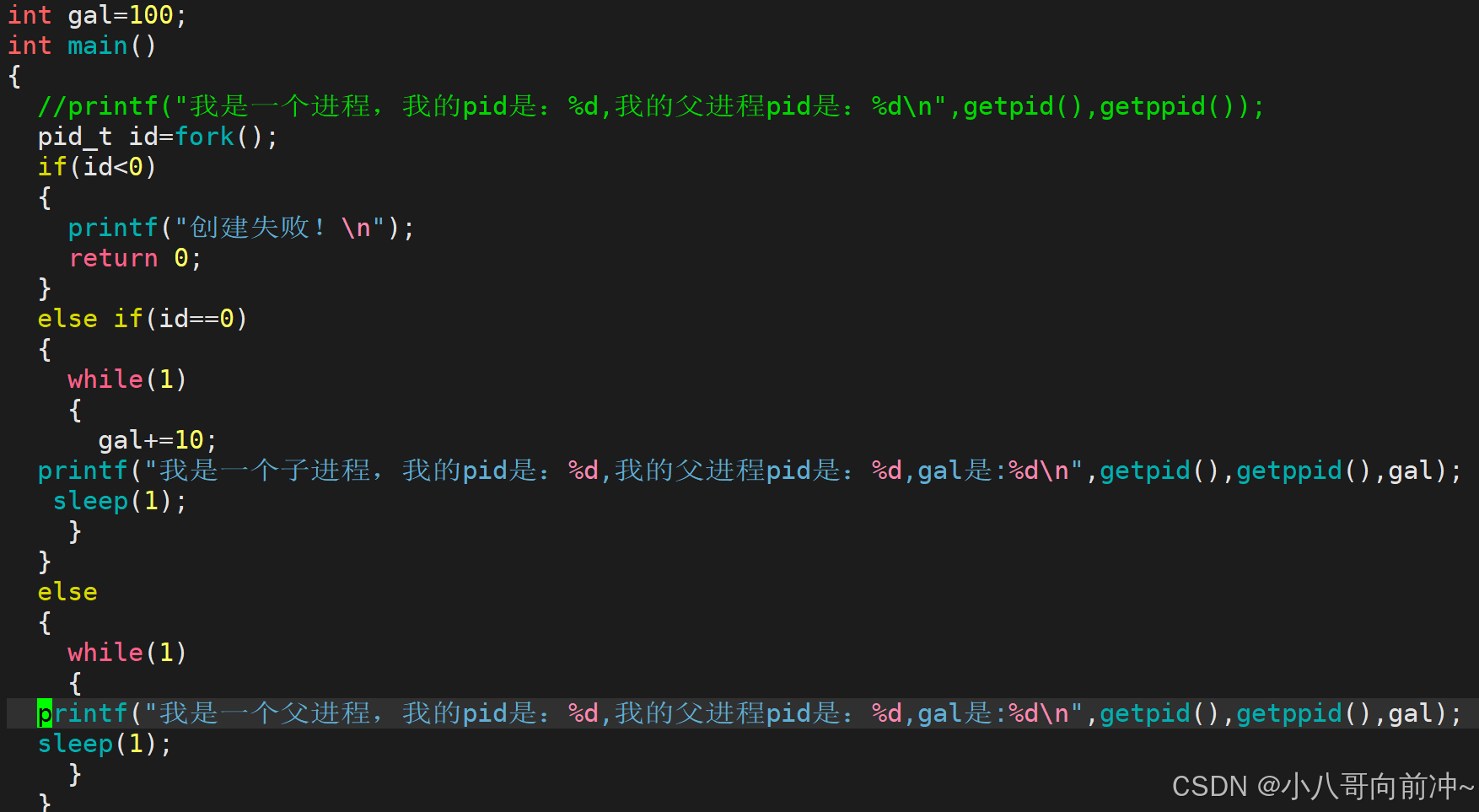
因为写时拷贝,所以子进程的gal会变,而父进程的gal始终是100.
结果:
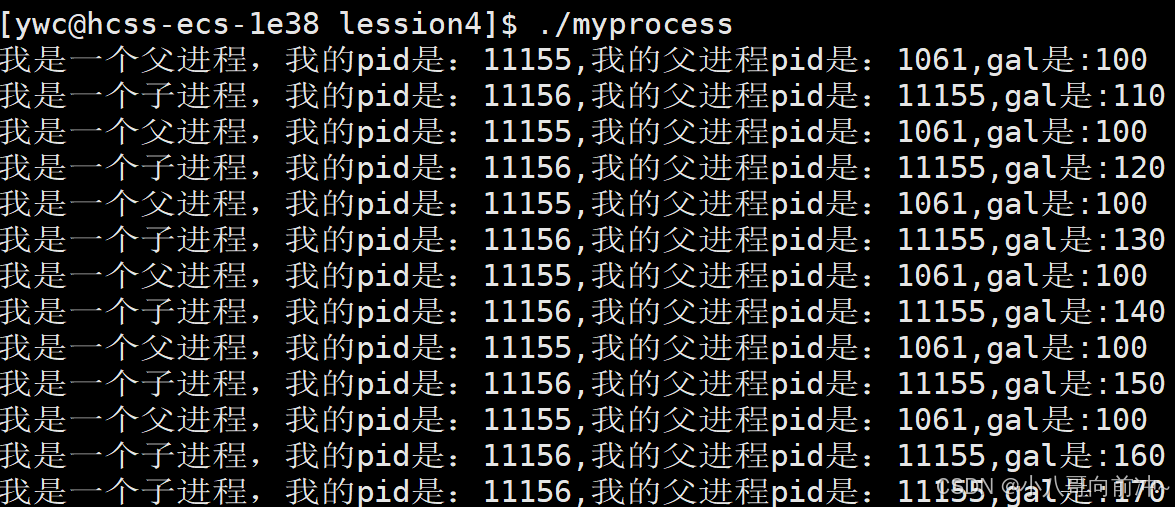
图:
好了,我们下期见!