
docker和云服务的区别
首先明确Docker的核心功能是容器化,它通过容器技术将应用程序及其依赖项打包在一起,确保应用在不同环境中能够一致地运行。而云服务则是由第三方提供商通过互联网提供的计算资源,例如计算能力、存储、数据库等。云服务的范围更广,涵盖了IaaS(基础设施即服务)、PaaS(平台即服务)和SaaS(软件即服务)等多种形式。
Docker可以与云服务结合使用,例如在云服务商提供的虚拟机中运行Docker容器,或者直接使用云服务商提供的容器服务(如AWS ECS、Google Kubernetes Engine等)。但两者本质上解决的问题不同,Docker关注的是应用的封装和隔离 ,而云服务关注的是计算资源的按需分配和管理。
-
Docker底层原理:Docker利用了Linux内核的命名空间(namespace)和控制组(cgroup)技术来实现容器的隔离和资源限制。命名空间提供了进程、网络、文件系统等方面的隔离,使得每个容器看起来像是独立的系统。控制组则用于限制和分配容器使用的CPU、内存等资源。
-
云服务分类:
-
IaaS(基础设施即服务):提供虚拟机、存储、网络等基础计算资源,用户可以在这些资源上部署自己的操作系统和应用。例如AWS EC2、Azure Virtual Machines。
-
PaaS(平台即服务):除了基础资源外,还提供了开发工具、数据库管理、应用托管等功能,简化了应用的开发和部署过程。例如Google App Engine、Heroku。
-
SaaS(软件即服务):直接向用户提供完整的软件应用,用户无需关心底层的技术细节。例如Salesforce、Office 365。
-
Docker与云服务的关系:虽然Docker和云服务的功能不同,但它们可以很好地互补。云服务提供了灵活的计算资源,而Docker则确保了应用在这些资源上的可移植性和一致性。例如,在Kubernetes集群中,Docker容器可以被编排和调度到不同的云实例上,从而实现高效的资源利用和应用扩展。
-
扩展知识:
-
容器与虚拟机的区别:容器和虚拟机都是用于隔离应用运行环境的技术,但容器共享宿主机的操作系统内核,而虚拟机则需要为每个实例运行一个完整操作系统。因此,容器在启动速度、资源占用方面具有优势,但在安全性上可能不如虚拟机。
-
云原生架构:随着容器技术和云服务的发展,云原生架构逐渐成为现代应用开发的趋势。云原生强调应用的设计应充分利用云的特点,例如弹性扩展、自动化部署、微服务架构等。Docker和Kubernetes是实现云原生的重要工具。
golang中读取文件的流程是什么
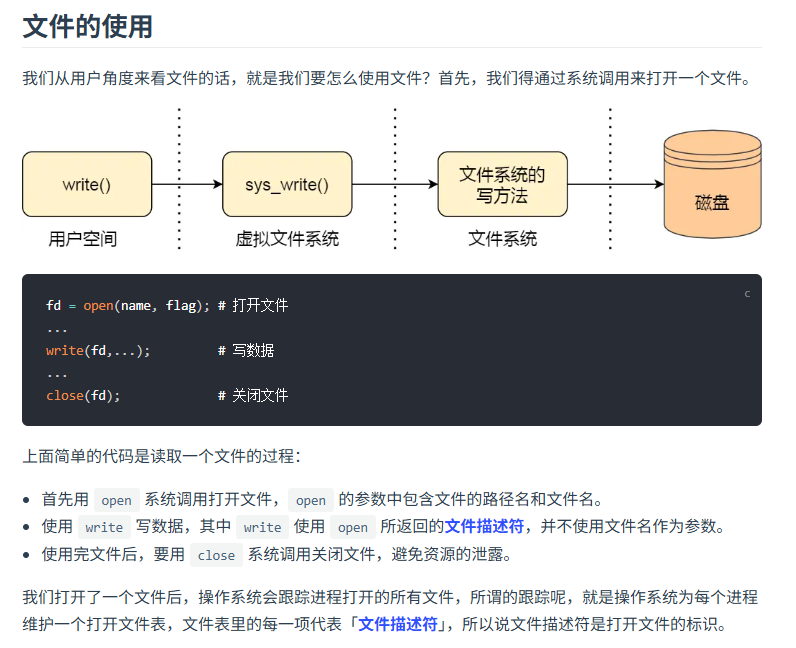
- 导入必要的包:要进行文件操作,必须先导入"os"包,如果需要更高效的缓冲读取,则还需要导入"bufio"包。
- 打开文件:使用os.Open(path)函数打开指定路径的文件,该函数返回一个*os.File类型的指针和可能的错误信息。
- 读取文件:可以选择不同的方式读取文件内容。可以直接使用file.Read方法将文件内容读取到字节切片中,也可以使用bufio.NewReader创建一个带缓冲的Reader对象,然后逐行读取文件内容。
- 关闭文件:无论读取过程是否成功,都需要确保文件被正确关闭以释放系统资源。这通常通过defer file.Close()实现,确保即使发生错误也能关闭文件。
- 深度知识讲解:
- 文件操作涉及操作系统层面的知识,在Go语言中,文件被视为一种特殊的流(stream)。打开文件实际上是在操作系统中请求一个文件描述符(file descriptor),这个描述符是内核用来跟踪文件状态的一个整数标识符。
- os.Open实际上是调用了底层的操作系统API来获取对文件的访问权限。它返回的是一个实现了io.Reader接口的对象,这意味着你可以使用任何符合该接口的方法来处理文件数据。
- 使用bufio包的好处在于它可以提供缓冲机制,减少频繁的系统调用,从而提高性能。例如,bufio.NewReader会预先读取一定量的数据到内存缓冲区,后续的小批量读取操作都会从缓冲区中获取数据,而不是每次都向操作系统发起请求。


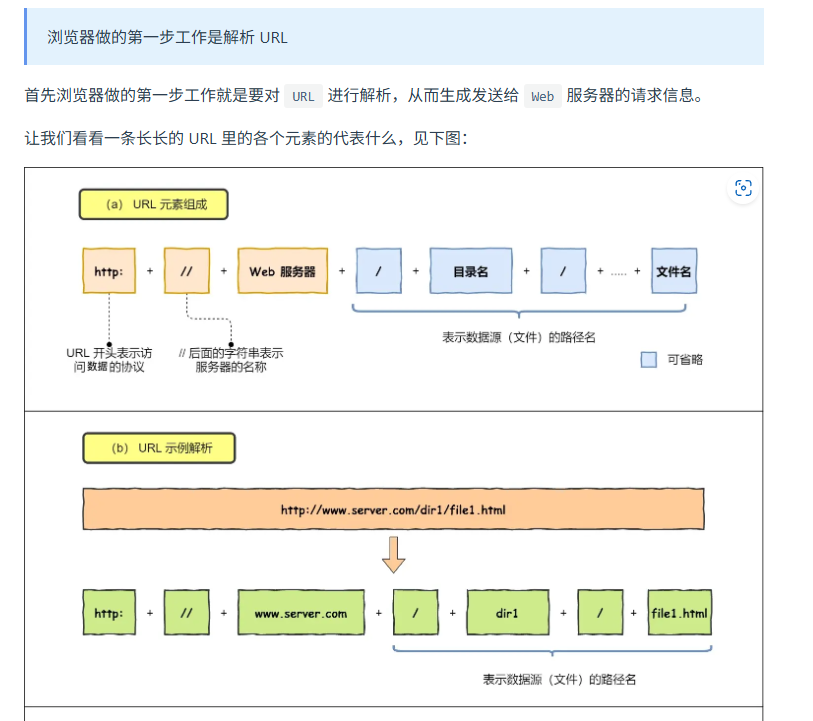
一个URL的输入到浏览器展示页面的过程
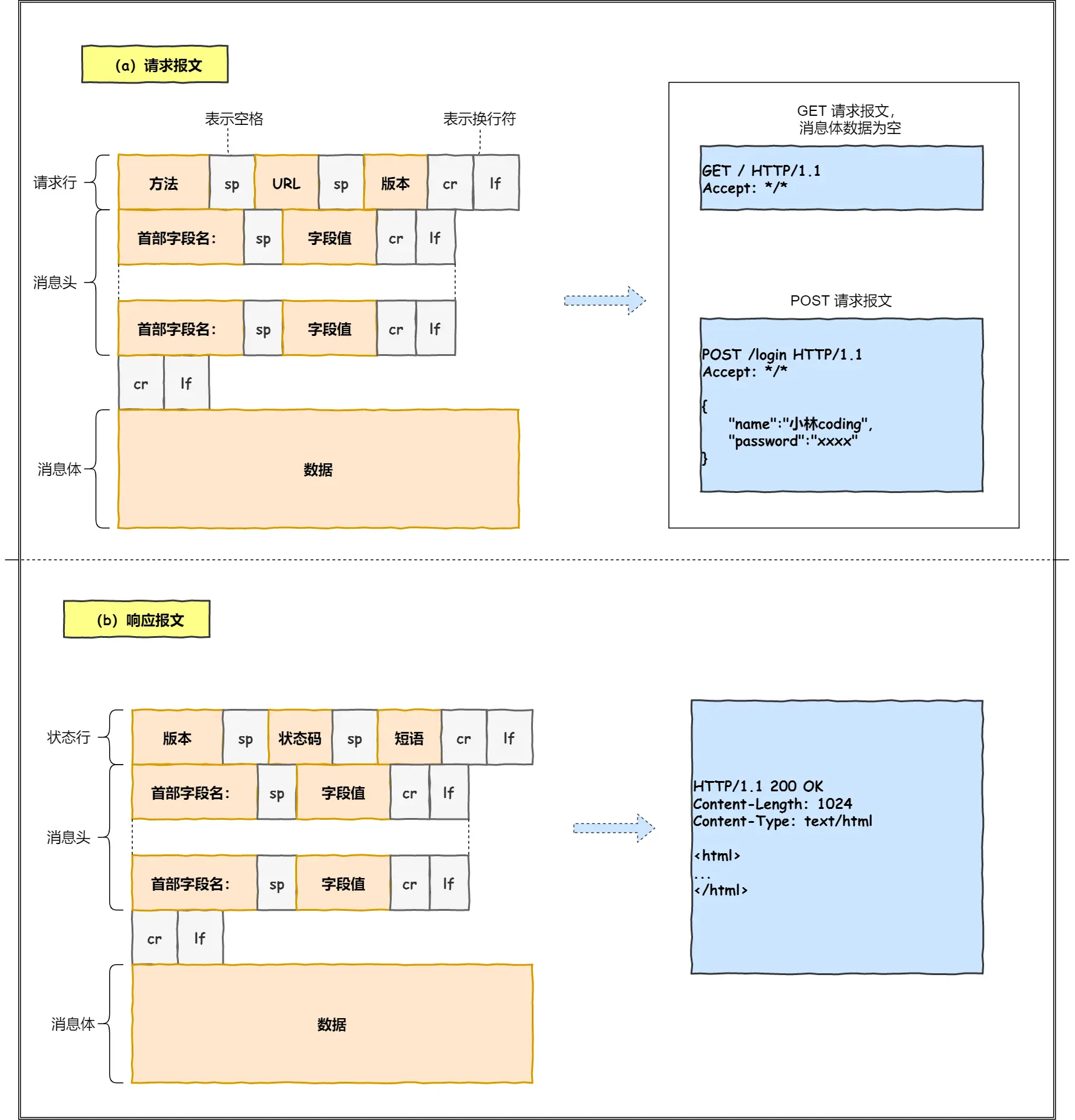
1. 浏览器解析url,产生http请求信息
2. DNS查询服务器域名对应的 IP 地址
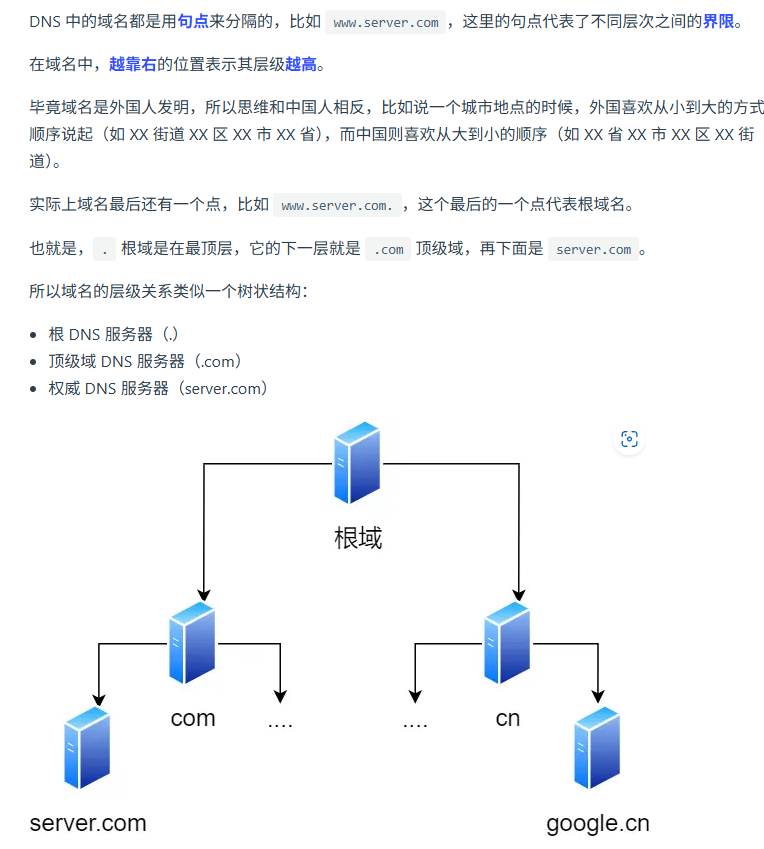
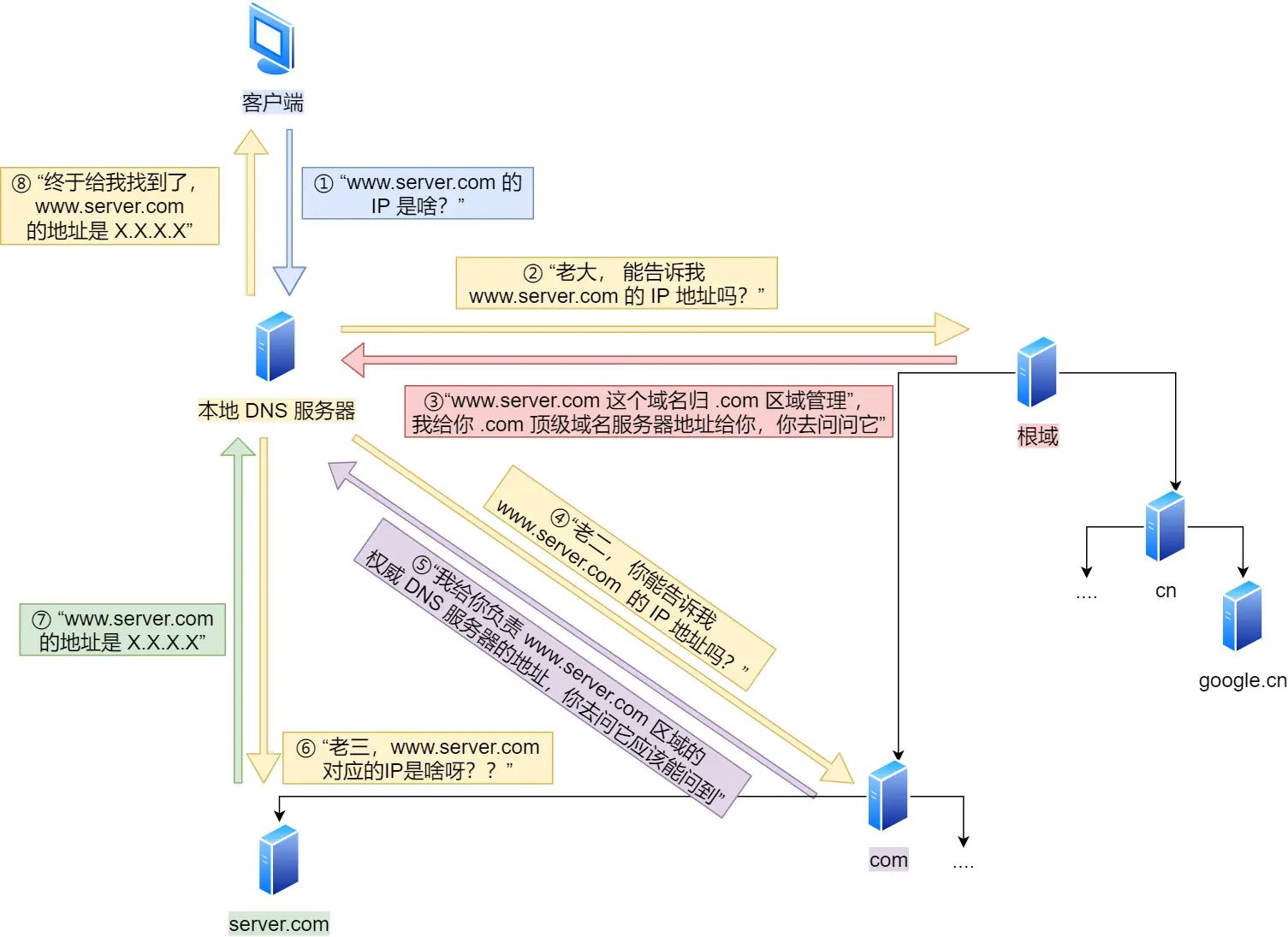
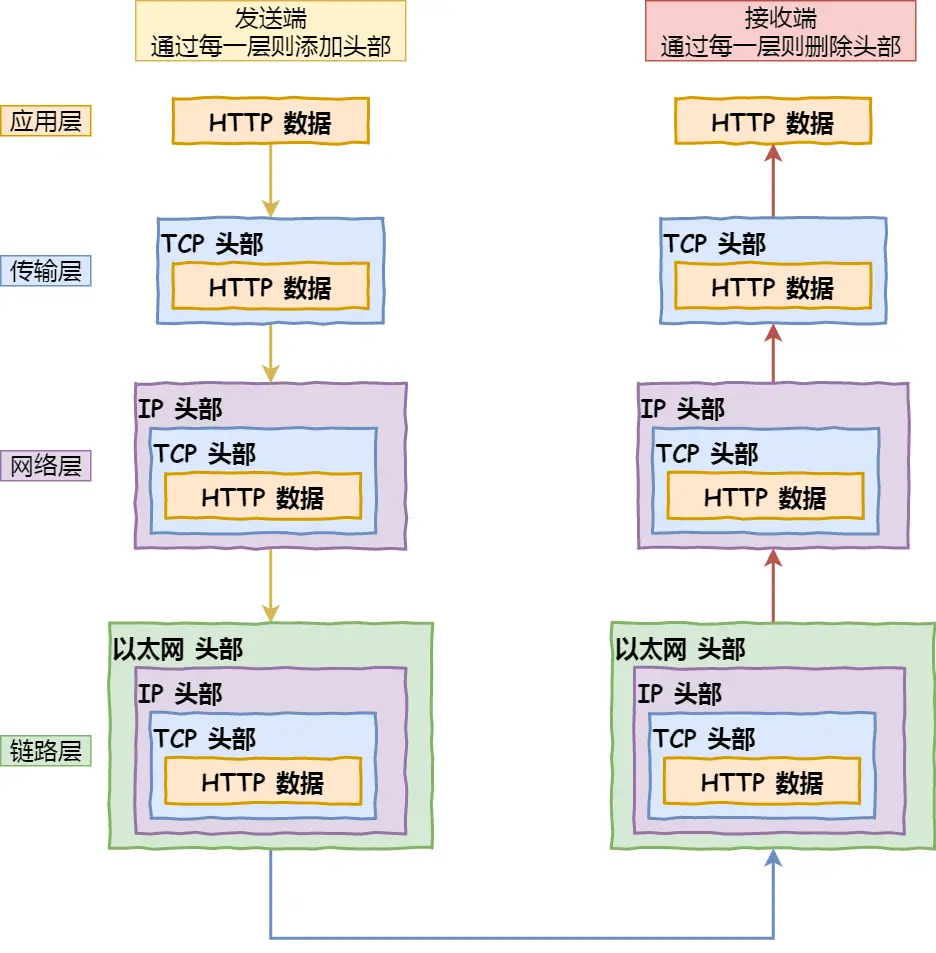
3. 应用程序(浏览器)通过调用Socket库,来委托协议栈工作
协议栈的上半部分有两块,分别是负责收发数据的TCP和UDP协议,这两个传输协议会接受应用层的委托执行收发数据的操作。
协议栈的下面一半是用IP协议控制网络包收发操作,在互联网上传数据时,数据会被切分成一块块的网络包,而将网络包发送给对方的操作就是由IP负责的。

4. 可靠传输TCP(传输层)
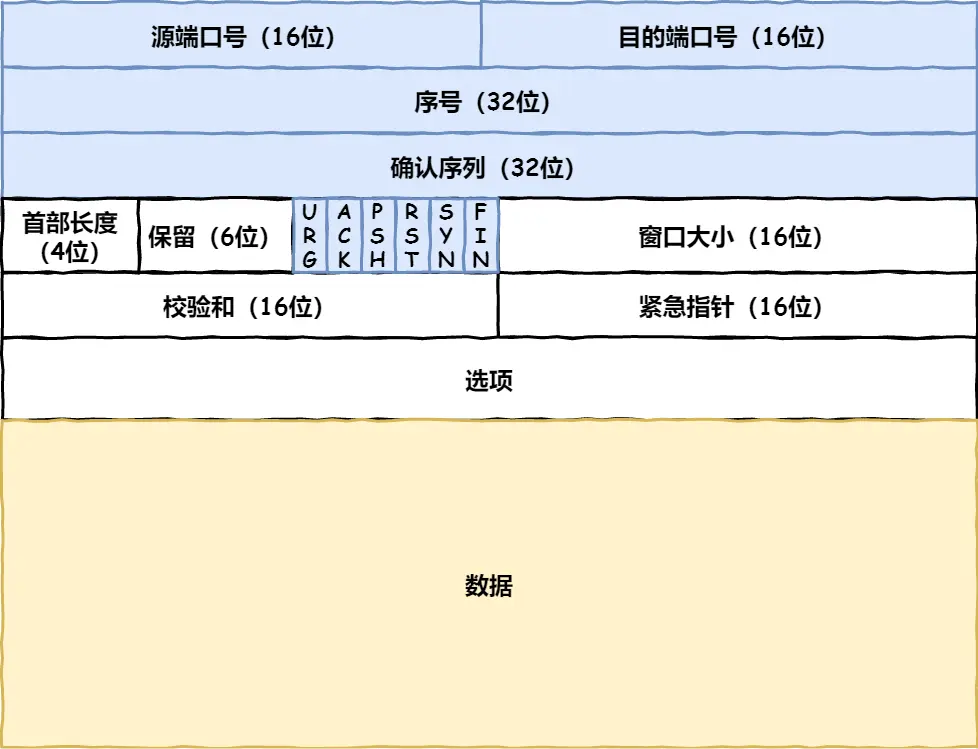
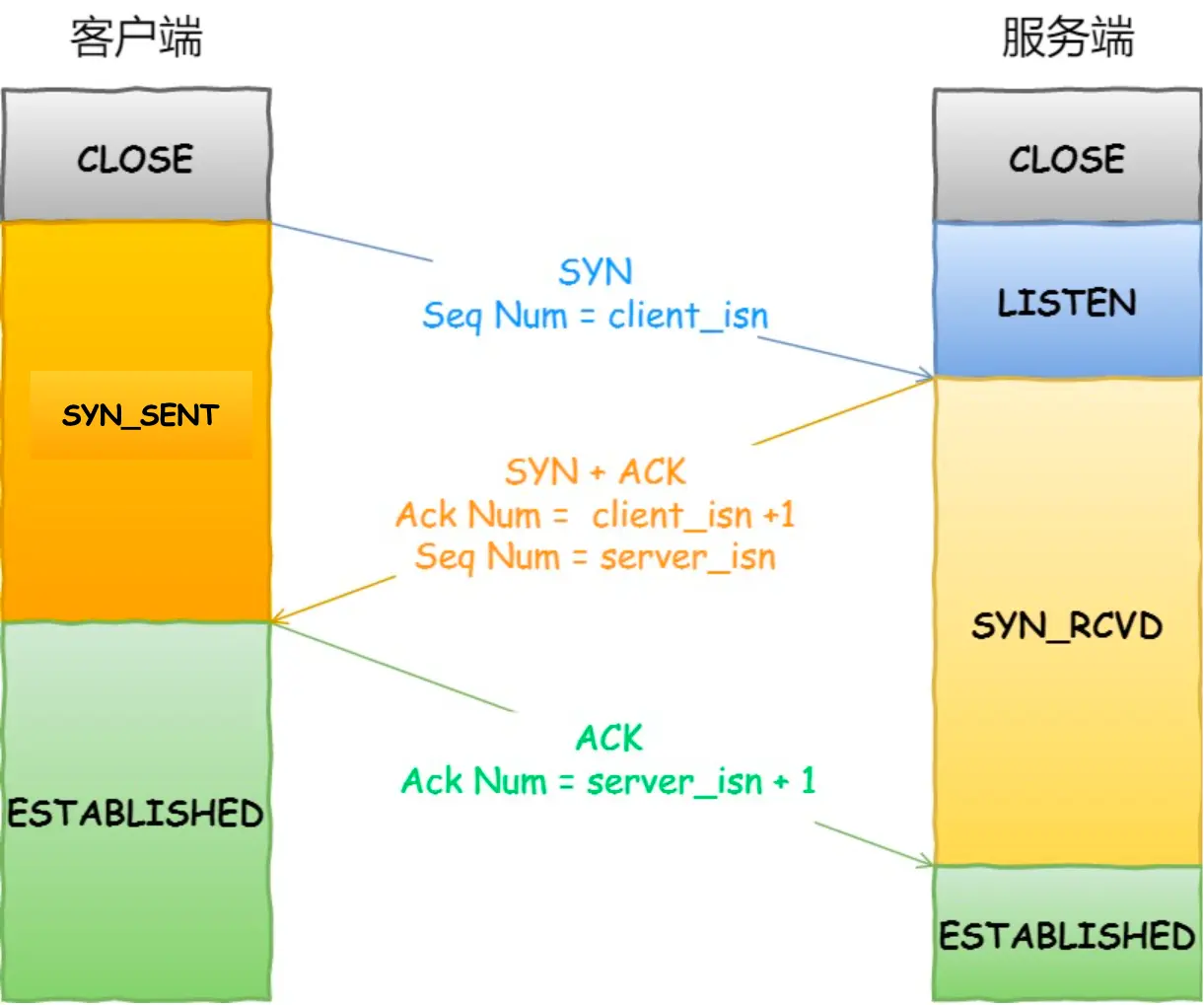
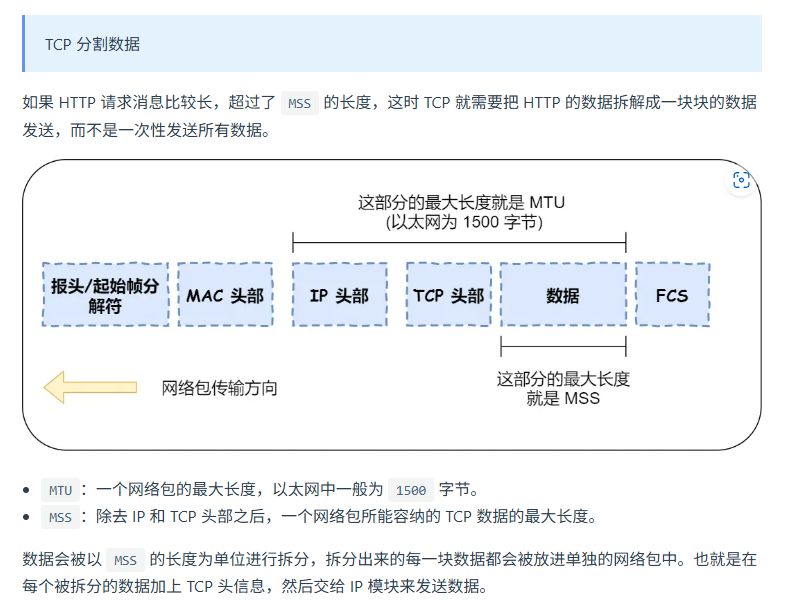 5. 远程定位IP(网络层)
5. 远程定位IP(网络层)
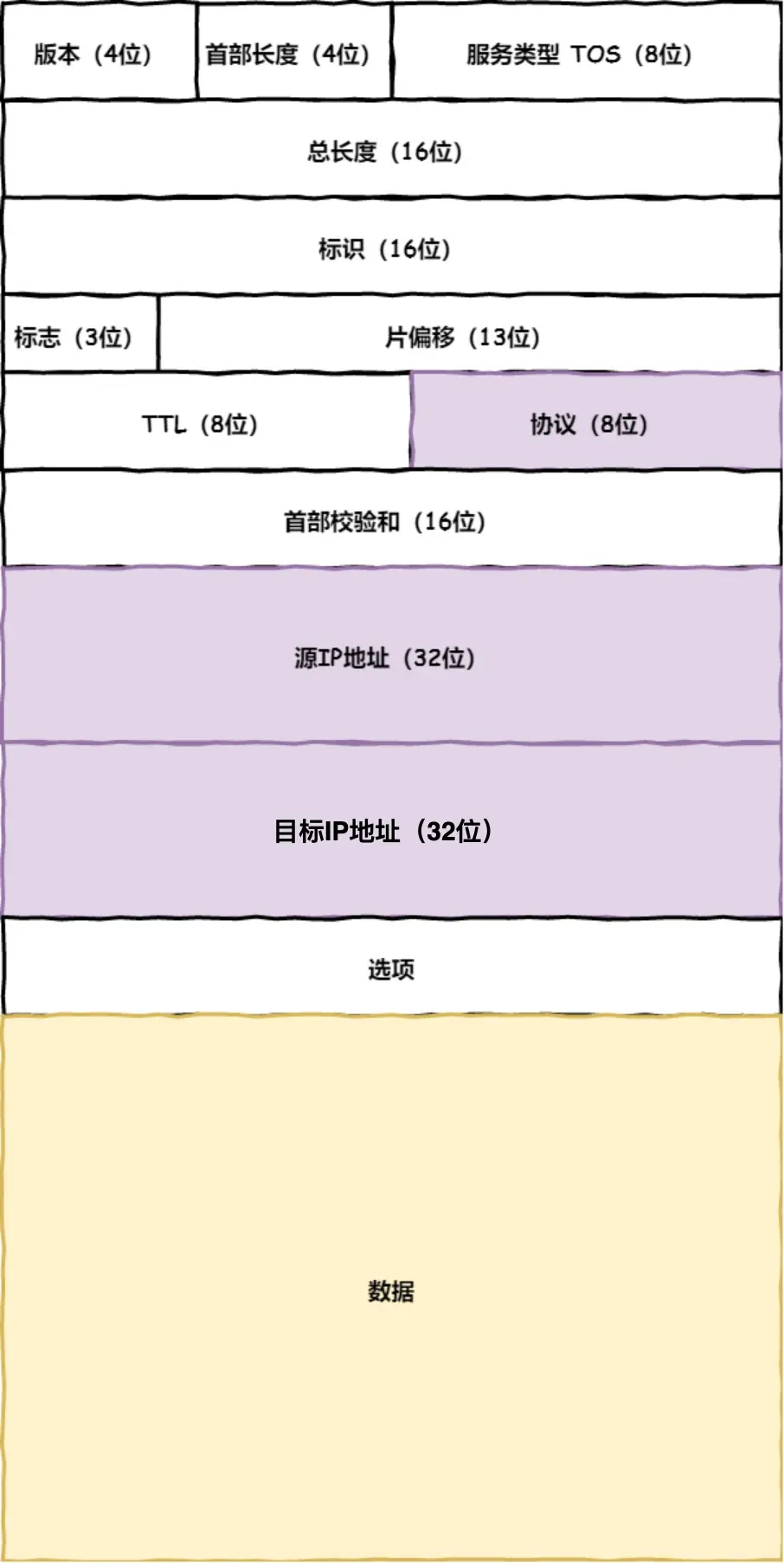
6. 两点传输MAC(数据链路层)
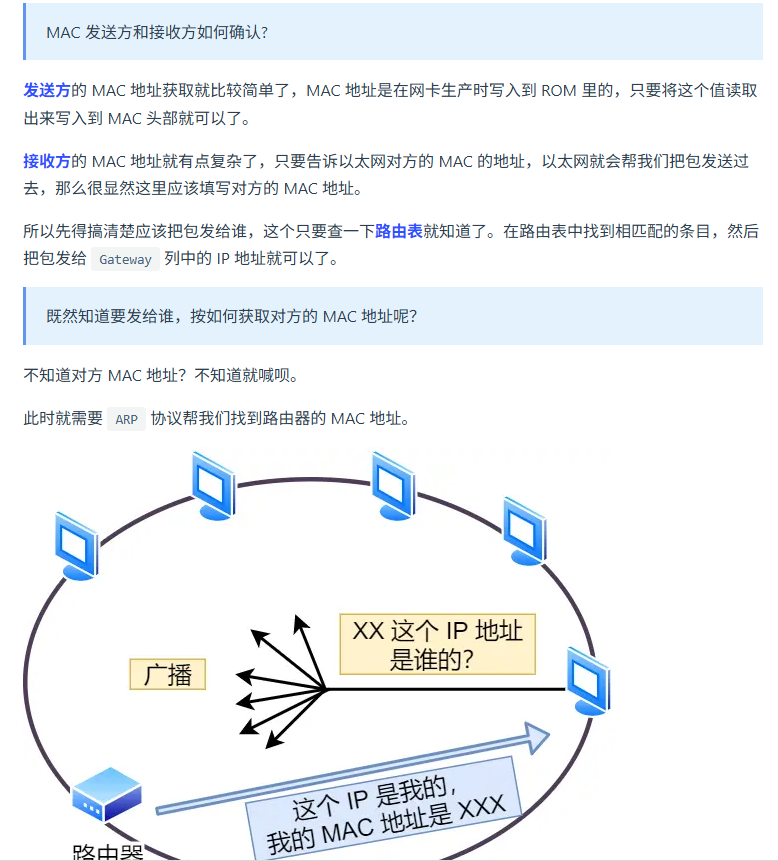
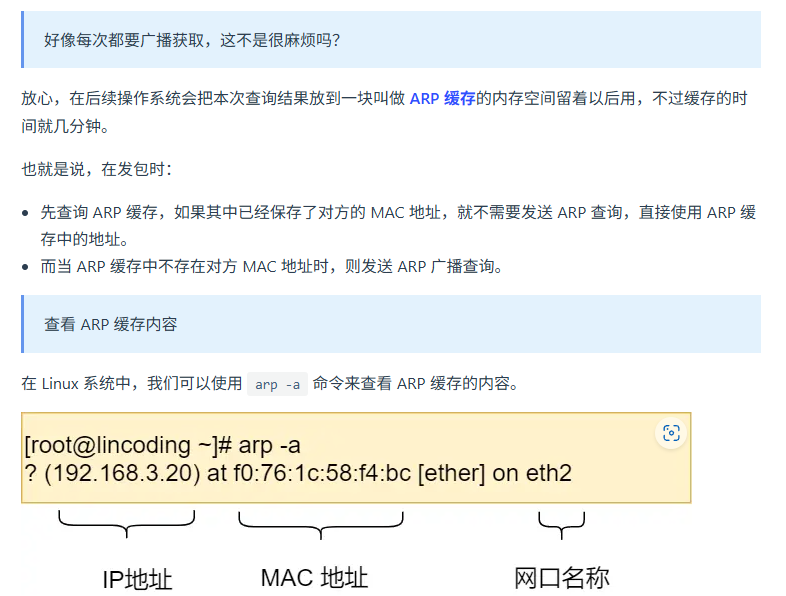
7. 网卡 网线

8. 交换机、路由器
KafKa
参考:https://blog.csdn.net/weixin_45366499/article/details/106943229
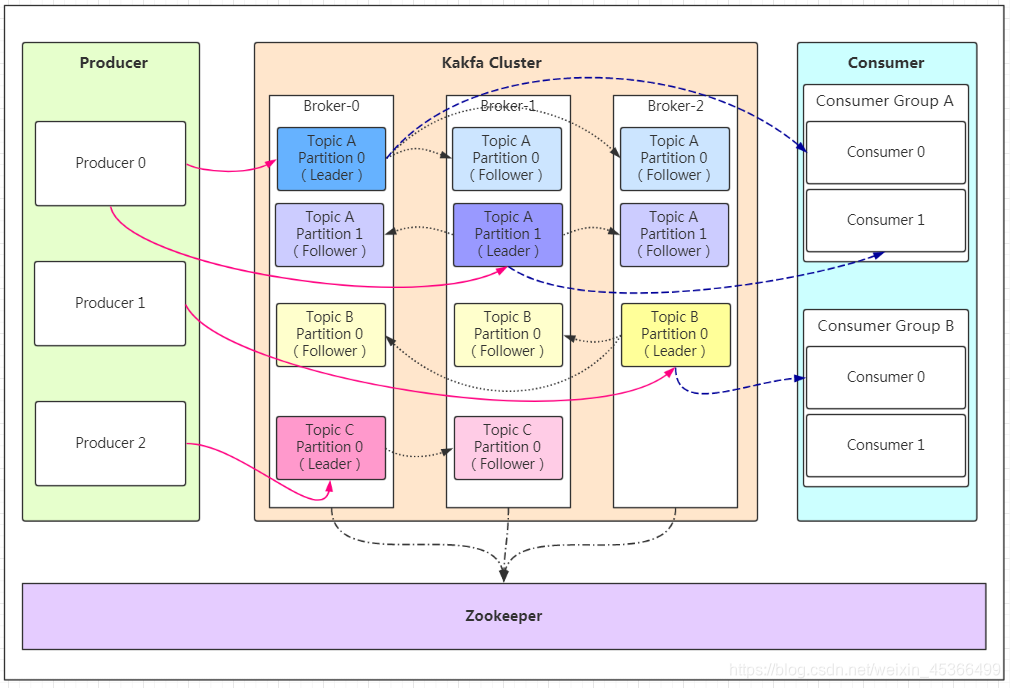
- Producer:Producer即生产者,消息的产生者,是消息的入口。
- Broker:Broker是kafka实例,每个服务器上有一个或多个kafka的实例,我们姑且认为每个broker对应一台服务器。每个kafka集群内的broker都有一个不重复的编号,如图中的broker-0、broker-1等......
- Topic:消息的主题,可以理解为消息的分类,kafka的数据就保存在topic。在每个broker上都可以创建多个topic。
- Partition:Topic的分区,每个topic可以有多个分区,分区的作用是做负载,提高kafka的吞吐量。同一个topic在不同的分区的数据是不重复的,partition的表现形式就是一个一个的文件夹!
- Replication:每一个分区都有多个副本,副本的作用是做备胎。当主分区(Leader)故障的时候会选择一个备胎(Follower)上位,成为Leader。在kafka中默认副本的最大数量是10个,且副本的数量不能大于Broker的数量,follower和leader绝对是在不同的机器,同一机器对同一个分区也只可能存放一个副本(包括自己)。
- Message:每一条发送的消息主体。
- Consumer:消费者,即消息的消费方,是消息的出口。
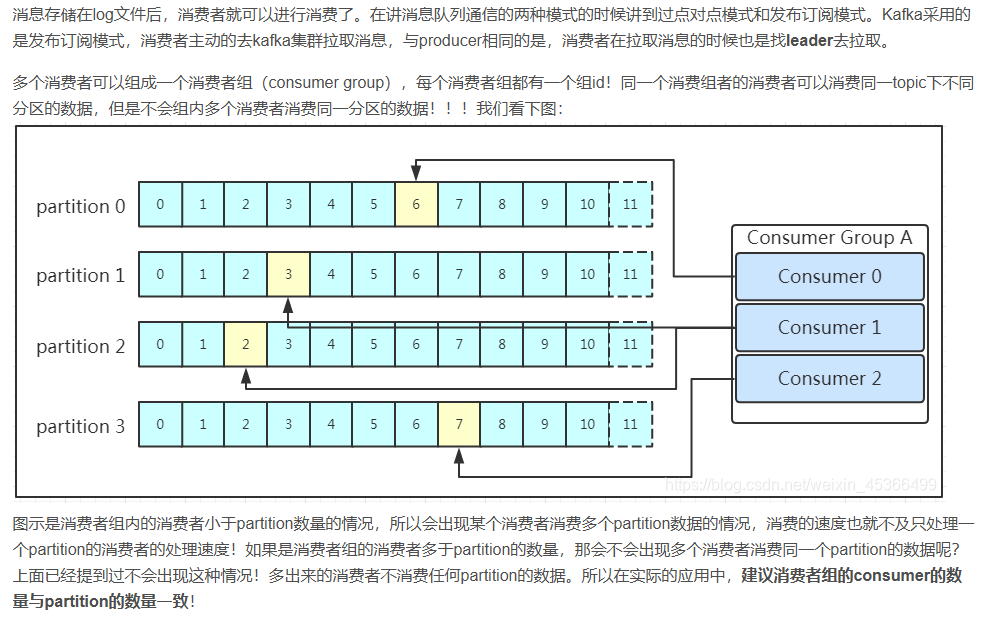
- Consumer Group:我们可以将多个消费组组成一个消费者组,在kafka的设计中同一个分区的数据只能被消费者组中的某一个消费者消费。同一个消费者组的消费者可以消费同一个topic的不同分区的数据,这也是为了提高kafka的吞吐量!
- Zookeeper:kafka集群依赖zookeeper来保存集群的的元信息,来保证系统的可用性。
发送数据
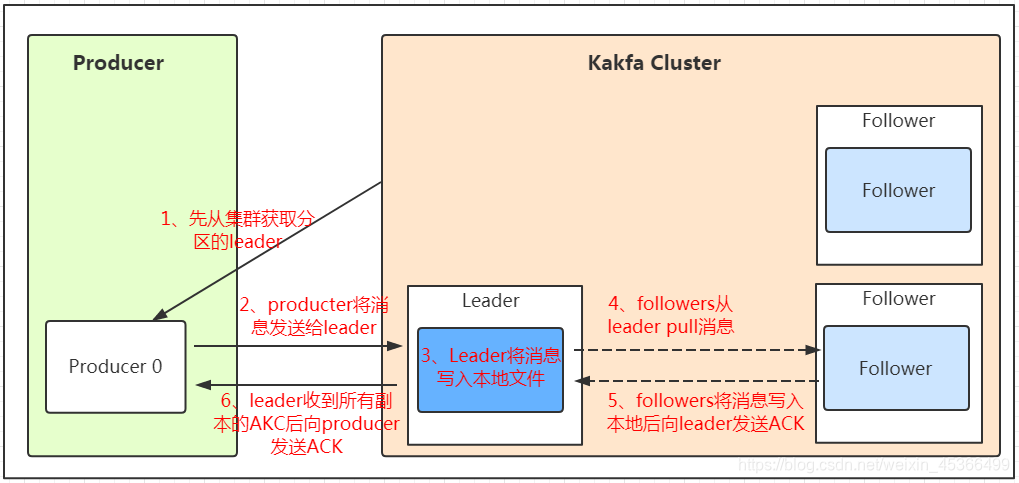
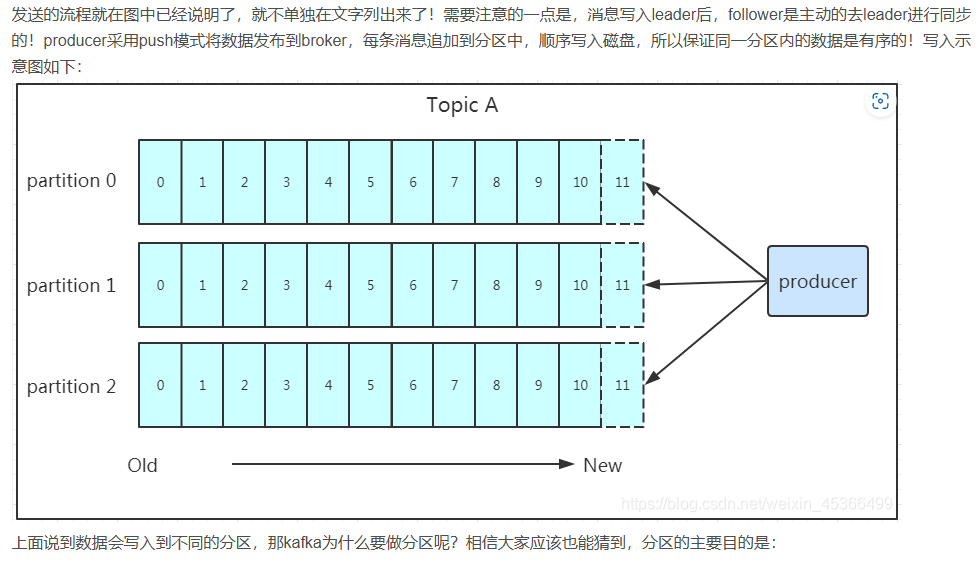

保存数据


消费数据
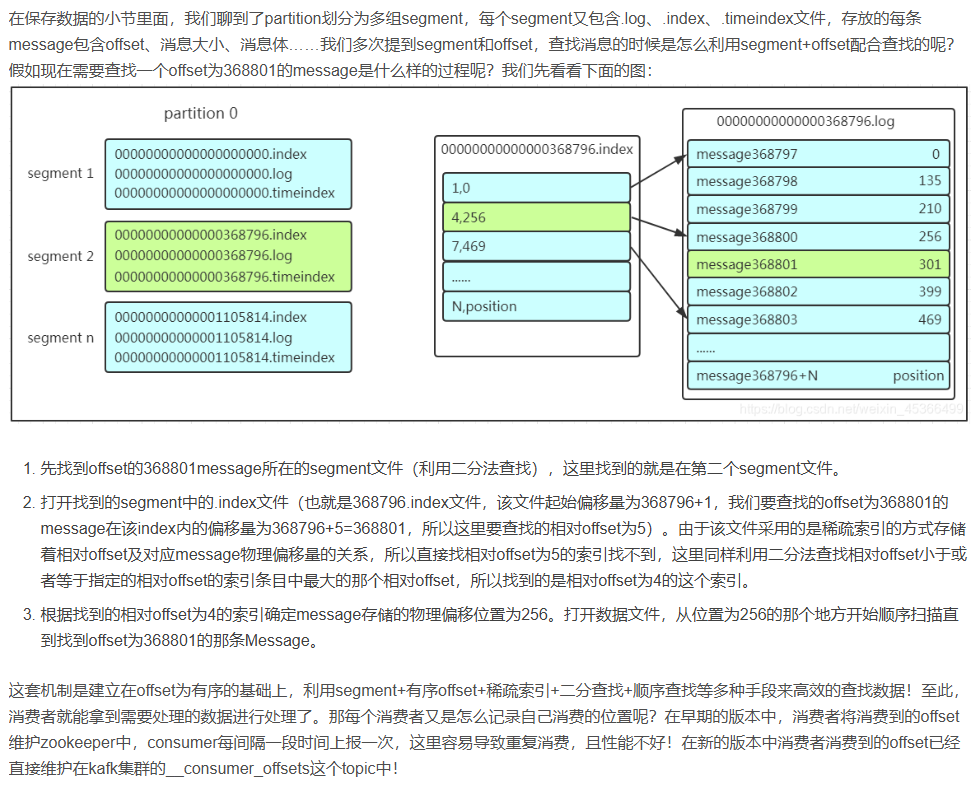


GMP
Go语言的GPM调度模型是Go运行时中用于处理并发的核心机制之一,它将Goroutine(轻量级线程)有效地映射到系统线程上,以最大化并发性能。GPM模型主要由三个部分组成:G(Goroutine)、P(Processor)、M(Machine)。让我们逐一详细介绍:
- G(Goroutine)
Goroutine 是Go语言中用于并发执行的轻量级线程,每个Goroutine都有自己的栈和上下文信息。
Goroutine相对于操作系统的线程更加轻量级,可以在同一时间内运行成千上万的Goroutine。 - P(Processor)
P 是处理Goroutine的调度器的上下文,每个P包含一个本地运行队列(Local Run Queue) ,用于存储需要运行的Goroutine。
P的数量由GOMAXPROCS设置决定,它决定了并行执行的最大线程数。
P不仅管理Goroutine,还负责与M协作,将Goroutine分配给M执行。 - M(Machine)
M 代表操作系统的线程,负责执行Goroutine。一个M一次只能执行一个Goroutine。
M是实际执行代码的工作单元,M与P绑定后才能执行Goroutine。
M可以通过调度器从全局运行队列中拉取新的Goroutine,也可以与其他M协作完成工作。 - GPM模型的调度过程
调度器工作机制:Goroutine创建后会被放入P的本地队列,P会从该队列中选择Goroutine,并将其分配给M执行。如果本地队列为空,P可以从全局运行队列或其他P的队列中窃取任务 。
工作窃取机制:如果一个P的本地队列为空,而另一个P的本地队列中有多个Goroutine,前者可以从后者中窃取任务,从而保持系统的高效利用率。
阻塞与调度**:当M执行的Goroutine阻塞(例如I/O操作)时,M会释放当前的P并等待P重新分配任务,从而避免资源浪费。** - 模型优点
高效的并发调度:GPM模型使得Go语言可以高效地管理数百万个Goroutine的并发执行。
可伸缩性:通过P与M的动态调度,GPM模型可以充分利用多核处理器的性能。
轻量级:Goroutine非常轻量,创建和切换的成本比系统线程要低得多。
P的核心作用
资源隔离与负载均衡
P作为逻辑"处理器",负责管理本地Goroutine队列(runq),使每个OS线程(M)绑定到一个P上工作。这种设计避免了全局队列的锁竞争,同时支持不同P之间通过工作窃取(Work Stealing)动态平衡负载。
多核利用率
P的数量默认等于CPU核心数,确保Goroutine能均匀分配到多个核心上执行。若去掉P,调度器将无法有效利用多核,可能退化为单线程或引发全局锁争用。
- 去掉P的后果
全局锁竞争加剧
所有Goroutine必须通过全局队列调度,多个M(OS线程)会频繁争夺同一把锁,导致并发性能骤降(参考Go 1.0之前的调度器问题)。
调度效率降低
P的本地队列减少了Goroutine的调度延迟。若去掉P,每次调度都需要访问全局队列,增加延迟和不确定性。
阻塞操作的协作困难
当Goroutine因系统调用阻塞时,P会解绑M并创建/复用新的M继续运行其他Goroutine。若无P,阻塞操作可能导致线程长时间挂起,浪费资源。
GC
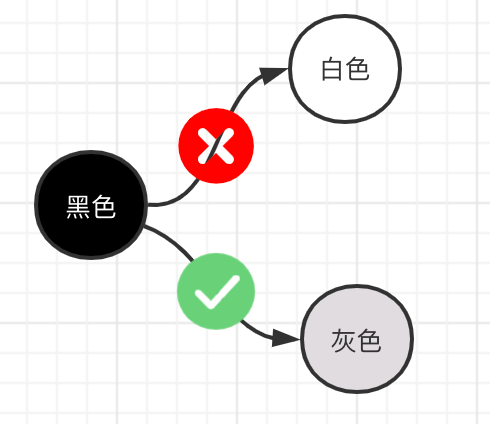
插入写屏障:黑色对象引用的对象变为灰色(栈区不会触发, stw+remark)

删除写屏障:删除的对象如果为白色被标记为灰色(被删除后即使没有别的对象再引用他,也会活到下一轮)
混合写屏障
GC期间,任何在栈上新创建的对象 ,均为黑色。
上面两点只有一个目的,将栈上的可达对象全部标黑,最后无需对栈进行STW,就可以保证栈上的对象不会丢失。有人说,一直是黑色的对象,那么不就永远清除不掉了么,这里强调一下,标记为黑色的是可达对象,不可达的对象一直会是白色,直到最后被回收。
堆上被删除的对象标记为灰色
堆上新添加的对象标记为灰色
k个一组翻转列表
https://leetcode.cn/problems/reverse-nodes-in-k-group/description/
go
/**
* Definition for singly-linked list.
* type ListNode struct {
* Val int
* Next *ListNode
* }
*/
func reverseKGroup(head *ListNode, k int) *ListNode {
if head==nil{
return nil
}
l,r := head, head
root := &ListNode{}
rr := root
num := 0
for r!=nil{
num++
if num%k==0{
tmp := r.Next
r.Next = nil
rr.Next = reverse(l)
rr = l
l,r = tmp, tmp
}else{
r = r.Next
}
}
rr.Next = l
return root.Next
}
func reverse(head *ListNode) *ListNode{
if head==nil || head.Next==nil{
return head
}
l,r := head, head.Next
l.Next = nil
for r!=nil{
tmp := r.Next
r.Next = l
l = r
r = tmp
}
return l
}