服务化性能调优
前置准备
- 完成MindIE环境的安装,参考链接
- 下载好要调优的模型权重
- 下载好性能测试数据集
调优流程
下面以Llama3-8B为例,讲解调优全流程
1.查看模型权重大小
Llama3-8B权重为15GB 
2.计算npuMemSize
计算公式为:Floor(单卡显存-空闲占用-权重/NPU卡数)\* 系数,系数取值为0.8 单卡空闲显存:61GB 空闲占用:约3GB 
npuMemSize = Floor (61 - 3 - 15/1 ) * 0.8 = 34GB
3.计算maxBatchSize
maxBatchSize = Total Block Num/Block Num,需要先计算出"Total Block Num"和"Block Num"的值
- 计算"Total Block Num"的值 Total Block Num = Floor(NPU显存 / (Block Size * 模型网络层数 * 模型注意力头数 * 注意力头大小 * Cache类型字节数 * Cache数))
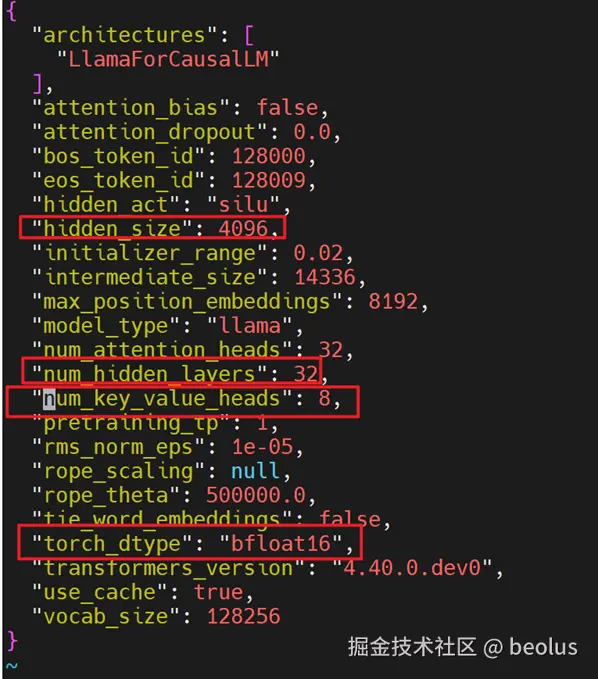
对于GQA类模型,注意力头大小=hidden_size/num_attention_heads 将以上参数值代入公式,得到Total Block Num = Floor34*1024* 1024*1024/(128 \* 32 \* 8* (4096/32)*2*2) = 2176
-
计算单个请求的"Block Num" 所需最大Block Num = Ceil(输入Token数/cacheBlockSize)+Ceil(最大输出Token数/cacheBlockSize) 所需最小Block Num = Ceil(输入Token数/cacheBlockSize) 所需平均Block Num = Ceil(输入Token数/cacheBlockSize)+Ceil(平均输出Token数/cacheBlockSize)
从下面benchmark信息获取数据集信息: InputTokens: 60(avg), 186(max), 23(min) OutputTokens: 467(avg), maxIterTimes(max), 18(min)

所需最小Block Num = Ceil(60/128) = 1 所需最大Block Num = Ceil(60/128)+Ceil(512/128) = 5 所需平均Block Num = Ceil(60/128)+Ceil(346/128) = 4
-
计算"maxBatchSize" 最小maxBatchSize = FloorTotal Block Num/所需最大Block Num = 435 最大maxBatchSize = FloorTotal Block Num/所需最小Block Num = 2176 平均maxBatchSize = FloorTotal Block Num/所需平均Block Num = 544
4.计算maxPrefillBatchSize和maxPrefillTokens的值
-
maxPrefillBatchSize建议设置为:maxBatchSize值的一半 maxPrefillBatchSize = FloormaxBatchSize/2 = 544/2 = 272
-
maxPrefillTokens的值一般不超过8192 maxPrefillTokens = maxPrefillBatchSize * 数据集token id平均输入长度 = 272*60 = 16320 根据公式计算出的值大于8192,所以maxPrefillTokens的取值为8192
5.更新配置&性能测试
-
更新配置如下:

-
实测性能 默认参数测试结果:

参数调优后测试结果: 
可以看到,吞吐提升了18%。