博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
1、项目介绍
- 技术栈:Python语言、Flask框架(Web后端)、requests爬虫(汽车之家数据采集)、机器学习(线性回归销量预测)、推荐算法(汽车个性化推荐)、Echarts可视化(数据图表展示)、HTML+CSS(前端界面)、MySQL/SQLite(数据存储)
- 核心功能:汽车之家数据自动化采集(车型信息、销量、配置、用户评价)、多维度数据可视化分析(销量趋势、车型对比)、汽车销量预测(线性回归算法)、个性化汽车推荐(基于用户偏好)、汽车详情展示、后台数据管理(增删改查)
- 研究背景:汽车市场信息分散在汽车之家等平台,用户(购车者)面临"选车难"(海量车型参数对比复杂),从业者(经销商、车企)缺乏"数据驱动决策工具"(如销量趋势预测、热门车型分析);传统信息获取依赖手动查询,效率低且缺乏深度分析(如"某车型未来3个月销量走势"),亟需"采集-分析-预测-推荐"一体化系统解决。
- 研究意义:技术层面,整合爬虫、机器学习、推荐算法与Web框架,构建"数据全流程处理"技术链;应用层面,为购车者提供"数据对比+个性化推荐",为从业者提供"销量预测+市场洞察";学习层面,适合作为Python全栈+机器学习的毕业设计,覆盖数据采集、算法应用、Web开发核心技能。
2、项目界面
-
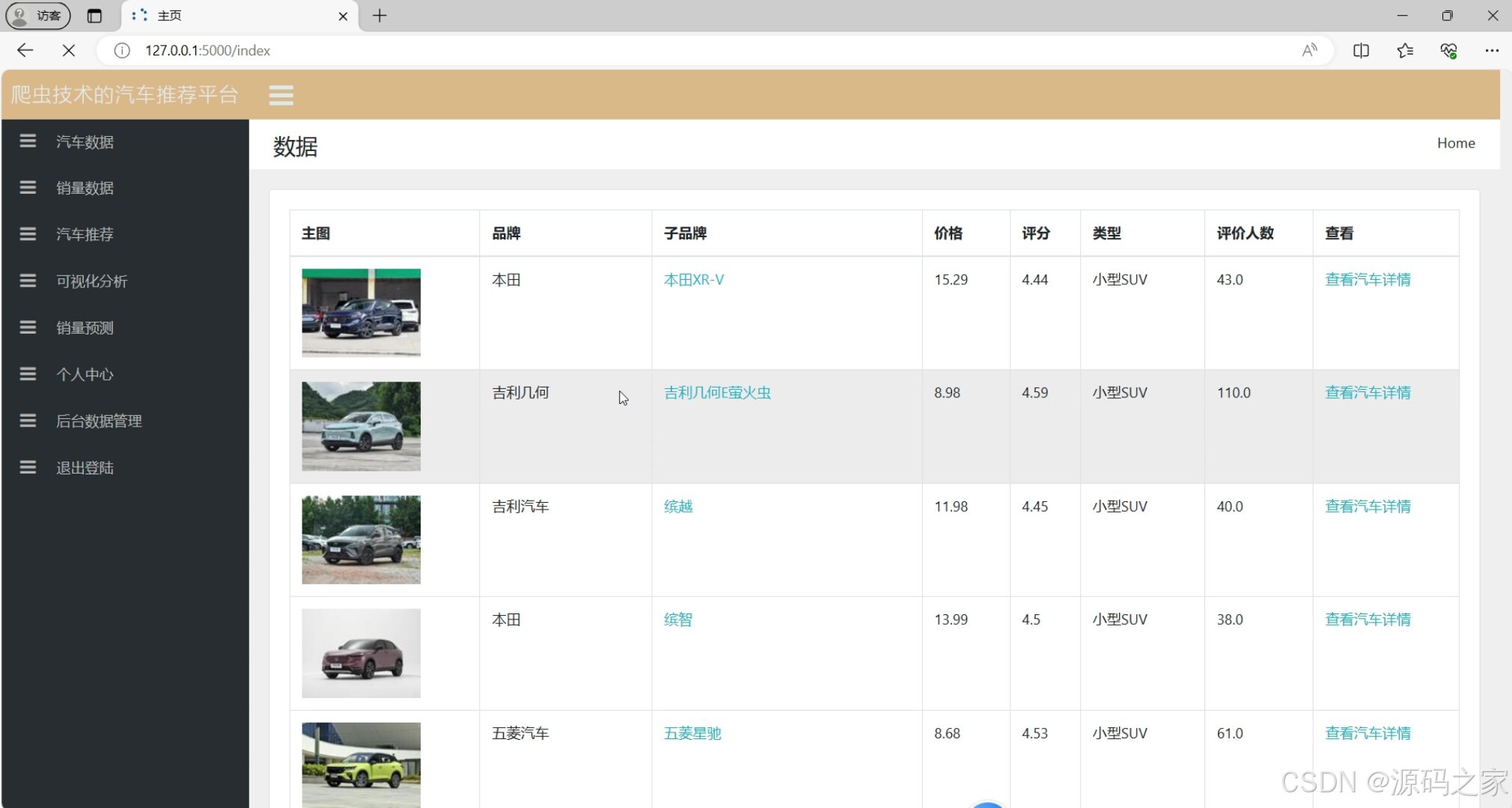
数据中心(汽车数据总览)
-
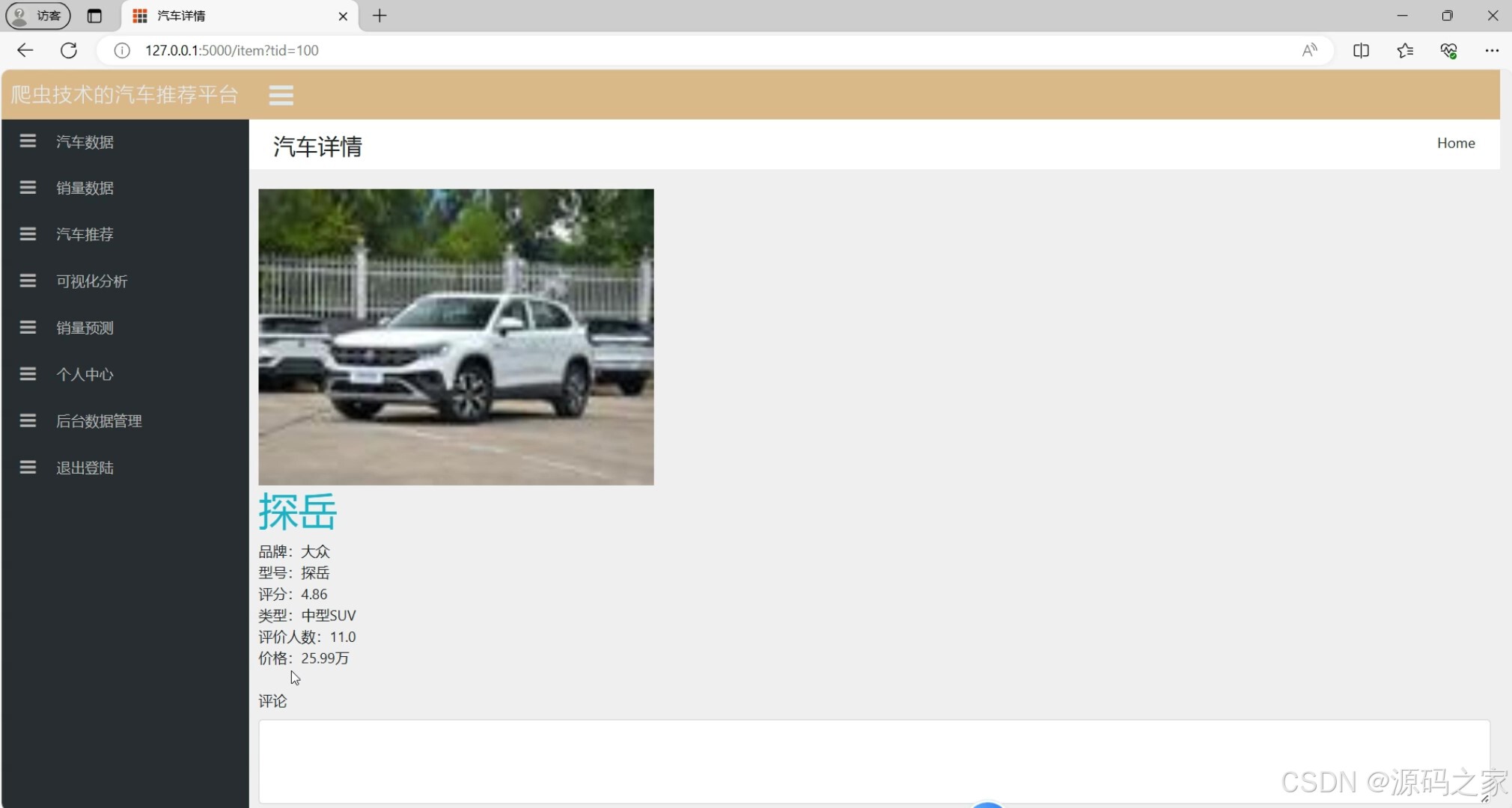
汽车详情页(单车型信息)
-
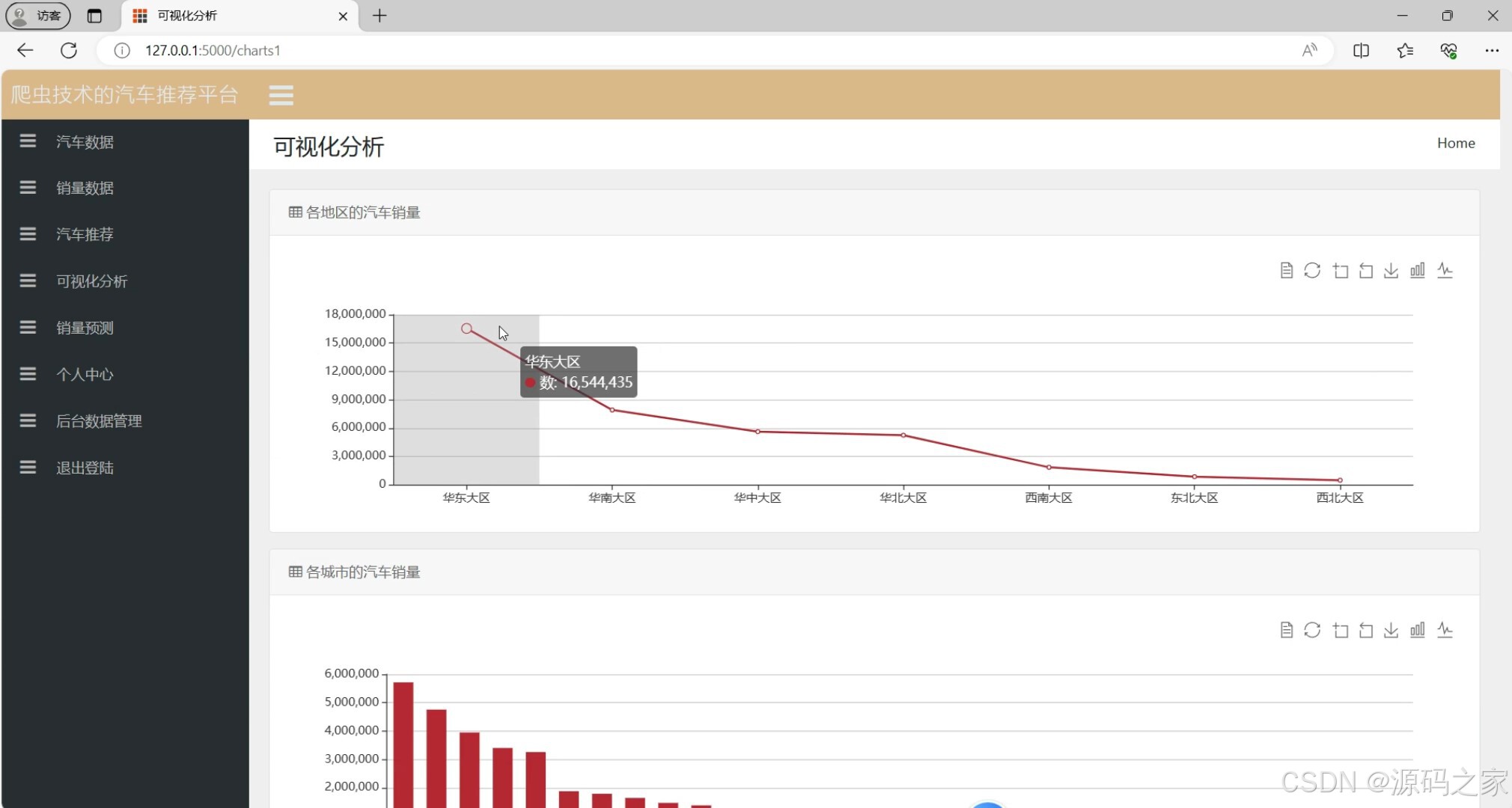
数据可视化分析(多维度图表)
-
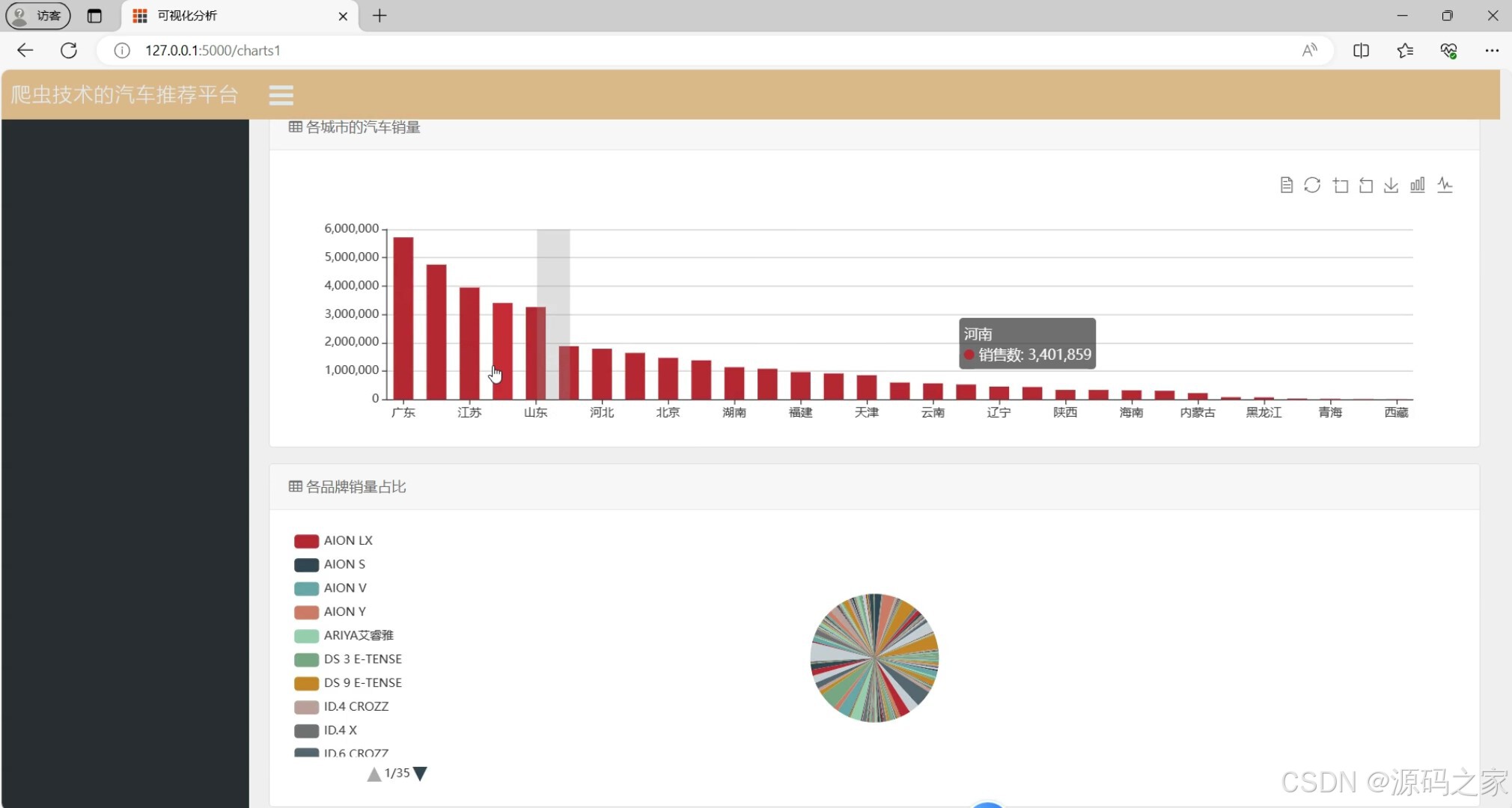
数据可视化分析2(深度对比分析)
-
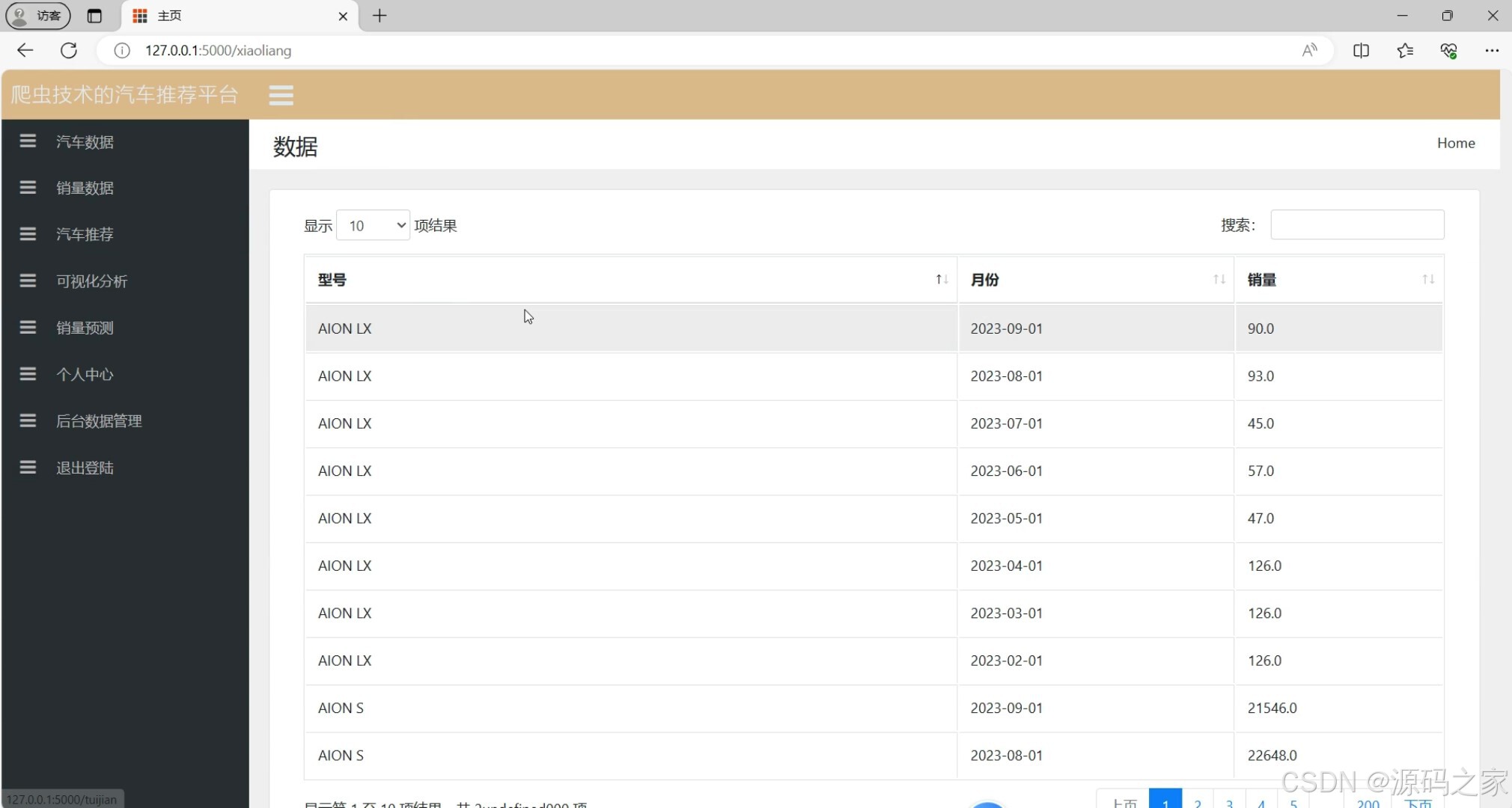
汽车销量数据(历史销量明细)
-
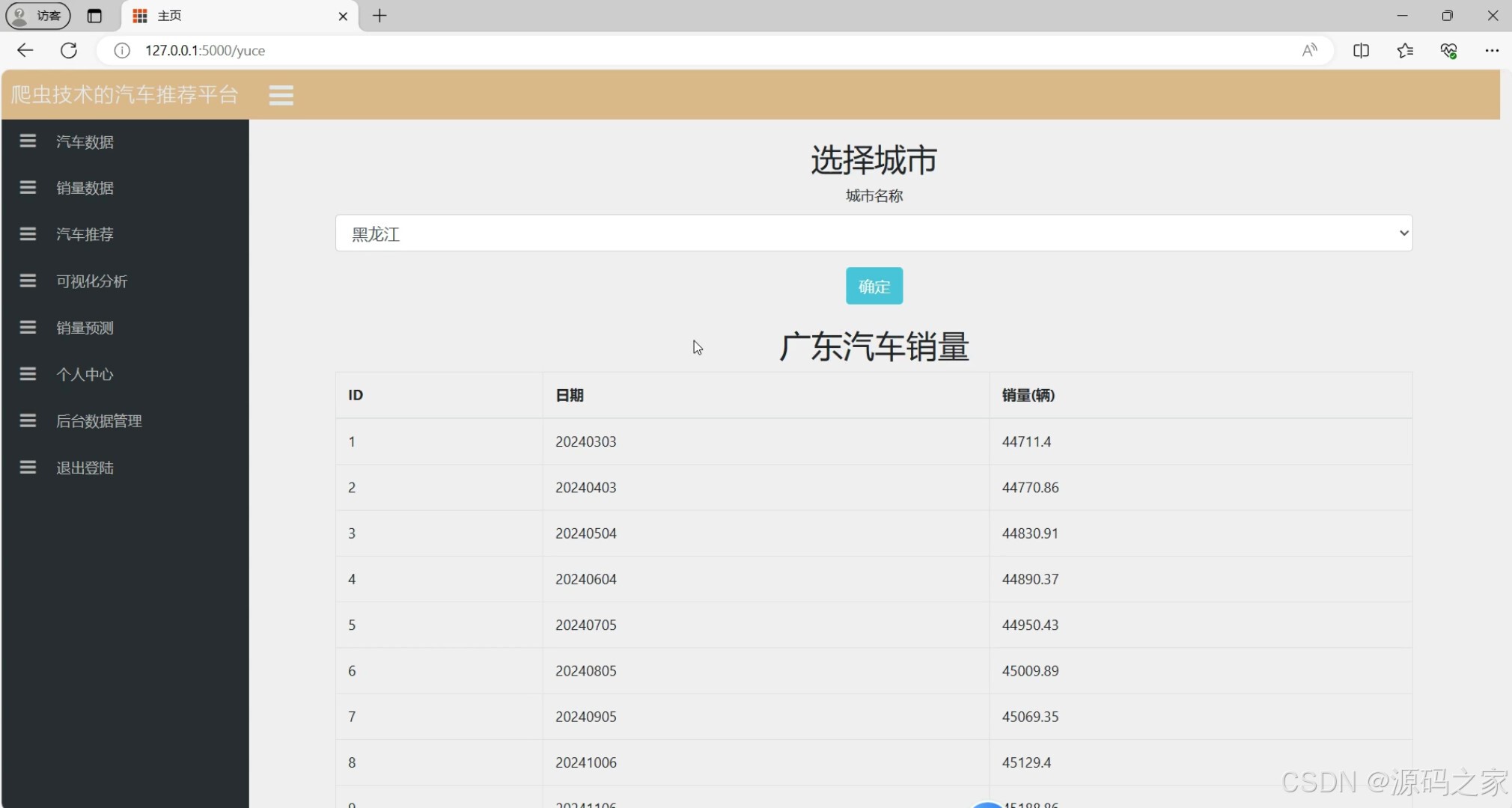
汽车销量预测(机器学习结果)
-
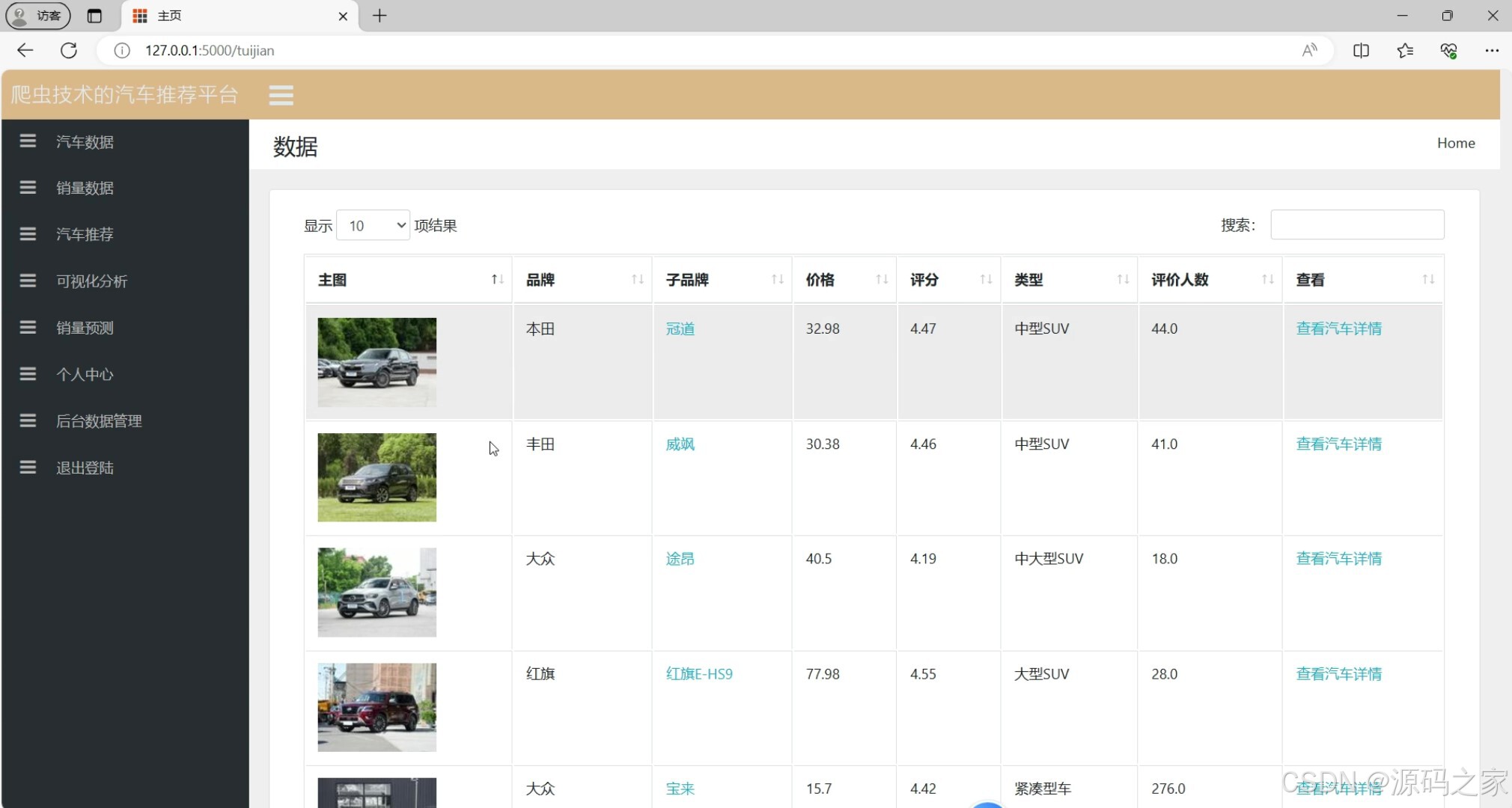
汽车推荐(个性化推荐结果)
-
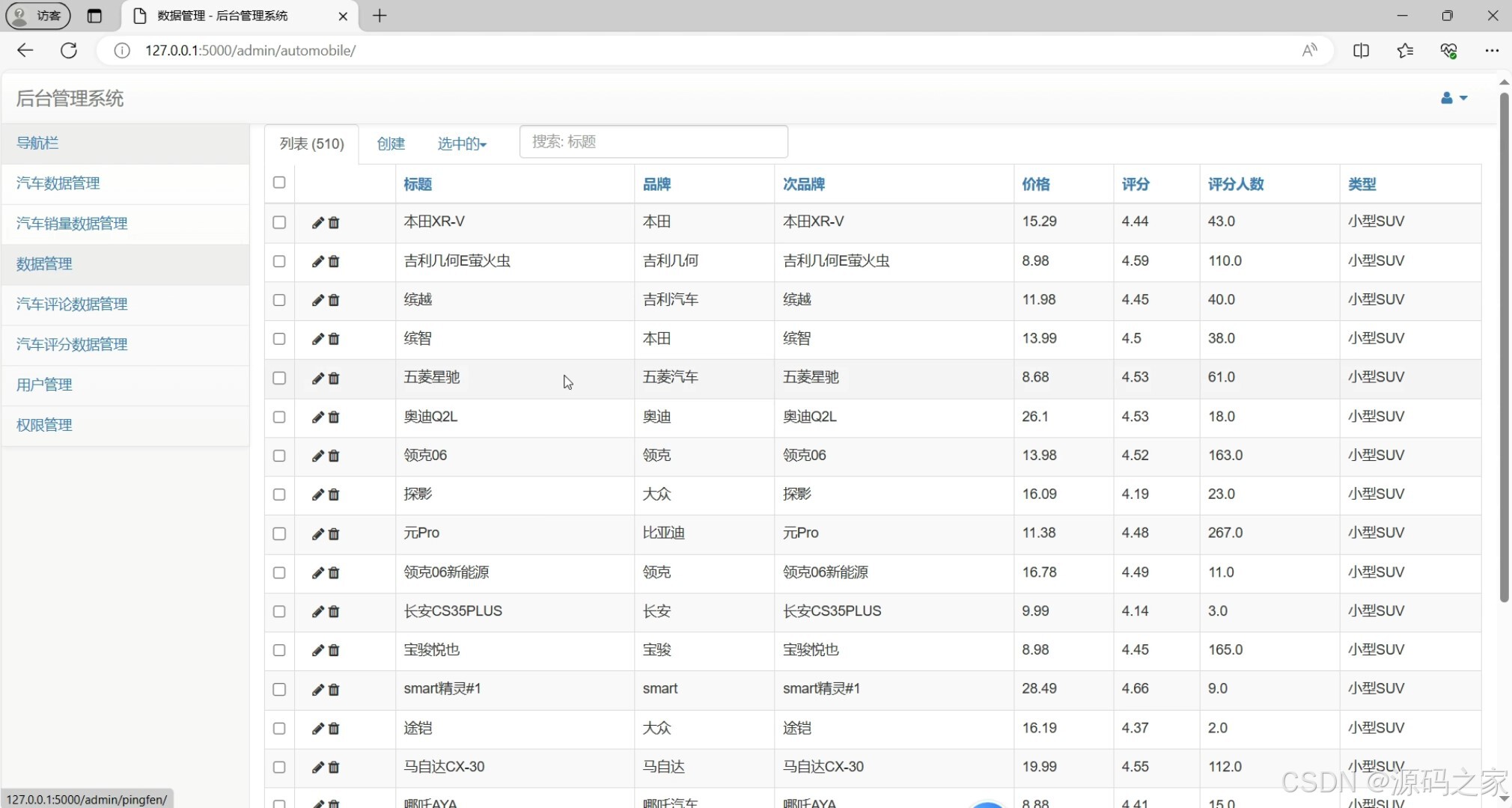
后台数据管理(数据维护界面)
3、项目说明
本项目是基于Python+Flask开发的汽车数据智能分析系统,核心通过requests爬虫采集汽车之家数据,结合机器学习(线性回归)与推荐算法,实现"数据展示-分析-预测-推荐"全流程,配套Echarts可视化与后台管理,旨在解决汽车市场信息分散、分析低效、决策缺乏数据支撑的问题。
(1)系统架构与技术逻辑
- 架构设计 :采用"数据层-算法层-应用层"三层架构,职责清晰:
- 数据层 :
- 采集:requests爬虫定向爬取汽车之家数据,包括车型基础信息(名称、价格、配置参数)、销量数据(月度/年度销量)、用户评价(评分、关键词)、市场动态(新款上市信息);
- 存储:结构化数据存入MySQL/SQLite,核心表包括------车型表(id、名称、价格、配置)、销量表(车型id、时间、销量)、评价表(车型id、用户id、评分、评论内容)、用户行为表(用户id、浏览车型、收藏记录);
- 算法层 :
- 数据分析:Pandas处理原始数据(清洗、统计、聚合),为可视化提供结构化数据;
- 销量预测:scikit-learn实现线性回归模型,以"历史销量、价格波动、竞品销量"为特征,预测未来3-6个月销量;
- 推荐算法:基于内容的推荐(匹配用户浏览车型的配置/价格偏好)+协同过滤(相似用户收藏的车型),生成个性化推荐列表;
- 应用层 :
- 后端(Flask):提供API接口(数据查询、预测调用、推荐生成)、用户认证、后台管理逻辑;
- 前端:HTML+CSS构建界面,Echarts渲染可视化图表(销量趋势图、配置对比图等),支持交互操作(筛选、切换维度);
- 数据层 :
- 核心流程:requests爬虫采集数据→清洗后存入数据库→Flask调用算法层(分析/预测/推荐)→前端通过Echarts展示结果(可视化/详情/推荐)→用户浏览/查询→管理员通过后台维护数据。
(2)核心功能模块详解
① 汽车之家数据采集模块(基础支撑)
- 功能:自动化提取汽车之家关键数据,解决"手动复制低效"问题;
- 技术实现(requests核心操作) :
- 定向爬取逻辑:
- 入口页:爬取汽车之家"车型列表页",提取所有车型名称、详情页链接;
- 详情页:访问单车型详情页,解析HTML提取------基础参数(价格区间、排量、变速箱类型)、销量数据(近12个月销量表格)、用户评价(分页爬取前100页评论);
- 反爬优化:设置随机请求头(User-Agent模拟浏览器)、爬取间隔(每5秒1次)、Cookie池(避免单一Cookie被封),确保稳定采集;
- 数据清洗:处理缺失值(如"暂无销量"标记为0)、统一格式(价格"15.98万"转为159800数值型)、去重(剔除重复车型数据)。
- 定向爬取逻辑:
② 数据可视化分析模块(直观洞察)
通过Echarts将汽车数据转化为多维度图表,辅助快速理解市场规律:
- 核心图表类型与价值 :
- 销量趋势分析:折线图展示"单车型近12个月销量"(如"特斯拉Model 3 2024年销量波动")、柱状图对比"同价位车型季度销量"(如"20万级SUV销量TOP5");
- 价格与配置分析:散点图展示"价格-配置关联"(X轴价格,Y轴配置评分,点大小代表销量,识别"高性价比车型");
- 用户评价分析:词云图展示"热门车型评论关键词"(如"省油""空间大"高频出现,反映用户关注点)、饼图展示"评分分布"(如"90%用户给某车型4星以上");
- 市场占比分析:饼图展示"各品牌市场份额"(如"BBA占豪华车市场60%")、地图展示"各省份销量占比"(识别区域偏好)。
③ 汽车销量预测模块(机器学习核心)
- 功能:基于历史数据预测未来销量,为车企/经销商提供库存、营销策略参考;
- 技术实现(线性回归流程) :
- 特征工程:选取"历史3个月销量(x1)、价格变动率(x2)、竞品同期销量(x3)、月度季节系数(x4,如春节所在月系数高)"作为输入特征;
- 模型训练:使用scikit-learn的LinearRegression,以过去3年销量数据为训练集(80%)、验证集(20%),通过均方误差(MSE)评估模型,优化特征权重;
- 预测与展示:用户在界面选择"车型+预测时长(3/6个月)"→后端调用模型输出预测销量→前端用折线图对比"历史销量+预测趋势",标注置信度(如"预测误差±5%")。
④ 汽车推荐模块(个性化服务)
- 功能:根据用户偏好推荐匹配车型,解决"选车信息过载"问题;
- 推荐逻辑 :
- 基于内容的推荐:分析用户浏览/收藏车型的"价格区间、品牌、配置(如新能源/燃油)",推荐相似特征车型(如用户浏览"20万级新能源SUV",推荐同价位同类型车型);
- 协同过滤推荐:找到与目标用户"浏览/评分行为相似"的用户群体,推荐该群体高关注度车型(如"与您相似的100位用户都收藏了某车型");
- 结果展示:推荐页面按"匹配度"排序,标注推荐理由(如"与您浏览的Model Y价格相近"),支持点击查看详情。
⑤ 汽车详情与后台管理模块(交互与运维)
- 汽车详情页 :
- 功能:展示单车型完整信息------高清图片轮播、配置参数表(排量/马力/油耗)、用户评价列表、历史销量趋势图,支持"收藏""对比"功能(添加到车型对比列表);
- 后台数据管理(管理员专属) :
- 功能:对数据库进行"增删改查"------手动补充爬虫未覆盖的数据(如新款车型)、修正错误信息(如销量录入错误)、导出分析数据(生成Excel报表)、管理用户权限(普通用户/管理员)。
4、核心代码
python
@app.route('/charts1', methods=['GET', 'POST'])
def charts1():#获取session的数据,判断是否登录,如未登录跳转到登录页
uuid = current_user.is_anonymous
if uuid:
return redirect(url_for('logins'))
username = models.User.query.get(current_user.get_id()).username
if request.method == 'GET':
datas = models.Xinxi.query.all()
#各地区的新能源汽车销量
sps = [i.diqu for i in datas]
sps_set = set(list(sps))
list1 = []
for resu in sps_set:
rows = models.Xinxi.query.filter(models.Xinxi.diqu==resu).all()
num = 0
for row in rows:
num += row.value
list1.append((resu,num))
list1.sort(key=lambda xx: xx[1], reverse=True)#对数据进行排序
zhiwei_list = []
xinzhi_list = []
for resu in list1:
zhiwei_list.append(resu[0])
xinzhi_list.append(resu[1])
#各城市的新能源汽车销量
citys = [i.city for i in datas]
citys_set = set(list(citys))
list1 = []
for resu in citys_set:
rows = models.Xinxi.query.filter(models.Xinxi.city==resu).all()
num = 0
for row in rows:
num += row.value
list1.append((resu, num))
list1.sort(key=lambda xx: xx[1], reverse=True) # 对数据进行排序
xiaoliang_list = []
xiaoliang_count = []
for resu in list1:
xiaoliang_list.append(resu[0])
xiaoliang_count.append(resu[1])
# 各品牌销量占比
leixing_set = list(set([i.name for i in models.XiaoLiang.query.all()]))
leixing_set.sort()
leixing_list = []
for row in leixing_set:
rows = models.XiaoLiang.query.filter(models.XiaoLiang.name == row).all()
num = 0
for row1 in rows:
num += row1.value
leixing_list.append({"name":row,"value":num})
print(leixing_list)
return render_template('charts1.html',**locals())
import traceback
from collections import OrderedDict
import pandas as pd
import models
from sqlalchemy import or_,and_
import datetime
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
import numpy
def yuce1(name):
try:
dates = models.Xinxi.query.filter(models.Xinxi.city == name).all()
li1 = []
for row in dates:
li1.append([int(str(row.date).replace('-','')),row.value])
li1.sort(key=lambda xx:xx[0])
date_day = []
liuliang = []
for row in li1:
date_day.append(row[0])
liuliang.append(row[1])
# 数据集
examDict = {
'日期': date_day,
'销量': liuliang
}
print(examDict)
examOrderedDict = OrderedDict(examDict)
examDf = pd.DataFrame(examOrderedDict)
examDf.head()
# exam_x 即为feature
exam_x = examDf.loc[:, '日期']
# exam_y 即为label
exam_y = examDf.loc[:, '销量']
x_train, x_test, y_train, y_test = train_test_split(exam_x, exam_y, train_size=0.8)
x_train = x_train.values.reshape(-1, 1)
x_test = x_test.values.reshape(-1, 1)
model = LinearRegression()
model.fit(x_train, y_train)
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False)
rDf = examDf.corr()
model.score(x_test, y_test)
data1 = datetime.datetime.strptime(str(date_day[-5]), '%Y%m%d')
li1 = []
for i in range(12):
data1 = data1 + datetime.timedelta(31)
li1.append([int(data1.strftime('%Y%m%d'))])
li2 = numpy.array(li1)
y_train_pred = model.predict(li2)
li2 = []
for i in range(len(li1)):
dicts = {}
dicts['riqi'] = li1[i][0]
dicts['xiaoliang'] = round(abs(y_train_pred[i]),2)
li2.append(dicts)
return li2[2:]
except:
print(traceback.format_exc())
return []
@app.route('/yuce', methods=['GET', 'POST'])
def yuce():
if request.method == 'GET':
result = list(set([i.city for i in models.Xinxi.query.all()]))
return render_template('yuce.html',**locals())
elif request.method == 'POST':
result = list(set([i.city for i in models.Xinxi.query.all()]))
name = request.form.get('name')
print(name)
datas = yuce1(name)
riqi = [i['riqi'] for i in datas]
xiaoliang = [i['xiaoliang'] for i in datas]
return render_template('yuce.html',**locals())
@app.route('/user', methods=['GET', 'POST'])
def user():
stu_id = current_user.is_anonymous
if stu_id:
return redirect(url_for('logins'))
if request.method == 'GET':
results = models.User.query.get(current_user.get_id())
return render_template('user.html',data=results)
elif request.method == 'POST':
data = request.form
username = data.get('name')
occupation = data.get('occupation')
results = models.User.query.get(current_user.get_id())
results.username = username
results.occupation = occupation
models.db.session.commit()
return redirect('/user')
from flask_security.utils import login_user, logout_user
@app.route('/logins', methods=['GET', 'POST'])
def logins():
uuid = current_user.is_anonymous
if not uuid:
return redirect(url_for('index'))
if request.method=='GET':
return render_template('account/index.html')
elif request.method=='POST':
user = request.form.get('user')
password = request.form.get('password')
data = models.User.query.filter(and_(models.User.username==user,models.User.password==password)).first()
if not data:
return render_template('account/index.html',error='账号密码错误')
else:
login_user(data, remember=True)
return redirect(url_for('index'))
@app.route('/loginsout', methods=['GET'])
def loginsout():
if request.method=='GET':
logout_user()
return redirect(url_for('logins'))
@app.route('/signups', methods=['GET', 'POST'])
def signup():
uuid = current_user.is_anonymous
if not uuid:
return redirect(url_for('index'))
if request.method == 'GET':
return render_template('account/register.html')
elif request.method == 'POST':
user = request.form.get('user')
email = request.form.get('email')
password = request.form.get('password')
if models.User.query.filter(models.User.username == user).all():
return render_template('account/register.html', error='账号名已被注册')
elif user == '' or password == '' or email == '':
return render_template('account/register.html', error='输入不能为空')
else:
new_user = user_datastore.create_user(username=user, email=email, password=password,occupation='')
normal_role = user_datastore.find_role('User')
models.db.session.add(new_user)
user_datastore.add_role_to_user(new_user, normal_role)
models.db.session.commit()
login_user(new_user, remember=True)
return redirect(url_for('index'))🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目编程以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看 👇🏻获取联系方式👇🏻