TikTok Shop has become an increasingly popular e-commerce platform, providing businesses and marketers with a wealth of data about popular products, customer preferences, and market dynamics. Scraping TikTok product data is extremely valuable for businesses that want to maintain a competitive advantage by analyzing product trends, prices, and user reviews. In this article, we will discuss different ways to scrape popular products on TikTok Shop, and introduce the pros and cons of different methods so that you can choose the right way to scrape TikTok data.
Why Scraping TikTok Products is Valuable
The Importance of Product Data for Market Analysis
Scraping TikTok product data provides unique insights for market analysis, helping businesses understand the latest product trends, customer preferences, and sales performance. By scraping product data from TikTok Shop, you can easily gather key information such as product details, pricing, and promotional strategies, all of which can serve as valuable references for your business decisions. With this data, you can adjust product pricing, identify emerging trends, and develop more precise marketing strategies to ensure your brand stays at the forefront of the market.
Gaining a Competitive Advantage through Data Scraping
In today's highly competitive e-commerce landscape, a TikTok scraper gives you access to market data that your competitors cannot easily obtain. By scraping product data from TikTok, you can track your competitors' pricing strategies, product popularity, and customer feedback. This data enables you to optimize your product offerings and marketing strategies, giving you a competitive edge and allowing you to respond more quickly and effectively than your competitors in the market.
How to Scrape TikTok Product Data Manually
Scraping TikTok product data manually is a great starting point for those who want to extract insights without using advanced tools or coding. While this method isn't scalable for large datasets, it's effective for learning how data is structured on TikTok Shop and collecting small amounts of product information. Here's a step-by-step guide to get started:
1. Use Browser Developer Tools to Identify Product Data
To begin, open TikTok in your browser (preferably Chrome) and navigate to a product listing page on TikTok Shop. Right-click anywhere on the product section (such as product title, price, or rating) and select "Inspect" or press Ctrl + Shift + I (Windows) / Cmd + Option + I (Mac) to open Developer Tools.
-
In the Elements tab, hover over different HTML blocks to find the code corresponding to the product details.
-
Look for HTML tags like
<div>,<span>, or<p>with class names that contain product info (e.g., product-title, price, rating, or description). -
Expand these elements to confirm that they contain the data you need. You can even copy the XPath or CSS Selector of those elements for reference.
This step allows you to visually map out where each piece of data exists within the page, which is essential for both manual copying and building automated scripts in the future.
2. Export the Data Using Extensions or Manual Copying
After locating the necessary product fields (like name, price, ratings, number of orders, etc.), you have two options for exporting the data:
Option A: Copy-Paste into a Spreadsheet
- Simply highlight the text content directly from the page and paste it into a Google Sheet or Excel file.
- Create columns like Product Name, Price, Number of Reviews, etc., and manually fill in each row for different products.
- This works well if you're only analyzing a handful of listings (e.g., 10--20 items).
Option B: Use Browser Extensions
There are browser extensions designed for scraping small amounts of data without needing code. Some popular Chrome extensions include:
- Web Scraper.io
Allows you to create a sitemap of a webpage and define what data to extract using a point-and-click interface.
- Data Miner
Lets you scrape and export table data, or custom-defined fields, directly into CSV/Excel with a visual workflow.
- Scraper
A simpler option that helps extract repeating patterns (e.g., product listings) with XPath.
Once the data is scraped with these tools, you can download the results as a CSV file for further analysis.
3. Understand the Limitations of Manual Scraping
While manual scraping offers simplicity and control, it comes with notable constraints:
- Time-consuming: Manually inspecting pages and copying data becomes inefficient very quickly, especially if you need more than a few dozen entries.
- Error-prone: It's easy to miss a field or make copy-paste mistakes, leading to inconsistent data.
- IP blocking risk: TikTok may detect suspicious activity if you refresh pages rapidly or scrape too frequently. This could temporarily block your access.
- Dynamic content: Some data on TikTok pages is dynamically loaded using JavaScript, which may not be visible in the initial HTML and might require scrolling or user interaction to appear --- making it harder to scrape manually.
In summary, manual scraping using browser tools is an excellent entry point for beginners or for analyzing a small batch of TikTok product listings. But for ongoing or large-scale data needs, it's advisable to consider automated scraping solutions or APIs that can handle the load more efficiently.
TikTok Scraper Python: Developing a Custom Solution
In this section, I will show you how to build a TikTok Scraper with the help of Python.
Step 1: Prerequisites
Before diving into the amazing world of web scraping, let's make sure we have the tools ready!
Execute the following command to make sure you have your Python environment set up. Install Python first if it is not installed.
Copy
python --versionAfter completing the Python environment configuration, we need to install some dependencies required for the local tutorial. You need to run the following command
Copy
pip3 install beautifulsoup4 playwright openpyxlAfter the installation is complete, you can open your Python IDE tool and create a Scraper.py file
Step 2: Start crawling Tiktok product details page data
In this example, we will introduce how to crawl the data of this Tiktok product details page.
We will analyze the HTML structure of this page and extract the following information
- Product title
- Product image
- Product price
- Product rating, number of reviewers and sales volume
- Product review
Get product HTML data
First, we write the following code in the Scraper.py file we created earlier
Copy
In the code above, we use Playwright to get the HTML content of a website and parse it using BeautifulSoup. We first defined the target URL, then used Playwright to open a browser, visit the page, wait for the page to load, retrieve the content, and finally close the browser. We then used BeautifulSoup to parse the HTML and print the page title.
You should see output similar to this:

Extract product title
In the previous step, we successfully obtained the HTML structure of the web page. Now, we will extract the product title data.
To extract the product name from the HTML, we must first find the HTML element corresponding to the product title rendering. We can use the browser's developer tools (press F12), click the arrow icon in the upper left corner of the tool, and then click the product name on the page. The corresponding HTML element will be highlighted.
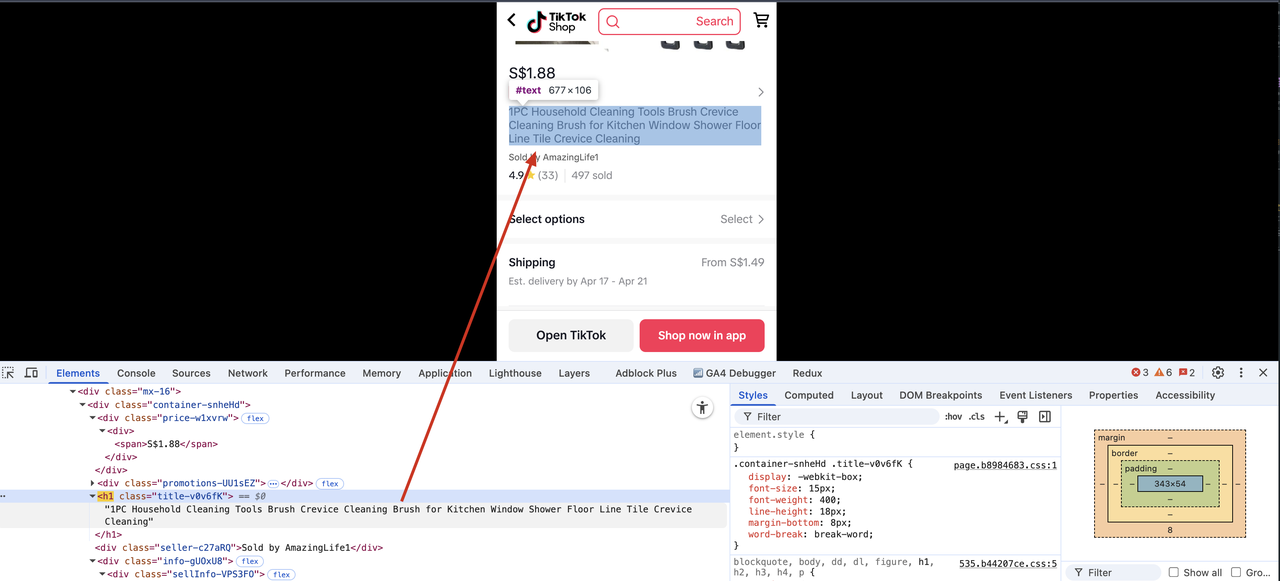
We can see that the product name is in the h1 tag. Use the BeautifulSoup tool to extract the content of the tag. Let's modify the Scraper.py file.
Copy
...
product_title = soup.find("h1", class_=re.compile("title-.*"))
print(product_title.text if product_title else "Product title not found")We will see the following output, confirming that the product title has been successfully extracted.

Extract product images
When we check the rendered tag of the product image, we find that it is located in a div.class=slick-list element, and there are multiple product images. Here we only need to take the first image.
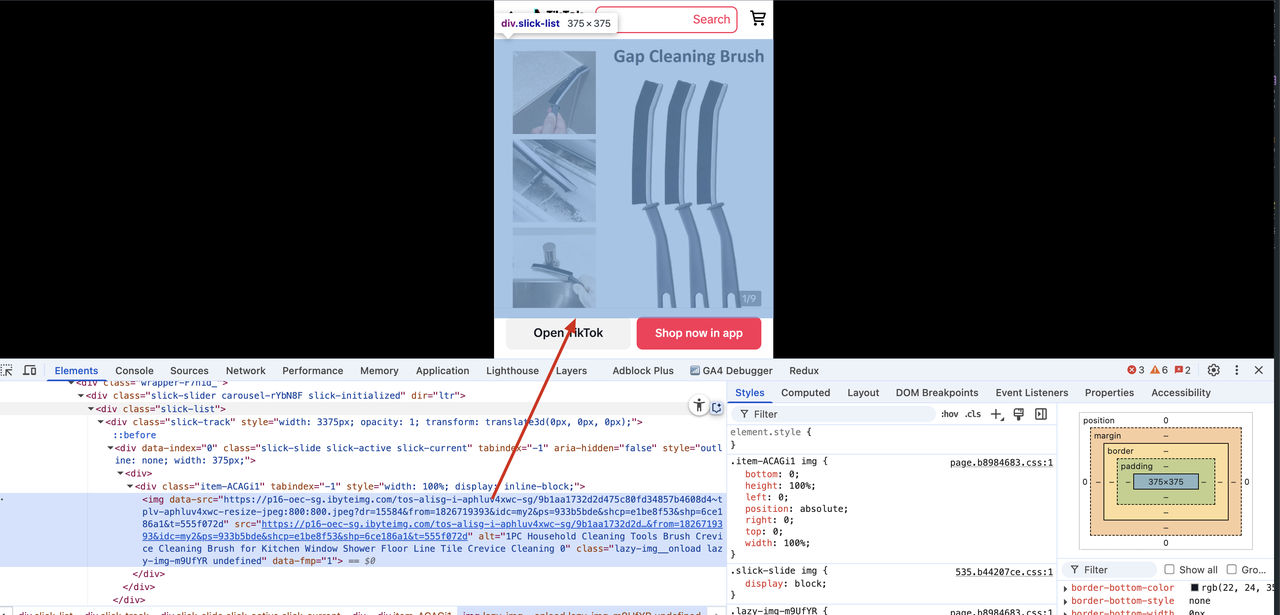
Let's modify the Scraper.py file and add the following code.
Copy
...
price_img_container = soup.find("div", {"class": "slick-list"})
price_img = price_img_container.find("img").get("src")
print(price_img)We will see the following output, indicating that we have successfully extracted product image information.

Extract product price
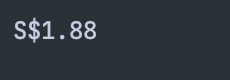
When checking the rendered tag corresponding to the product price, I found that in a div, the class name is price+hash
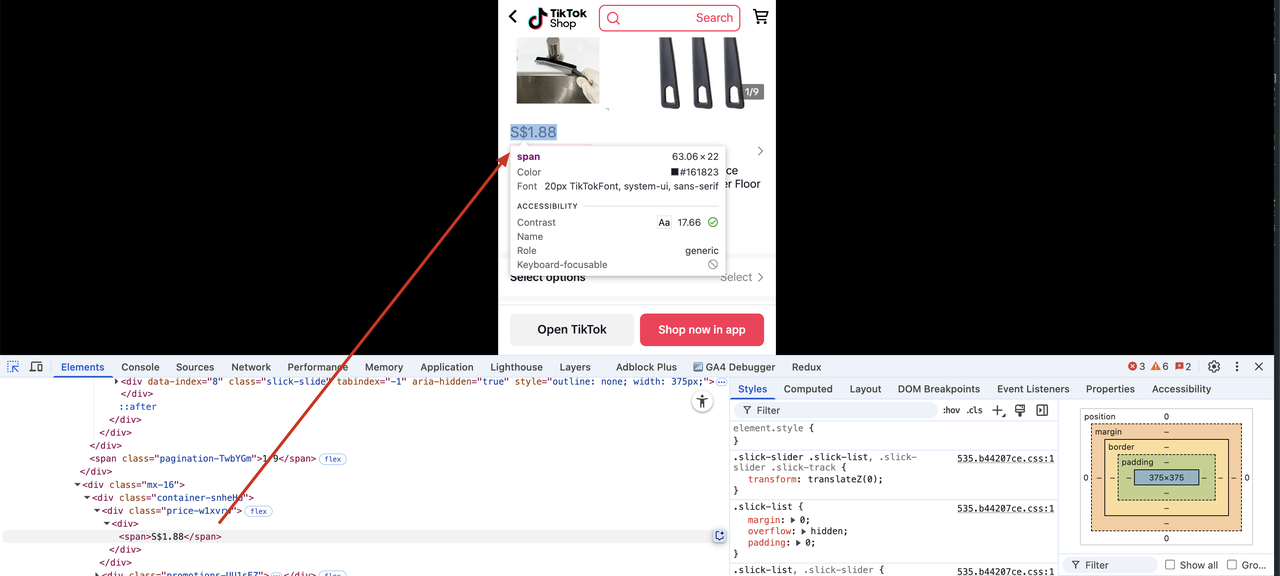
Let's modify the Scraper.py file and add the following code:
Copy
...
price_container = soup.find("div", class_=re.compile("price-.*"))
price = price_container.find("span").text
print(price if price else "Price not found")We will see the following output, indicating that we have successfully extracted the champ price information.
Extract product ratings, number of reviewers, and sales volume
By analyzing the HTML structure rendered corresponding to product rating information and sales volume, we can adjust it according to the processing method of extracting product price codes.
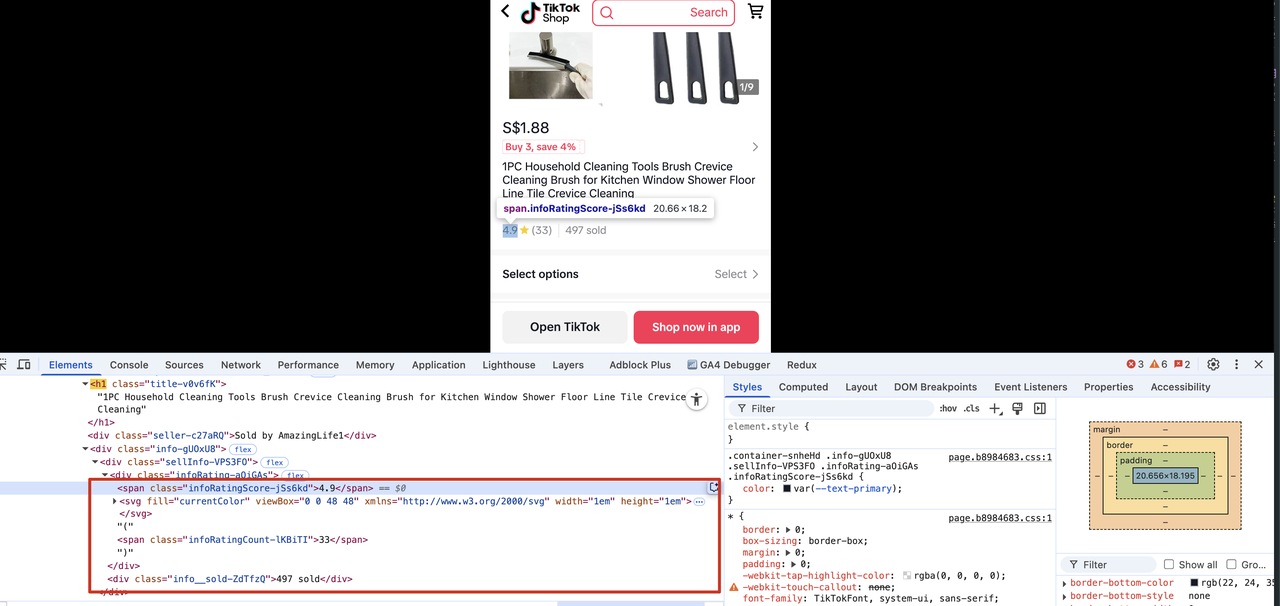
Let's modify the Scraper.py file and add the following code:
Copy
...
sell_info_container = soup.find("div", class_=re.compile("sellInfo-.*"))
rating_score = sell_info_container.find("span", class_=re.compile("infoRatingScore-.*")).text
rating_score_count = sell_info_container.find("span", class_=re.compile("infoRatingCount-.*")).text
sell_sold_count_text = sell_info_container.find("div", class_=re.compile("info__sold-.*")).text
sell_sold_count = re.search(r"\d+", sell_sold_count_text).group()
print(rating_score if rating_score else "Rating score not found")
print(rating_score_count if rating_score_count else "Rating score count not found")
print(sell_sold_count if sell_sold_count else "Sell sold count not found")We will see the following output, indicating that we have successfully extracted the product rating, number of reviewers, and sales quantity:

Extract product review information
By analyzing the HTML structure rendered by the product review information, it is found that the content is located in the element of div.class=reviews__hash
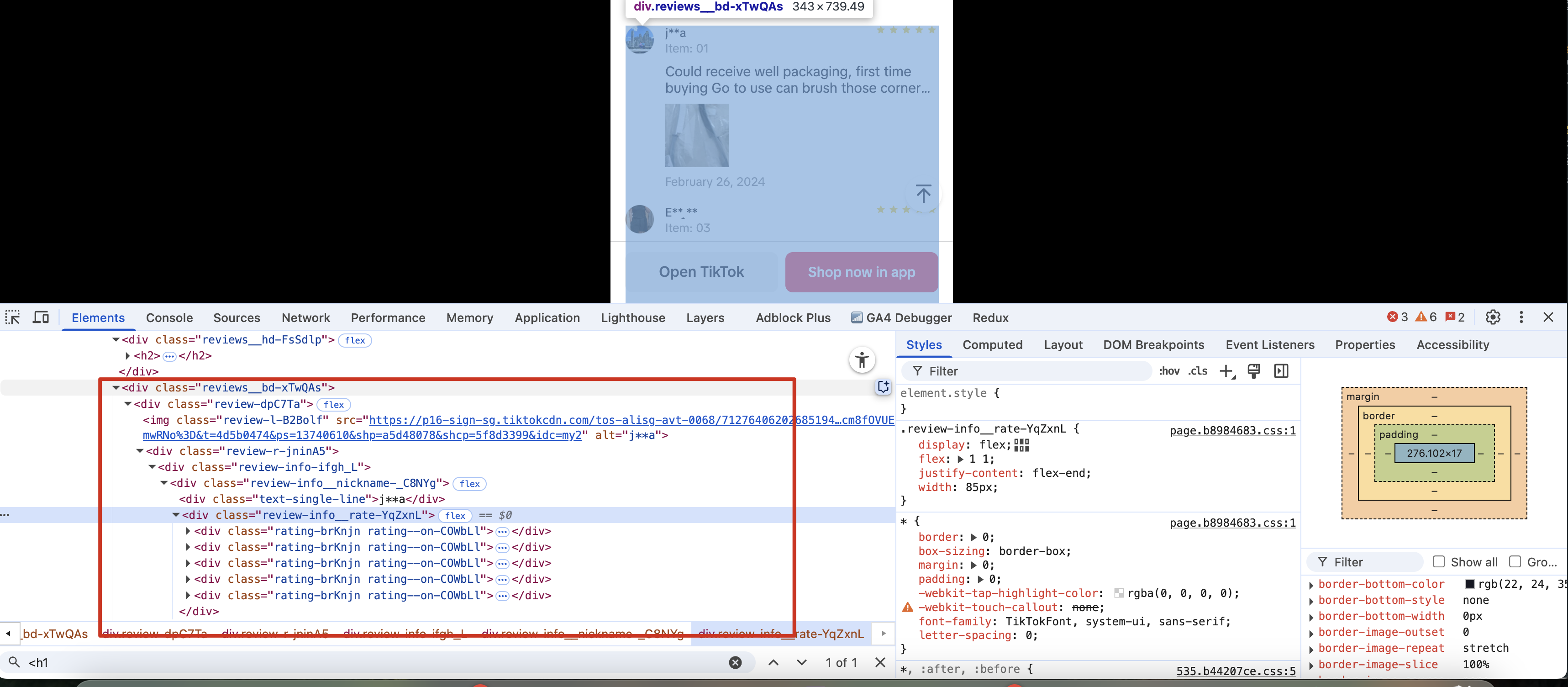
Next, let's modify the Scraper.py file and add the following code:
Copy
..
reviews_container = soup.find("div", class_=re.compile("reviews__bd-.*"))
reviews = []
if reviews_container:
reviews_list = reviews_container.find_all(recursive=False)
for review in reviews_list:
review_person_nick_name = review.find("div", {"class": "text-single-line"}).text
review_star_count = len(review.find_all("div", class_=re.compile("rating--on-.*")))
review_content = review.find("div", class_=re.compile("review-content-.*")).find("div").text
review_date = review.find("div", class_=re.compile("reviewSku-.*")).text
reviews.append({
"Nick Name": review_person_nick_name,
"Star Count": review_star_count,
"Content": review_content,
"Date": review_date
})
print(reviews if reviews else "Reviews not found")We will see the following information:

Step 3: Export data
Here we will export the obtained data into product basic data and comment data; let's modify the Scraper.py file and add the following export code:
Copy
...
# export the data to a CSV file
# create a new workbook
wb = Workbook()
# write the first sheet: product info data
product_sheet = wb.active
product_sheet.title = "Product Info"
product_sheet.append(["Page Title", "Product Title", "Price Img", "Price", "Rating Score", "Rating Score Count", "Sell Sold Count"])
product_sheet.append([
page_title,
product_title.text if product_title else "Product title not found",
price_img,
price,
rating_score,
rating_score_count,
sell_sold_count
])
# write the second sheet: reviews data
reviews_sheet = wb.create_sheet(title="Reviews")
reviews_sheet.append(["Nick Name", "Star Count", "Content", "Date"])
for review in reviews:
reviews_sheet.append([
review["Nick Name"],
review["Star Count"],
review["Content"],
review["Date"]
])
# save the workbook
wb.save("tiktok_product_data.xlsx")You will end up seeing data like this:
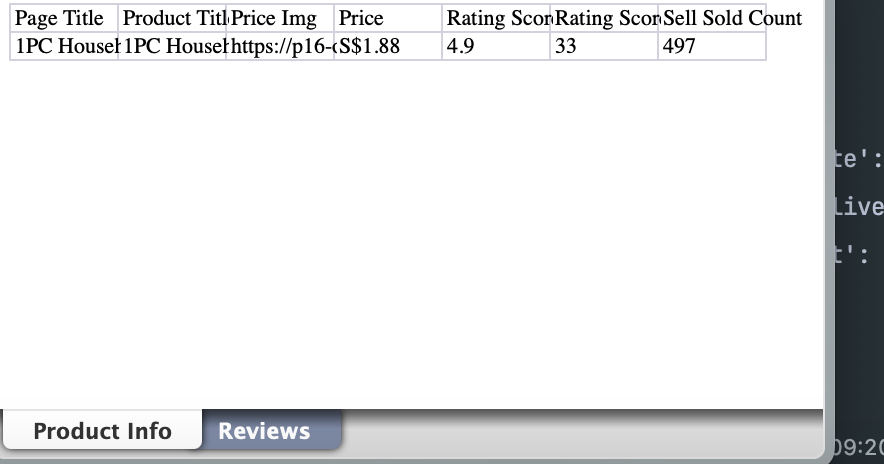
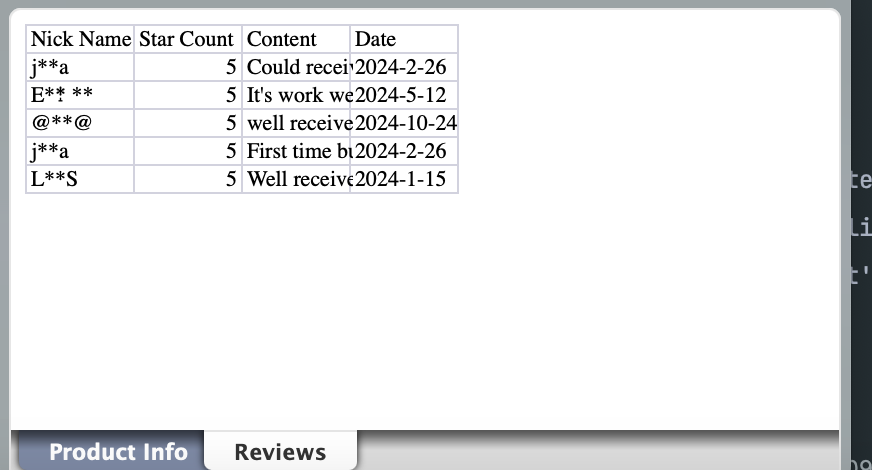
The complete code is as follows:
Copy
from playwright.sync_api import sync_playwright
from bs4 import BeautifulSoup
import re
from openpyxl import Workbook
# define target website url
url = "https://www.tiktok.com/view/product/1729515492411803046"
# use playwright to scrape the website
with sync_playwright() as p:
# launch the browser
browser = p.chromium.launch(headless=False)
# create a new page
page = browser.new_page()
# navigate to the target website
page.goto(url)
# wait for the page to load
page.wait_for_load_state("load")
# sleep for 5 seconds to ensure all content is loaded
page.wait_for_timeout(3000)
# scroll down to load more content
page.evaluate("window.scrollTo(0, document.body.scrollHeight)")
# close the browser
# get the page content
html = page.content()
browser.close()
soup = BeautifulSoup(html, "html.parser")
page_title = soup.find("title").text
print(page_title)
product_title = soup.find("h1", class_=re.compile("title-.*"))
print(product_title.text if product_title else "Product title not found")
price_img_container = soup.find("div", {"class": "slick-list"})
price_img = price_img_container.find("img").get("src")
print(price_img)
price_container = soup.find("div", class_=re.compile("price-.*"))
price = price_container.find("span").text
print(price if price else "Price not found")
sell_info_container = soup.find("div", class_=re.compile("sellInfo-.*"))
rating_score = sell_info_container.find("span", class_=re.compile("infoRatingScore-.*")).text
rating_score_count = sell_info_container.find("span", class_=re.compile("infoRatingCount-.*")).text
sell_sold_count_text = sell_info_container.find("div", class_=re.compile("info__sold-.*")).text
sell_sold_count = re.search(r"\d+", sell_sold_count_text).group()
print(rating_score if rating_score else "Rating score not found")
print(rating_score_count if rating_score_count else "Rating score count not found")
print(sell_sold_count if sell_sold_count else "Sell sold count not found")
reviews_container = soup.find("div", class_=re.compile("reviews__bd-.*"))
reviews = []
if reviews_container:
reviews_list = reviews_container.find_all(recursive=False)
for review in reviews_list:
review_person_nick_name = review.find("div", {"class": "text-single-line"}).text
review_star_count = len(review.find_all("div", class_=re.compile("rating--on-.*")))
review_content = review.find("div", class_=re.compile("review-content-.*")).find("div").text
review_date = review.find("div", class_=re.compile("reviewSku-.*")).text
reviews.append({
"Nick Name": review_person_nick_name,
"Star Count": review_star_count,
"Content": review_content,
"Date": review_date
})
print(reviews if reviews else "Reviews not found")
# export the data to a CSV file
# create a new workbook
wb = Workbook()
# write the first sheet: product info data
product_sheet = wb.active
product_sheet.title = "Product Info"
product_sheet.append(["Page Title", "Product Title", "Price Img", "Price", "Rating Score", "Rating Score Count", "Sell Sold Count"])
product_sheet.append([
page_title,
product_title.text if product_title else "Product title not found",
price_img,
price,
rating_score,
rating_score_count,
sell_sold_count
])
# write the second sheet: reviews data
reviews_sheet = wb.create_sheet(title="Reviews")
reviews_sheet.append(["Nick Name", "Star Count", "Content", "Date"])
for review in reviews:
reviews_sheet.append([
review["Nick Name"],
review["Star Count"],
review["Content"],
review["Date"]
])
# save the workbook
wb.save("tiktok_product_data.xlsx")Use Scrapeless to scrape TikTok shop product information without code
Scrapeless offers a powerful no-code solution for extracting TikTok Shop product data with precision and ease. Instead of relying on complex scripts or unstable browser extensions, you can leverage Scrapeless's prebuilt scraping modules to target TikTok Shop from multiple entry points:
- 🔍
scraper.tiktok.mobile.shop.keywords-- Looking for trending products or niche ideas? This scraper lets you fetch product listings based on keyword search in TikTok Shop. Simply enter a keyword (like "LED makeup mirror") and Scrapeless will return a structured list of matching products, including titles, prices, thumbnails, and store links. - 🏪
scraper.tiktok.mobile.shop.homepage-- Want to monitor a specific TikTok seller's full catalog? Use this scraper to extract all product listings from a store's homepage. It's ideal for tracking competitor offerings or analyzing a brand's full product lineup. - 📄
scraper.tiktok.mobile.shop.detail-- Need in-depth information about a single product? This module digs into the product detail page to extract rich data including price history, seller info, rating, review counts, and more.
With Scrapeless, everything runs in the cloud --- no code, no setup, no headache. You just input your parameters, hit "Run," and receive clean, structured data in your preferred format (CSV, Excel, or JSON).
Step-by-Step Tutorial: Scrape TikTok Shop in Minutes
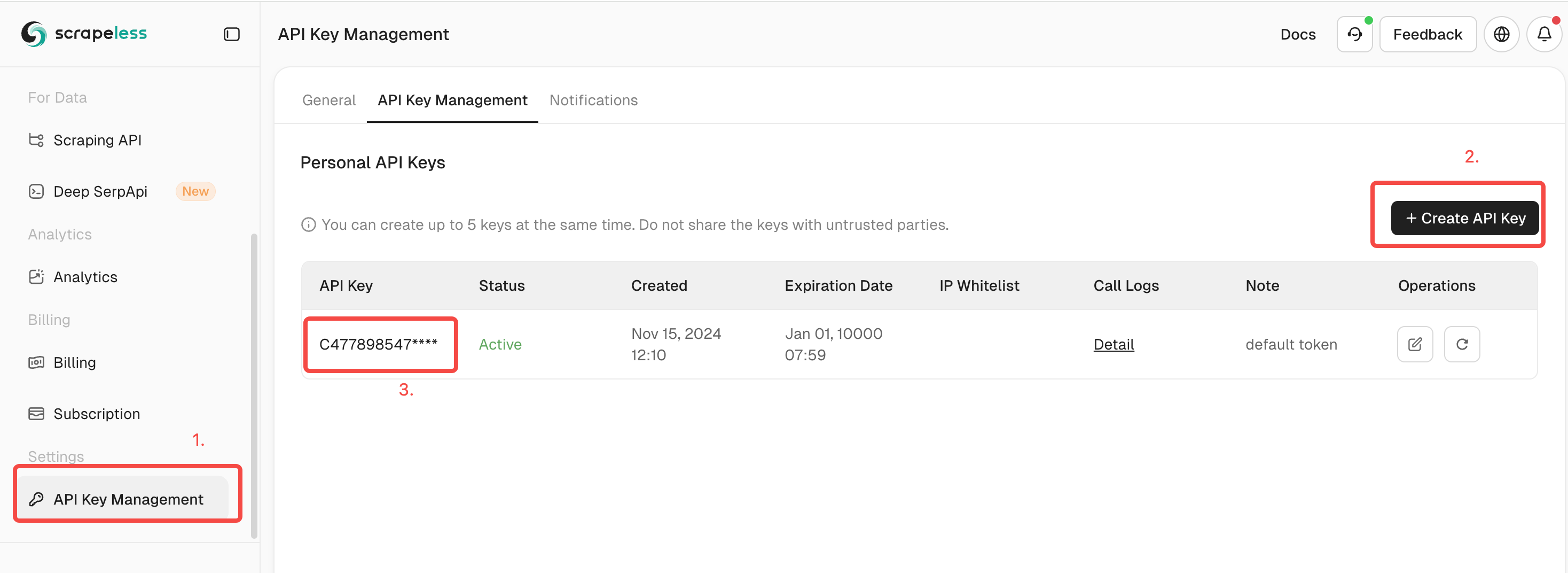
Step 1: Register and get API access
Click here to log in to Scrapeless. After registering an account, you can automatically obtain a unique API Token for identity authentication.
Step 2: Prepare the scraping request
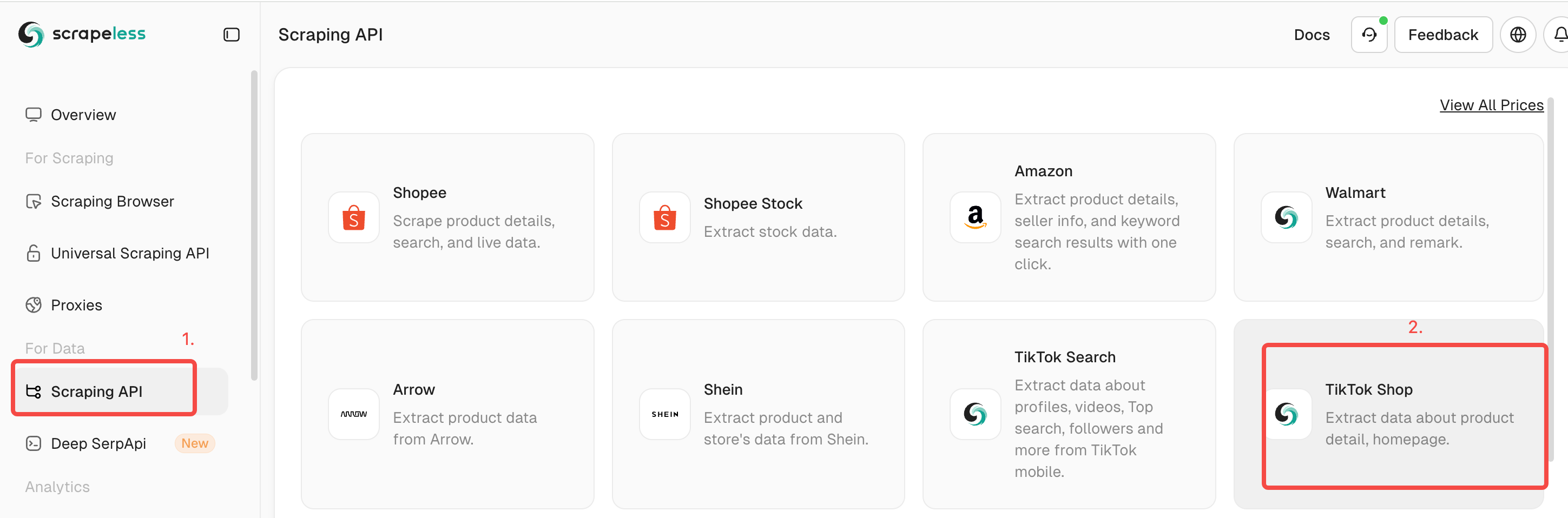
Click Scraping API > Select TikTok Shop > Enter the interface shown below.(Here we use keyword query as an example)
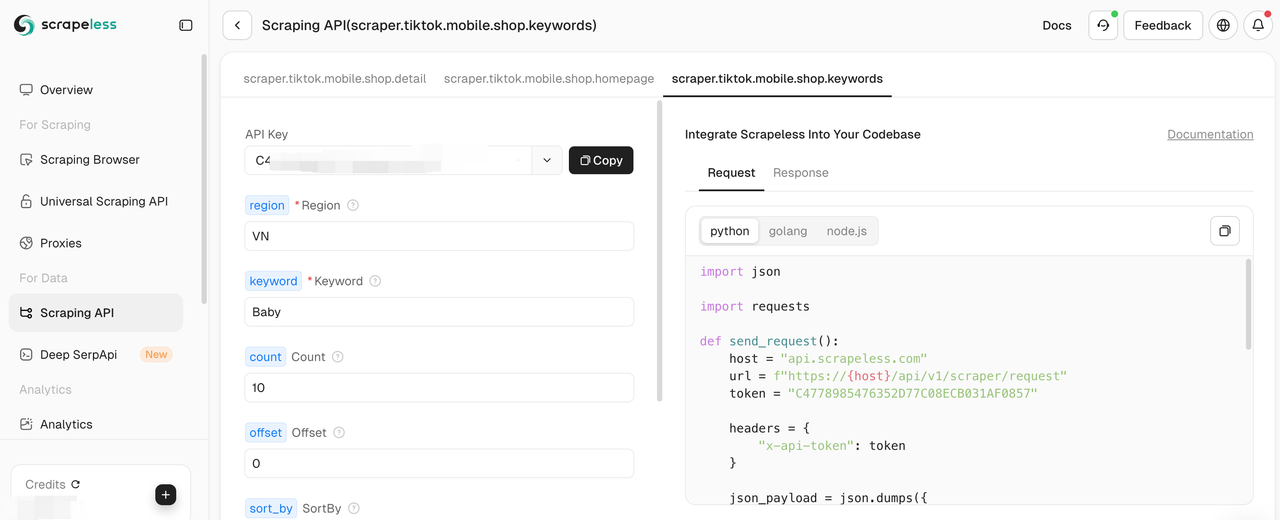
Step 3: Fill in the corresponding crawling information
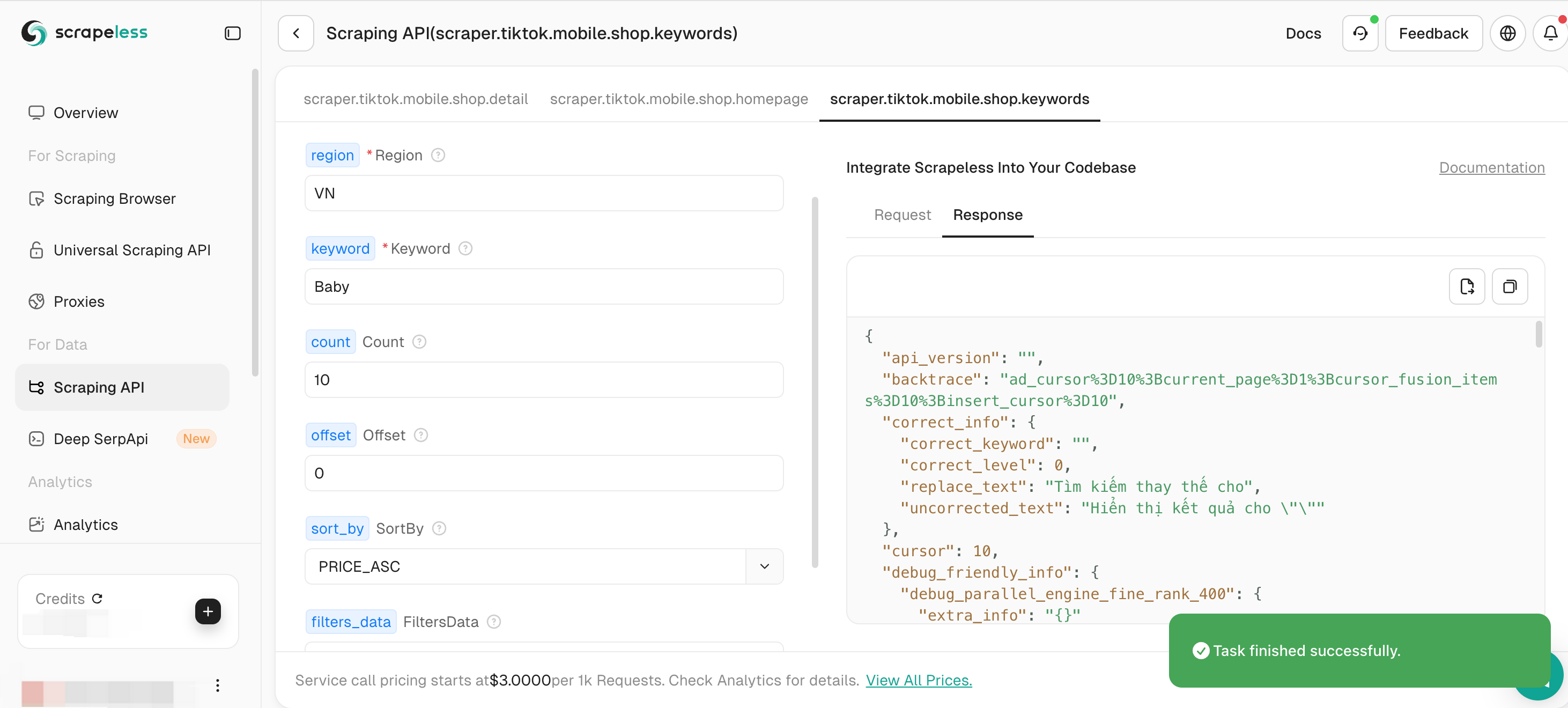
Step 4: Click Start Scraping to start data scraping. It only takes a few seconds to output the scraping results on the right.
- Or you can deploy our API to your own project like:
Copy
import json
import requests
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "your scrapeless api key"
headers = {
"x-api-token": token
}
json_payload = json.dumps({
"actor": "scraper.tiktok.mobile.shop.keywords",
"input": {
"region": "VN",
"keyword": "Baby",
"count": "10",
"offset": "0",
"sort_by": "PRICE_ASC",
"filters_data": ""
}
})
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()This approach is perfect for:
- eCommerce Sellers analyzing competitor pricing and bestsellers
- Dropshippers discovering viral products
- Marketers identifying influencer-based product trends
- Analysts building real-time product research dashboards
So if you're tired of fragile scripts or limited browser extensions, Scrapeless gives you the control and scale you need to scrape TikTok product data --- completely code-free.
🚀 Start Scraping TikTok Shop Data with Scrapeless Today!
Why waste hours copying and pasting when you can automate everything in just a few clicks? Whether you're a product researcher, seller, or data analyst, Scrapeless empowers you to collect TikTok Shop product data at scale --- without writing a single line of code.
✅ No setup required
✅ Works 24/7 in the cloud
✅ Export to CSV, Excel, JSON --- whatever fits your workflow
✅ Built-in anti-blocking, proxy handling, and smart detection
👉 Try Scrapeless for Free Now --- and get your first TikTok Shop dataset in less than 3 minutes.
Still not sure? Explore our TikTok Scraping Guide or chat with our team --- we're here to help you scale your product intelligence the easy way.
Additional Tips: How to Bypass TikTok's bot detection
Step 1. Sign in Scrapeless.
Step 2. Click the "Proxies", and create a channel.
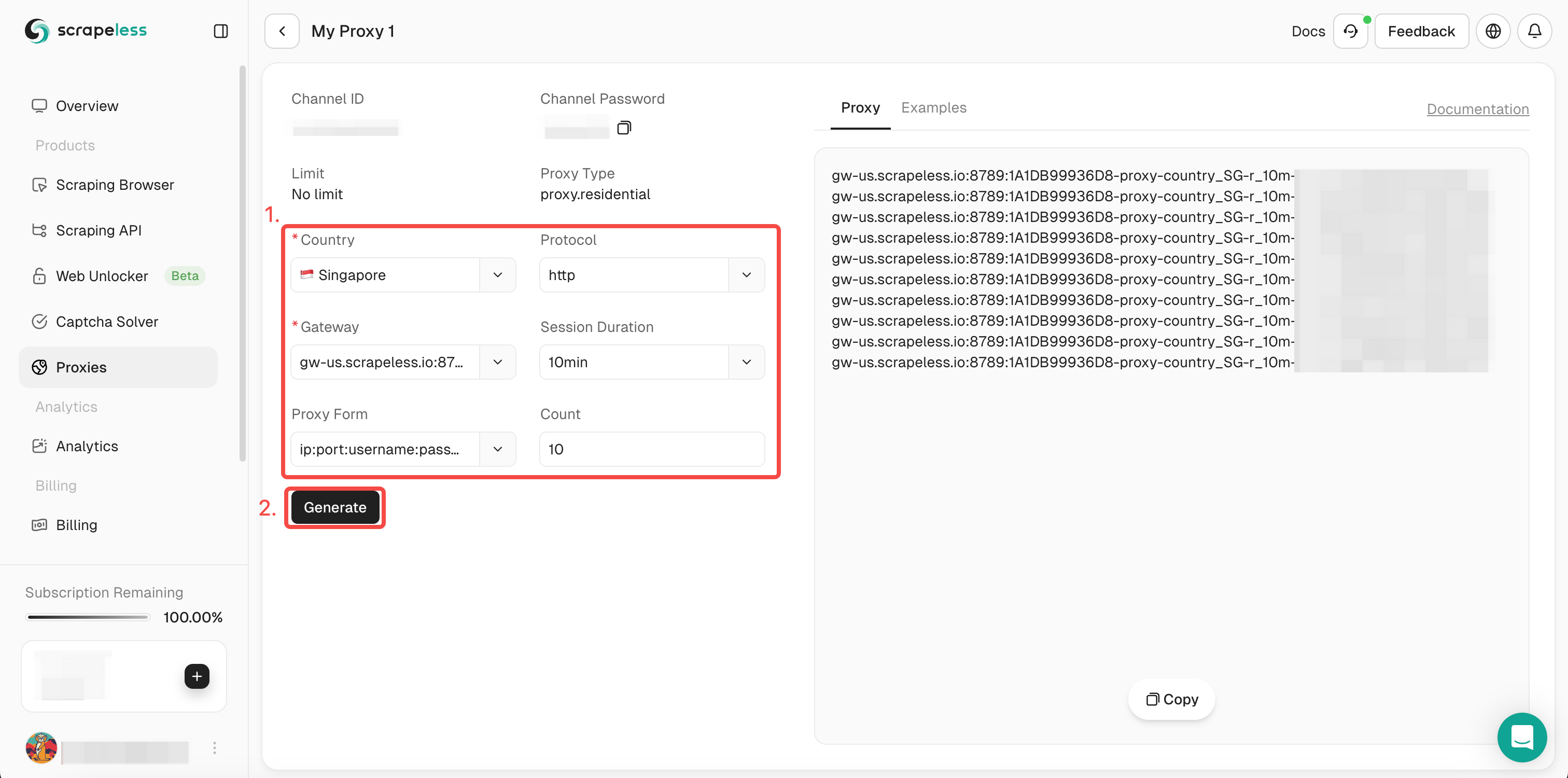
Step 3. Fill in the information you need in the left operation box. Then click "Generate". After a while, you can see the rotate proxy we generated for you on the right. Now just click "Copy" to use it.
Or you can just integrate our proxy codes into your project:
- Code:
Copy
curl --proxy host:port --proxy-user username:password API_URL- Browser:
- Selenium
Copy
from seleniumbase import Driver
proxy = 'username:password@gw-us.scrapeless.com:8789'
driver = Driver(browser="chrome", headless=False, proxy=proxy)
driver.get("API_URL")
driver.quit()- Puppeteer
Copy
const puppeteer =require('puppeteer');
(async() => {
const proxyUrl = 'http://gw-us.scrapeless.com:8789';
const username = 'username';
const password = 'password';
const browser = await puppeteer.launch({
args: [`--proxy-server=${proxyUrl}`],
headless: false
});
const page = await browser.newPage();
await page.authenticate({ username, password });
await page.goto('API_URL');
await browser.close();
})();FAQ
❓How to scrape user accounts on Instagram and TikTok via AWS?
To scrape user accounts on platforms like Instagram and TikTok using AWS, you typically need to deploy a scraping framework (like Puppeteer, Playwright, or Selenium) on an AWS EC2 instance. However, due to strict anti-bot policies and login restrictions on both platforms, scraping user profiles can be technically complex and legally sensitive.
A better alternative? Use a service like Scrapeless, which provides prebuilt scraping endpoints with rotating IPs and no maintenance needed --- no need to handle AWS configurations or session management manually.
❓How to scrape TikTok tags?
Scraping TikTok tags involves extracting videos and metadata associated with a specific hashtag (e.g., #cleantok). This requires fetching pages tied to the tag and parsing data like video titles, likes, user handles, and timestamps.
While TikTok doesn't offer an official API for hashtag scraping, services like Scrapeless can simulate TikTok's frontend behavior and extract structured hashtag-related data via a dedicated scraper module --- all without code.
❓Is it legal to scrape TikTok product data?
Scraping public product data (like names, prices, and descriptions) from TikTok Shop is generally legally permissible under fair use --- especially if the data is publicly available and used for market research, price comparison, or academic purposes.
However, always follow best practices:
- Do not scrape personal or private information.
- Do not violate TikTok's terms of service.
- Respect rate limits and avoid DDoS-like behavior.
Conclusion
Scraping popular products on TikTok Shop can provide valuable insights into trending items, market demand, and competitor strategies. Whether you're using manual methods via browser DevTools or leveraging powerful no-code tools like Scrapeless, choosing the right approach depends on your data scale, technical comfort, and need for efficiency. Scrapeless simplifies the entire process with ready-to-use endpoints for product search, detail extraction, and storefront analysis---without writing a single line of code.
🚀 Ready to extract TikTok product data effortlessly? Try Scrapeless now and turn insights into action---no coding, no setup, just data.
Disclaimer: Always ensure your data collection practices align with TikTok's terms of service and relevant data privacy laws. Scrapeless is designed for ethical use, including research and business intelligence.