目前基于学习的主题定制方法主要依赖于 U-Net 架构,但其泛化能力有限,图像质量也大打折扣。同时,基于优化的方法需要针对特定主题进行微调,这不可避免地会降低文本的可控性。为了应对这些挑战,我们提出了 "即时角色"(InstantCharacter)--一种基于基础扩散变换器的可扩展字符定制框架。InstantCharacter 展示了三个基本优势:首先,它在保持高保真效果的同时,实现了不同角色外观、姿势和风格的开放域个性化。其次,该框架引入了带有级联变换器编码器的可扩展适配器,可有效处理开放域角色特征,并与现代扩散变换器的潜在空间无缝交互。第三,为了有效地训练框架,我们构建了一个包含千万级样本的大规模字符数据集。该数据集被系统地组织成配对(多视角字符)和非配对(文本-图像组合)子集。这种双重数据结构可通过不同的学习途径同时优化身份一致性和文本可编辑性。定性实验证明了 InstantCharacter 在生成高保真、文本可控和字符一致图像方面的先进能力,为字符驱动的图像生成设定了新基准。

方法
与传统的基于 UNet 的架构相比,现代 DiT 已显示出前所未有的保真度和容量,为生成和编辑任务提供了更强大的基础。然而,现有的方法主要基于 UNet,在字符一致性和图像保真度之间面临着根本性的权衡,限制了它们在开放域字符上的通用能力。此外,之前没有任何工作成功验证了大规模扩散变换器(如 12B 参数)上的字符定制,这在该领域留下了巨大的空白。在这些进展的基础上,我们提出了 InstantCharacter,这是一个新颖的框架,它扩展了 DiT,用于可通用的高保真字符驱动图像生成。InstantCharacter 的架构围绕两项关键创新展开。首先,开发了一个可扩展的适配器模块,以有效解析字符特征,并与 DiT 的潜在空间进行无缝交互。其次,我们设计了一种渐进式三阶段训练策略,以适应我们收集的多用途数据集,从而实现字符一致性和文本可编辑性的分离训练。通过将灵活的适配器设计和分阶段学习策略协同结合,我们增强了通用字符定制能力,同时最大限度地保留了基础 DiT 模型的生成先验。在下面的章节中,我们将详细介绍适配器的架构,并详细阐述我们的渐进式训练策略。
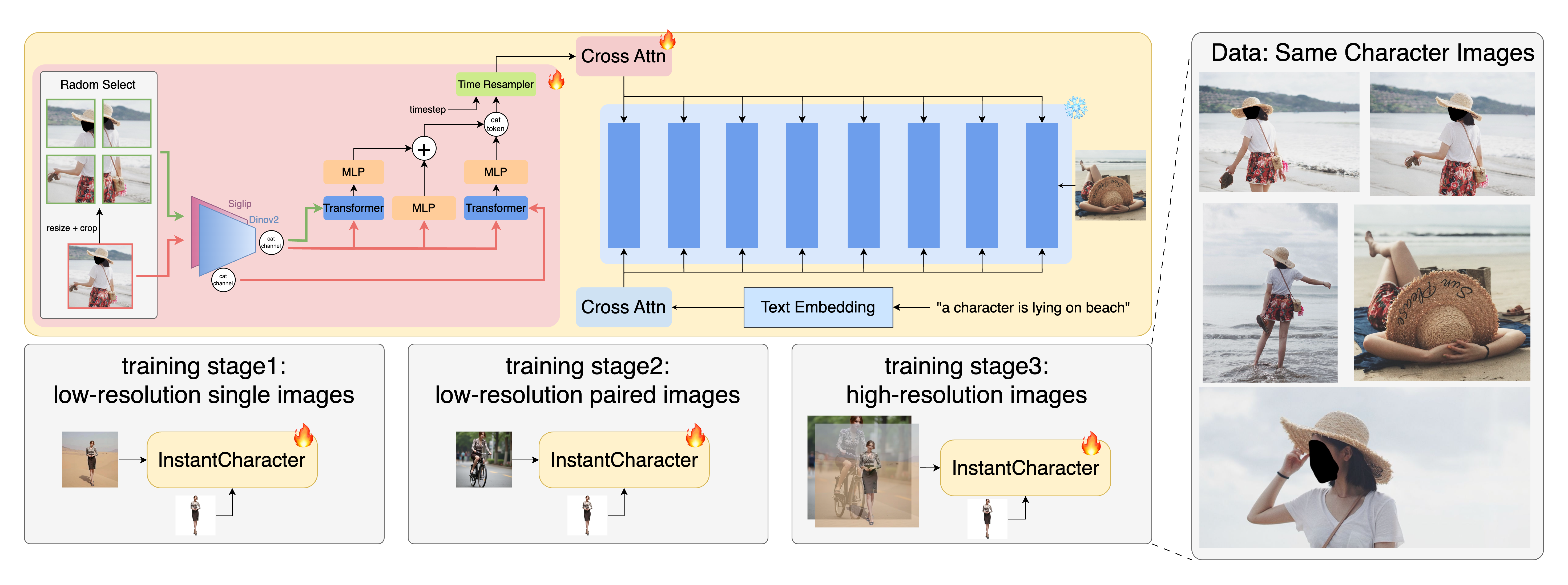

我们的框架将可扩展的适配器与预训练的 DiT 模型无缝集成。适配器由多个堆叠变压器编码器组成,可逐步完善字符表征,实现与 DiT 潜在空间的有效互动。训练过程采用三阶段渐进策略,从无配对低分辨率预训练开始,到配对高分辨率微调结束。
https://github.com/Tencent/InstantCharacter
演示
官方推荐45GB 内存
python
# !pip install transformers accelerate diffusers huggingface_cli
import torch
from PIL import Image
from pipeline import InstantCharacterFluxPipeline
# Step 1 Load base model and adapter
ip_adapter_path = 'checkpoints/instantcharacter_ip-adapter.bin'
base_model = 'black-forest-labs/FLUX.1-dev'
image_encoder_path = 'google/siglip-so400m-patch14-384'
image_encoder_2_path = 'facebook/dinov2-giant'
seed = 123456
pipe = InstantCharacterFluxPipeline.from_pretrained(base_model, torch_dtype=torch.bfloat16)
pipe.to("cuda")
pipe.init_adapter(
image_encoder_path=image_encoder_path,
image_encoder_2_path=image_encoder_2_path,
subject_ipadapter_cfg=dict(subject_ip_adapter_path=ip_adapter_path, nb_token=1024),
)
# Step 2 Load reference image
ref_image_path = 'assets/girl.jpg' # white background
ref_image = Image.open(ref_image_path).convert('RGB')
# Step 3 Inference without style
prompt = "A girl is playing a guitar in street"
image = pipe(
prompt=prompt,
num_inference_steps=28,
guidance_scale=3.5,
subject_image=ref_image,
subject_scale=0.9,
generator=torch.manual_seed(seed),
).images[0]
image.save("flux_instantcharacter.png")
python
# You can also use other style lora
# Step 3 Inference with style
lora_file_path = 'checkpoints/style_lora/ghibli_style.safetensors'
trigger = 'ghibli style'
prompt = "A girl is playing a guitar in street"
image = pipe.with_style_lora(
lora_file_path=lora_file_path,
trigger=trigger,
prompt=prompt,
num_inference_steps=28,
guidance_scale=3.5,
subject_image=ref_image,
subject_scale=0.9,
generator=torch.manual_seed(seed),
).images[0]
image.save("flux_instantcharacter_style_ghibli.png")
# Step 3 Inference with style
lora_file_path = 'checkpoints/style_lora/Makoto_Shinkai_style.safetensors'
trigger = 'Makoto Shinkai style'
prompt = "A girl is playing a guitar in street"
image = pipe.with_style_lora(
lora_file_path=lora_file_path,
trigger=trigger,
prompt=prompt,
num_inference_steps=28,
guidance_scale=3.5,
subject_image=ref_image,
subject_scale=0.9,
generator=torch.manual_seed(seed),
).images[0]
image.save("flux_instantcharacter_style_Makoto.png")