目录
1.配置模版虚拟机
1.安装模板虚拟机,IP地址 192.168.10.100****、主机名称**** hadoop100****、内存2**** G****、****硬盘20G(有需求的可以配置4G内存,50G硬盘)
2.hadoop100虚拟机配置要求(本文Linux系统以CentOS-7.5-x86_64-DVD-1804.iso为例)
(1)先看能否正常上网
root@hadoop100 \~# ping www.baidu.com
PING www.a.shifen.com (183.2.172.177) 56(84) bytes of data.
64 bytes from 183.2.172.177 (183.2.172.177): icmp_seq=1 ttl=128 time=20.6 ms
64 bytes from 183.2.172.177 (183.2.172.177): icmp_seq=2 ttl=128 time=21.3 ms
64 bytes from 183.2.172.177 (183.2.172.177): icmp_seq=3 ttl=128 time=23.4 ms
(2)然后安装epel-release
root@hadoop100 \~# yum install -y epel-release
Loaded plugins: fastestmirror, langpacks
Determining fastest mirrors
epel/x86_64/metalink | 5.1 kB 00:00:00
* epel: d2lzkl7pfhq30w.cloudfront.net
base | 3.6 kB 00:00:00
extras | 2.9 kB 00:00:00
updates | 2.9 kB 00:00:00
Package epel-release-7-14.noarch already installed and latest version
Nothing to do
我这个是已经安装过了的
(3)检查是否有ifconfig和vim等命令,没有则下载
root@hadoop100 \~# yum install -y net-tools
Loaded plugins: fastestmirror, langpacks
Loading mirror speeds from cached hostfile
* epel: d2lzkl7pfhq30w.cloudfront.net
Resolving Dependencies
root@hadoop100 \~# yum install -y net-tools
Loaded plugins: fastestmirror, langpacks
Loading mirror speeds from cached hostfile
* epel: d2lzkl7pfhq30w.cloudfront.net
Resolving Dependencies
--> Running transaction check
---> Package net-tools.x86_64 0:2.0-0.22.20131004git.el7 will be updated
(4)关闭防火墙
root@hadoop100 \~# sudo systemctl stop firewalld
关闭防火墙
root@hadoop100 \~# sudo systemctl disable firewalld
Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service.
Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.
关闭自启动
验证是否关闭防火墙
root@hadoop100 \~# systemctl status firewalld
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; enabled; vendor preset: enabled)
Active: inactive (dead) since Mon 2025-04-21 02:54:55 PDT; 3min 55s ago
Docs: man:firewalld(1)
Process: 677 ExecStart=/usr/sbin/firewalld --nofork --nopid $FIREWALLD_ARGS (code=exited, status=0/SUCCESS)
Main PID: 677 (code=exited, status=0/SUCCESS)
Apr 21 02:43:14 hadoop100 systemd1: Starting firewalld - dynamic firewall daemon...
Apr 21 02:43:14 hadoop100 systemd1: Started firewalld - dynamic firewall daemon.
Apr 21 02:54:54 hadoop100 systemd1: Stopping firewalld - dynamic firewall daemon...
Apr 21 02:54:55 hadoop100 systemd1: Stopped firewalld - dynamic firewall daemon.
这个就显示已经关闭防火墙了,不过会开机自启
root@hadoop100 \~# systemctl status firewalld
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; disabled; vendor preset: enabled)
Active: inactive (dead)
Docs: man:firewalld(1)
Apr 21 02:43:14 hadoop100 systemd1: Starting firewalld - dynamic firewall daemon...
Apr 21 02:43:14 hadoop100 systemd1: Started firewalld - dynamic firewall daemon.
Apr 21 02:54:54 hadoop100 systemd1: Stopping firewalld - dynamic firewall daemon...
Apr 21 02:54:55 hadoop100 systemd1: Stopped firewalld - dynamic firewall daemon.
这个则显示关闭防火墙,并且不会开机自启
如果你想打开防火墙,你可以
sudo systemctl start firewalld
如果要打开开机自启
sudo systemctl enable firewalld
(5)创建用户,并且更改密码,我用的是perf1,你们可以自由选择
root@hadoop100 \~# useradd perf1
root@hadoop100 \~# passwd perf1
Changing password for user perf1.
New password:
BAD PASSWORD: The password is shorter than 8 characters
Retype new password:
passwd: all authentication tokens updated successfully.
(6)给我们的用户添加root权限(添加免密功能),方便后期加sudo执行root权限的命令
root@hadoop100 \~# vim /etc/sudoers
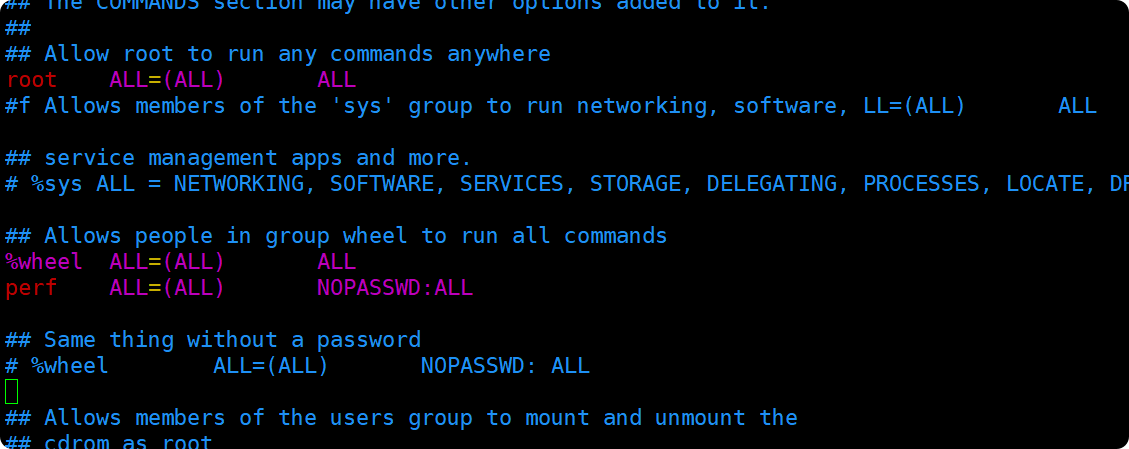
在%wheel这行下面添加一行,
perf ALL=(ALL) NOPASSWD:ALL
要注意,不要添加到root下方,因为所有的用户都在%wheel组那里,如果添加到root下面,后面仍然还是要输密码
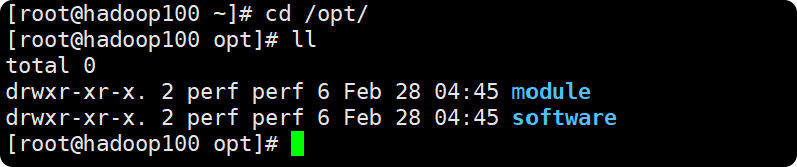
(7)在 /opt 目录下创建module、software文件夹,然后修改他们所属主和所属组
mkdir /opt/module
mkdir /opt/software
用这两串代码创建文件夹,然后
chown perf:perf /opt/module
chown perf:perf /opt/software
用这两串代码把他们的所属组和主都为自己的用户,我是perf,你们用自己的用户就好
(8)卸载虚拟机自带的jdk
root@hadoop100 \~# rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps
rpm -qa:查询所安装的所有rpm软件包
grep -i:忽略大小写
xargs -n1:表示每次只传递一个参数
rpm -e --nodeps:强制卸载软件
(9)重启虚拟机
reboot
2.克隆虚拟机
1.在关闭hadoop100的条件下,克隆三个虚拟机,我的是命名为hadoop102,hadoop103,hadoop104
2.修改克隆机IP,以下以hadoop102举例说明
(1)修改克隆虚拟机的静态IP
root@hadoop102 \~# vim /etc/sysconfig/network-scripts/ifcfg-ens33
改成
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="static"
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
UUID="9687cc8e-3361-48c3-831d-bb57555426e0"
DEVICE="ens33"
ONBOOT="yes"
IPADDR=192.168.10.102
GATEWAY=192.168.10.2
DNS1=192.168.10.2
你对照着改就好了,然后对应不同机子,就是不同的192.168.10.103->hadoop103。
(2)查看Linux虚拟机的虚拟网络编辑器,编辑->虚拟网络编辑器->VMnet8
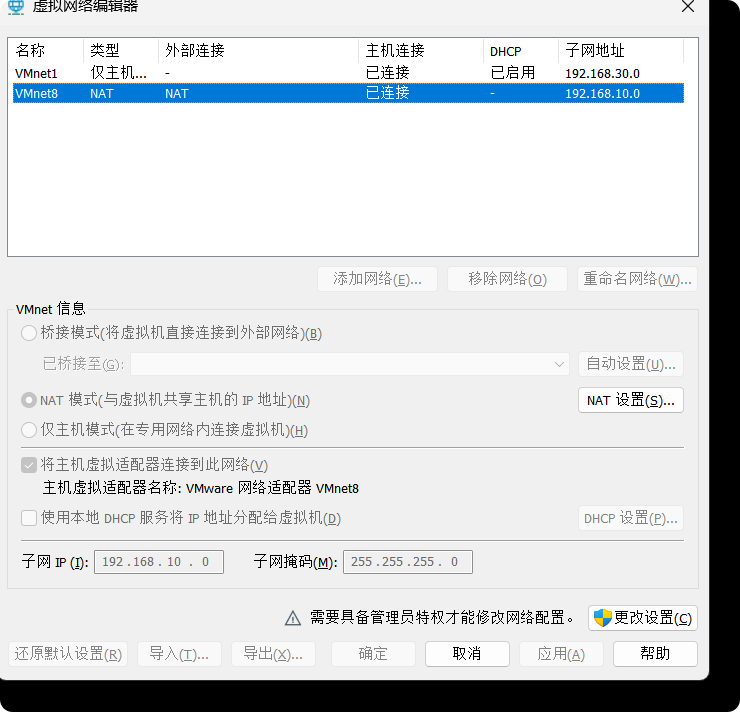
进入管理员模式
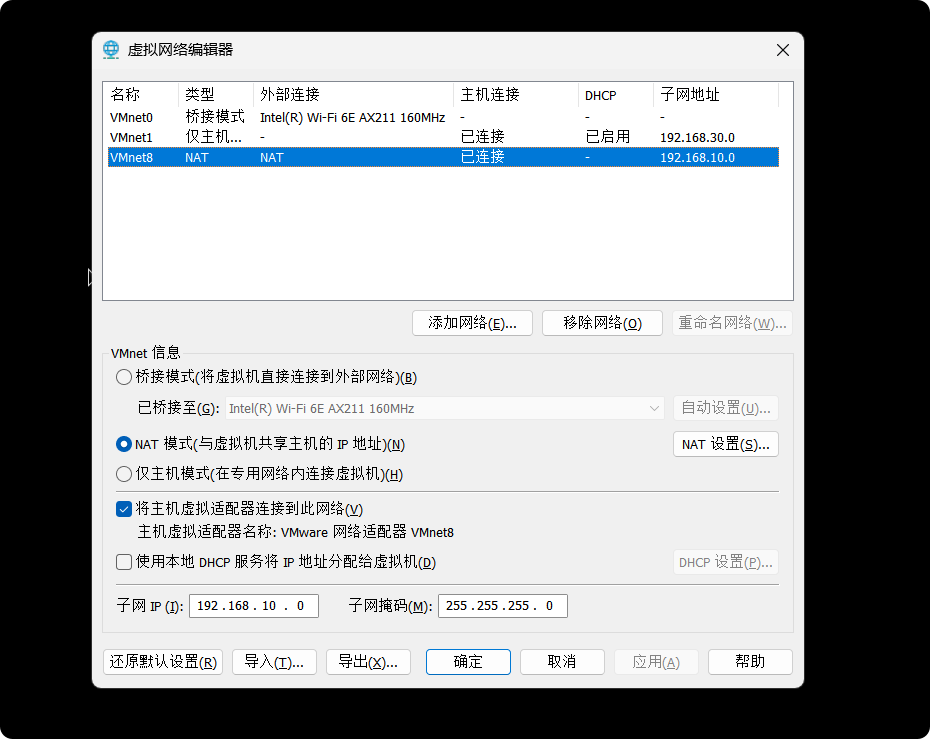
然后把VMnet8改为NAT模式,把子网和掩码改好
进入NAT设置
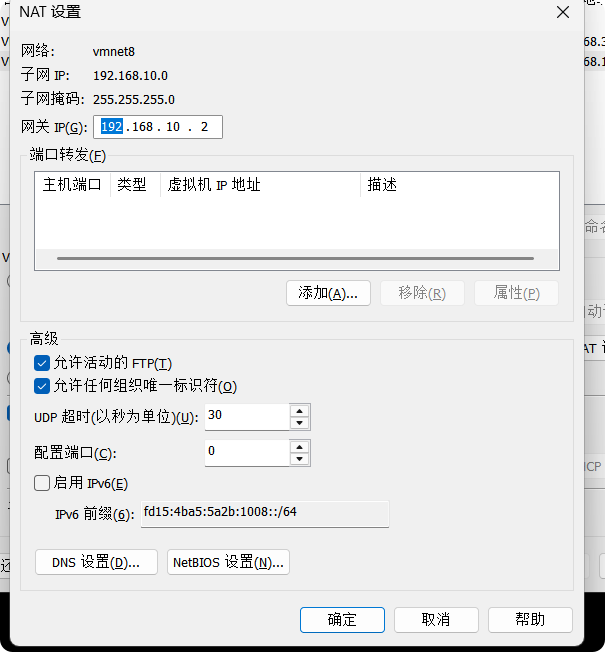
检查一下是否有问题,然后点击确定
(3)接下来就是把Windows系统的系统适配器VMware Network Adapter VMnet8的IP地址改好
进入控制面板->网络和internet->网络和共享中心,然后点击更改适配器选项。
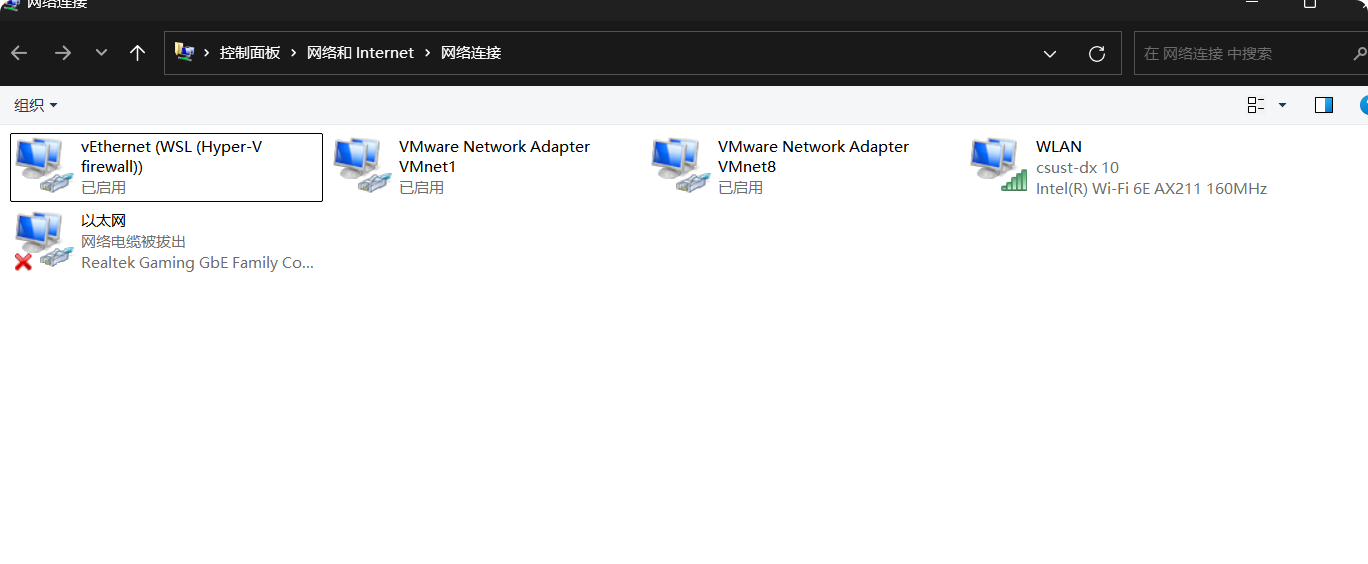
右键该配置,然后点击属性,找到ipv4的协议
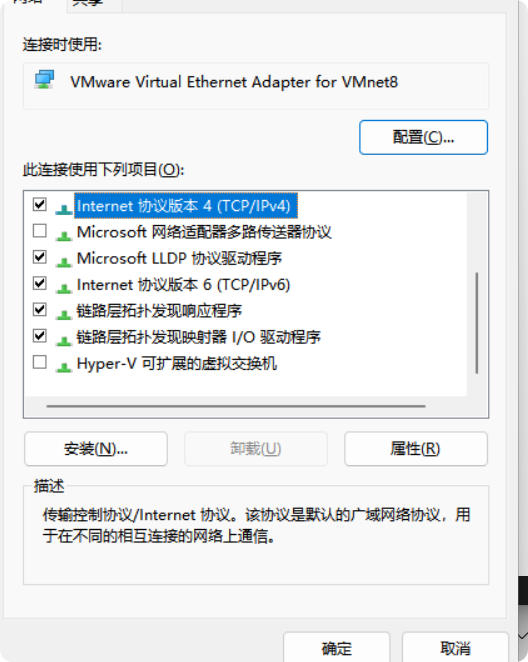
然后点击属性
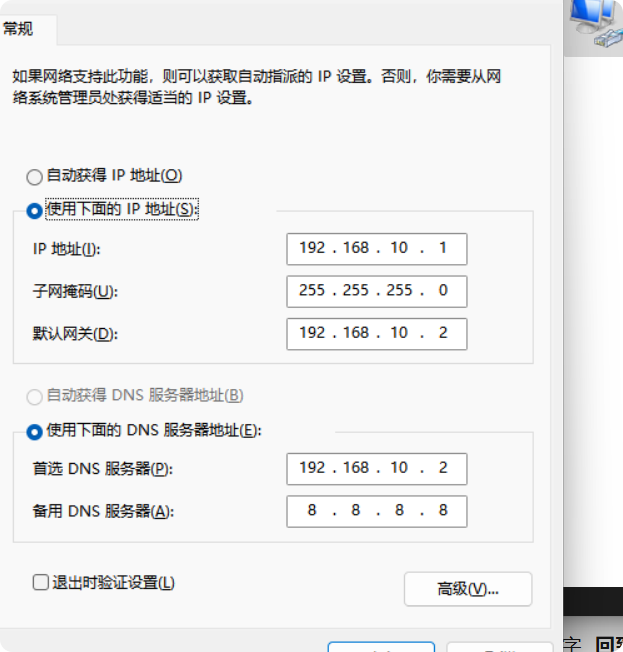
按照这样更改就好了,一定要保证Linux系统ifcfg-ens33文件中IP地址、虚拟网络编辑器地址和Windows系统VM8网络IP地址相同。
3.修改克隆机主机名,我以hadoop102举例说明
(1)修改主机名称
root@hadoop100 \~# vim /etc/hostname
hadoop102
(2)配置Linux克隆机主机名称映射hosts文件,打开/etc/hosts
root@hadoop100 \~# vim /etc/hosts
添加如下内容
192.168.10.102 hadoop102
192.168.10.103 hadoop103
192.168.10.104 hadoop104
然后重启(reboot)克隆机
4.修改windows的主机映射文件(hosts文件),不这样的话到时候无法直接在网页上用hadoop102![]() http://hadoop102:9870/
http://hadoop102:9870/
访问,到那时候也不要着急,因为你配置了前面的文件,你仍然可以用
http://192.168.10.102/![]() http://192.168.10.102:9870/
http://192.168.10.102:9870/
访问你的hadoop
我举例window11
(1)进入C:\Windows\System32\drivers\etc路径
(2)拷贝hosts文件到桌面
(3)打开桌面hosts文件并添加如下内容
192.168.10.102 hadoop102
192.168.10.103 hadoop103
192.168.10.104 hadoop104
(4)将桌面hosts文件覆盖C:\Windows\System32\drivers\etc路径hosts文件
3.在hadoop102安装JDK
1.用XShell传输工具将JDK导入到opt目录下面的software文件夹下面
XShell和XFTP下载地址:
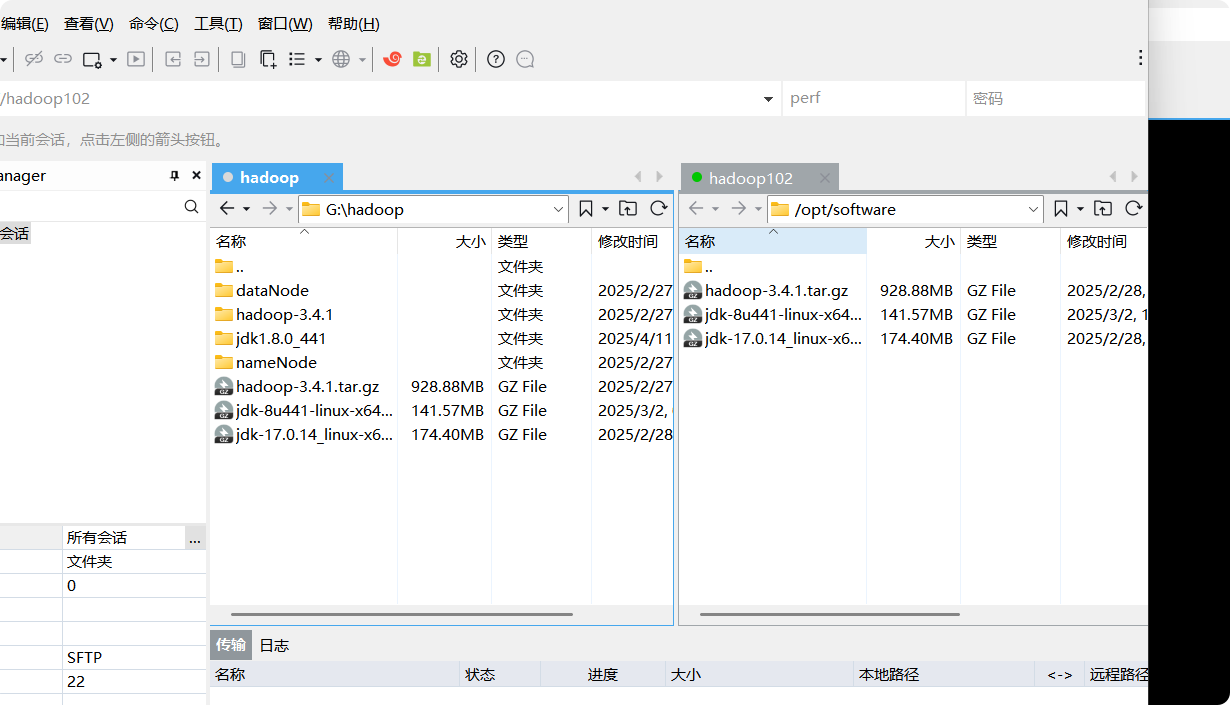
我们直接把hadoop-3.4.1.tar.gz和jdk-8u441-linux-x64.tar.gz复制过去
2.在Linux系统下的software目录中查看软件包是否导入成功
perf@hadoop102 software$ cd /opt/software/
perf@hadoop102 software$ ll

3.解压我们的导入
tar -zxvf jdk-8u441-linux-x64.tar.gz -C /opt/module/
tar -zxvf hadoop-3.4.1.tar.gz -C /opt/module/
4.配置环境变量和hadoop
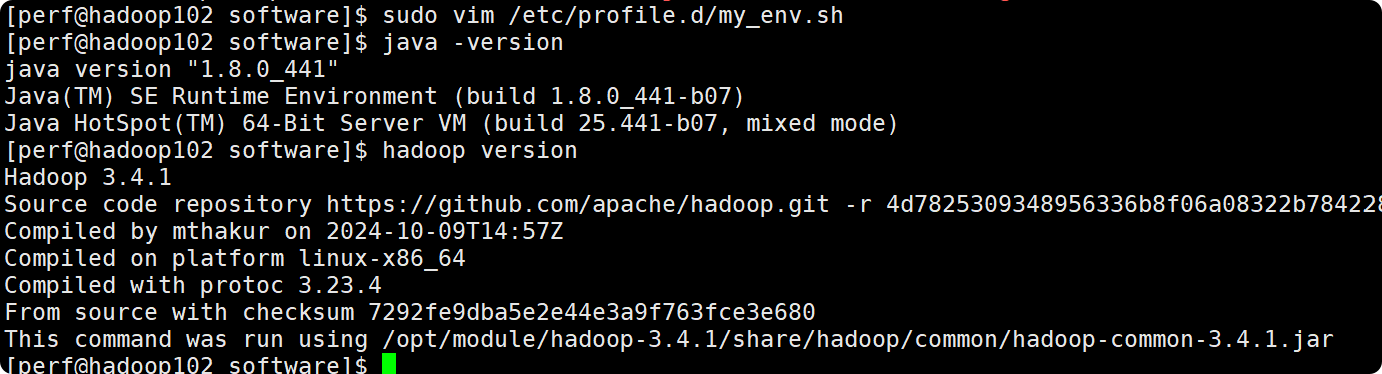
(1)新建/etc/profile.d/my_env.sh文件
perf@hadoop102 \~$ sudo vim /etc/profile.d/my_env.sh
添加如下内容
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_441
export PATH=PATH:JAVA_HOME/bin
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.4.1
export PATH=PATH:HADOOP_HOME/bin
export PATH=PATH:HADOOP_HOME/sbin
(2)保存后退出
:wq
(3)source一下/etc/profile文件,让新的环境变量PATH生效
perf@hadoop102 \~$ source /etc/profile
5.测试是否安装成功
perf@hadoop102 \~$ java -version
perf@hadoop102 hadoop-3.1.3$ hadoop version
出现以下内容,代表成功:
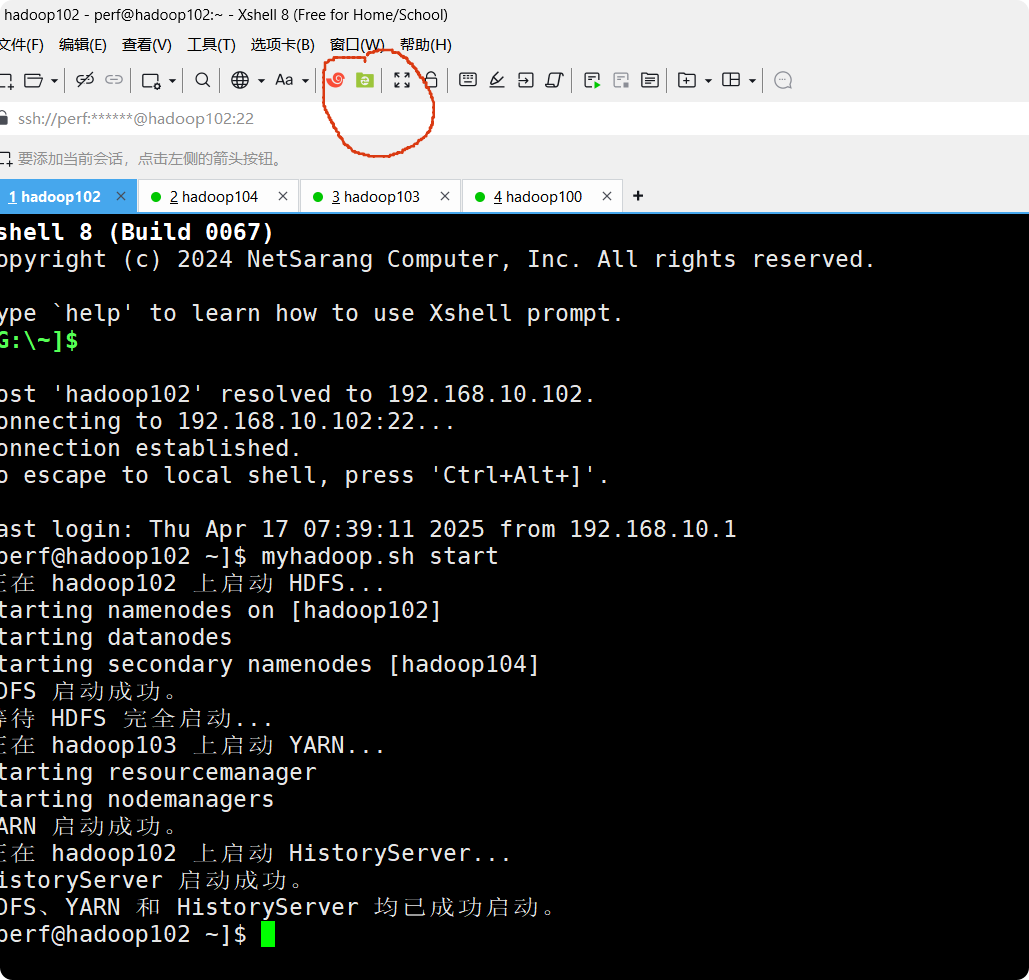
6.sudo reboot,重启,如果命令可以用,那就不要重启
4.完全分布式运行模式
1.SSH无密登录配置
(1)配置ssh
(1)基本语法
ssh另一台电脑的IP地址
(2)ssh连接时出现Host key verification failed的解决方法
perf@hadoop102 \~$ ssh hadoop103
如果出现如下内容
Are you sure you want to continue connecting (yes/no)?
输入yes,并回车
(3)退回到hadoop102
perf@hadoop103 \~$ exit
(2)无密钥配置
(1)
perf@hadoop102 \~$ cd /home/perf/.ssh/
perf@hadoop102 .ssh$ ll
total 16
-rw-------. 1 perf perf 1188 Mar 1 00:44 authorized_keys
-rw-------. 1 perf perf 1679 Mar 1 00:19 id_rsa
-rw-r--r--. 1 perf perf 396 Mar 1 00:19 id_rsa.pub
-rw-r--r--. 1 perf perf 558 Feb 28 23:08 known_hosts
perf@hadoop102 .ssh$ ssh-keygen -t rsa
然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
perf@hadoop102 .ssh$ ssh-copy-id hadoop102
perf@hadoop102 .ssh$ ssh-copy-id hadoop103
perf@hadoop102 .ssh$ ssh-copy-id hadoop104
然后分别在hadoop103和hadoop104的perf用户进行一样的操作,然后在hadoop102的root也做一个一样的。
2.集群配置
|------|-------------------|-----------------------------|----------------------------|
| | hadoop102 | hadoop103 | hadoop104 |
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
(1)核心配置文件
perf@hadoop102 .ssh cd HADOOP_HOME/etc/hadoop
perf@hadoop102 hadoop$ vim core-site.xml
更改文件内容:
<configuration>
<!-- HDFS默认访问地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:9000</value>
</property>
<!-- Hadoop目录(所有节点) -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.4.1/data</value>
<!--配置HDFS网页静态用户为perf-->
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>perf</value>
</property>
</configuration>
(2)HDFS配置文件
perf@hadoop102 hadoop$ vim hdfs-site.xml
更改文件内容:
<configuration>
<!-- NameNode HTTP Web UI地址 -->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value> <!-- 绑定到主节点的主机名和端口 -->
</property>
<!-- NameNode HTTPS Web UI地址(可选) -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9871</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
(3)YARN配置文件
perf@hadoop102 hadoop$ vim yarn-site.xml
更改文件配置:
<!-- 环境变量白名单(修正后) -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME,CLASSPATH_PREPEND_DISTCACHE</value>
</property>
<!-- 新增配置:启用日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 新增配置:日志保留时间(7 天) -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs\</value>
</property>
</configuration>
(4)MapReduce配置文件
perf@hadoop102 hadoop$ vim mapred-site.xml
更改文件配置:
<configuration>
<!-- 指定使用YARN -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value> <!-- 历史服务器RPC地址 -->
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value> <!-- 历史服务器Web UI地址 -->
</property>
</configuration>
3.分发配置到其他节点
(1)编写xsync集群分发脚本(循环复制文件到所有节点的相同目录下)
这是原始拷贝:rsync -av /opt/module perf@hadoop103:/opt/
现在我们编写脚本实现便利分发:
(1)在/home/perf/bin目录下创建xsync文件
perf@hadoop102 opt$ cd /home/perf
perf@hadoop102 \~$ mkdir bin
perf@hadoop102 \~$ cd bin
perf@hadoop102 bin$ vim xsync
#!/bin/bash
# 检查参数是否为空
if $# -lt 1 ; then
echo "请提供要同步的文件或目录!"
exit 1
fi
# 定义要同步的服务器列表,这里需要根据实际情况修改
servers=(hadoop102 hadoop103 hadoop104)
# 获取当前执行脚本的用户
user=$(whoami)
# 获取要同步的文件或目录的绝对路径
pdir=(cd -P "(dirname "1")" \&\& pwd)
fname=(basename "$1")
# 检查路径是否有效
if -z "$pdir" || -z "$fname" ; then
echo "无法获取有效的文件或目录路径,请检查输入。"
exit 1
fi
**# 遍历服务器列表
for server in "{servers\[@\]}"; do
echo "================== server =================="
使用 rsync 命令进行同步
rsync -avzP "pdir/fname" "user@server:pdir" rsync_status=?**
# 检查同步是否成功
if $rsync_status -eq 0 ; then
echo "server 同步成功!"
else
case rsync_status in
1)
echo "server 同步失败:协议错误。"
;;
2)
echo "server 同步失败:语法错误。"
;;
10)
echo "server 同步失败:无法连接到远程主机。请检查网络连接和 SSH 服务是否正常。"
;;
11)
echo "server 同步失败:远程主机上的 rsync 服务未运行。"
;;
12)
echo "server 同步失败:请求的操作不支持。"
;;
13)
echo "server 同步失败:读取本地文件时出错。"
;;
*)
echo "server 同步失败:未知错误,错误码 rsync_status。"
;;
esac
fi
done
(2)修改权限
chmod +x xsync
(3)测试脚本
perf@hadoop102 \~$ xsync /home/perf/bin
(d)将脚本复制到/bin中,以便全局调用
perf@hadoop102 bin$ sudo cp xsync /bin/
(e)同步环境变量配置(root所有者)
perf@hadoop102 \~$ sudo ./bin/xsync /etc/profile.d/my_env.sh
注意:如果用了sudo,那么xsync一定要给它的路径补全。
让环境变量生效
perf@hadoop103 \~$ source /etc/profile
perf@hadoop104 \~$ source /etc/profile
接下来,你可以用这个同步各个位置的东西了。由于前面关于环境的配置没有分发,所以你可以一次性分发
perf@hadoop102 bin$ xsync /opt
4.建起集群
(1)配置workers
perf@hadoop102 bin$ vim /opt/module/hadoop-3.4.1/etc/hadoop/workers
hadoop103
hadoop104
hadoop102
注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
(2)启动集群
如果集群是第一次启动,需要在hadoop102节点格式化NameNode(注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要删除所有机器的data和logs目录,然后再进行格式化。)
perf@hadoop102 hadoop-3.4.1$ hdfs namenode -format
启动HDFS
perf@hadoop102 hadoop-3.4.1$ sbin/start-dfs.sh
在配置了ResourceManager的节点(hadoop103)启动YARN
perf@hadoop103 hadoop-3.4.1$ sbin/start-yarn.sh
在Web端查看HDFS的NameNode
(1)浏览器中输入:http://hadoop102:9870
(2)查看HDFS上存储的数据信息
在Web端查看YARN的ResourceManager
(1)浏览器中输入:http://hadoop103:8088
(2)查看YARN上运行的Job信息
注意:如果有点击无法打开的,可以试试把hadoop102改为原始192.168.10.102.如果可以打开,说明原来的hosts配置有问题。
整个集群就简单配置好了!