Scrapy是一个目前还比较流行的开源爬虫框架。
专门用于提供爬虫学习的网站如:http://books.toscrape.com、https://www.zhihu.com/hot、https://movie.douban.com/top250等。
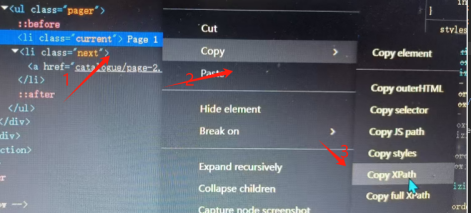
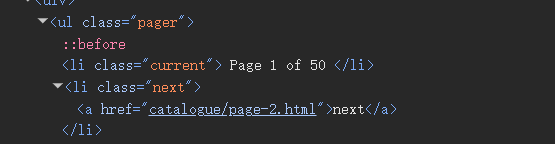
在使用parse来对网页内容进行爬时,使用的是CSS选择器或XPath来提取页面中的数据内容。以以下图片中的内容为例。XPath的使用用法:提取信息的命名=爬虫名称.XPath("输入复制的XPath").提取第几个内容
CSS选择器的使用方法:提取信息的命名=爬虫名称.css("ul.pager li.next a::attr(herf)").提取第几个内容
对获取的下一个网页的URL,使用yield和request的组合方式将请求都由yield语句交给Scrapy引擎,例子:yield scrapy.Request(next_url,cllback=self.parse)
知识扩展:yield与return的区别:都是返回一个值,return返回一个值后,yield返回的是一个对象。代码段执行结束;yield在返回值以后会交出CPU的使用权,代码段并没有直接结束,而是在此处中断,当调用send()或next()方法后,yield可以从之前中断的地方继续执行后续新增的代码段。
爬虫注意事项:①爬虫的时候在爬取网页的URL的时候记得对URL进行去重,这很关键;在进行网页搜索中的搜索策略可以选择深度搜索或者广度搜索两种策略;以及还要考虑爬虫的边界限定的问题。
②Scrapy的安装很简单:直接就是pip install scrapy,然后查看下载的版本:scrapy.version_info
③爬虫的起始点可以设定多个,但是需要预先对每个不同的爬虫进行不同的命名,是的爬虫的效率增加
④爬虫的流程:创建并命名爬虫名称-》对爬取的网页的URL进行设定-》parse方法的使用来提取页面总的内容
爬虫学习——Scrapy
爱吃泡芙的小白白2025-04-21 17:10
相关推荐
天青色等烟雨..5 分钟前
全流程ArcGISPro空间分析、三维建模、可视化及Python融合应用技术极光代码工作室9 分钟前
基于Spark的日志监控与分析平台AOwhisky14 分钟前
Python 学习笔记(第十三期)——运维自动化(下·前篇):远程命令执行——paramiko基础篇浊酒南街22 分钟前
subprocess.check_output函数介绍TheBestRucy23 分钟前
RAG知识库问答系统落地:从向量检索到上下文增强的全链路实践AOwhisky41 分钟前
Python 学习笔记(第十四期)——运维自动化(下·中篇):远程文件传输——paramiko进阶篇其实防守也摸鱼1 小时前
补天SRC新手入门指南:从0到1的漏洞挖掘之路lupai1 小时前
手机在网状态查询 API 新手实战指南拓海SEO外贸1 小时前
Google 爬虫管理:抓取预算、404 与重定向其美杰布-富贵-李2 小时前
Spring Boot 依赖注入说明文档